1.DDL(data definition language)
DDL的命令有CREATE、ALTER、DROP等,DDL主要是用在定义或改变表(TABLE)的结构,数据类型,表之间的链接和约束等初始化工作上,他们大多在建立表时使用
1.1一般操作
1.1.1 查看HBASE版本:version
1 | hbase(main):019:0> version |
1.1.2 查看HBASE状态:status
1 | hbase(main):022:0* status |
1.1.3 查看当前用户:whoami
1 | hbase(main):026:0* whoami |
1.2 表空间操作
在HBASE中,namespace命名空间指对一组表进行逻辑分组,类似于关系型数据库中的database,方便对表在业务上划分。Apache HBASE 从0.98、0.95.2两个版本开始支持namespace级别的授权操作,HBASE全局管理员可以创建、修改和回收namespace的授权。
HBASE系统默认定义了两个默认的namespace:
- hbase:系统内建表,包括namespace 和 meta表。
- default:当用户建表时未指定namespace,那么会在该namespace下创建表。
1.2.1 列出表空间:list_namespace
1 | hbase(main):029:0> list_namespace |
1.2.2 新建表空间:create_namespace
- 语法:create_namespace ‘表空间名称’
1 | hbase(main):035:0> create_namespace 'test' |
1.2.3 查看表空间:describe_namespace
- 语法:describe_namespace ‘表空间名称’
1 | hbase(main):039:0> describe_namespace 'test' |
1.2.4 在表空间下创建表:
- 语法:create ‘表空间名称:表名称’,’列簇名’
1 | hbase(main):060:0* create 'test:t1','info' |
1.2.5 查看表空间下的表:list_namespace_tables
- 语法:list_namespace_tables ‘表空间名称’
1 | hbase(main):064:0* list_namespace_tables 'test' |
1.2.6 删除表空间:drop_namespace
- 语法:drop_namespace ‘表空间名称’
1 | hbase(main):068:0* drop_namespace 'test' |
1.3 表的相关操作
1.3.1 列出所有的表:list
1 | hbase(main):085:0* list |
1.3.2 检查某个表是否存在:exists
- 语法:exists ‘表名’
1 | hbase(main):089:0> exists 'Student' |
1.3.3 使用默认配置建表
- 语法:create ‘空间名:表名’,’列簇名’/create ‘表名’,’列簇名’
空间名非必须,如果建表时不写表空间则新建表在默认表空间中
1 | '创建一张表 t1 有两个列簇 cf1、cf2' |
1.3.4 查看表结构 describe
- 语法:describe ‘表名’
1 | hbase(main):095:0> describe 't1' |
表结构说明:
Table t1 is ENABLED –> 表是可用状态
t1
COLUMN FAMILIES DESCRIPTION –> 以下是列簇描述
{
NAME => ‘cf1’, –> 列簇名称
VERSIONS => ‘1’, –> 版本数量
EVICT_BLOCKS_ON_CLOSE => ‘false’, –> 在关闭时是否移除缓存块
NEW_VERSION_BEHAVIOR => ‘false’, –> 来指定备用版本并删除处理
KEEP_DELETED_CELLS => ‘FALSE’, –>在major compaction发生的时候,决定要不要清理旧数据
CACHE_DATA_ON_WRITE => ‘false’, –> 如果块缓存开启,那么默认是否在写入数据时缓存数据块
CACHE_INDEX_ON_WRITE => ‘false’, –>如果块缓存开启,那么默认是否在写入数据时缓存index
