1. 什么是分布式文件系统
数据量越来越多,在一个操作系统管辖的范围存不下了,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,因此迫切需要一种系统来管理多台机器上的文件,这就是分布式文件管理系统(Distributed File System)。
是一种允许文件通过网络在多台主机上分享的文件系统,可以让多台机器上的多用户分享文件和存储空间
通透性,实际上就是通过网络来访问文件的动作,由于程序与用户看来,就像是访问本地磁盘一般
容错,即使系统中有些节点脱机,整体来说系统仍然可以持续运作,而不会有数据损失
分布式文件管理系统很多,HDFS只是其中一种,适用于一次写入多次查询的情况,不支持并发情况,小文件不太适合(不支持修改操作,hadoop1不适合小文件,hadoop2也可以了)
存储元数据信息是瓶颈,元数据信息存放在NameNode上,NameNode既要保证数据不丢,又要保证高速读写,放在内存一份,序列化到磁盘一份,内存是有限的,存1M要保存一条元数据,1G也要保存一条元数据
2. 常见的分布式文件系统有哪些
常见的分布式文件系统有:GFS、HDFS、Lustre、GeidFS、Ceph、mogonDB、TFS
3. 架构介绍
3.1 NameNode
- NameNode 是整个文件系统的管理节点。它维护着整个文件系统的文件目录树,文件/目录的元信息和每个文件对应的数据块列表,接收用户的操作请求。
- 文件夹包括
| fsimage |
元数据镜像文件。存储某一时段NameNode元数据信息(内存中的元数据序列化到磁盘之后的名字,hadoop1 或hadoop2伪分布式不是实时同步的,hadoop2集群模式是实时同步的) |
| edits |
操作日志文件 |
| fstime |
