1. SparkSQL 概述 1.1 Shark
Shark 是 Databricks 开发出专门针对于spark的构建大规模数据仓库系统的一个框架
Shark 与 Hive 兼容,同时也依赖于Spark版本
Shark是把sql语句解析成了Spark任务,Hivesql 底层把 sql 解析成了 mapreduce 程序
随着对 Shark 性能优化的上限,以及集成SQL的一些复杂的分析功能,发现Hive的MapReduce思想限制了Shark的发展
最后 Databricks 公司终止对 Shark 的开发,决定单独开发一个框架,不在依赖hive,把重点转移到了 SparkSQL 这个框架上
1.2 SparkSQL 是什么
Spark SQL is Apache Spark’s module for working with structured data.
SparkSQL是apache Spark用来处理结构化数据的一个模块
1.3 SparkSQL 的特性
易整合
SparkSQL将SQL查询与Spark程序无缝混合
SparkSQL 可以使用java、Scala、Python、R 等不同的语言进行代码开发
统一的数据源访问
1 2 val dataFrame = sparkSession.read.文件格式的方法名("该文件格式的路径" )
兼容hive
SparkSQL 可以支持 HiveSql 这种语法
支持标准的数据库连接
SparkSQL支持标准的数据库连接JDBC或者ODBC
2. DataFrame 2.1 DataFrame的由来
DataFrame 前身是 schemaRDD,schemaRDD 是RDD的一个实现类,直接继承自 RDD
在spark1.3.0之后把 schemaRDD 改名为 DataFrame,它不在继承自RDD,而是自己实现RDD上的一些功能
DataFrame也可以调用rdd方法将其转换成一个rdd
2.2 DataFrame是什么
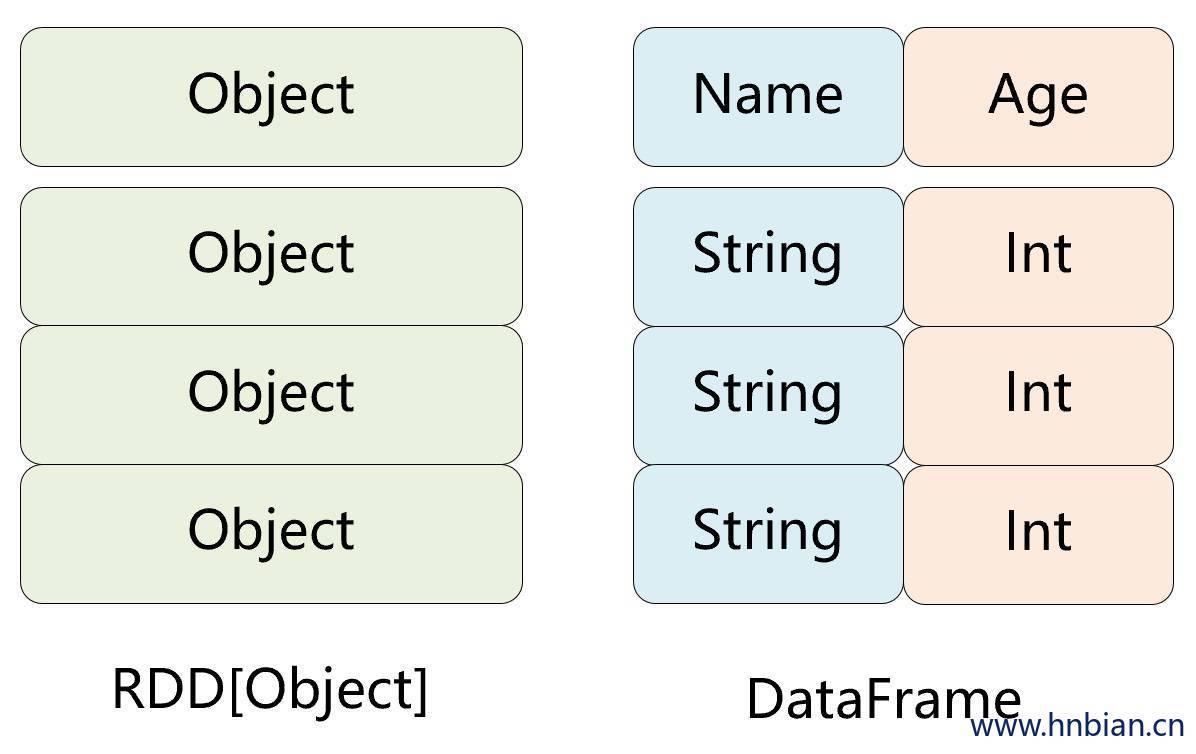
DataFrame 是Spark中一种 以RDD为基础的分布式数据集,类似于传统数据库的表格
DataFrame 带有 Schema元信息 ,即DataFrame所表示的二维表数据集的每一列都带有名称和类型,但底层做了更多的优化
DataFrame 可以从很多数据源构建,比如:已经存在的RDD、结构化文件、外部数据库、Hive表
DataFrame 可以把内部是一个Row对象,它表示一行一行的数据(RDD可以把它内部元素看成是一个java对象)
DataFrame 相比于rdd来说,多了对数据的描述的schema元信息
2.3 DataFrame和RDD的对比 2.3.1 RDD
编译时类型安全开发会进行类型检查
在编译的时候及时发现错误 具有面向对象编程的风格
构建大量的java对象占用了大量heap堆空间,导致频繁的GC
由于数据集RDD它的数据量比较大,后期都需要存储在heap堆中,这里有heap堆中的内存空间有限,出现频繁的垃圾回收(GC),程序在进行垃圾回收的过程中,所有的任务都是暂停。影响程序执行的效率
数据的序列化和反序列性能开销很大
在分布式程序中,对象(对象的内容和结构)是先进行序列化,发送到其他服务器,进行大量的网络传输,然后接受到这些序列化的数据之后,再进行反序列化来恢复该对象
2.3.2 DataFrame
DataFrame 引入off-heap(堆外内存) ,大量的对象构建直接使用操作系统层面上的内存,不在使用heap堆中的内存,这样一来heap堆中的内存空间就比较充足,不会导致频繁GC,程序的运行效率比较高,它是解决了RDD构建大量的java对象占用了大量heap堆空间,导致频繁的GC这个缺点。
DataFrame 引入了schema元信息,就是数据结构的描述信息,后期spark程序中的大量对象在进行网络传输的时候,只需要把数据的内容本身进行序列化就可以,数据结构信息可以省略掉。这样一来数据网络传输的数据量是有所减少,数据的序列化和反序列性能开销就不是很大了。它是解决了RDD数据的序列化和反序列性能开销很大这个缺点
DataFrame引入了schema元信息和off-heap(堆外)它是分别解决了RDD的缺点,同时它也丢失了RDD的优点
编译时类型不安全,编译时不会进行类型的检查,这里也就意味着前期是无法在编译的时候发现错误,只有在运行的时候才会发现
不在具有面向对象编程的风格
2.4 构建DataFrame 前提工作
1 2 3 4 5 6 7 8 9 10 11 12 13 # 1. 将数据文件传到服务器上 scp dataFile userName@serverNode:/path # dataFile 数据文件 # username 登录到服务器的用户名 # serverNode 将数据上传到哪台服务器 # path 保存数据的路径 # 2. 进入 spark Home 目录 cd /opt/spark-2.3.3-bin-hadoop2.7/ # 3. 启动 spark shell bin/spark-shell --master local[2] --jars /opt/hadoop-2.6.0-cdh5.14.2/share/hadoop/common/hadoop-lzo-0.4.20.jar
