1. 程序与数据流
- 所有的 Flink 程序都是由三部分组成:Source、Transformation和 Sink。
- Source 负责读取数据源
- Transformation 负责利用各种算子加工数据
- Sink 负责将数据输出
- 在程序运行时,Flink 上运行的程序会被映射成”逻辑数据流” (dataflows),它包含了这三部分。
- 每个 dataflow 以一个或多个 Source 开始 并以一个或多个 Sink 结束。dataflow 类似于任意的有向无环图(DAG)。
- 大部分情况下,程序中的转换(transformations) 和dataflow 中的算子(operator)是一一对应的关系。
1.1 执行环境
创建一个执行环境,表示当前执行程序的上下文,
如果程序是独立调用的,则此方法返回本地执行环境,
如果从命令行客户端调用程序以提交到集群,则此方法会返回集群的执行环境,
getExecutionEnviroment 会根据查询运行的方式返回执行环境是最常用的一种创建执行环境的方式。
如果没有设置并行度,flink 会以flink-conf.yaml中的配置为准,默认为 1
创建流计算执行环境
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment- 创建批计算执行环境
import org.apache.flink.api.scala._
var env:ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment- 创建本地执行环境
// 返回本地执行环境,在调用时需要指定并行度
val env = StreamExecutionEnvironment.createLocalEnvironment(1)- 创建远程执行环境
// 返回集群执行环境,将运行 jar 提交到远程服务器,需要在调用时指定 JobManager 的 IP 与端口号,
// 并执行在集群上运行的 jar 文件
val env = ExecutionEnvironment.createRemoteEnvironment("hostname","port","path/*.jar")
// 端口默认 61231.2 数据流类型
1.2.1 DataStream
DataStream 是 Flink 流处理 API 中最核心的数据结构。它代表了一个运行在多个分区上的并行流。DataStream 可以从 StreamExecutionEnvironment 通过 env.addSource(SourceFunction) 获得。
DataStream 上的转换操作都是逐条的,比如 map() , flatMap()
,filter()。DataStream 也可以执行Rebalance`(再平衡,用来减轻数据倾斜)和 Broadcast(广播)等分区转换。在下一篇会详细介绍 Rebalance 和 Broadcast
1.2.2 KeyedStream
- 通过调用
DataStream.keyBy()可以得到KeyedStream数据流。 KeyedStream用来表示根据指定的key进行分组的数据流。- 在
KeyedStream上进行任何 transformation 都将转变回DataStream。在实现中,KeyedStream是把key的信息写入到了transformation中。每条记录只能访问所属key的状态,其上的聚合函数可以方便地操作和保存对应key的状态。
1.2.3 ConnectedStreams
- 通过
DataStream.connect(OtherDataStream)可以得到一个 ConnectedStreams 数据流。
ConnectedStreams 是将 DataStream合并后得到的流,而在 Flink 还提供 union 算子用来合并多个流,他们两个去区别如下:
- 类型限制:union 所有合并的流的类型必须是一致的,ConnectedStreams合并的流类型可以是不一致的。
- 合并流的数量:union 可以连接多个流,ConnectedStreams 只能连接两个流。
- 处理数据的方法:union 合并的流处理数据时使用的方法作用于所有数据,ConnectedStreams会对两个流的数据应用不同的处理方法,并且双流之间可以共享状态。
如下 ConnectedStreams 的样例,连接 input 和 other 流,并在input流上应用map1方法,在other上应用map2方法,双流可以共享状态(比如计数)。
DataStream[MyType] input = ...
DataStream[AnotherType] other = ...
ConnectedStreams[MyType, AnotherType] connected = input.connect(other)
DataStream[ResultType] result = connected.map(new CoMapFunction[MyType, AnotherType, ResultType]() {
override def map1(value: MyType): ResultType = { ... }
override def map2(value: AnotherType): ResultType = { ... }
})1.2.4 WindowedStream & AllWindowedStream
WindowedStream都是从KeyedStream衍生而来的,并且基于WindowAssigner切分窗口的数据流。- 在
WindowedStream上进行任何transformation也都将转变回DataStream。 WindowedStream会将到达的数据缓存在对应的窗口buffer中(一个数据可能会对应多个窗口)。- 当到达窗口发送的条件时(由Trigger控制),Flink 会对整个窗口中的数据进行处理。