保存最近一次checkpoint的时间(最近一次还原点的时间) |
- 以上这些文件是保存在linux的文件系统中
- 对应文件中的目录 tmp 文件夹下(hadoop/tmp)
| 路径 |
说明 |
| dfs/data |
datanode 存储数据相关 |
| dfs/name |
存储元数据 |
| dfs/namesecondary |
帮助NameNode同步数据 |
| dfs/name/current |
edits/fsimage等文件 |
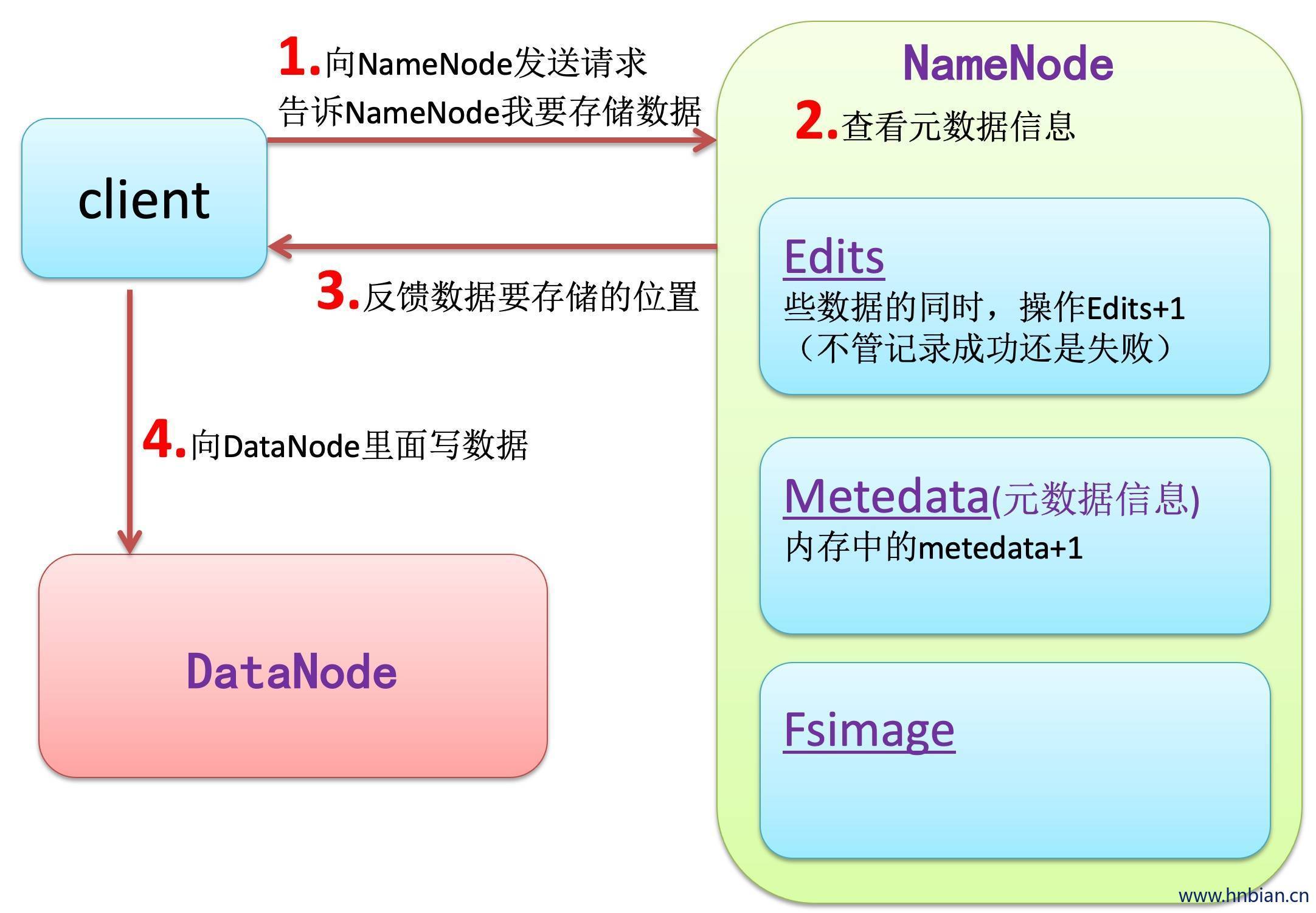
NameNode 始终在内存中保存metedata,用于处理“读请求”
到有“写请求”到来时,NameNode会首先写editlog到磁盘,即向edits文件中写日志,成功返回后,才会修改内存,并且想客户端返回
hadoop会维护一个fsimage文件,也就是NameNode中metedata的镜像,但是fsimage不会随时与NameNode内存中的metedata保持一致,而是每隔一段时间通过合并edits文件来更新内容(伪分布式与1.0,2.0已经可以实时同步了)。Secondary Namenode就是用来合并fsimage和edits文件来更新NameNode的metedata的
3.2 SecondaryNameNode
HA的一个解决方案。但是不支持热备。配置即可
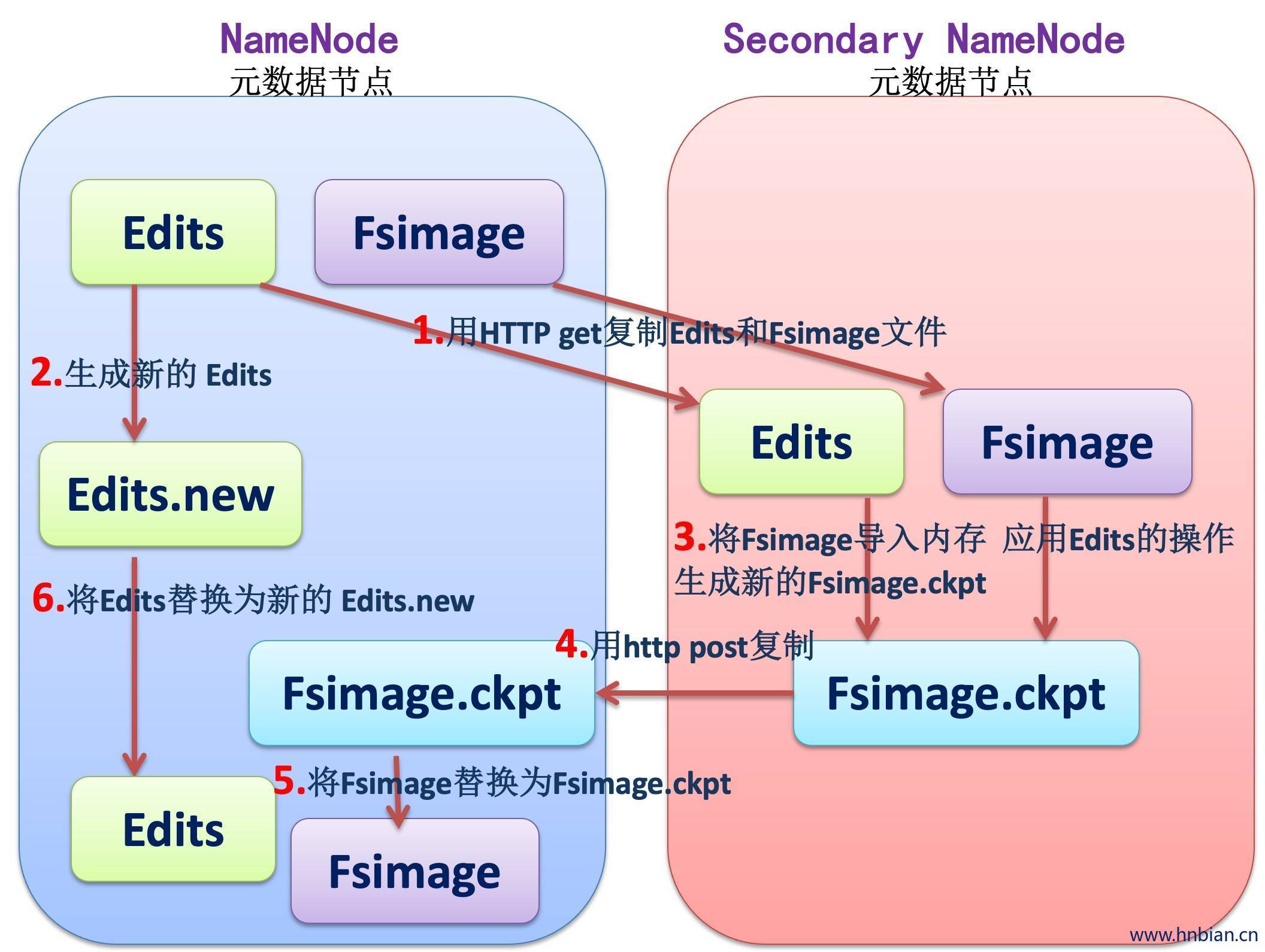
执行过程:从NameNode上下载元数据信息(Fsimage,edits),然后把二者合并,并声称新的Fsimage,在本地保存,并将其推送到NameNode替换就得Fsimage。
默认安装在NameNode节点上,但是这样》》》不安全!
