1. postgresql 升级
gpdb 5版本是将 postgresql 从 8.2 升级到 8.3 ,gpdb 6 有 6 个 postgresql 大版本升级:
- v8.4 - 2314 commits
- v9.0 - 1859 commits
- v9.1 - 2035 commits
- v9.2 - 1945 commits
- v9.3 - 1603 commits
- v9.4 - 1964 commits
共 11720 个 commits
2. OLTP 性能大幅提升
平均性能提升 70+ 倍
- 许多分析系统需要混合使用 OLTP 和 OLAP 查询。
- 高并发 OLTP 操作。
- Update TPS 24448
- Insert TPS 46570
- Select TPS 140000
- 利用资源组(resource group)进行多样化的工作负载管理
3.精细化资源管理
3.1 目标
- 多租户资源隔离
- 更好低支持混合工作负载
- 更好地支持高并发
3.2 特征
- 指定每个用户组的最大 CPU
- 指定每个用户组和限制每个查询的最大内存
- 指定每个用户组的最大并发数
- 利用 Linux Cgroup 实现
cgroups,其名称源自控制组群(英语:control groups)的简写,是Linux内核的一个功能,用来限制、控制与分离一个进程组的资源(如CPU、内存、磁盘输入输出等)。
这个项目最早是由Google的工程师(主要是Paul Menage和Rohit Seth)在2006年发起,最早的名称为进程容器(process containers)[1]。在2007年时,因为在Linux内核中,容器(container)这个名词有许多不同的意义,为避免混乱,被重命名为cgroup,并且被合并到2.6.24版的内核中去[2]。自那以后,又添加了很多功能。
cgroups的一个设计目标是为不同的应用情况提供统一的接口,从控制单一进程(像nice)到操作系统层虚拟化(像OpenVZ,Linux-VServer,LXC)。cgroups提供:
资源限制:组可以被设置不超过设定的内存限制;这也包括虚拟内存。
- 优先级:一些组可能会得到大量的CPU 或磁盘IO吞吐量。
- 结算:用来度量系统实际用了多少资源。
- 控制:冻结组或检查点和重启动。