2.4.1 通过文本创建 DataFrame 1 2 3 4 5 6 7 8 9 10 val personDF=spark.read.text("file:///sparkdatas/person.txt" )personDF.printSchema personDF.show
1 2 3 4 5 6 7 8 9 10 11 12 13 val rdd1=sc.textFile("file:///sparkdatas/person.txt" ).map(x=>x.split(" " ))case class Person (id:String ,name:String ,age:Int )val personRDD=rdd1.map(x=>Person (x(0 ),x(1 ),x(2 ).toInt))val personDF=personRDD.toDFpersonDF.printSchema personDF.show
2.4.2 通过JSON文件创建 DataFrame 1 2 3 4 5 6 7 val df1=spark.read.json("file:///sparkdatas/person.json" )df1.printSchema df1.show
2.4.3 通过Parquet创建 DataFrame 1 2 3 4 5 6 7 val df2=spark.read.parquet("file:///sparkdatas/person.parquet" )df2.printSchema df2.show
2.5 DataFrame API 2.5.1 引入依赖 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 <dependencies > <dependency > <groupId > org.apache.spark</groupId > <artifactId > spark-core_2.11</artifactId > <version > 2.3.3</version > <exclusions > <exclusion > <groupId > org.apache.avro</groupId > <artifactId > avro-mapred</artifactId > </exclusion > </exclusions > </dependency > <dependency > <groupId > org.apache.commons</groupId > <artifactId > commons-lang3</artifactId > <version > 3.7</version > </dependency > <dependency > <groupId > org.apache.hadoop</groupId > <artifactId > hadoop-core</artifactId > <version > 2.6.0-mr1-cdh5.14.2</version > <exclusions > <exclusion > <groupId > org.apache.zookeeper</groupId > <artifactId > zookeeper</artifactId > </exclusion > </exclusions > </dependency > <dependency > <groupId > org.apache.hbase</groupId > <artifactId > hbase-common</artifactId > <version > 1.2.0-cdh5.14.2</version > </dependency > <dependency > <groupId > org.apache.hbase</groupId > <artifactId > hbase-client</artifactId > <version > 1.2.0-cdh5.14.2</version > </dependency > <dependency > <groupId > org.apache.spark</groupId > <artifactId > spark-sql_2.11</artifactId > <version > 2.3.3</version > </dependency > </dependencies >