Hadoop2.0集群模式没有SecondaryNameNode
SecondaryNameNode的工作流程
- Secondary通知NameNode切换edits文件
- Secondary从NameNode获得Fsimage和edits(通过http)
- Secondary将Fsimage载入内存,然后考试合并edits
- Secondary将Fsimage发回给NameNode
- NameNode用新的Fsimage替换就得Fsimage
- Fs.checkpoing.period 指定两次checkpoint的最大时间间隔,默认是3600秒
- Fs.checkpoint.size 规定edits文件的最大值,一旦超过这个值则强制checkpoint,不管是否达到最大时间间隔默认大小是64M。
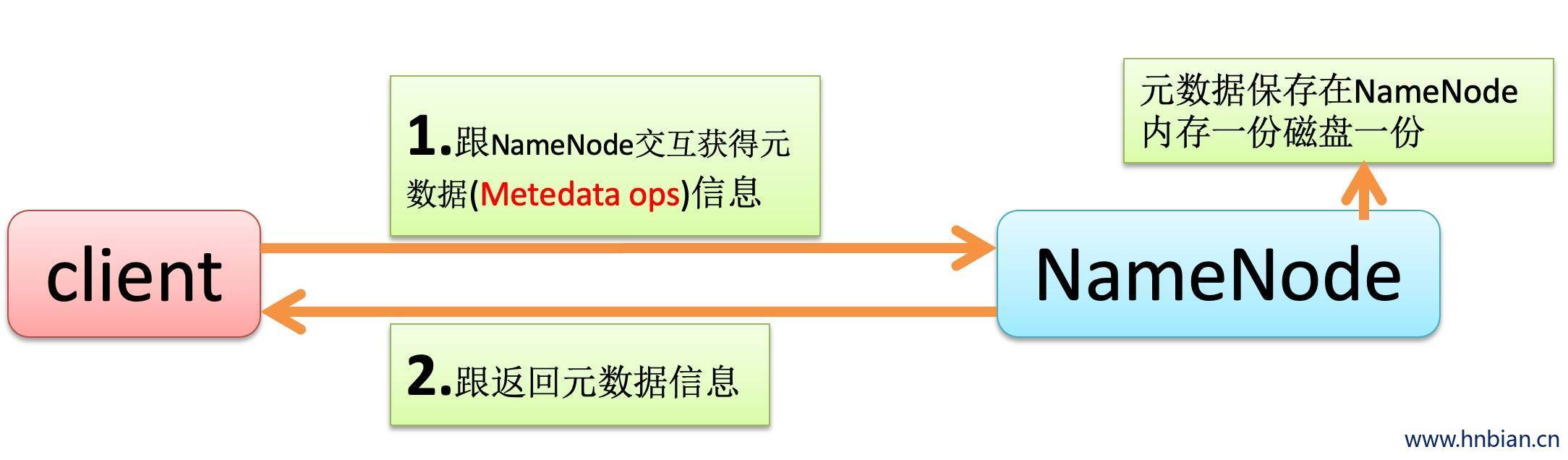
3.3 元数据处理细节
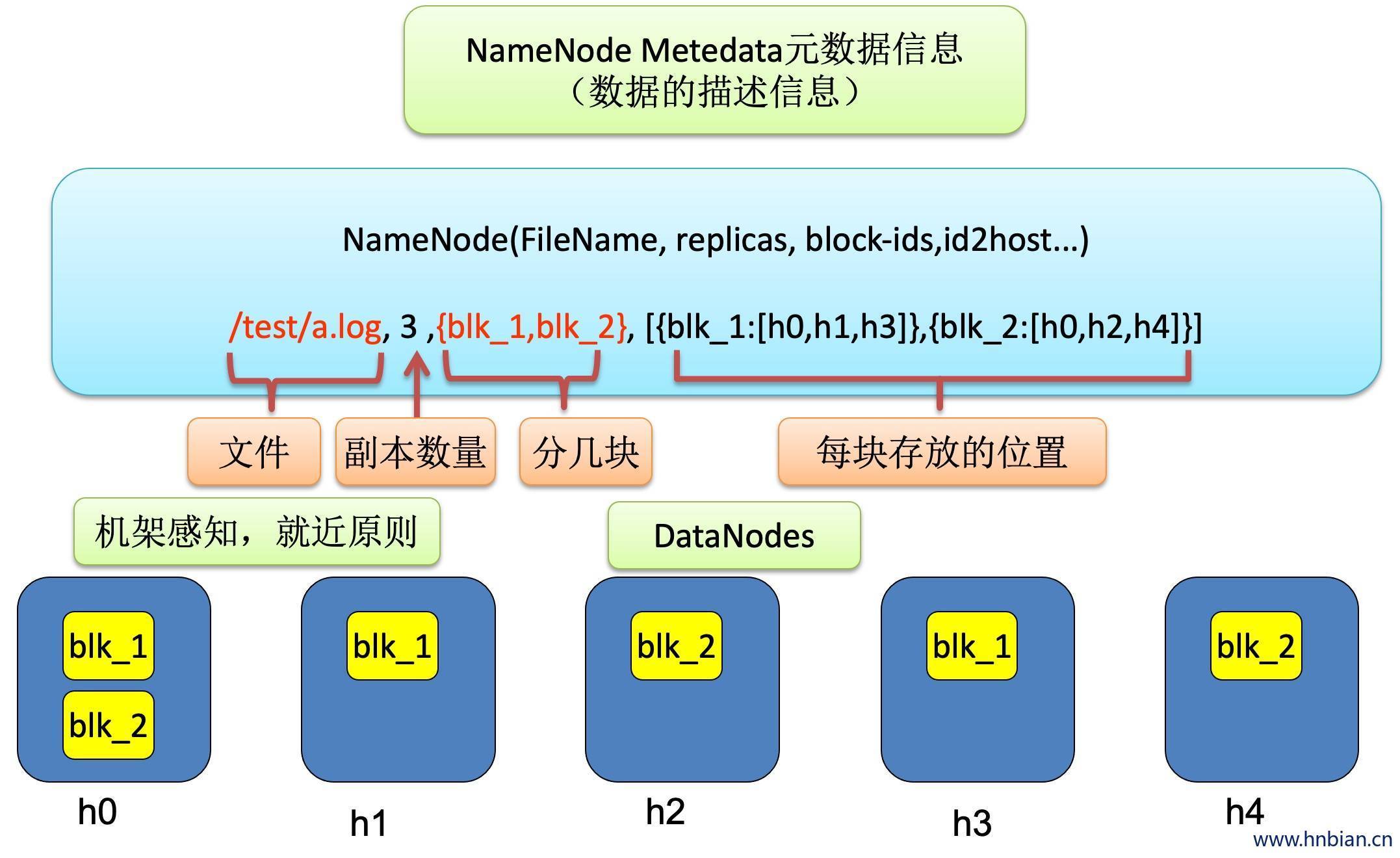
3.4 DataNode
负责数据块的实际存储和读写工作,Block 默认是64MB(HDFS2.0改成了128MB),当客户端上传一个大文件时,HDFS 会自动将其切割成固定大小的 Block,为了保证数据可用性,每个 Block 会以多备份的形式存储,默认是3份。
3.5 HDFS 高可用
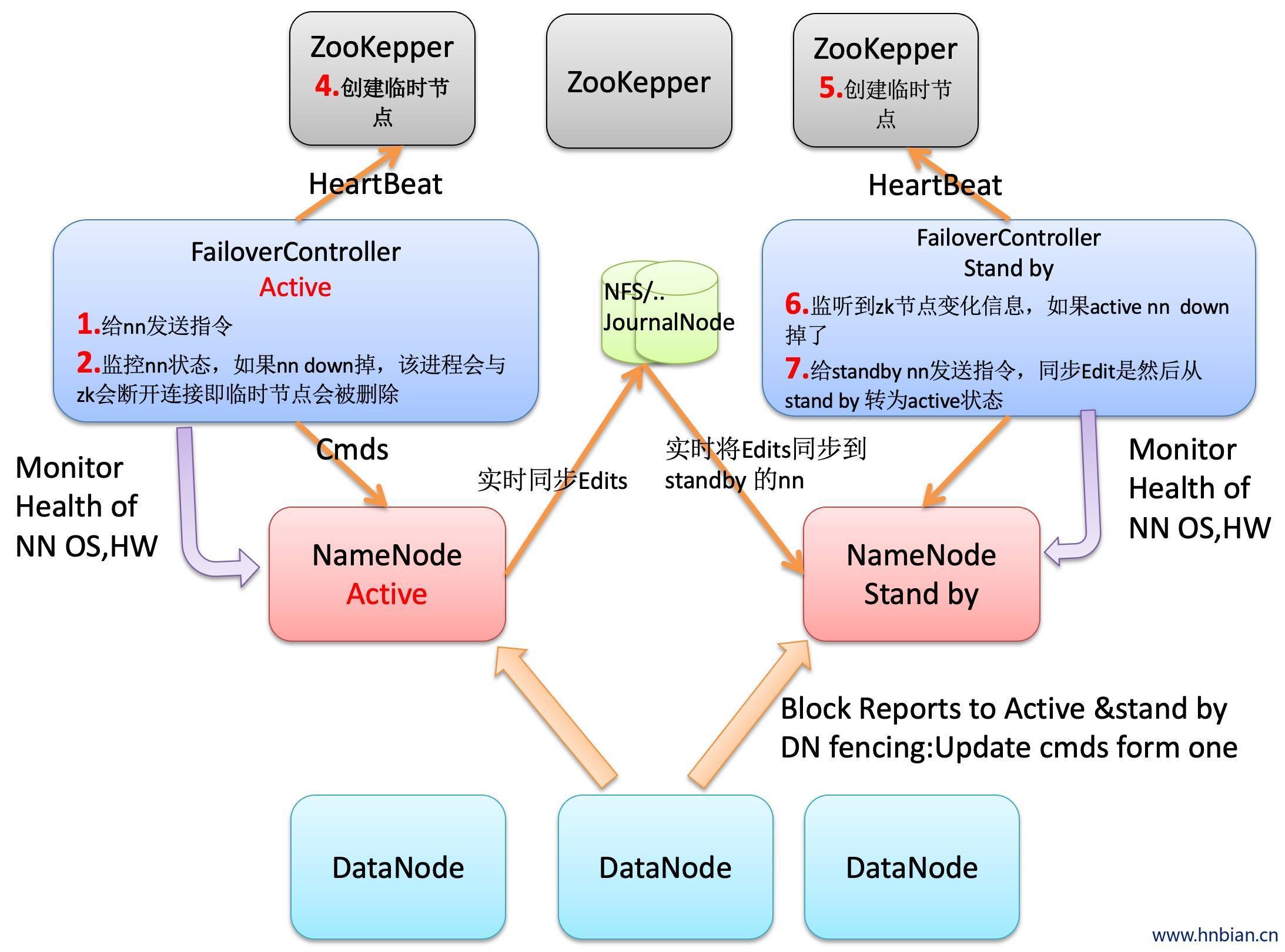
4. 数据的读写过程
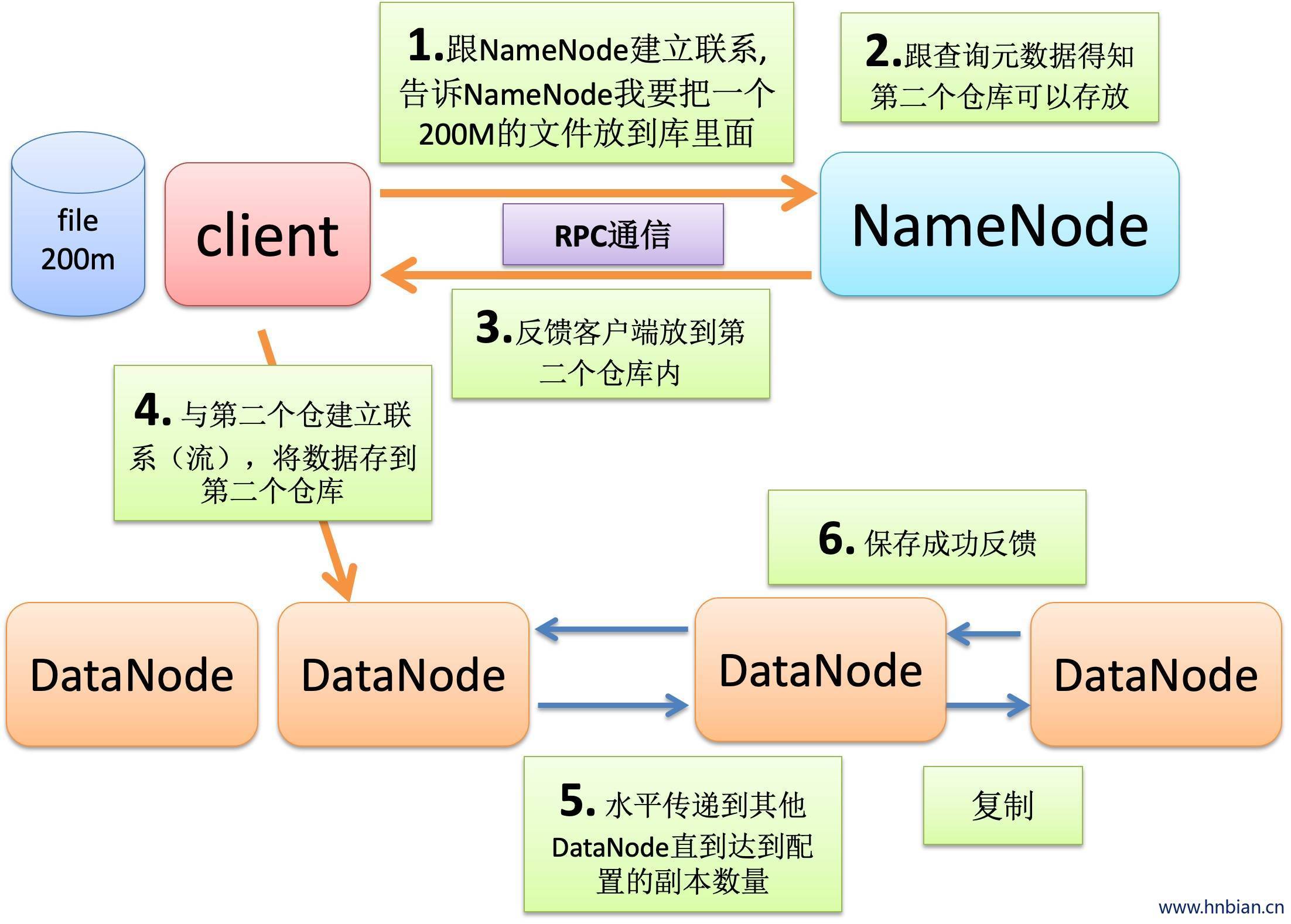
4.1 数据的写入过程
- 初始化FileSystem,客户端调用create()来创建文件。
- FileSystem用RPC调用元数据节点,在文件系统的命名空间创建一个新的文件,元数据节点首先确定文件原来存不存在,并且客户端有创建文件的权限,然后创建文件。
- FileSystem返回DFSOutputStream,客户端用于写数据,客户端开始写数据。
- DFSOutputStream将数据分成块,写入dataQueue(dataQueue是数据队列,用于保存等待发送给datanode的数据包),dataQueue由dataStream读取,并通知元数据节点分配数据节点,用来存储数据块(每块默认复制三块)。范培的数据节点放在一个popeline里。DataStream将数据块写入pieline中的第一个数据节点。第一个数据节点将数据块发送给第二个数据节点,第二个数据节点发送给第三个数据节点。
- DFSOutputStream为发出去的数据库保存了ackQueue(ackQueue是确认队列,保存还没有被datanode确认接收的数据包),等待pipeline中的数据节点告知数据已经写入成功。
- 当客户端结束些数据,则调用stream的close函数,此操作将为所有的数据块写入pipeline中的数据节点,并等待ackQueue返回成功。最后通知元数据节点写入完毕。
- 如果数据节点在写过程中失败,关闭pipeline,将ackQueue中的数据块放入dataQueue的开始,当前的数据块在已经写入的数据节点中被元数据节点赋予新的标识,则错误节点重启后能够察觉数据块是过时的,会被删除。失败的数据节点从pipeline中移除,另外的数据块则写入pipeline中的另外两个数据节点。元数据节点则被通知此数据块是复制数不足,将来会在创建第三个备份。
在向DFSOutputStream中,写入数据(通常是byte数组)的时候,实际的传输过程是:
1、byte[]被封装成64KB的Packet,然后扔进dataQueue中
2、DataStreamer线程不断的从dataQueue中取出Packet,通过socket发送给datanode(向blockStream写数据)
发送前,将当前的Packet从dataQueue中移除,并addLast进ackQueue