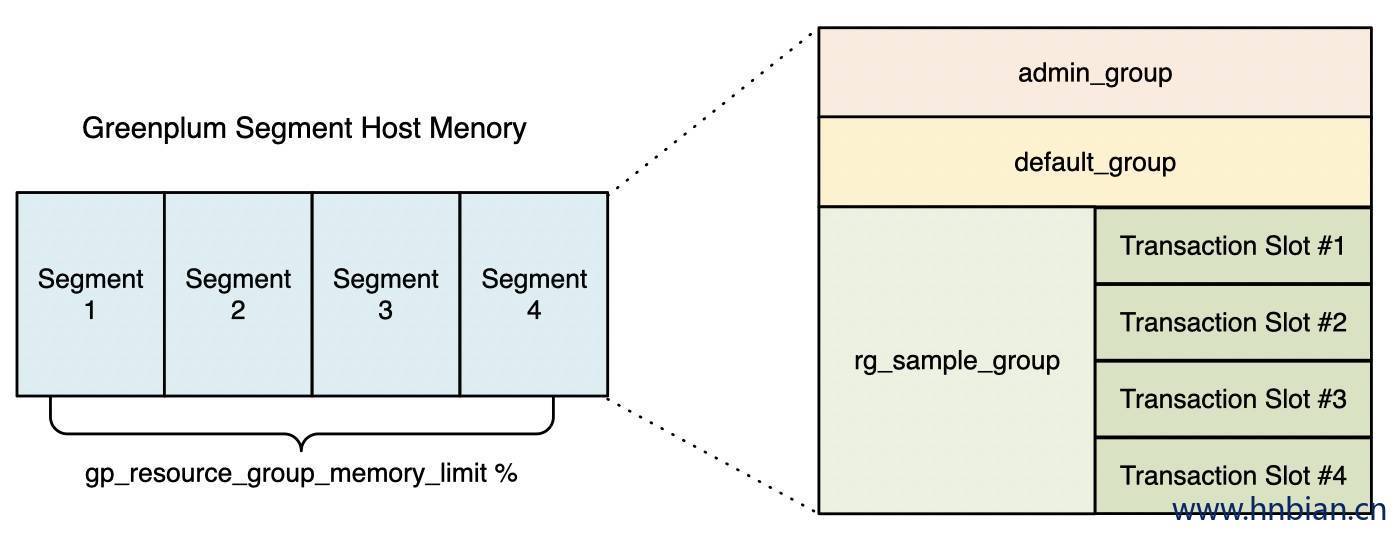
3.3 新建资源组
CREATE RESOURCE GROUP RG_SAMPLE WITH(
CONCURRENCY=4, -- 最大并发事务数
CPU_LIMIT=30, --CPU资源的百分比
MEMORY_LIMIT=60, --内存资源的总百分比
MEMORY_SHARED_QUOTA=50 --共享内存的配额
)
4. 磁盘配额
- 多租户场景下,磁盘配额是 SLA 的一部分
- 支持 Schema 和用户级别的磁盘配额创建和管理
- 当磁盘使用量达到限定额度时,限制用户继续占用磁盘空间
- 基于Greenplum Extenion框架构建
- 最小化 IO 性能的影响
- 近似实时的响应
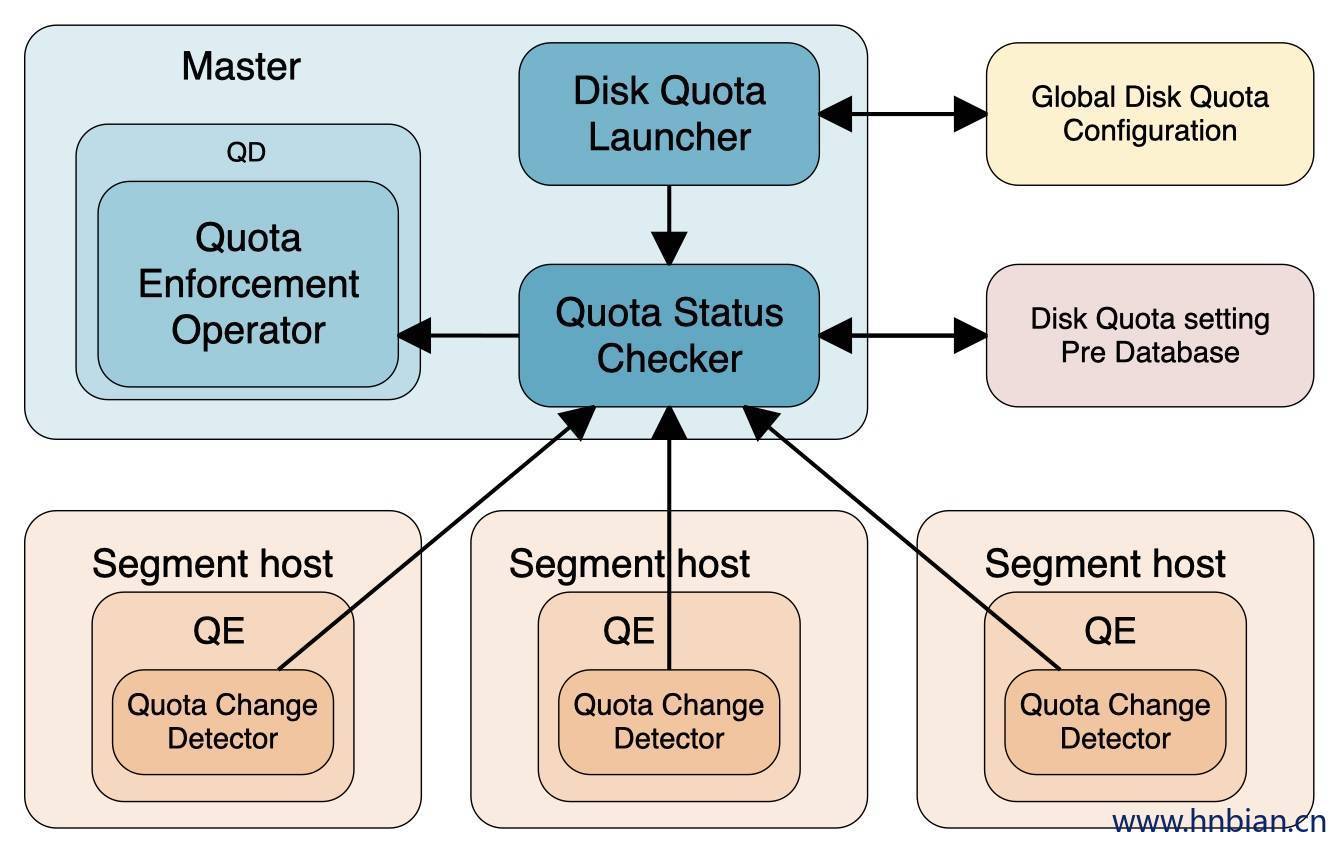
重要角色说明:
- detector: 对 segment 中文件大小进行监控,定期监控文件大小增长情况
- checker: 收集 detector 上监控的文件占用空间信息,并将信息上报给operator。
- operator: 通过配额规则对达到限额条件的文件或进程进行限制。