2.5.2 常用 API 示例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 import org.apache.spark.{SparkConf , SparkContext }import org.apache.spark.sql.SparkSession case class Person (id:String ,name:String ,age:Int )object SparkDSL def main Array [String ]): Unit = { val sparkConf: SparkConf = new SparkConf ().setMaster("local[2]" ).setAppName("sparkDSL" ) val sparkSession: SparkSession = SparkSession .builder().config(sparkConf).getOrCreate() val sc: SparkContext = sparkSession.sparkContext sc.setLogLevel("WARN" ) val rdd1=sc.textFile("file:///D:\\datas/person.txt" ).map(x=>x.split(" " )) val personRDD=rdd1.map(x=>Person (x(0 ),x(1 ),x(2 ).toInt)) import sparkSession.implicits._ val personDF=personRDD.toDF personDF.printSchema personDF.show personDF.select("name" ).show personDF.select($"name" ).show personDF.select($"name" ,$"age" ,$"age" +1 ).show() personDF.filter($"age" > 30 ).show personDF.groupBy("age" ).count.show personDF.groupBy("age" ).count().sort($"count" .desc).show sparkSession.stop() sc.stop() } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 import org.apache.spark.{SparkConf , SparkContext }import org.apache.spark.sql.SparkSession case class Person (id:String ,name:String ,age:Int )object SparkDSL def main Array [String ]): Unit = { val sparkConf: SparkConf = new SparkConf ().setMaster("local[2]" ).setAppName("sparkDSL" ) val sparkSession: SparkSession = SparkSession .builder().config(sparkConf).getOrCreate() val sc: SparkContext = sparkSession.sparkContext sc.setLogLevel("WARN" ) val rdd1=sc.textFile("file:///D:\\datas/person.txt" ).map(x=>x.split(" " )) val personRDD=rdd1.map(x=>Person (x(0 ),x(1 ),x(2 ).toInt)) import sparkSession.implicits._ val personDF=personRDD.toDF personDF.printSchema personDF.show personDF.createTempView("person" ) spark.sql("select * from person" ).show spark.sql("select name from person" ).show spark.sql("select name,age from person" ).show spark.sql("select * from person where age >30" ).show spark.sql("select count(*) from person where age >30" ).show spark.sql("select age,count(*) from person group by age" ).show spark.sql("select age,count(*) as count from person group by age" ).show spark.sql("select * from person order by age desc" ).show sparkSession.stop() sc.stop() } }
3. DataSet 3.1 DataSet是什么
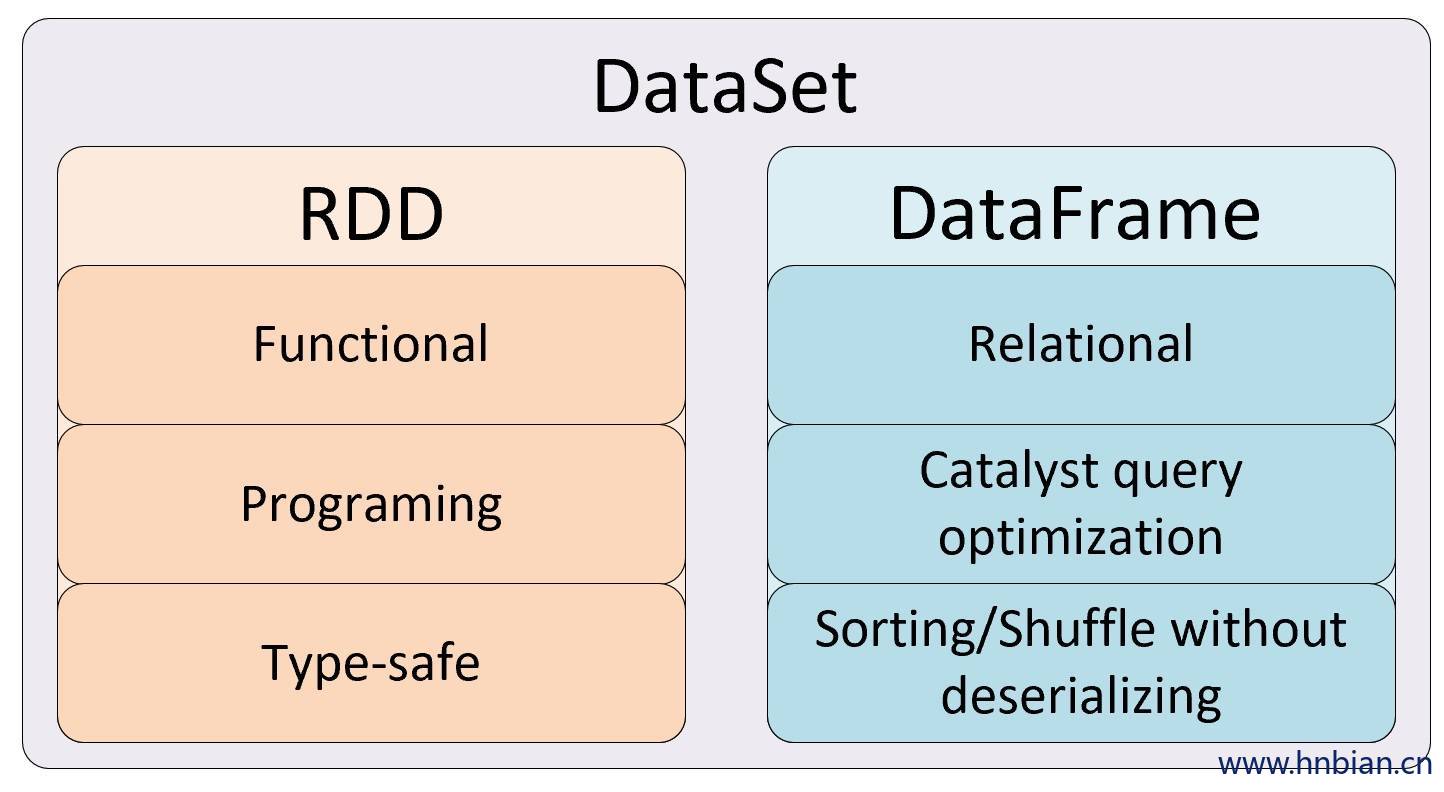
DataSet 是分布式的数据集合,Dataset提供了 强类型支持 ,也是在RDD的每行数据加了类型约束。
DataSet 是在Spark1.6中添加的新的接口,它集中了RDD的优点,强类型和可以用强大lambda函数以及使用了Spark SQL优化的执行引擎。
DataSet 包含了 DataFrame 的功能,Spark2.0中两者统一
DataFrame 表示为DataSet[Row],即DataSet的子集