- Flink 在聚合类窗口有一定的优化,即不会保存窗口中的所有值,而是每到一个元素执行一次聚合函数,最终只保存一份数据。
- AllWindowedStream 的实现是基于 WindowedStream 的。
AllWindowedStream是直接在DataStream上进行windowAll(...)操作。- Flink 不推荐使用
AllWindowedStream,因为在普通流上进行窗口操作,就势必需要将所有分区的流都汇集到单个的Task中,而这个单个的Task很显然就会成为整个Job的瓶颈
1.2.5 JoinedStreams & CoGroupedStreams
CoGroupedStreams:侧重的是group,是对同一个key上的两组集合进行操作。
JoinedStreams:侧重的是pair,是对同一个key上的每对元素进行操作
JoinedStreams 只是 CoGroupedStreams 的一个特例。
JoinedStreams 和 CoGroupedStreams 是基于 Window 上实现的,所以 CoGroupedStreams 最终又调用了 WindowedStream 来实现。
1.2.6 SplitStream
- DataStream 调用 split(expr)算子会通过指定条件得到一个SplitStream数据流。
- SplitStream 将一个DataStream划分成多个流。
- SplitStream 调用 select(streamName)算子会得到一个 DataStream数据流。
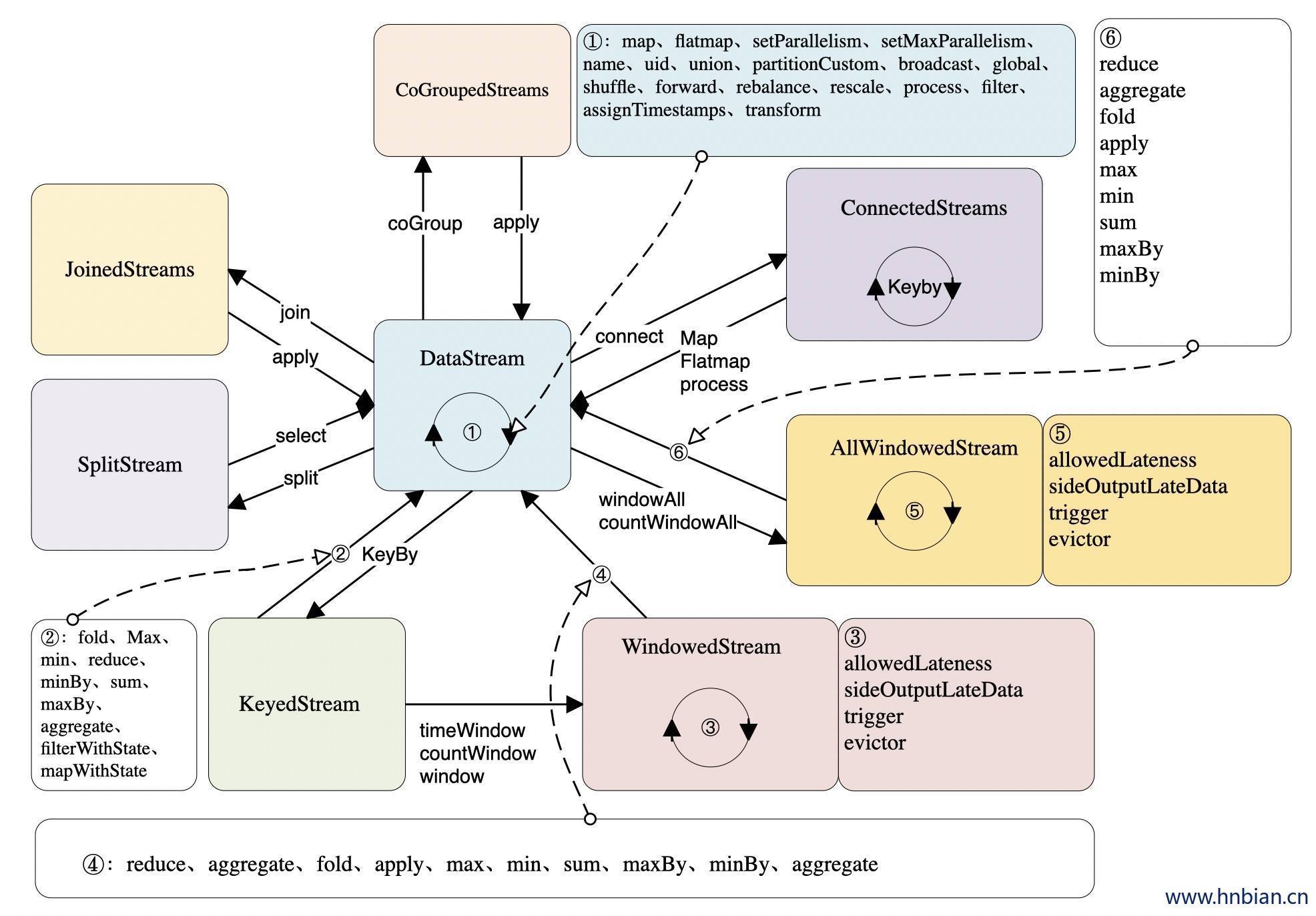
1.3 Flink 中数据流相互转换关系
Flink 为流处理提供了多种 DataStream API。正是这种高层的抽象的 API 极大地便利了用户编写大数据应用。所以本文将介绍Flink 中几种关键的数据流类型,它们之间是如何通过转换关联起来的。下图展示了 Flink 中目前支持的主要几种流的类型,以及它们之间的转换关系。
2. Source介绍
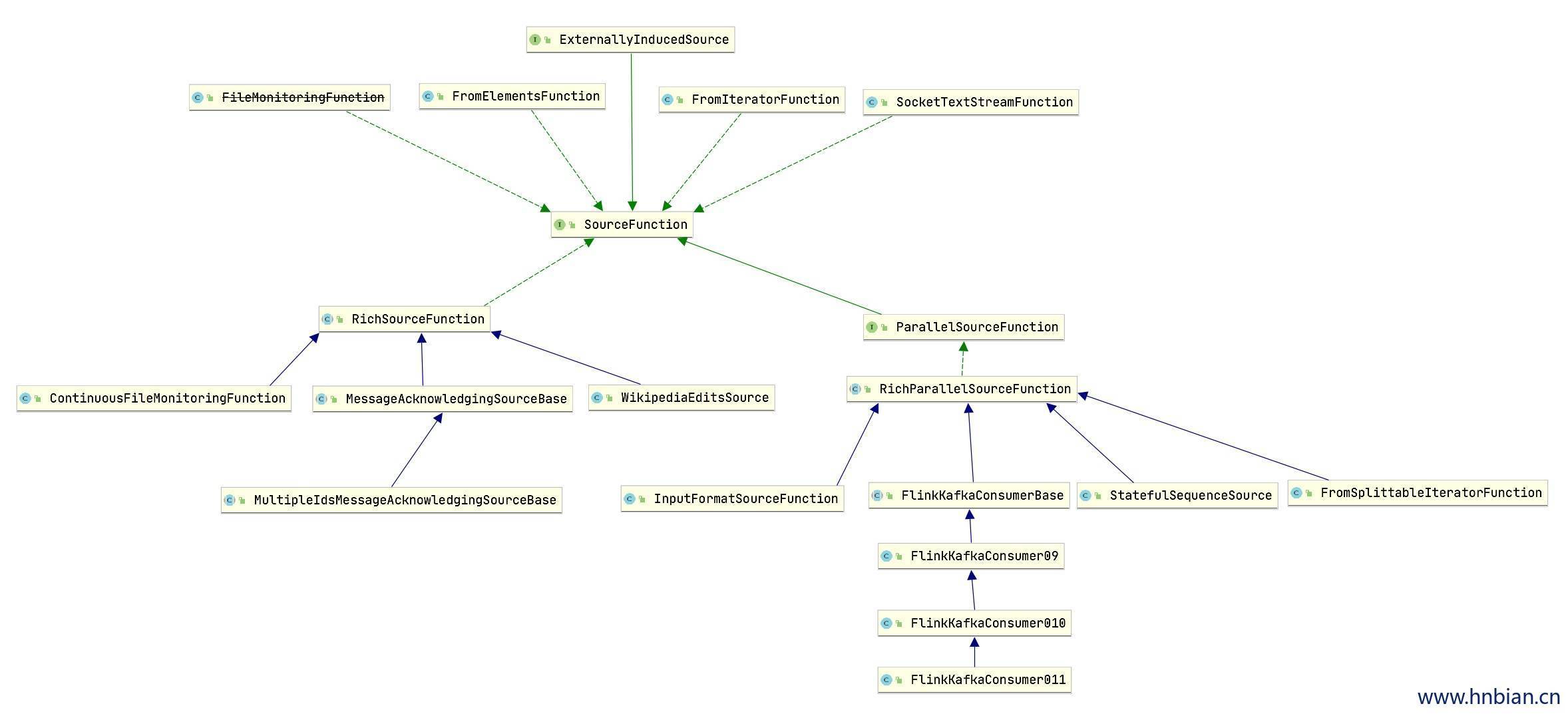
Flink Data Sources 是什么呢?就字面意思其实就可以知道:数据来源。
Flink 做为一款流式计算框架,它可用来做批处理,即处理静态的数据集、历史的数据集,也可以用来做流处理,即实时的处理些实时数据流,实时的产生数据流结果,只要数据源源不断的过来,Flink 就能够一直计算下去,这个 Data Sources 就是数据的来源地。
Flink 中你可以使用 StreamExecutionEnvironment.addSource(sourceFunction) 来为你的程序添加数据来源。
Flink 已经提供了若干实现好了的 source functions,当然你也可以通过实现 SourceFunction 来自定义非并行的 source 或者实现 ParallelSourceFunction 接口或者扩展 RichParallelSourceFunction 来自定义并行的 source。
2.1 从集合中读取数据
package com.hnbian.flink.source
import org.apache.flink.streaming.api.scala._
object SourceTestList {
// 定义数据模型样例类
case class Record(number: Int,value:String)
def main(args: Array[String]): Unit = {
// 创建执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 从自定义的集合中读取数据
val stream = env.fromCollection(List(
Record(1,"hello"),
Record(1,"world")
))
val stream2 = stream.map(record=>{
Record(record.number*100,record.value+"_map")
})
stream2.print("record").setParallelism(1)
/**
* record> Record(100,world_map)
* record> Record(100,hello_map)
*/
// 从 不同的元素 中读取数据
val stream3 = env.fromElements(1,2,3,"hello","world")
stream3.print()
/**
* 前面的数字是线程编号
*
* 9> world
* 5> 1
* 7> 3
* 6> 2
* 8> hello
*/
env.execute()
}
}2.2 文件作为数据源读取数据
package com.hnbian.flink.source
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
object SourceTestFile {
def main(args: Array[String]): Unit = {
// 创建执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 从文本中读取数据
val stream = env.readTextFile("/opt/apache-maven-3.6.0/conf/settings.xml")
stream.print()
env.execute()
}
}
2.3 Kafka 作为数据源读取数据
- 首先添加依赖
<dependency>
<!--kafka 版本 0.11, scala 版本 2.11 -->
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.11_2.11</artifactId>
