1. HBase 介绍
HBase是一个开源的非关系型分布式数据库,它参考了谷歌的BigTable建模,实现的编程语言为Java。它是Apache软件基金会的Hadoop项目的一部分,运行于HDFS文件系统之上,为 Hadoop 提供类似于BigTable 规模的服务。因此,它可以容错地存储海量稀疏的数据。
HBase是一个高可靠、高性能、面向列、可伸缩的分布式数据库,是谷歌BigTable的开源实现,主要用来存储非结构化和半结构化的松散数据。HBase的目标是处理非常庞大的表,可以通过水平扩展的方式,利用廉价计算机集群处理由超过10亿行数据和数百万列元素组成的数据表。
2. HBase集群部署
HBase 部署文档地址:https://www.hnbian.cn/posts/fdea61c2.html#toc-heading-87
3.HBase 架构
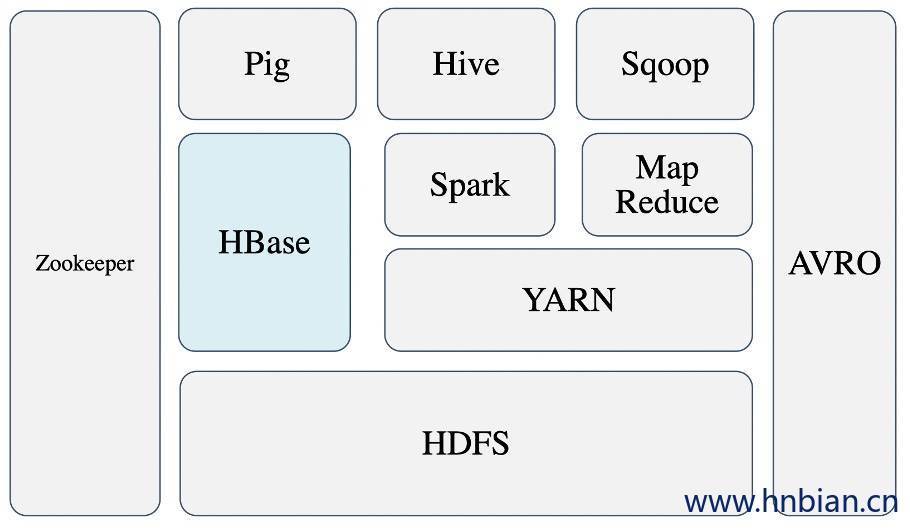
上图描述了Hadoop 生态系统中的各层系统,HBase位于结构化存储层,Hadoop HDFS为HBase提供了高可靠性的底层存储支持,Zookeeper为HBase提供了稳定服务和故障转移机制。
此外,Pig和Hive还为HBase提供了高层语言支持,使得在HBase上进行数据统计处理变的非常简单。 Sqoop则为HBase提供了方便的RDBMS数据导入功能,使得传统数据库数据向HBase中迁移变的非常方便。
- HBase 系统架构
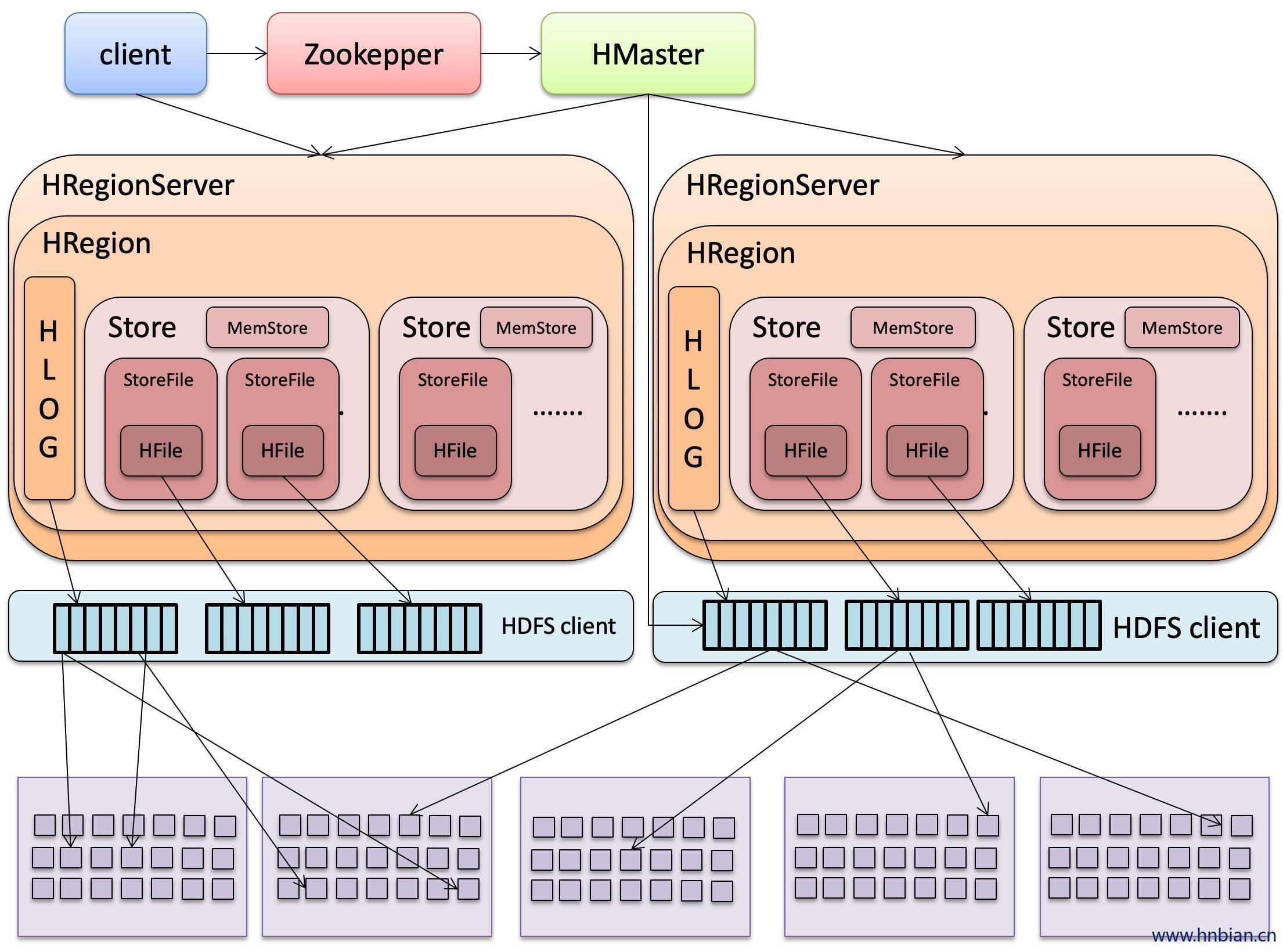
- Client
包含访问HBase的接口,Client维护着一些cache(缓存)来加快对HBase的访问,比如Region的位置信息
- Zookepper(协调者)
保证任何之后,集群中只有一个Hmaster(选举机制Master selete)
存储所有Region的寻址入口
实时监控HRegionServer的状态,将HRegionServer的上线下线信息实时通知给Hmaster
存储HBase的schema(元数据),包括有哪些table,每个table有哪些column family
- Master