3、ResponseProcessor线程从blockReplyStream中读出从datanode的反馈信息
反馈信息很简单,就是一个seqno,再加上每个datanode返回的标志(成功标志为DataTransferProtocol.OP_STATUS_SUCCESS)
通过判断seqno(序列号,每个Packet有一个序列号),判断datanode是否接收到正确的包。
只有收到反馈包中的seqno与ackQueue.getFirst()的包seqno相同时,说明正确。否则可能出现了丢包的情况。
如果一切OK,则从ackQueue中移出:ackQueue.removeFirst(); 说明这个Packet被datanode成功接收了。
4.2 数据的读取过程
HDFS读过程
- 初始化FileSystem,然后客户端(Client)用FileSystem 的open()函数打开文件
- FileSystem用RPC调用元数据节点,得到文件的数据块信息,对于每一个数据块,元数据节点返回保存数据块的数据节点地址。
- FileSystem返回FSDataInputStream给客户端,用来读取数据,客户端调用stream的read()函数开始读取数据。
- DFSInputStream连接保存此文件第一个数据块的最近的数据节点,data从数据节点读到客户端(Client)
- 当磁块数据读取完毕时,DFSInputStream关闭和此数据节点的连接,然后连接此文件的下一个数据块的最近的数据节点。
- 当客户端读取完毕数据的时候,调用DFSInputStream的close函数。
- 在读取数据的过程中,如果客户端在数据节点通信出现错误,则常识连接包含此数据块的下一个数据节点。
- 失败的数据节点将被记录,以后不再连接。
5. Remote Procedure Call
5.1 RPC 介绍
- RPC——远程过程调用协议,它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。RPC协议假定某些传输协议的存在,如TCP或UDP,为通信程序之间携带信息数据。在OSI网络通信模型中,RPC跨越了传输层和应用层。RPC使得开发包括网络分布式多程序在内的应用程序变得更加容易。
- RPC采用客户机/服务器模式。请求程序就是一台客户机,而服务提供程序就是一个服务器。首先,客户机调用进程发送一个有进程参数的调用信息到服务程序,然后等待应答信息。在服务器端,进程保持睡眠状态直到调用的信息到达为止,当一个调用信息到达,服务器获得进程参数,计算结果,发送答复信息,然后等待下一个调用信息,最后,客户端调用进程接收答复,获得进程结果,然后调用执行程序继续进行。
- hadoop的整个结构体系就是构建在RPC之上的(见org.apache.hadoop.ipc)
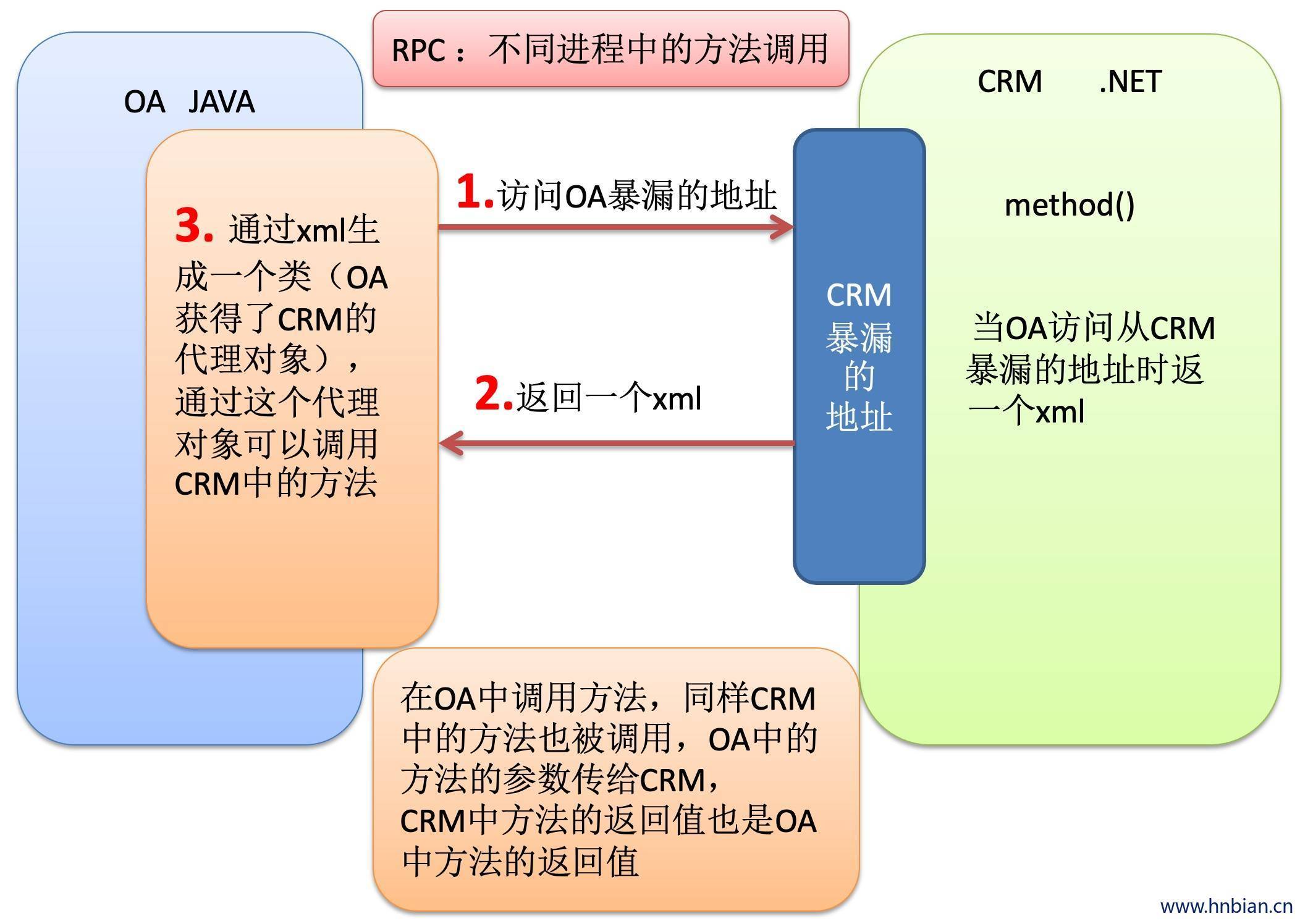
5.2 基于hadoop的RPC实现代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| package cn.itcast.hadoop.rpc;
import java.io.IOException;
import org.apache.hadoop.HadoopIllegalArgumentException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.ipc.RPC;
import org.apache.hadoop.ipc.RPC.Server;
public class RPCServer2 implements Bizable{
public String sysHi(String name){
return "HI!!"+name;
}
public static void main(String[] args) throws HadoopIllegalArgumentException, IOException {
