1. 数据分发策略
数据的分区策略决定了数据会分发到下游算子的那个分区,在 Flink 中有八种不同的分区策略,也称为分区器。
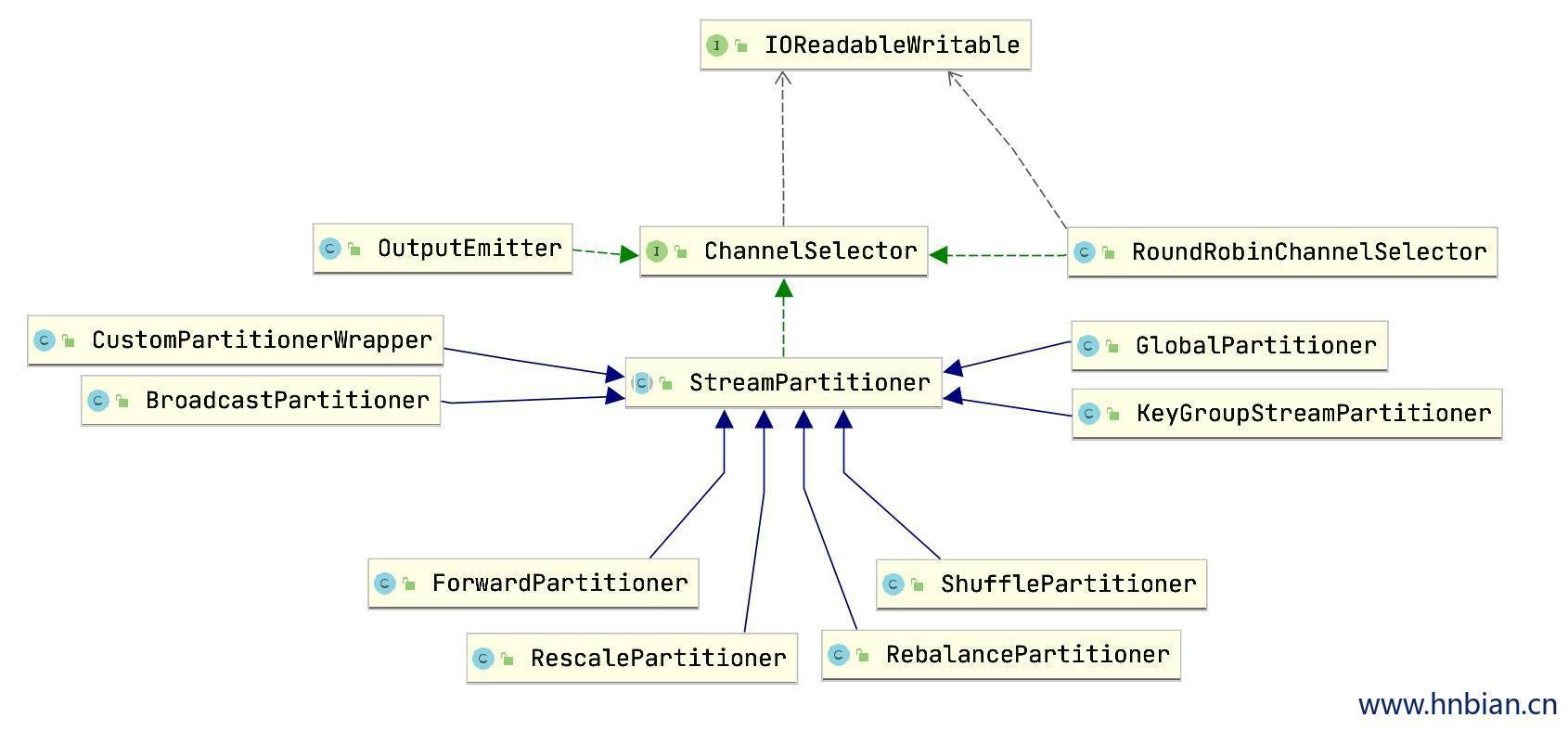
1.1 ChannelSelector
ChannelSelector 是一个接口,它的核心功能是为输入的数据选择一个逻辑的channel。
package org.apache.flink.runtime.io.network.api.writer;
// ChannelSelector用于确定数据被写入哪个通道
public interface ChannelSelector<T extends IOReadableWritable> {
/
* 根据输出通道的数量初始化通道选择器
* @param numberOfChannels 输出通道总数
*/
void setup(int numberOfChannels);
/
* 根据当前记录以及Channel总数,决定应将记录写入下游哪个Channel。
* flink 中实现的分区策略的区别主要在这个方法的实现上
*/
int selectChannel(T record);
/
* 是否广播模式,决定是否将记录写入到下游的所有channel
*/
boolean isBroadcast();
}1.2 StreamPartitioner
StreamPartitioner 是一个抽象类,它实现了 ChannelSelector 接口,它也是所有分区器的基类。
package org.apache.flink.streaming.runtime.partitioner;
import org.apache.flink.annotation.Internal;
import org.apache.flink.runtime.io.network.api.writer.ChannelSelector;
import org.apache.flink.runtime.plugable.SerializationDelegate;
import org.apache.flink.streaming.runtime.streamrecord.StreamRecord;
import java.io.Serializable;
public abstract class StreamPartitioner<T> implements
ChannelSelector<SerializationDelegate<StreamRecord<T>>>, Serializable {
private static final long serialVersionUID = 1L;
protected int numberOfChannels;
// 重写setup方法,初始化Chennal 数量
@Override
public void setup(int numberOfChannels) {
this.numberOfChannels = numberOfChannels;
}
// 重写广播方法,默认不广播
@Override
public boolean isBroadcast() {
return false;
}
// 抽象的构造方法
public abstract StreamPartitioner<T> copy();
}2.分区器介绍
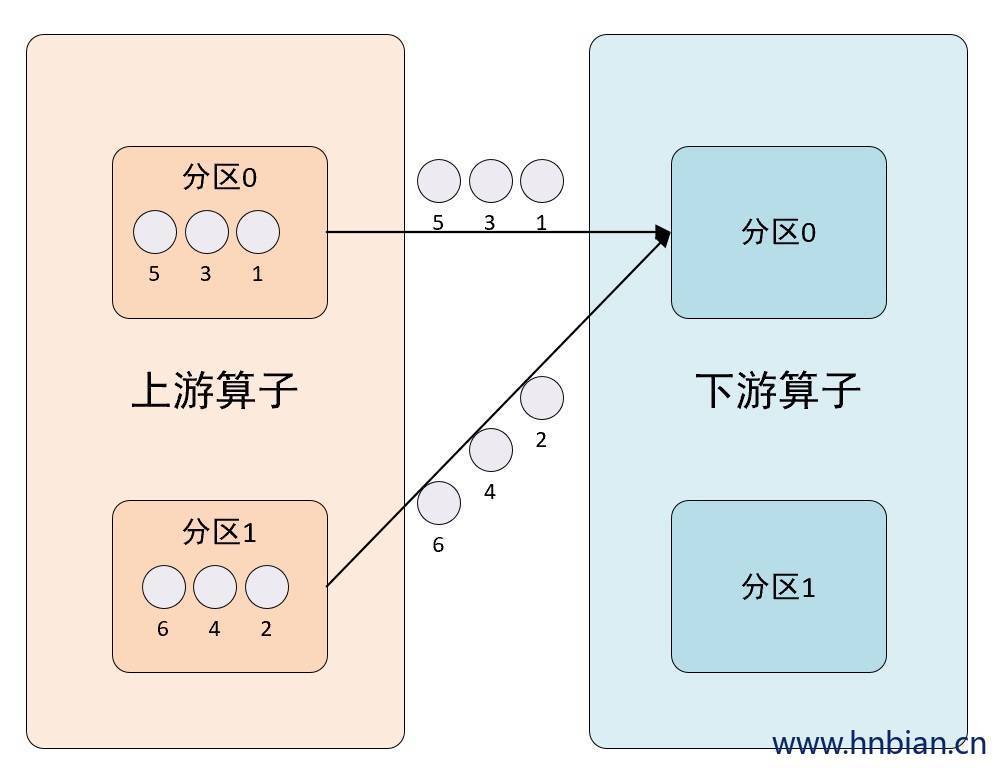
2.1 GlobalPartitioner
将所有的数据都发送到下游 0 号分区中。
2.1.1 源码解析
package org.apache.flink.streaming.runtime.partitioner;
import org.apache.flink.annotation.Internal;
import org.apache.flink.runtime.plugable.SerializationDelegate;
import org.apache.flink.streaming.runtime.streamrecord.StreamRecord;
/**
* 分区器将所有元素发送到下游算子中分区为 0 的分区中
*
* @param <T> Type of the elements in the Stream being partitioned
*/
@Internal
public class GlobalPartitioner<T> extends StreamPartitioner<T> {
private static final long serialVersionUID = 1L;