通过资源组和磁盘配额就可以对 CPU、内存、磁盘进行很好的隔离。
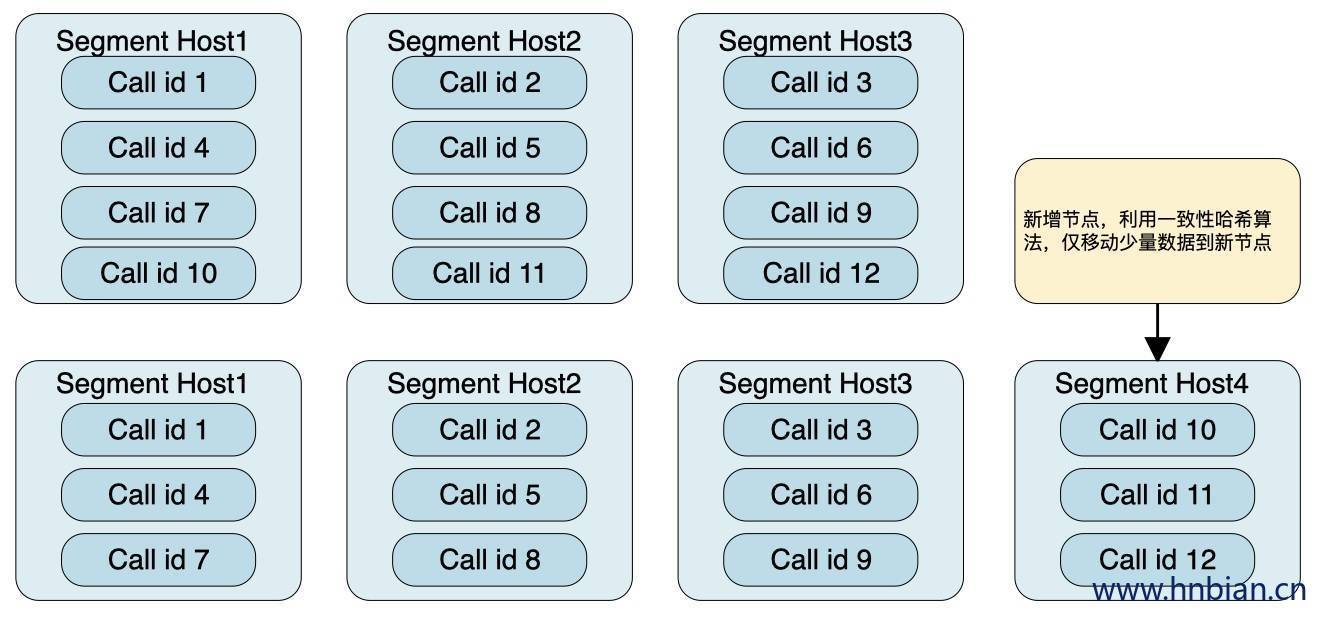
5. 更快的集群扩容
10 倍以上的性能提升
- 新的一致性哈希算法
- 不需要重新分布集群的所有数据,仅移动少量数据
- 不需要重启集群
6. 预写日志
- 降低准备节点同步数据时的网络开销
- 适应高负载 CPU
- 重新平衡更快
- 兼容 postgres
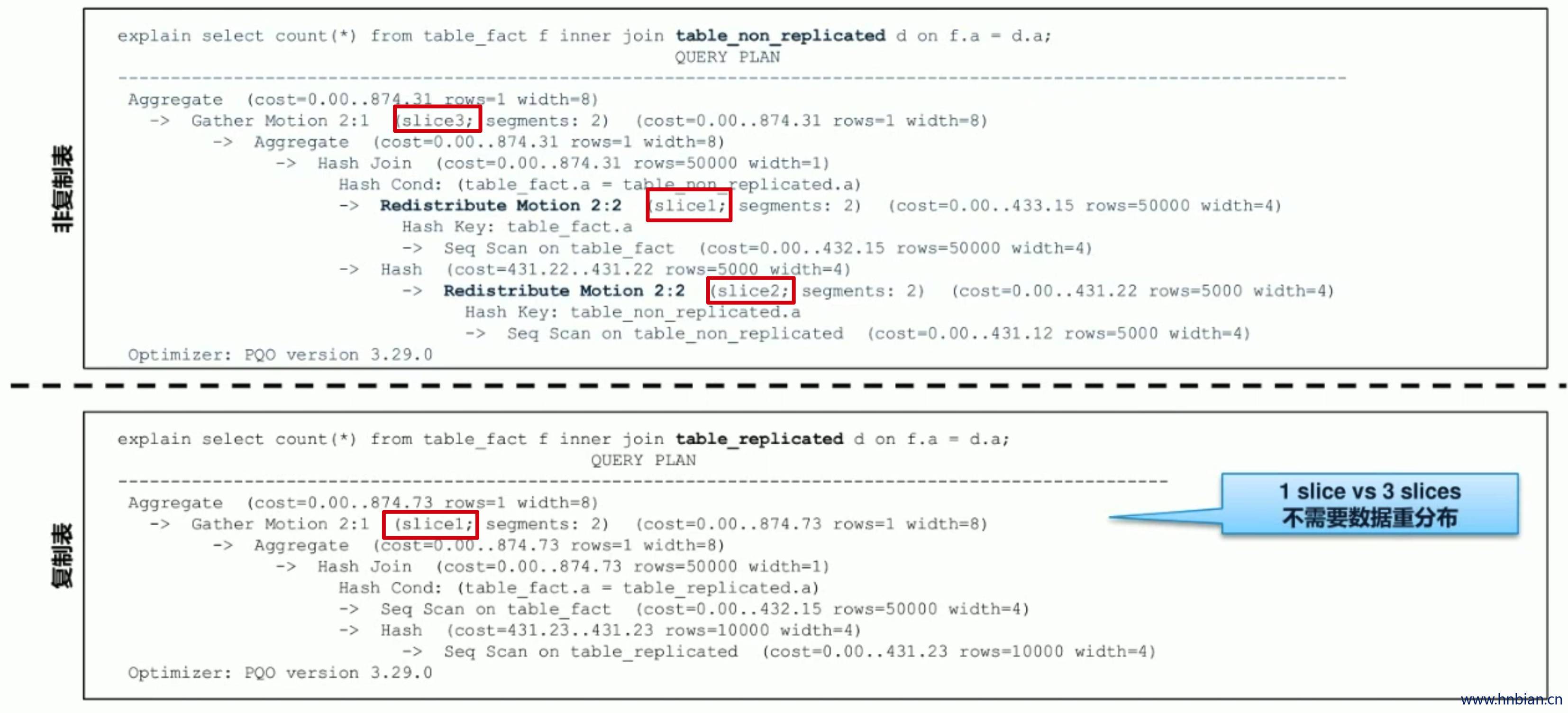
7. 复制表
8. zStandard 压缩算法升级
| 算法名称 | 压缩率 | 压缩速度 | 解压缩速度 |
|---|---|---|---|
| sztd 1.3.4-1 | 2.877 | 470M/s | 1380M/s |
| zlib 1.2.11-1 | 2.743 | 110M/s | 400M/s |
| brotli 1.0.2 -0 | 2.701 | 410M/s | 430M/s |
| quicklz 1.5.0 -1 | 2.238 | 550M/s | 710M/s |