<version>1.10.0</version>
</dependency>
package com.hnbian.flink.source
import java.util.Properties
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer011
object SourceTestKafka {
def main(args: Array[String]): Unit = {
// 创建执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
val properties = new Properties()
val topic = "text"
properties.setProperty("bootstrap.servers","node1:9092")
properties.setProperty("group.id","consumer-group1")
properties.setProperty("key.deserializer","org.apache.kafka.common.serialization.StringDeserializer")
properties.setProperty("value.deserializer","org.apache.kafka.common.serialization.StringDeserializer")
properties.setProperty("auto.offset.reset","latest")
val stream = env.addSource(
new FlinkKafkaConsumer011[String](topic,new SimpleStringSchema(),properties)
)
// flink 消费数据可以把消费数据的 offset 作为状态保存起来
// 恢复数据时可以将 offset 设置为恢复数据的位置。
stream.print()
env.execute()
}
}
2.4 自定义 source (随机数 Source)
除了上面的数据源我们还可以自定义 source,需要做的就是定义一个类, 继承SourceFunction。
val stream = env.addSource(new MySource())这里定义一个生成随机数的 source
package com.hnbian.flink.source
import org.apache.flink.streaming.api.functions.source.SourceFunction
import org.apache.flink.streaming.api.scala._
import scala.util.Random
object SourceTestRandom{
def main(args: Array[String]): Unit = {
// 创建执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream = env.addSource(new SourceRandom())
stream.print()
/**
* 7> 0.3922027730456249
* 8> 0.6396968318646995
* 9> 0.4301654052412155
* 10> 0.8927365619289196
*/
env.execute()
}
}
/**
* 自定义的数据源,生成随机数
* 需要继承 SourceFunction 接口并实现run、cancel两个方法
*/
class SourceRandom() extends SourceFunction[Double]{
// 状态标识,标识 source 是否正在运行
var isRunning:Boolean = true
/**
* 执行当前数据源的方法,生成数据
*/
override def run(sourceContext: SourceFunction.SourceContext[Double]): Unit = {
// 初始化一个随机数生成器
val rand = new Random()
while(isRunning){
sourceContext.collect(rand.nextDouble())
Thread.sleep(500)
}
}
/**
* 取消当前数据源的方法,停止生成数据
*/
override def cancel(): Unit = {
isRunning = false
}
}3.常用的 Transform 算子
3.1 setParallelism
设置并行度
task的parallelism可以在Flink的不同级别上指定
算子上面设置的并行度优先级高于执行环境设置的并行度
def setParallelism(env:StreamExecutionEnvironment): Unit ={
val stream1:DataStream[Integer] = env.fromElements(1,2,3,4)
stream1.map(v=>v).setParallelism(3).print("setParallelism").setParallelism(2)
// setParallelism:1> 4
// setParallelism:2> 3
// setParallelism:2> 1
// setParallelism:1> 2
}
3.2 setMaxParallelism
最大并行度可以在设置并行度的地方设定(除了客户端和系统层次)。不同于调用setParallelism()方法, 你可以通过调用setMaxParallelism()方法来设定最大并行度。
默认的最大并行度大概等于‘算子的并行度+算子的并行度/2’,其下限为1而上限为32768。