@Override
public int selectChannel(SerializationDelegate<StreamRecord<T>> record) {
// 无论数据怎样,都返回 0 号分区
return 0;
}
@Override
public StreamPartitioner<T> copy() {
return this;
}
@Override
public String toString() {
return "GLOBAL";
}
}2.1.2 图示说明
2.1.3 API 使用
object TestGlobalPartitioner extends App {
// 创建执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 从自定义的集合中读取数据
val stream = env.fromCollection(List(1,2,3,4,5))
// 直接打印数据
stream.print()
/**
* 打印结果
* 10> 1
* 2> 5
* 1> 4
* 11> 2
* 12> 3
*/
// 使用 GLobal Partitioner 之后打印数据
stream.global.print("global")
/**
* global:1> 1
* global:1> 2
* global:1> 3
* global:1> 4
* global:1> 5
*/
env.execute()
}2.2 ShufflePartitioner
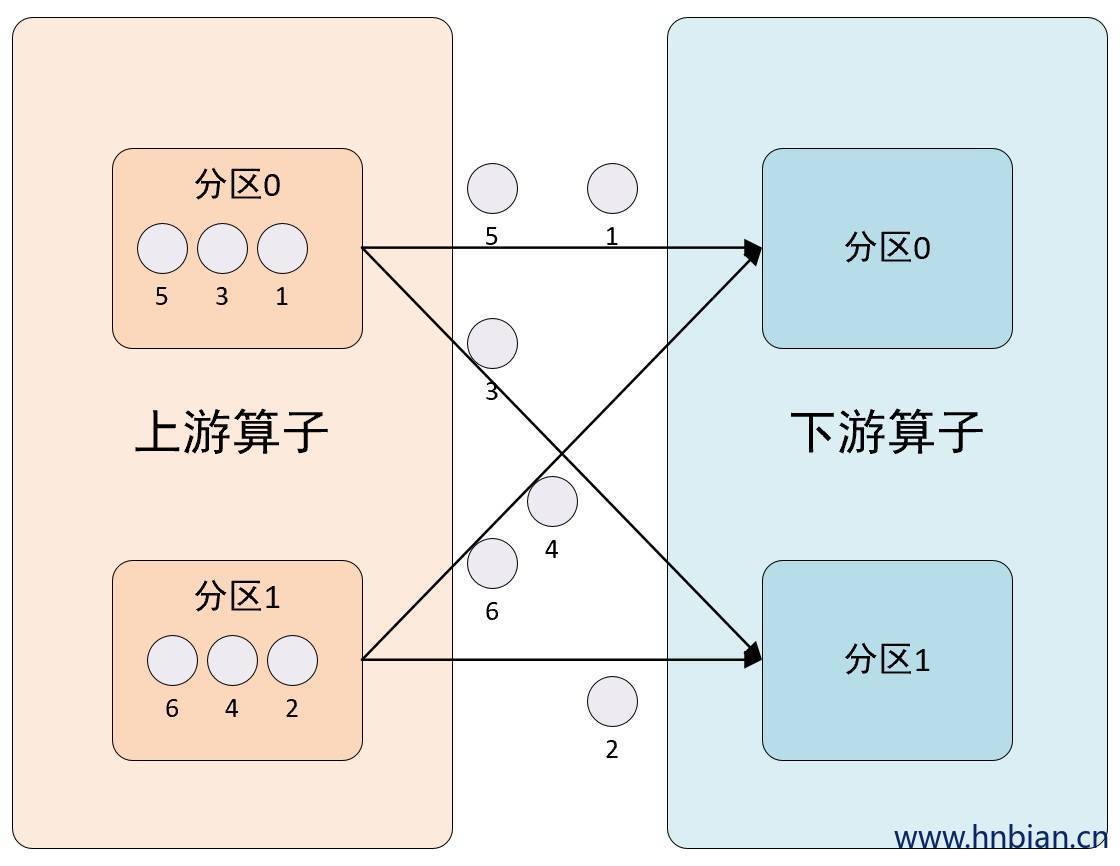
ShufflePartitioner 是默认的数据分发策略。在这种策略下,每个数据记录都有相同的概率被发送到下游算子的任何一个并行实例(即任务或子任务)。
ShufflePartitioner 的主要目标是尽可能地均匀地分布数据,以避免某些并行实例处理更多数据而导致的数据倾斜问题。在许多情况下,这样的数据分发方式可以确保各个并行实例的工作负载相对均衡。
但是,请注意,ShufflePartitioner 并不能保证每个并行实例接收到的数据量完全相等,特别是在数据量较小或并行度较高的情况下。另外,由于ShufflePartitioner 的数据分发是随机的,它不保证同一数据记录总是被发送到同一个并行实例,因此在需要保证数据一致性的场景中,可能需要使用其他的数据分发策略。
2.2.1 源码解析
package org.apache.flink.streaming.runtime.partitioner;
import org.apache.flink.annotation.Internal;
import org.apache.flink.runtime.plugable.SerializationDelegate;
import org.apache.flink.streaming.runtime.streamrecord.StreamRecord;
import java.util.Random;
/**
* 将数据随机分发到一个分区
*/
@Internal
public class ShufflePartitioner<T> extends StreamPartitioner<T> {
private static final long serialVersionUID = 1L;
private Random random = new Random();
@Override
public int selectChannel(SerializationDelegate<StreamRecord<T>> record) {
// 随机选择一个分区
return random.nextInt(numberOfChannels);
}
@Override
public StreamPartitioner<T> copy() {
return new ShufflePartitioner<T>();
}
@Override
public String toString() {
return "SHUFFLE";
}
}2.2.2 图示说明
2.2.3 API 使用
import org.apache.flink.streaming.api.scala._
object TestShufflePartitioner extends App{
// 创建执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 从自定义的集合中读取数据
val stream = env.fromCollection(List(1,2,3,4,5))