| lzo1x 2.0.9 -1 | 2.108 | 650M/s | 830M/s |
| lz4 1.8.1 | 2.101 | 750M/s | 3700M/s |
| snappy 1.1.4 | 2.091 | 530M/s | 1800M/s |
| lzf 3.6 -1 | 2.077 | 400M/s | 860M/s |
9. 列级安全管理
10. Unlogged 表
- 写入 Unlogged 表的数据不会写预写(WAL)日志,这使得它比普通表快很多。
- 作用与临时表类似但与临时表不同的是 Unlogged 表在当前会话/事务结束时不会删除。
- 保持数据原子性、完整性和一致性,但是如果发生崩溃数据可能丢失。
11. Kafka Connector
- Minibacth 模式的流式计算引擎
- 端到端不重复不丢失、高速、可靠、低延迟
- Confluent 认证
- 支持丰富的数据格式,Avro、Json、Text、Binary以及自定义格式等。
- 支持并行Transform
- 支持机器学习、文本分析、地理信息等分析工具,并可以通过 UDF 扩展。
12. GPCC 6.0 新特性
- 首次支持GreenPlum 6
- 无需运行 gpperfmon 服务
- 提供日志级别来控制日志粒度
- 搜索历史查询时,使用过滤器缩小搜索范围
- 监测 standby master 状态
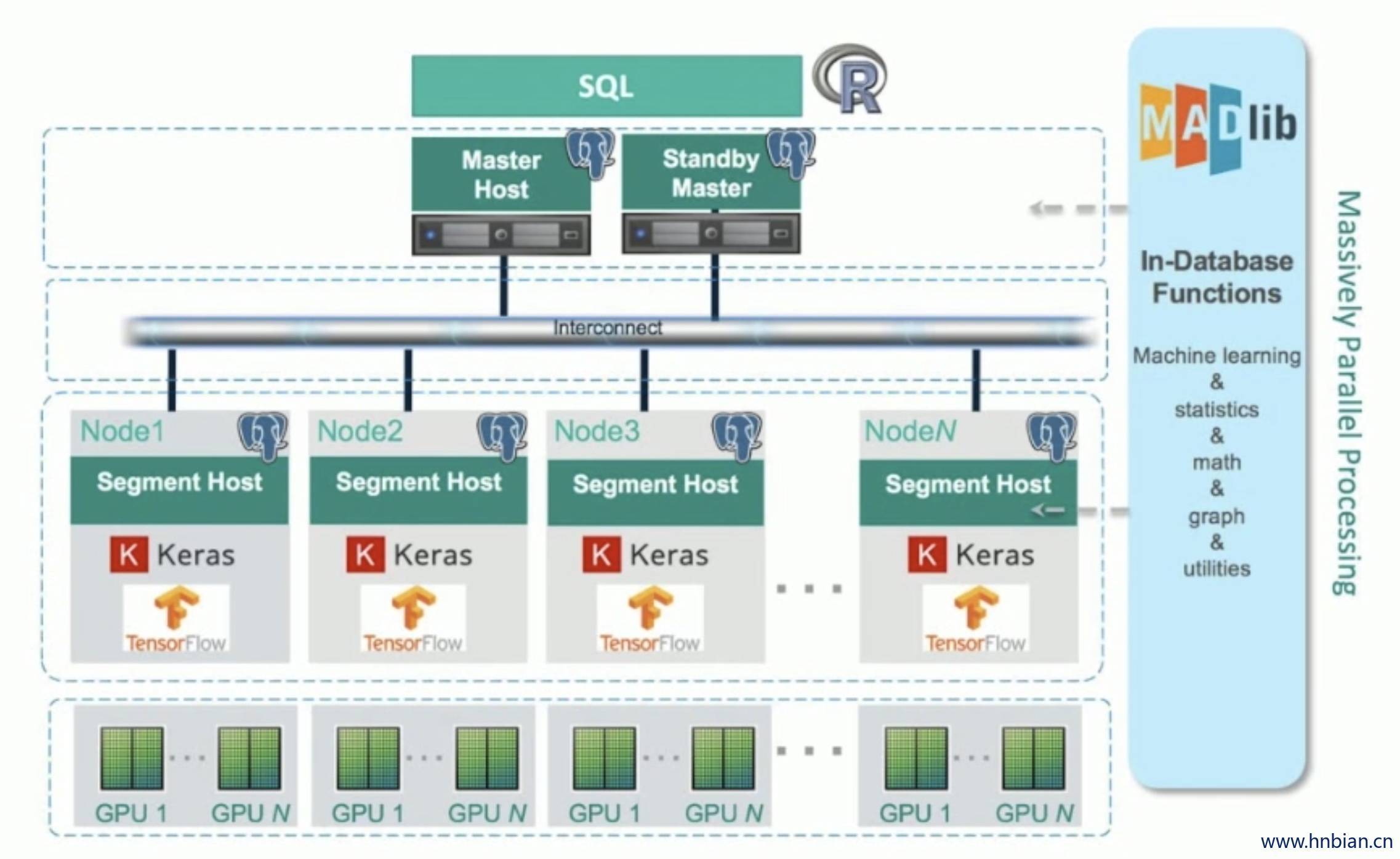
13. MadLib 1.6 提供了深度学习能力
- 支持图像和文本
- 识别非结构化数据中的模式
- 将图像和文本转化为可预测的业务决策
- 可以运行在 GreenPlum 和 postgres 上
14. Greenplum 7 的规划
14.1 Postgre 9.5 版本升级
- Upsert (Update & Insert)
- 行级安全管理
- Block Ranger Indices
- 排序性能大幅提升
- 多 CPU 机器性能大幅提升
14.2 Postgre 9.6 版本升级
- 并行执行顺序扫描,join 和聚合
- 避免在Vacuum 操作期间不必要的扫描存储页
- 全文检索具备检索短语的能力(多个相邻词)
- postgres_fdw支持远程 join、排序、更新和删除。
- 大幅提升性能,尤其是在多 CPU 插槽服务器上的可扩展性方面
14.3 多数据中心复制