DataSet可以在编译时检查类型,并且是面向对象的编程接口。
3.2 构建 DataSet
通过sparkSession调用createDataset方法
1 2 val ds = spark.createDataset(1 to 10 ) val ds = spark.createDataset(sc.textFile("/person.txt" ))
使用scala集合和rdd调用toDS方法
1 2 sc.textFile("/person.txt" ).toDS List (1 ,2 ,3 ,4 ,5 ).toDS
把一个DataFrame转换成DataSet
1 val dataSet=dataFrame.as[强类型]
通过一个DataSet转换生成一个新的DataSet
1 List (1 ,2 ,3 ,4 ,5 ).toDS.map(x=>x*10 )
3.2 RDD,DataFrame,DataSet的区别与联系 Spark RDD、DataFrame和DataSet是Spark的三类API,DataFrame是spark1.3.0版本提出来的,spark1.6.0版本又引入了DateSet的,但是在spark2.0版本中,DataFrame和DataSet合并为DataSet。
3.2.1 RDD
相比于传统的MapReduce框架,Spark在RDD中内置很多函数操作,group,map,filter等,方便处理结构化或非结构化数据
面向对象编程,直接存储的java对象,类型转化也安全
由于它基本和hadoop一样万能的,因此没有针对特殊场景的优化,比如对于结构化数据处理相对于sql来比非常麻烦
默认采用的是java序列号方式,序列化结果比较大,而且数据存储在java堆内存中,导致gc比较频繁
3.2.2DataFrame
结构化数据处理非常方便,支持Avro, CSV, elastic search, and Cassandra等kv数据,也支持HIVE tables, MySQL等传统数据表
有针对性的优化,如采用Kryo序列化,由于数据结构元信息spark已经保存,序列化时不需要带上元信息,大大的减少了序列化大小,而且数据保存在堆外内存中,减少了gc次数,所以运行更快。
hive兼容,支持hql、udf等
编译时不能类型转化安全检查,运行时才能确定是否有问题
对于对象支持不友好,rdd内部数据直接以java对象存储,dataframe内存存储的是row对象而不能是自定义对象
3.2.3 DateSet
DateSet整合了RDD和DataFrame的优点,支持结构化和非结构化数据
和RDD一样,支持自定义对象存储
和DataFrame一样,支持结构化数据的sql查询
采用堆外内存存储,gc友好
类型转化安全,代码友好
3.3 RDD,DataFrame,DataSet数据结构
4. DataFrame,DataSet转换 4.1 介绍转换方式
把一个DataFrame转换成DataSet
1 val dataSet = dataFrame.as[强类型]
把一个DataSet转换成DataFrame
1 val dataFrame=dataSet.toDF
可以从dataFrame和dataSet获取得到rdd
1 2 3 val rdd1=dataFrame.rddval rdd2=dataSet.rdd
4.2 测试代码 4.2.1 利用反射机制 通常应用在在开发代码之前,是可以先确定好DataFrame的schema元信息的情况。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 case class Person (id:String ,name:String ,age:Int )import org.apache.spark.SparkContext import org.apache.spark.rdd.RDD import org.apache.spark.sql.{Column , DataFrame , Row , SparkSession }case class Person (id:String ,name:String ,age:Int )object CaseClassSchema def main Array [String ]): Unit = { val spark: SparkSession = SparkSession .builder().appName("CaseClassSchema" ).master("local[2]" ).getOrCreate() val sc: SparkContext = spark.sparkContext sc.setLogLevel("warn" ) val data: RDD [Array [String ]] = sc.textFile("file:///D:\\datas" ).map(x=>x.split(" " )) val personRDD: RDD [Person ] = data.map(x=>Person (x(0 ),x(1 ),x(2 ).toInt)) import spark.implicits._ val personDF: DataFrame = personRDD.toDF