Configuration conf = new Configuration();
Server server = new RPC.Builder(conf)
.setProtocol(Bizable.class)
.setInstance(new RPCServer2())
.setBindAddress("192.168.0.102")
.setPort(9527)
.build();
server.start();
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
package cn.itcast.hadoop.rpc;
import java.io.IOException;
import java.net.InetSocketAddress;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.ipc.RPC;
public class RPCClient2 {
public static void main(String[] args) throws IOException {
Bizable proxy = RPC.getProxy(Bizable.class, 10010, new InetSocketAddress("123.57.205.179",9527), new Configuration());
String result = proxy.sysHi("xiaoming");
System.out.println(result);
RPC.stopProxy(proxy);
}
}
|
1
2
3
4
5
6
7
8
|
package cn.itcast.hadoop.rpc;
public interface Bizable {
public static final long versionID=10010;
public String sysHi(String name);
}
|
RPC 不同进程间的方法调用而不是简单的传递字符串.。底层是socket
6. HDFS接口简单调用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
|
19. package cn.itcast.hadoop.hdfs;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.URI;
import java.net.URISyntaxException;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.conf.Configuration;
import org.junit.Before;
import org.junit.Test;
public class HDFSdemohn {
static FileSystem fs = null;
@Before
public void init() throws IOException, URISyntaxException, InterruptedException{
fs = FileSystem.get(new URI("hdfs://hadoop1:9000"), new Configuration(),"root");
}
@Test
public void testUpload() throws IllegalArgumentException, IOException{
InputStream in = new FileInputStream("c://apache-ant-1.9.4-bin.tar.gz");
OutputStream out = fs.create(new Path("/test.gz"));