注意 设置最大并行度到一个非常大的值将会降低性能因为一些状态的后台需要维持内部的数据结构,而这些数据结构将会随着key-groups的数目而扩张(key-groups 是rescalable状态的内部实现机制)。
def setMaxParallelism(env:StreamExecutionEnvironment): Unit ={
val stream1:DataStream[Integer] = env.fromElements(1,2,3,4)
stream1.map(v=>v).setMaxParallelism(30000000)
.print("setMaxParallelism")
}
// throws exception Maximum parallelism must be between 1 and 32768. Found: 300000003.3 map
遍历 DataStream 中的元素,并在元素中应用指定函数生成新的DataStream。
val stream1:DataStream[String] = env.fromElements("hello", "world")
val stream2:DataStream[String] = stream1.map(v => {
v + "-map"
})
stream2.print("map")
// map> hello-map
// map> world-map
3.4 flatmap
通过将给定的函数应用在每个元素上,并将压扁的结果创建一个新的DataStream
val stream1:DataStream[String] = env.fromElements("hello world", "flink demo")
val stream2:DataStream[String]= stream1.flatMap(v => {
v.split(" ")
})
stream2.print("flatMap")
// flatMap> hello
// flatMap> world
// flatMap> flink
// flatMap> demo3.5 filter
创建一个只包含满足给定的过滤谓词元素的DataStream
def filter(env:StreamExecutionEnvironment): Unit ={
val stream1:DataStream[Integer] = env.fromElements(1,2,3,4,5,6,7)
val stream2:DataStream[Integer]= stream1.filter(v => {
v > 5
})
stream2.print("filter")
// filter> 6
// filter> 7
}
3.6 union
将多个类型相同的 DataStream 合并成一个 DataStream
注意 DataStream 中的数据类型要一致 才可以做 union 操作
def union(env:StreamExecutionEnvironment): Unit ={
val stream1:DataStream[Integer] = env.fromElements(1,2)
val stream2:DataStream[Integer] = env.fromElements(3,4)
val stream3:DataStream[Integer] = env.fromElements(5,6)
val stream4:DataStream[Integer] = stream1.union(stream2,stream3)
stream4.print("union")
// union> 3
// union> 4
// union> 5
// union> 6
// union> 1
// union> 2
}
3.7 name
/**
* 设置当前数据流的名称。
* 绑定到数据源上的 name 属性是为了调试方便,
* 如果发生一些异常,我们能够通过它快速定位问题发生在哪里。
* @param env
*/
def name(env:StreamExecutionEnvironment): Unit ={
val stream1:DataStream[Integer] = env.fromElements(1,2,3,4,5,6,7)
stream1.name("stream1")
stream1.print()
}
3.8 uid
/**
* 用户指定的uid,该uid的主要目的是用于在job重启时可以再次分配跟之前相同的uid,应该是用于持久保存状态的目的。
* 指定的ID用于在整个作业中分配相同的操作员ID提交
* 此ID必须是唯一的 否则,作业提交将失败。
*
* @param env
*/
def uid(env:StreamExecutionEnvironment): Unit ={
val stream1:DataStream[Integer] = env.fromElements(1,2,3,4,5,6,7)
stream1.uid("source-1")
}
3.9 split 与 select
- split 算子:将 DataStream 拆分成多个 DataStream
- select算子:在SplitStream 中获取一个 DataStream
import org.apache.flink.streaming.api.scala._
/**
* @Author haonan.bian
* @Description //TODO
* @Date 2020/8/6 16:43
**/
object SplitStreamTest {
def main(args: Array[String]): Unit = {
// 创建执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream1:DataStream[Integer] = env.fromElements(1,2,3,4)