personDF.printSchema() personDF.show() val first: Row = personDF.first() println("first:" +first) val top3: Array [Row ] = personDF.head(3 ) top3.foreach(println) personDF.select("name" ).show() personDF.select($"name" ).show() personDF.select(new Column ("name" )).show() personDF.select("name" ,"age" ).show() personDF.select($"name" ,$"age" ,$"age" +1 ).show() personDF.filter($"age" >30 ).show() val count: Long = personDF.filter($"age" >30 ).count() println("count:" +count) personDF.groupBy("age" ).count().show() personDF.show() personDF.foreach(row => println(row)) personDF.foreach(row =>println(row.getAs[String ]("name" ))) personDF.foreach(row =>println(row.get(1 ))) personDF.foreach(row =>println(row.getString(1 ))) personDF.foreach(row =>println(row.getAs[String ](1 ))) personDF.createTempView("person" ) spark.sql("select * from person" ).show spark.sql("select name from person" ).show spark.sql("select name,age from person" ).show spark.sql("select * from person where age >30" ).show spark.sql("select count(*) from person where age >30" ).show spark.sql("select age,count(*) from person group by age" ).show spark.sql("select age,count(*) as count from person group by age" ).show spark.sql("select * from person order by age desc" ).show spark.stop() } }
4.2.2 通过StructType动态指定Schema
通常应用在,在开发代码之前,是无法确定需要的DataFrame对应的schema元信息的情况。需要在开发代码的过程中动态指定。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 import org.apache.spark.SparkContext import org.apache.spark.rdd.RDD import org.apache.spark.sql.types.{IntegerType , StringType , StructField , StructType }import org.apache.spark.sql.{DataFrame , Row , SparkSession }object StructTypeSchema def main Array [String ]): Unit = { val spark: SparkSession = SparkSession .builder().appName("StructTypeSchema" ).master("local[2]" ).getOrCreate() val sc: SparkContext = spark.sparkContext sc.setLogLevel("warn" ) val data: RDD [Array [String ]] = sc.textFile("file:///D:\\datas" ).map(x=>x.split(" " )) val rowRDD: RDD [Row ] = data.map(x=>Row (x(0 ),x(1 ),x(2 ).toInt)) val schema=StructType ( StructField ("id" ,StringType ):: StructField ("name" ,StringType ):: StructField ("age" ,IntegerType )::Nil ) val dataFrame: DataFrame = spark.createDataFrame(rowRDD,schema) dataFrame.printSchema() dataFrame.show() dataFrame.createTempView("user" ) spark.sql("select * from user" ).show() spark.stop() } }