IOUtils.copyBytes(in, out, 4096, true);
}
@Test
public void testDownload() throws IllegalArgumentException, IOException{
fs.copyToLocalFile(new Path("/input"), new Path("c:/inputtmp"));
};
@Test
public void testMkdir() throws IllegalArgumentException, IOException{
boolean b = fs.mkdirs(new Path("/dir1"));
System.out.println(b);
}
@Test
public void delFile() throws IllegalArgumentException, IOException{
boolean b = fs.delete(new Path("/input"), true);
System.out.println(b);
}
public static void main(String[] args) throws URISyntaxException {
try {
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop1:9000"), new Configuration());
InputStream in = fs.open(new Path("/input"));
OutputStream out = new FileOutputStream("c:/inputtmp");
IOUtils.copyBytes(in, out, 4096, true);
} catch (IOException e) {
e.printStackTrace();
}
}
}
|
7.HDFS shell 介绍
通过hdfs 命令操作 hdfs文件
调用文件系统(FS)shell命令应使用bin/hadoop fs的形式
所有的FS shell命令使用URI路径作为参数。
- URI的格式是scheme://authority/path。
- HDFS的scheme是HDFS,对本地文件系统,
- scheme是file。其中scheme和authonrity参与都是可选的,如果未加指定,就会使用配置中指定的默认scheme。
例如:/parent/child 可以表示成 hdfs://namenode:namenodePort/parrnt/child, 或者更简单的/parent/child(假设配置文件是namenode:namenodePort)
大多数FS shell命令的行为和对应UNIX shell命令类似
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| # 1. 启动hdfs
cd /hnbian/hadoop-2.2.0/sbin
./start-dfs.sh
# 2. 查看帮助
hadoop fs -help <cmd>
# 3. 通过命令查看hdfs根目录下的文件
hadoop fs -ls hdfs://hadoop1:9000/
hadoop fs -ls /
# 4. 上传文件
hadoop fs -copyFromLocal /root/install.log /in.log
# 5. 查看内容
hadoop fs -cat /in.log
# 6. 查看根目录 文件数量
hadoop fs -count /
# 7. 删掉文件夹
hadoop fs -rm -r /tmp
# 8. 删掉文件
hadoop fs -rm /tmp.txt
# 9. 给文件赋权限(给文件所有组都赋予执行权限)
hadoop fs -chmod a+x /in.log
# 10. 给文件夹减去限(给文件夹所有组都减去执行权限)
hadoop fs -chmod -R -x /wcout