// 使用 split 算子将 DataStream 拆分成多个 DataStream
val stream2:SplitStream[Integer] = stream1.split(v=>{
if(v % 2 == 0){
Seq("even")
}else{
Seq("odd")
}
})
stream2.print("SplitStream")
// SplitStream:9> 1
// SplitStream:10> 2
// SplitStream:11> 3
// SplitStream:12> 4
// 使用 select 算子 在SplitStream 中获取一个 DataStream
val Stream3:DataStream[Integer] = stream2.select("odd")
Stream3.print("odd")
// odd:5> 3
// odd:4> 1
stream2.select("even").print("even")
// even:6> 4
// even:5> 2
env.execute()
}
}3.10 side output
DataStream 可以使用 side output 产生一个或多个结果数据流。输入与输出流中的数据类型匹配,并且不同侧输出的类型也可以不同。当拆分数据流时,通常必须复制该流,然后从每个流中过滤掉不需要的数据。
def sideOutput(env: StreamExecutionEnvironment): Unit = {
val input: DataStream[Int] = env.fromElements(1, 2, 3, 4)
// 定义 output tag 用于标识输出流
val evenTag = OutputTag[Int]("even")
val oddTag = OutputTag[String]("odd")
import org.apache.flink.util.Collector
import org.apache.flink.streaming.api.functions.ProcessFunction
val mainDataStream =
input.process(new ProcessFunction[Int, Int] {
override def processElement(
value: Int,
ctx: ProcessFunction[Int, Int]#Context,
out: Collector[Int]): Unit = {
// 分流逻辑,分为奇数、偶数两个流
if (value % 2 == 0) {
ctx.output(evenTag, value)
} else {
ctx.output(oddTag, String.valueOf(s"odd-$value"))
}
}
})
val evenOutputStream: DataStream[Int] = mainDataStream.getSideOutput(evenTag)
evenOutputStream.print("even")
// even:11> 2
// even:1> 4
val oddOutputStream: DataStream[String] = mainDataStream.getSideOutput(oddTag)
oddOutputStream.print("odd")
// odd:7> odd-1
// odd:9> odd-3
}
3.11 keyBy
/**
* dataStream 转换为 KeyedStream
* @param env
*/
def dataStreamToKeyedStream(env:StreamExecutionEnvironment): Unit ={
val stream1:DataStream[String] =
env.fromElements ("hello world","how are you","hello flink","flink datastream")
import org.apache.flink.streaming.api.scala.KeyedStream
import org.apache.flink.api.java.tuple.Tuple
val stream2:scala.KeyedStream[(String, Int), Tuple] = stream1
.flatMap(v=>{v.split(" ")})
.map((_,1))
.keyBy(0)
stream2.print("KeyedStream")
// KeyedStream> (hello,1)
// KeyedStream> (world,1)
// KeyedStream> (how,1)
// KeyedStream> (are,1)
// KeyedStream> (you,1)
// KeyedStream> (hello,1)
// KeyedStream> (flink,1)
// KeyedStream> (flink,1)
// KeyedStream> (datastream,1)
}
}
3.12 函数类
Flink 中暴露了所有的 udf 函数的接口(实现方式为接口或实现类),例如 MapFunction、FilterFunction、ProcessFunction 等。
def filter1(env:StreamExecutionEnvironment): Unit ={
val stream: DataStream[Int] = env.fromElements(1, 2, 3, 4, 5)
stream.filter(new MyFilterFunction).print("MyFilterFunction")
// MyFilterFunction> 4