// 这里只是为了能够将并行度设置为 2
val stream2 = stream.map(v=>{(v%2,v)}).keyBy(0).map(v=>(v._1,v._2)).setParallelism(2)
println(stream2.parallelism) // 查看并行度
stream2.shuffle.print("shuffle").setParallelism(3)
/**
* shuffle:3> (0,4)
* shuffle:2> (1,1)
* shuffle:1> (0,2)
* shuffle:3> (1,3)
* shuffle:1> (1,5)
*/
env.execute()
}
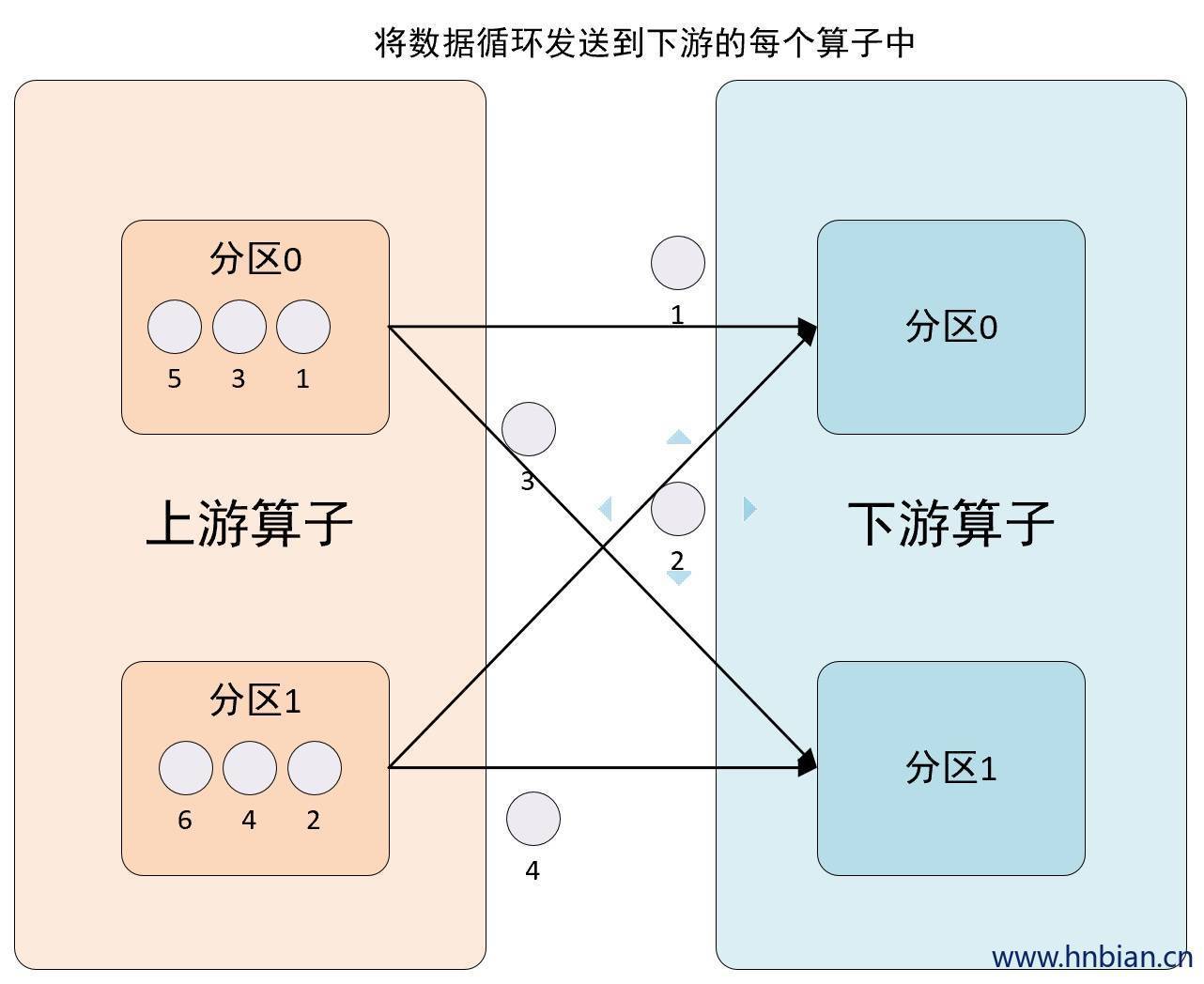
2.3 RebalancePartitioner
2.3.1 源码解析
package org.apache.flink.streaming.runtime.partitioner;
import org.apache.flink.annotation.Internal;
import org.apache.flink.runtime.plugable.SerializationDelegate;
import org.apache.flink.streaming.runtime.streamrecord.StreamRecord;
import java.util.concurrent.ThreadLocalRandom;
/**
* 轮询 所有的分区,将数据均匀的发送出去
* @param <T> Type of the elements in the Stream being rebalanced
*/
@Internal
public class RebalancePartitioner<T> extends StreamPartitioner<T> {
private static final long serialVersionUID = 1L;
private int nextChannelToSendTo;
@Override
public void setup(int numberOfChannels) {
super.setup(numberOfChannels);
//初始化channel的id,返回[0,numberOfChannels) 区间中的任意一个分区号码
nextChannelToSendTo = ThreadLocalRandom.current().nextInt(numberOfChannels);
}
@Override
public int selectChannel(SerializationDelegate<StreamRecord<T>> record) {
//循环依次发送到下游的分区
//比如:nextChannelToSendTo初始值为0,numberOfChannels(下游算子的实例个数,并行度)值为2
//则第一次发送到ID = 1的task,第二次发送到ID = 0的task,第三次发送到ID = 1的task上...依次类推
nextChannelToSendTo = (nextChannelToSendTo + 1) % numberOfChannels;
return nextChannelToSendTo;
}
public StreamPartitioner<T> copy() {
return this;
}
@Override
public String toString() {
return "REBALANCE";
}
}2.3.2 图示说明
2.3.3 API 使用
import org.apache.flink.streaming.api.scala._
object RebalancePartitioner extends App{
// 创建执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 从自定义的集合中读取数据
val stream = env.fromCollection(List(1,2,3,4,5,6))
// 直接打印数据
stream.rebalance.print().setParallelism(2)
/**
* 2> 1
* 2> 3
* 2> 5
*
* 1> 2
* 1> 4
* 1> 6
*/
env.execute()
}2.4 RescalePartitioner
RescalePartitioner是一个特殊的数据分发策略,它在应用于DataStream时会尝试在操作符之间进行重分区。RescalePartitioner不保证一致的数据分布,也就是说,同样的记录可能会被发送到不同的目标并行实例。