# 11. 修改文件所属用户
hadoop fs -chown supergroup /in.log
# 12. 修改文件所属组
hadoop fs -chgrp root /in.log
# 13. 一次递归更文件夹用户组与所属用户
hadoop fs -chown -R supergroup:root /wcout
# 14. hdfs 命令 2.0 之后
# 15. hdfs dfs -ls /
hadoop jar /hnbian/hadoop-2.2.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jar wordcount /aaa.txt /wcount
# 16. put上传文件
hadoop fs -put /<本地文件夹> /<目标文件夹>/<文件名称>
|
8. 源码解析
获得fs的过程
通过读取配置文件获得实现类
通过反射将实现类进行初始化(很多成员变量没有初始化)
调用init方法(多态new谁调用谁的方法)
在init方法里面 new一个dfsclient 将dfsclient作为成员变量,然后在dfsclient里面 通过hadoop的rpc机制 获得server端的代理对象
对代理对象进行增强(动态代理模式),将代理对象作为dfsclient 的成员变量
初始化完成之后得到一个FileSystem
调用FileSystem.open 在open里面抓取块的信息(客户端通过rpc机制跟NameNode通信 将要下载的文件作为参数传给NameNode,NameNode查询之后反馈给客户端,然后客户端将块的信息作为流的成员变量,以后流想读谁就读谁)

9.Java 操作 HDFS
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
| import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import org.apache.commons.compress.utils.IOUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.LocatedFileStatus;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.RemoteIterator;
import org.junit.Before;
import org.junit.Test;
public class HdfsUtil {
FileSystem fs = null;
@Before
public void init() throws IOException{
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://had1:9000/");
fs = FileSystem.get(conf);
}
@Test
public void upload() throws Exception{
Path dst = new Path("hdfs://had1:9000/word.txt");
FSDataOutputStream out = fs.create(dst);
FileInputStream ist = new FileInputStream("c://ww.txt");
IOUtils.copy(ist, out);
}
@Test
public void upload2() throws IllegalArgumentException, IOException {
fs.copyFromLocalFile(new Path("c://ww.txt"), new Path("hdfs://had1:9000/word.txt"));
}
@Test