// MyFilterFunction> 5
}
// 实现自定义 UDF
class MyFilterFunction() extends FilterFunction[Int](){
override def filter(value: Int): Boolean = {
value > 3
}
}
3.13 匿名函数
def filter2(env:StreamExecutionEnvironment): Unit ={
val stream: DataStream[Int] = env.fromElements(1, 2, 3, 4, 5)
stream.filter(new FilterFunction[Int] {
override def filter(value: Int): Boolean = {
value>3
}
}).print("anonymous")
// anonymous> 4
// anonymous> 5
}
3.14 富函数
RichFunction (富函数) 是 DataStreamAPI提供的一个函数l类的接口,所有 Flinkh函数都有 RIch 版本,RichFunction 与常规函数的区别在于可以获取运行环境的上下文,并拥有一些生命周期的方法,可以实现更复杂的功能
RichFunction 有一个生命周期的概念,典型的生命周期有下面几个方法:
- open 方法:RichFunction的初始化方法,当一个算子(如 map、filter)在调用之前会先调用 open 方法。
- close方法:RichFunction的最后执行的化方法,做一些清理工作。
- getRuntimeContext方法:提供了函数 RuntimeContext 的一些信息,例如函数执行的并行度、函数的名称、以及 state 状态等等。
3.14.1 RichFunction 接口源码
package org.apache.flink.api.common.functions;
import org.apache.flink.annotation.Public;
import org.apache.flink.configuration.Configuration;
/**
* 所有丰富的用户定义功能的基本接口。
* 此类定义了函数生命周期的方法,以及访问在其中执行函数的上下文的方法
*/
public interface RichFunction extends Function {
/**
* 该函数的初始化方法。 在实际的工作方法(例如map或join )之前调用它,因此该方法只执行一次。
* 默认情况下,此方法不执行任何操作
* @param parameters 配置参数
*
*/
void open(Configuration parameters) throws Exception;
/**
* 在方法执行完成之后执行,可做清理工作,如关闭数据库连接等。
*/
void close() throws Exception;
/**
* 获取上下文,该上下文包含有关UDF运行时的信息,例如函数的并行性,函数的子任务索引或执行函数的任务的名称
*
* @return The UDF's runtime context.
*/
RuntimeContext getRuntimeContext();
/**
* 获取RuntimeContext的专用版本,该版本具有有关执行函数的迭代的其他信息。
* 仅当函数是迭代的一部分时,此IterationRuntimeContext才可用。 否则,此方法将引发异常
*/
IterationRuntimeContext getIterationRuntimeContext();
/**
* 设置函数的运行时上下文。 在创建函数的并行实例时由框架调用。
* @param t The runtime context.
*/
void setRuntimeContext(RuntimeContext t);
}3.14.2 RichFunction 使用示例
def richMap(env:StreamExecutionEnvironment): Unit ={
val stream: DataStream[Int] = env.fromElements(1, 2, 3, 4, 5)
stream.map(new MyRichMapFunction(5)).print("richMap")
// 首先执行 open
// richMap> 5
// richMap> 10
// richMap> 15
// richMap> 20
// richMap> 25
// 最后执行 close
}
/**
* 富函数
* @param i
* RichMapFunction[Int,Int] 两个类型分别为输入输出类型
*/
class MyRichMapFunction(i:Int) extends RichMapFunction[Int,Int](){
override def open(parameters: Configuration): Unit = {
println("首先执行 open")
// 可以进行获取数据库连接等初始化操作
}
override def map(value: Int): Int = {
// val context = this.getRuntimeContext
// println(s"taskName${context.getTaskName}")
value * i
}
override def close(): Unit = {
println("最后执行 close")
// 可以进行关闭数据库连接等清理操作
}
}
4. Sink 介绍
Flink 中没有类似于 Spark 中的 freach 的方法,让用户进行迭代的操作,所有对外输出操作都要使用 Sink 完成,通过类似如下方法完成整个任务的最终输出操作
stream.addSink(new MySink(...))