RescalePartitioner是一个非常有用的工具,可以帮助开发者在动态调整并行度时保持数据处理的连续性,但在使用时也需要考虑其特性和限制。
2.4.1 源码解析
package org.apache.flink.streaming.runtime.partitioner;
import org.apache.flink.annotation.Internal;
import org.apache.flink.runtime.jobgraph.DistributionPattern;
import org.apache.flink.runtime.plugable.SerializationDelegate;
import org.apache.flink.streaming.runtime.streamrecord.StreamRecord;
@Internal
public class RescalePartitioner<T> extends StreamPartitioner<T> {
private static final long serialVersionUID = 1L;
private int nextChannelToSendTo = -1;
@Override
public int selectChannel(SerializationDelegate<StreamRecord<T>> record) {
if (++nextChannelToSendTo >= numberOfChannels) {
nextChannelToSendTo = 0;
}
return nextChannelToSendTo;
}
public StreamPartitioner<T> copy() {
return this;
}
@Override
public String toString() {
return "RESCALE";
}
}2.4.2 图示说明


2.4.3 API 使用
// 2.5 BroadcastPartitioner
广播变量
- 广播变量创建后,它可以运行在集群中的任何function上,而不需要多次传递给集群节点。
- 不修改广播变量,这样才能确保每个节点获取到的值都是一致的。
- 可以理解为是一个公共的共享变量,我们可以把一个dataset 数据集广播出去,然后不同的task在节点上都能够获取到,这个数据在每个节点上只会存在一份。
- 如果不使用broadcast,则在每个节点中的每个task中都需要拷贝一份dataset数据集,比较浪费内存(也就是一个节点中可能会存在多份dataset数据)。
2.5.1 源码解析
package org.apache.flink.streaming.runtime.partitioner;
import org.apache.flink.annotation.Internal;
import org.apache.flink.runtime.plugable.SerializationDelegate;
import org.apache.flink.streaming.runtime.streamrecord.StreamRecord;
/**
* 选择所有分区发送数据
*/
@Internal
public class BroadcastPartitioner<T> extends StreamPartitioner<T> {
private static final long serialVersionUID = 1L;
/**
* 广播模式可以直接在记录写入器中为所有输出通道处理,因此不需要通过此方法选择通道。
*/
@Override
public int selectChannel(SerializationDelegate<StreamRecord<T>> record) {
throw new UnsupportedOperationException("Broadcast partitioner does not support select channels.");
}
// 广播数据
@Override
public boolean isBroadcast() {
return true;
}
@Override
public StreamPartitioner<T> copy() {
return this;
}
@Override
public String toString() {
return "BROADCAST";
}
}2.5.2 图示说明
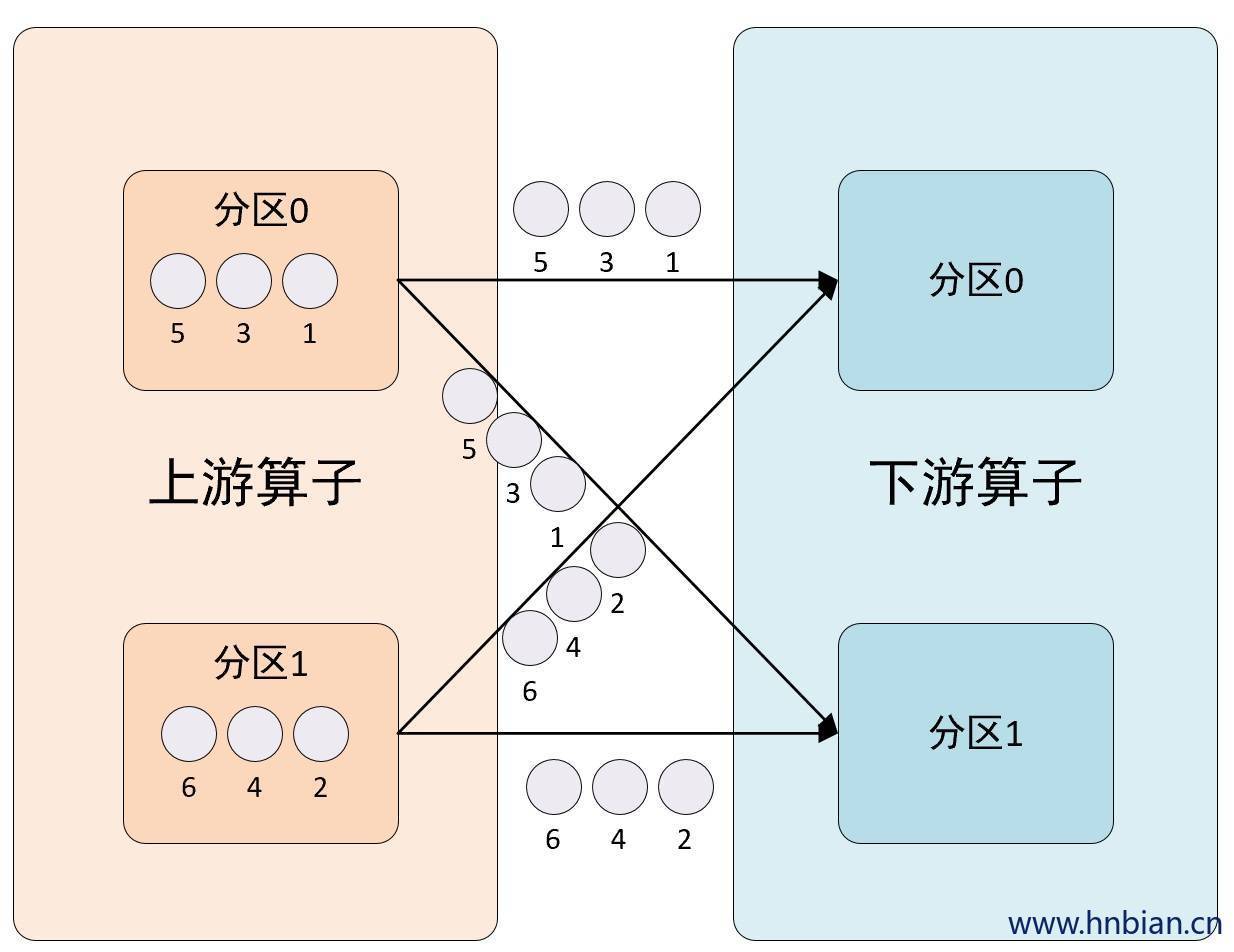