5. SparkSQL 读取与写入数据示例 5.1 SparkSQL读取sql数据 spark sql可以通过 JDBC 从关系型数据库中读取数据的方式创建DataFrame,通过对DataFrame一系列的计算后,还可以将数据再写回关系型数据库中
1 2 3 4 5 <dependency > <groupId > mysql</groupId > <artifactId > mysql-connector-java</artifactId > <version > 5.1.38</version > </dependency >
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 import java.util.Properties import org.apache.spark.SparkConf import org.apache.spark.sql.{DataFrame , SparkSession }object DataFromMysql def main Array [String ]): Unit = { val sparkConf: SparkConf = new SparkConf ().setAppName("DataFromMysql" ).setMaster("local[2]" ) val spark: SparkSession = SparkSession .builder().config(sparkConf).getOrCreate() val url="jdbc:mysql://localhost:3306/mydb?characterEncoding=UTF-8" val tableName="jobdetail" val properties = new Properties () properties.setProperty("user" ,"root" ) properties.setProperty("password" ,"123456" ) val mysqlDF: DataFrame = spark.read.jdbc(url,tableName,properties) mysqlDF.printSchema() mysqlDF.show() mysqlDF.createTempView("job_detail" ) spark.sql("select * from job_detail where city = '广东' " ).show() spark.stop() } }
5.2 sparkSQL读取CSV文建写入MySQL 使用spark程序读取CSV文件,然后将读取到的数据内容,保存到mysql里面去,注意csv文件的换行问题。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 import java.util.Properties import org.apache.spark.SparkConf import org.apache.spark.sql.{DataFrame , SaveMode , SparkSession }object CSVOperate def main Array [String ]): Unit = { val sparkConf: SparkConf = new SparkConf ().setMaster("local[8]" ).setAppName("sparkCSV" ) val session: SparkSession = SparkSession .builder().config(sparkConf).getOrCreate() session.sparkContext.setLogLevel("WARN" ) val frame: DataFrame = session .read .format("csv" ) .option("timestampFormat" , "yyyy/MM/dd HH:mm:ss ZZ" ) .option("header" , "true" ) .option("multiLine" , true ) .load("file:///D:\\datas" ) frame.createOrReplaceTempView("job_detail" ) val prop = new Properties () prop.put("user" , "root" ) prop.put("password" , "123456" ) frame.write.mode(SaveMode .Append ).jdbc("jdbc:mysql://localhost:3306/mydb?useSSL=false&useUnicode=true&characterEncoding=UTF-8" , "mydb.jobdetail_copy" , prop) } }