public void download() throws IllegalArgumentException, IOException{
fs.copyToLocalFile(new Path("hdfs://had1:9000/slaves.sh"),new Path("c://www.txt"));
}
@Test
public void mkdir() throws IllegalArgumentException, IOException{
fs.mkdirs(new Path("/mk/mkd/mkdi/mkdii"));
}
@Test
public void rmdir() throws IllegalArgumentException, IOException{
fs.delete(new Path("/mk/mkd/mkdi/mkdii"),true);
}
@Test
public void listFiles() throws FileNotFoundException, IllegalArgumentException, IOException{
RemoteIterator<LocatedFileStatus> files = fs.listFiles(new Path("/"), true);
while(files.next() != null){
LocatedFileStatus f = files.next();
System.out.println(f.getPath().getName());
}
FileStatus[] ff= fs.listStatus(new Path("/"));
for(FileStatus status:ff){
String name = status.getPath().getName();
System.out.println(name+(status.isDirectory()?" is dir":" is file"));
}
}
}
|
10. 压缩 HDFS 文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
public static void compress(String codecClassName, String dir, String f,
String inPath) throws Exception {
Class<?> codecClass = Class.forName(codecClassName);
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
CompressionCodec codec = (CompressionCodec) ReflectionUtils
.newInstance(codecClass, conf);
if (fs.exists(new Path(inPath))) {
if (!fs.exists(new Path(dir))) {
fs.mkdirs(new Path(dir));
}
outputStream = fs.create(new Path(f));
in = fs.open(new Path(inPath));
CompressionOutputStream out = codec.createOutputStream(outputStream);
IOUtils.copyBytes(in, out, conf);
IOUtils.closeStream(in);
IOUtils.closeStream(out);
if (fs.exists(new Path(f))) {
logger.info("successfuly,the gzip file created :{}", f);
}
} else {
logger.info("in file not exists :{}", inPath);
}
}
|