2.5.3 API 使用
import org.apache.flink.streaming.api.scala._
object TestBroadcastPartitioner extends App {
// 创建执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 从自定义的集合中读取数据
val stream = env.fromCollection(List(1,2,3,4,5))
val bro = stream.broadcast
bro.print("broadcast").setParallelism(2)
/**
* broadcast:1> 1
* broadcast:1> 2
* broadcast:1> 3
* broadcast:1> 4
* broadcast:1> 5
*
* broadcast:2> 1
* broadcast:2> 2
* broadcast:2> 3
* broadcast:2> 4
* broadcast:2> 5
*/
env.execute()
}2.6 ForwardPartitioner
发送到下游对应的第一个task,保证上下游算子并行度一致,即上有算子与下游算子是1 对 1的关系,在上下游的算子没有指定分区器的情况下,如果上下游的算子并行度一致,则使用ForwardPartitioner,否则使用RebalancePartitioner,对于ForwardPartitioner,必须保证上下游算子并行度一致,否则会抛出异常。
2.6.1 源码解析
package org.apache.flink.streaming.runtime.partitioner;
import org.apache.flink.annotation.Internal;
import org.apache.flink.runtime.plugable.SerializationDelegate;
import org.apache.flink.streaming.runtime.streamrecord.StreamRecord;
@Internal
public class ForwardPartitioner<T> extends StreamPartitioner<T> {
private static final long serialVersionUID = 1L;
@Override
public int selectChannel(SerializationDelegate<StreamRecord<T>> record) {
return 0;
}
public StreamPartitioner<T> copy() {
return this;
}
@Override
public String toString() {
return "FORWARD";
}
}2.6.2 图示说明
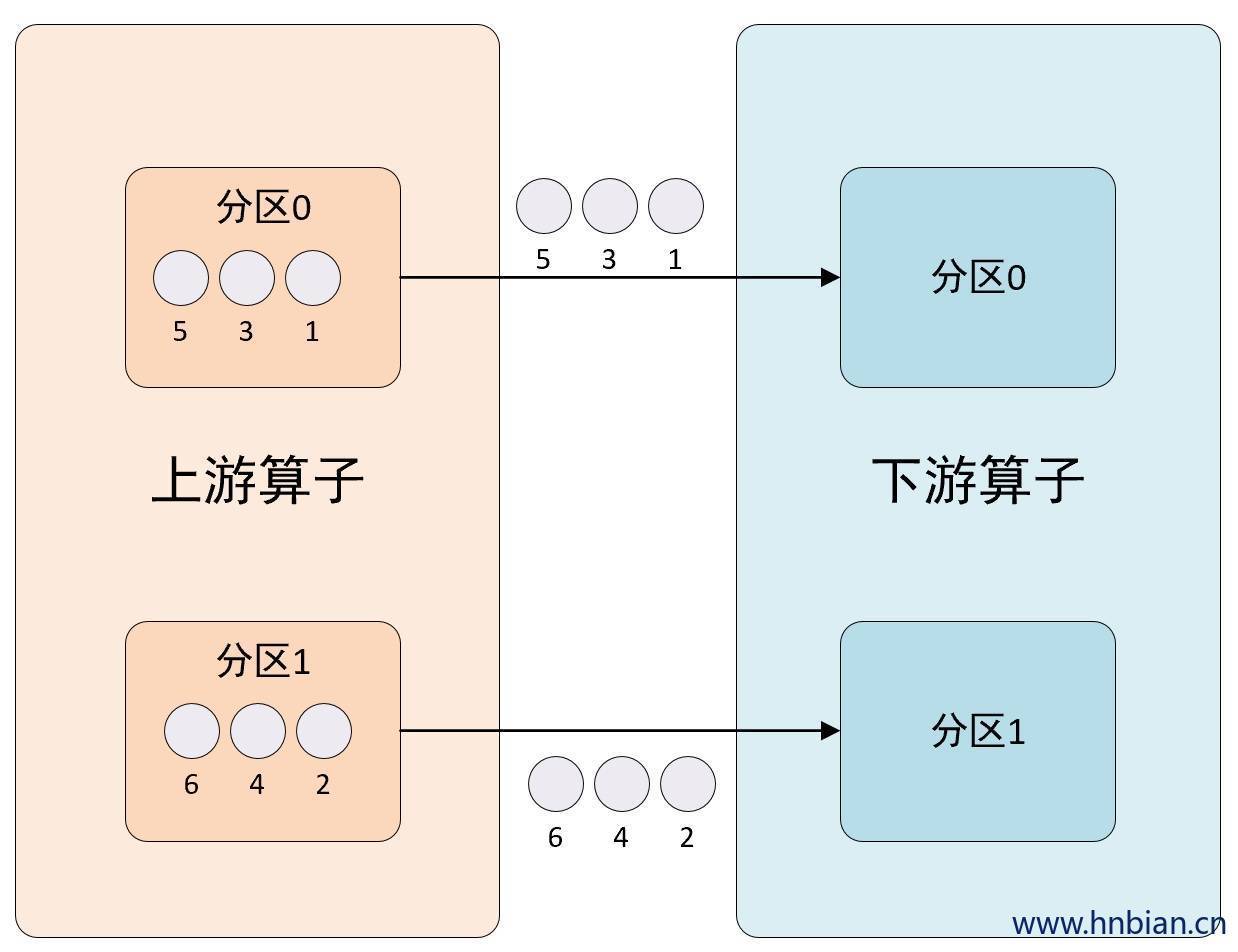
2.6.3 API 使用
import org.apache.flink.streaming.api.scala._
object TestForwardPartitioner extends App{
// 创建执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 从自定义的集合中读取数据
val stream = env.fromCollection(List(1,2,3,4,5))
// 直接打印数据
stream.map(v=>{v+1}).setParallelism(2).print().setParallelism(2)
/**
* 2> 2
* 1> 3
* 2> 4
* 1> 5
* 2> 6
*/
env.execute()
}
2.7 KeyGroupStreamPartitioner
KeyGroupStreamPartitioner是一种基于键组(Key Group)的数据分区策略。键组是 Flink 为了管理 keyed state 和进行故障恢复而设计的概念。一个 keyed state 由多个键组组成,每个键组对应一部分键的范围。
KeyGroupStreamPartitioner的分区策略是根据数据的键值计算出键组,然后根据键组的编号来决定将数据发送到哪个并行任务。每个并行任务管理一部分键组,因此,KeyGroupStreamPartitioner可以确保具有相同键的数据总是被发送到同一个并行任务。
这种分区策略在处理 keyed state 的操作,如键控流的操作或者有状态的窗口操作时非常有用。通过确保具有相同键的数据始终在同一个并行任务中处理,可以确保数据的一致性,并使得状态管理和故障恢复更加高效。