- 利用 GPDB 6 中实现的预写日志
- 支持故障转移和故障修复
- 最大化数据可用性
- 支持冷热待机
- 在现有的网络配置中可以工作
- 只需要配置一次
14.4 夸集群查询
- 让用户可以更快的夸 GreenPlum 集群查询你数据
- “扩大” GreenPlum 集群规模
- 减少数据冗余
- 支持跨级群表 join
- 支持谓词下推,减少数据网络传输
14.5 GPCC 报表和报警功能增强
- 对数据表的信息跟踪,大小,负载等
- 对数据表的数据倾斜等预置条件进行报警
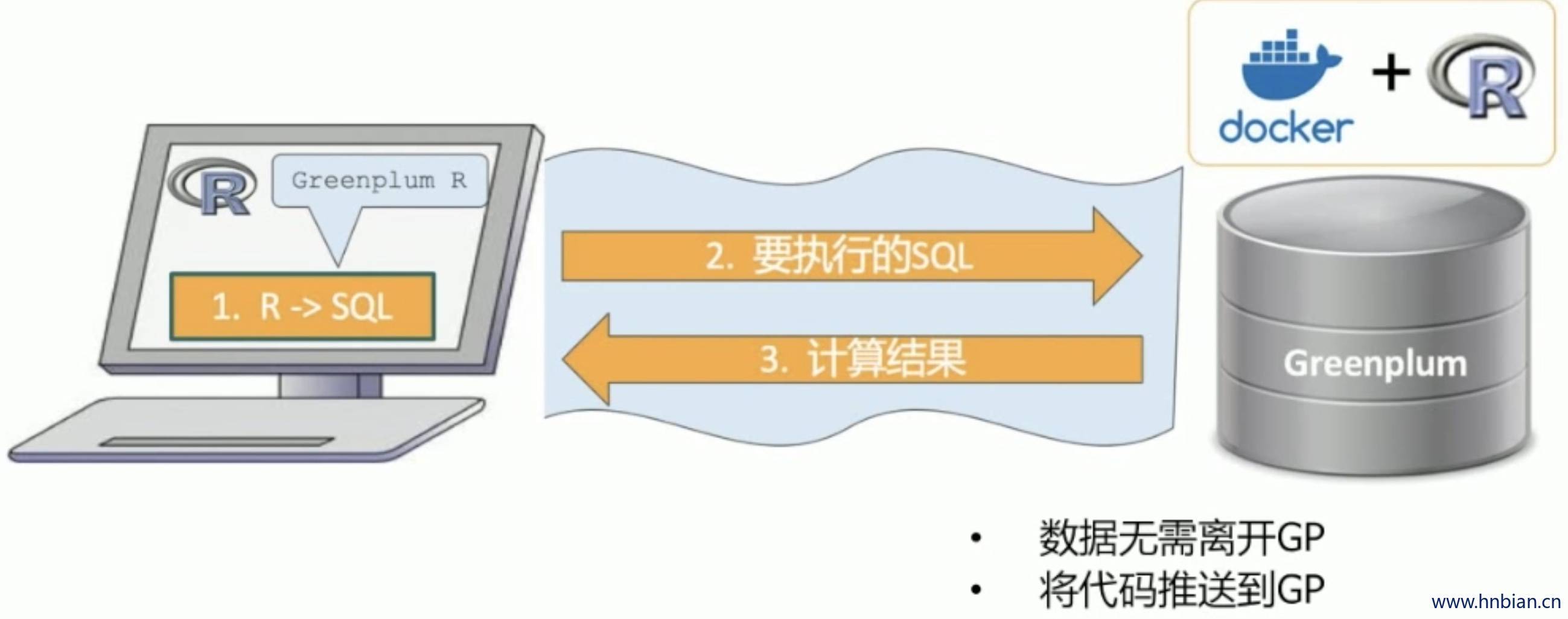
14.6 GreenPlum R
- R 开发者在本地编写代码
- R 函数推送到 GreenPlum 服务器
- 在 Docker 环境中并行执行 R 函数
- R 函数在 GreenPlum 中处理数据
- 结果存储到数据库或返回给客户端
15. 总结
GreenPlum 重新定义大数据和数据仓库
- 基于 Postgres
- 混合事务分析处理(HTAP)
- 关键业务可用性
- 可扩展编程模型
- 数据库内分析
- 优化的系统监控
- 不断创新