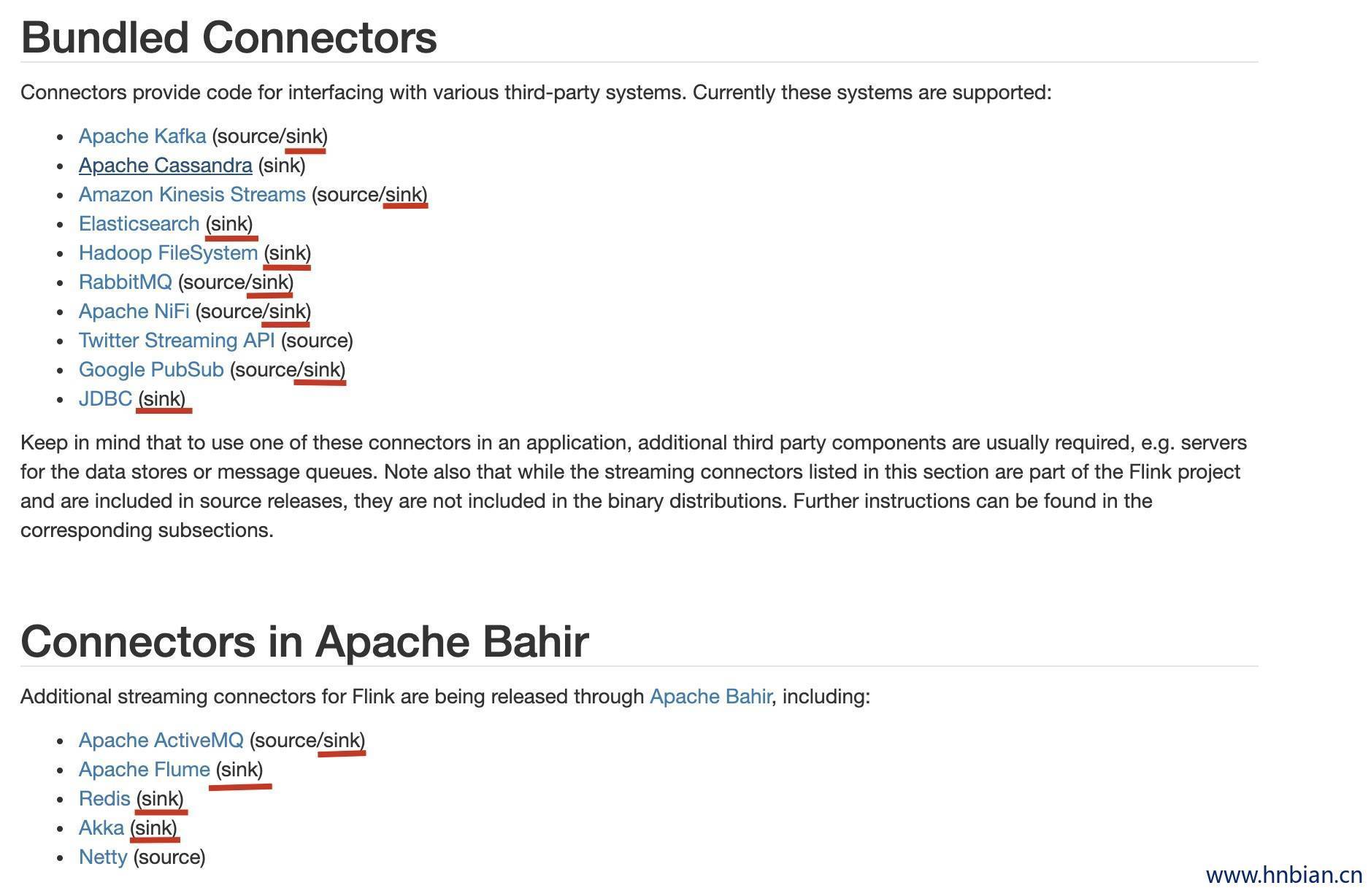
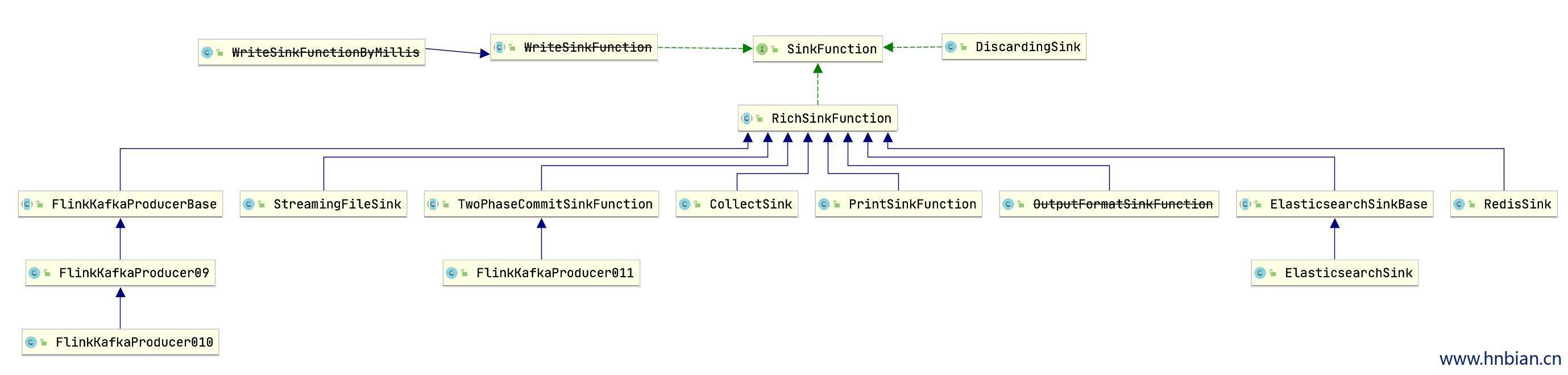
Flink 官方提供了一部分框架的 Sink,除此之外如果不满足需求,就需要用户实现自定义的 Sink。
Flink 官方提供的 Sink
4.1 ElasticSearch Sink
package com.hnbian.flink.sink
import java.util
import org.apache.flink.api.common.functions.RuntimeContext
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.connectors.elasticsearch.{ElasticsearchSinkFunction, RequestIndexer}
import org.apache.flink.streaming.connectors.elasticsearch6.ElasticsearchSink
import org.apache.http.HttpHost
import org.elasticsearch.client.Requests
import scala.collection.mutable.ArrayBuffer
object ESSink {
def main(args: Array[String]): Unit = {
// 创建执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val stream = env.readTextFile("/opt/apache-maven-3.6.0/conf/settings.xml")
val httpHosts = new util.ArrayList[HttpHost]()
httpHosts.add(new HttpHost("node1",9200))
// 创建 es sink 的 builder
val esSinkBuilder = new ElasticsearchSink.Builder[String](
httpHosts,
new ElasticsearchSinkFunction[String] {
/**
* 发送数据的方法
* @param t 要发送的数据
* @param runtimeContext 上下文
* @param requestIndexer 发送操作请求
*/
override def process
(t: String, runtimeContext: RuntimeContext, requestIndexer: RequestIndexer): Unit = {
// 将数据包装成json或者Map
val map = new java.util.HashMap[String,String]()
map.put(t.length.toString,t.toString)
// 创建 index request 准备发送数据
val indesRequest = Requests.indexRequest()
.index("data_length")
.`type`("flinkData")
.source(map)
// 使用 requestIndexer 发送 HTTP 请求保存数据
requestIndexer.add(indesRequest)
}
})
stream.addSink(esSinkBuilder.build())
env.execute("ESSink")
}
}
4.2 Kafka Sink
package com.hnbian.flink.sink
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer011
object KafkaSink {
def main(args: Array[String]): Unit = {
val brokers = "node1;992,node2:9092,node3:9093"
val topic = "flink"
// 创建执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val stream = env.readTextFile("/opt/apache-maven-3.6.0/conf/settings.xml")
stream.addSink(new FlinkKafkaProducer011[String](brokers,topic,new SimpleStringSchema()))
env.execute("kafka sink ")
}
}4.3 Redis Sink
package com.hnbian.flink.sink
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer011
import org.apache.flink.streaming.connectors.redis.RedisSink
import org.apache.flink.streaming.connectors.redis.common.config.FlinkJedisPoolConfig
import org.apache.flink.streaming.connectors.redis.common.mapper.{RedisCommand, RedisCommandDescription, RedisMapper}