2.7.1 源码解析
package org.apache.flink.streaming.runtime.partitioner;
import org.apache.flink.annotation.Internal;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.runtime.plugable.SerializationDelegate;
import org.apache.flink.runtime.state.KeyGroupRangeAssignment;
import org.apache.flink.streaming.runtime.streamrecord.StreamRecord;
import org.apache.flink.util.Preconditions;
/**
* 通过 key 分区将数据发送到下游算子的分区中
* @param <T> Type of the elements in the Stream being partitioned
*/
@Internal
public class KeyGroupStreamPartitioner<T, K> extends StreamPartitioner<T> implements ConfigurableStreamPartitioner {
private static final long serialVersionUID = 1L;
private final KeySelector<T, K> keySelector;
private int maxParallelism;
public KeyGroupStreamPartitioner(KeySelector<T, K> keySelector, int maxParallelism) {
Preconditions.checkArgument(maxParallelism > 0, "Number of key-groups must be > 0!");
this.keySelector = Preconditions.checkNotNull(keySelector);
this.maxParallelism = maxParallelism;
}
public int getMaxParallelism() {
return maxParallelism;
}
@Override
public int selectChannel(SerializationDelegate<StreamRecord<T>> record) {
K key;
try {
key = keySelector.getKey(record.getInstance().getValue());
} catch (Exception e) {
throw new RuntimeException("Could not extract key from " + record.getInstance().getValue(), e);
}
// 调用KeyGroupRangeAssignment类的assignKeyToParallelOperator方法,返回应该发送的分区号码
return KeyGroupRangeAssignment.assignKeyToParallelOperator(key, maxParallelism, numberOfChannels);
}
@Override
public StreamPartitioner<T> copy() {
return this;
}
@Override
public String toString() {
return "HASH";
}
@Override
public void configure(int maxParallelism) {
KeyGroupRangeAssignment.checkParallelismPreconditions(maxParallelism);
this.maxParallelism = maxParallelism;
}
}/**
* 将指定的key 分配给指定的 operator index
*
* @param key key 值
* @param maxParallelism 最大并行度
* @param parallelism 当前算子并行度
* @return the index of the parallel operator to which the given key should be routed.