DATA_BLOCK_ENCODING => ‘NONE’, –> 设置数据块编码方式
TTL => ‘FOREVER’, –> 数据有效时间,时间单位秒
MIN_VERSIONS => ‘0’, –> 在compact操作执行之后,至少要保留的版本数
REPLICATION_SCOPE => ‘0’, –> 配置HBase集群replication时需要将该参数设置为1
BLOOMFILTER => ‘ROW’, –>布隆过滤器的作用级别
IN_MEMORY => ‘false’, –> 设置激进缓存,优先考虑将该列族放入块缓存中,默认值为false, 针对随机读操作相对较多的列族可以设置该属性为true
CACHE_BLOOMS_ON_WRITE => ‘false’, –> 当缓存数据块开启的时候是否缓存 布隆过滤器数据
PREFETCH_BLOCKS_ON_OPEN => ‘false’, –>预先加载数据,如果设置,则在打开文件后,属于该列簇的HFiles的所有INDEX,BLOOM和DATA块都将被加载到缓存中
COMPRESSION => ‘NONE’, –> 压缩算法
BLOCKCACHE => ‘true’, –> #设置数据块是否缓存,默认为true
BLOCKSIZE => ‘65536’–> 设置HFile数据块大小,单位 B,默认64kb
}
1.3.5 停用表 disable
- 语法:disable ‘表名’
1 | disable 't1' |
1.3.6 启用表 enable
- 语法:enable ‘表名’
1 | enable 't1' |
1.3.7 创建表2->对TTL、缓存、压缩等配置
- 语法:create ‘表名’,{NAME => ‘info’, 配置名称=>’值’,配置名称=>’值’,…}
如下语句,创建表名为t1的表,并创建两个列簇 info 和header,并设置数据有效时间为604800秒(7天),使用SNAPPY压缩算法,只有一个版本,开启块缓存。
1 | create 't1', |
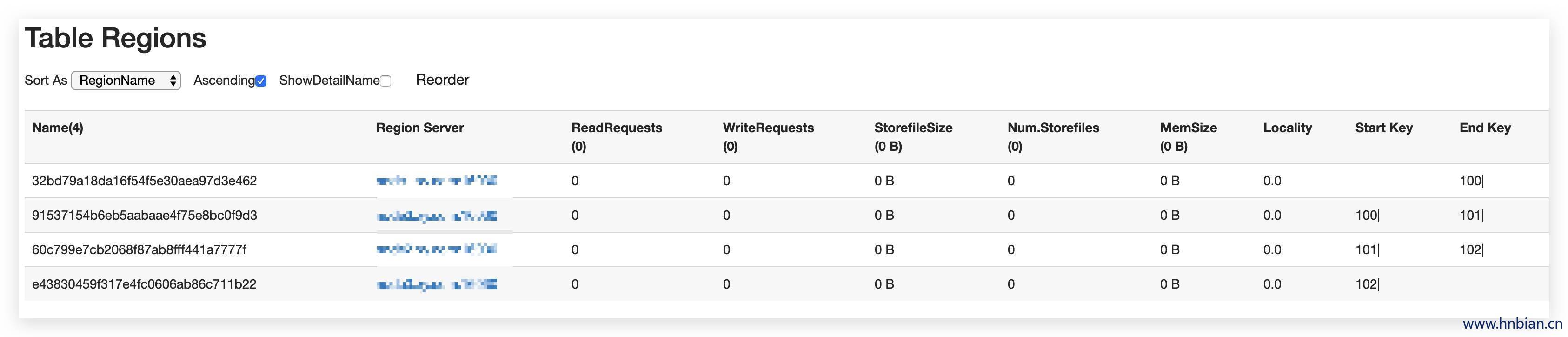
1.3.8 创建表3->对region进行预分区1.命令行中进行分区
- 语法:create ‘表名’,列簇,SPLITS =>[‘分区前缀|’,’分区前缀|’,…]
创建表并对region分配3个预分区
1 | create 't2','info',SPLITS =>['100|','101|','102|'] |
1.3.9 创建表3->对region进行预分区1.配置文件中进行分区
1.3.10 增加/删除列簇
- 语法:alter ‘表名’,’delete’=>’列簇名称’
增加一个列簇 f1,并且删除header列簇
1 | alter 't2',{NAME=>'f1'},'delete'=>'header' |
1.3.11 修改info列簇版本号
将t2表的info列族版本号改为5
1 | alter 't2',NAME=>'info',VERSIONS=>5 |
修改表其他配置项语法类似
1.3.12 修改压缩格式
- 语法:alter ‘表名’, NAME => ‘列簇名’, COMPRESSION => ‘压缩算法’
1 | #停用表 |
1.3.13 删除表
- 语法:drop ‘表名’
1 | disable 't2' |
2. DML(data manipulation language)
它们是SELECT、UPDATE、INSERT、DELETE,就象它的名字一样,这4条命令是用来对数据库里的数据进行操作的语言
2.1 增加数据
- 语法:put ‘表名’,’row key’,’列族名:列名’,’值’
1 | #创建一个新表,有cf1、cf2两个列簇 |
2.2 查询数据
2.2.1 使用 get 查询数据
- 语法:get ‘表名’,’rowkey’,’列簇’,’过滤器’
1 | # 查询 rowkey 为101行的所有数据 |
2.2.2 使用 scan 查询数据
1 | #查询 t3 表中的所有信息 |
2.2.3 表数据量统计
1 | #统计表 t3 数据量 |
2.3 修改数据
修改数据可以向表中写入数据覆盖原来的数据即可,
1 | #将101 列的cf1:name 名字由xiaoming 改成 xiaoxiaoming |
2.4 删除数据
1 | #删除 t3 表中 101 行中的cf2:address列 |
2.5 清空数据
1 | 清空 t3 表中的数据 |