object RedisSink {
def main(args: Array[String]): Unit = {
// 创建执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val stream = env.readTextFile("/opt/apache-maven-3.6.0/conf/settings.xml")
val config = new FlinkJedisPoolConfig.Builder()
.setHost("localhost")
.setPort(6379)
.build()
stream.addSink(new RedisSink[String](config,new Mapper))
env.execute("Redis sink ")
}
}
/**
* 定义发送数据的 Mapper
*/
class Mapper() extends RedisMapper[String]{
/**
* 定义保存数据到 Redis 的命令
* @return
*/
override def getCommandDescription: RedisCommandDescription = {
// 将数据保存成哈希表 k->v
new RedisCommandDescription(RedisCommand.HSET,"data_length")
}
/**
* 定义保存到 Redis 的key
* @param t
* @return
*/
override def getKeyFromData(t: String): String =t.length.toString
/**
* 定义保存到 Redis 的value
* @param t
* @return
*/
override def getValueFromData(t: String): String = t
}4.4 自定义 Sink (JdbcSink)
package com.hnbian.flink.sink
import java.sql.{Connection, Driver, DriverManager, PreparedStatement}
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.functions.sink.{RichSinkFunction, SinkFunction}
import org.apache.flink.streaming.api.scala._
object JDBCSink {
def main(args: Array[String]): Unit = {
// 创建执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val stream = env.readTextFile("/opt/apache-maven-3.6.0/conf/settings.xml")
val stream2 = stream.flatMap(_.split(" "))
.filter(v=>{
v.length> 5 && v.contains("a")
})
.map((_,1))
.keyBy(0)
.sum(1)
stream2.addSink(new JDBCSink())
env.execute("jdbc sink")
}
}
class JDBCSink() extends RichSinkFunction[(String,Int)](){
val url = "jdbc:mysql://**:3306/mydb"
val uname = "root"
val pwd = "**"
// 建立连接
var conn:Connection = _
var insertStmt:PreparedStatement = _
var updateStmt:PreparedStatement = _
// 预编译
// 调用连接执行 SQL
override def invoke(value: (String,Int), context: SinkFunction.Context[_]): Unit = {
updateStmt.setInt(1,value._2)
updateStmt.setString(2,value._1)
updateStmt.execute()
if(updateStmt.getUpdateCount == 0 ){
insertStmt.setString(1,value._1)
insertStmt.setInt(2,value._2)
insertStmt.execute()
}
}
//打开连接 并创建预编译
override def open(parameters: Configuration): Unit = {
super.open(parameters)
conn = DriverManager.getConnection(url,uname,pwd)
insertStmt = conn.prepareStatement("insert into tab_jdbc_sink (words,count)values(?,?)")
updateStmt = conn.prepareStatement("update tab_jdbc_sink set count= ? where words= ? ")
}
override def close(): Unit = {
insertStmt.close()
updateStmt.close()
conn.close()
}
}