*/
public static int assignKeyToParallelOperator(Object key, int maxParallelism, int parallelism) {
Preconditions.checkNotNull(key, "Assigned key must not be null!");
// 调用 computeOperatorIndexForKeyGroup 方法
return computeOperatorIndexForKeyGroup(maxParallelism, parallelism, assignToKeyGroup(key, maxParallelism));
}/**
* 在给定的并行度和最大并行度下计算键组所属的运算符的索引。
* 重要说明:maxParallelism必须为<= Short.MAX_VALUE,以避免此方法中的舍入问题。
* 如果我们想超越此界限,则此方法必须对长值执行算术运算。
*
* @param maxParallelism 最大并行度
* 0 < parallelism <= maxParallelism <= Short.MAX_VALUE must hold.
* @param parallelism 当前作业并行度. Must be <= maxParallelism.
* @param keyGroupId Key 分区 ID. 0 <= keyGroupID < maxParallelism.
* @return 返回分区号 在
*/
public static int computeOperatorIndexForKeyGroup(int maxParallelism, int parallelism, int keyGroupId) {
// 计算数据发送到哪个分区
return keyGroupId * parallelism / maxParallelism;
}2.7.2 图示说明
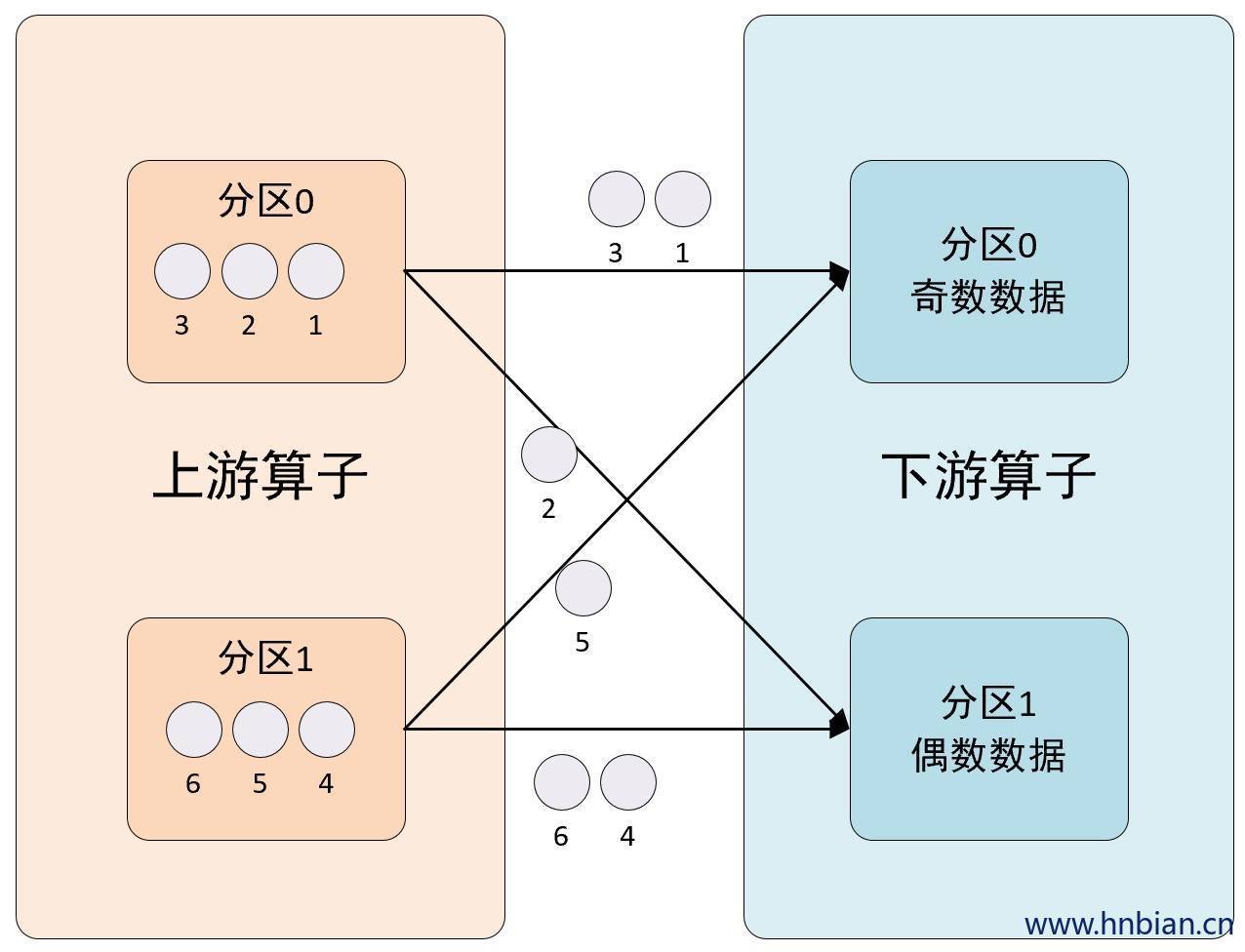
2.7.3 API 使用
import org.apache.flink.streaming.api.scala._
/**
* @Author haonan.bian
* @Description //TODO
* @Date 2020/12/31 16:23
**/
object TestKeyGroupStreamPartitioner extends App{
// 创建执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 从自定义的集合中读取数据
val stream = env.fromCollection(List(1,2,3,4,5,6))
val stream2 = stream.map(v=>{(v%2,v)})
stream2.setParallelism(2).keyBy(_._1).print("key")
env.execute()
}2.8 CustomPartitionerWrapper
通过Partitioner实例的partition方法,可以实现自定义的将记录输出到下游指定分区中。
2.8.1 源码解析
package org.apache.flink.streaming.runtime.partitioner;
import org.apache.flink.annotation.Internal;
import org.apache.flink.api.common.functions.Partitioner;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.runtime.plugable.SerializationDelegate;
import org.apache.flink.streaming.runtime.streamrecord.StreamRecord;
/**
* 自定义分区方式
* @param <K>
* Type of the key
* @param <T>
* Type of the data
*/
@Internal
public class CustomPartitionerWrapper<K, T> extends StreamPartitioner<T> {
private static final long serialVersionUID = 1L;
Partitioner<K> partitioner;
KeySelector<T, K> keySelector;
public CustomPartitionerWrapper(Partitioner<K> partitioner, KeySelector<T, K> keySelector) {
this.partitioner = partitioner;
this.keySelector = keySelector;
}
@Override
public int selectChannel(SerializationDelegate<StreamRecord<T>> record) {
K key;
try {
key = keySelector.getKey(record.getInstance().getValue());
} catch (Exception e) {
throw new RuntimeException("Could not extract key from " + record.getInstance(), e);
}
//实现Partitioner接口,重写partition方法
return partitioner.partition(key, numberOfChannels);
}
@Override
public StreamPartitioner<T> copy() {
return this;
}
@Override
public String toString() {
return "CUSTOM";
}
}2.8.2 测试 API
import org.apache.flink.api.common.functions.Partitioner
import org.apache.flink.streaming.api.scala._
/**
* @Author haonan.bian
* @Description //TODO
* @Date 2020/12/31 16:36
**/
object CustomPartitioner extends Partitioner[String]{
override def partition(key: String, numPartitions: Int): Int = {
// 根据 key值的 奇偶 返回到不同的分区
key.toInt % 2
}
}
object TestCustomPartitioner extends App{
// 创建执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 从自定义的集合中读取数据
val stream = env.fromCollection(List("1","2","3","4","5"))
val partitioner = CustomPartitioner
val stream2 = stream.map(value=>{((value.toInt%2).toString,value)})
stream2.partitionCustom(partitioner,0).print().setParallelism(2)
/**
* 1> (0,2)
* 1> (0,4)
* 2> (1,1)
* 2> (1,5)
* 2> (1,3)
*/
env.execute()
}
3. 任务链(Operator Chains)
- flink 采用了一种称为任务链的优化技术,可以在特定条件下减少本地通信的开销。为了满足任务链的要求,必须将两个及以上的算子设为相同的并行度,并通过本地转发(local forward)的方式进行连接。
- 将算子合并为任务链有两个必须条件 : 1. 算子的并行度相同 2. 合并任务链的算子都是 one-to-one 算子
- 算子合并为任务链之后,原来的算子成为里面的 subtask
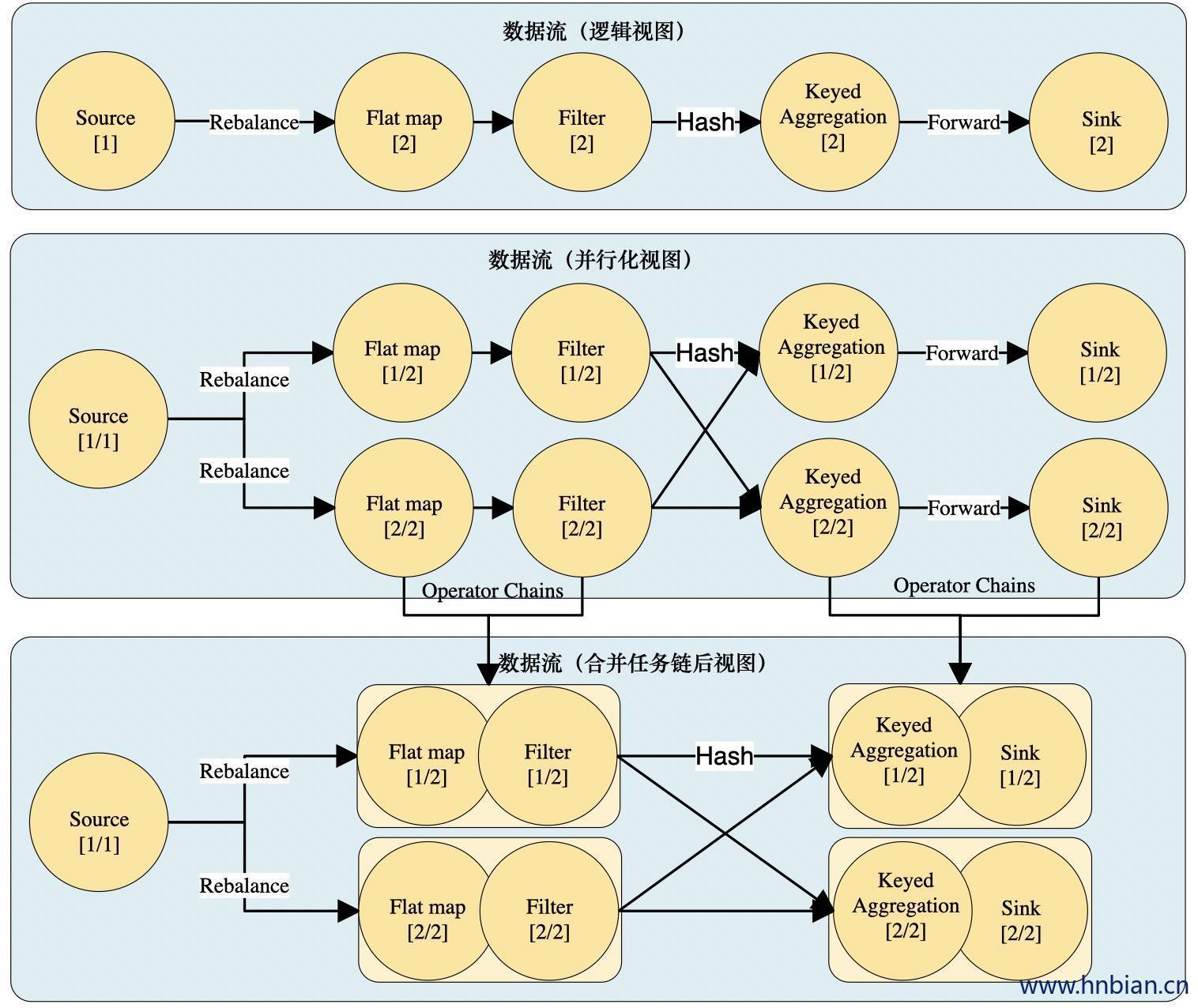
3.1 禁止 任务链合并
// 禁止全局任务链合并
env.disableOperatorChaining()
// 禁止某个算的的任务链合并
filter().disableChaining()
// 断开前面的任务链并开始一个新的任务链
filter().startNewChain()