为HRegionServer分配Region
负责HRegionServer的负载均衡
发现失效的HRegionServer 并重新分配其上的Region(高可靠性)
GFS上的垃圾文件回收
处理schema更新请求(进行ddl的操作)
- HRegionServer
HRegionServer 维护Hmaster 分配给他的Region,处理对这些Region的IO请求
HRegionServer负责切分在运行中变得过大的Region 可以看到,Client访问HBase上的数据过程并不需要HMaster的参与(寻址访问Zookepper和HRegionServer,读写HRegionServer),HMaster仅仅维护着table和Region的元数据信息,负载很低
- region
按大小分割的,每个表开始只有一个region,随着数据不管插入表,region不断增大,当增大到一个阀值的时候 ,Hregion 会等分为两个新的region,当table中的行不断增多,就会有越来越多的reigon.
HregionServer负责分割region,HMaster负责迁移region
- Hregion是HBase中分布式存储和负载均衡的最小单元。最小单元就表示不同的HRegion可以分布在不同的HRegionServer上,但是一个HRegion是不会拆分到多个Server上的
- HRegion虽然是分布式存储的最小单元,但并不是存储的最小单元
- 事实上,HRegion由一个或者多个Store组成,每个store保存一个columns family。每个store又由一个memStore和0至多个StoreFile组成
- StoreFile以HFile格式保存在HDFS上
(Hbase:meta
HBase:namespace)
HBase中有两张特殊的table,-ROOT-和.META.
-ROOT-:记录了.META.表的Region信息,-ROOT-只有一个Region
.META.:记录了用户创建的表的Region信息,.META.可以有多个Region
Zookepper中记录了-ROOT-表的location
Client 访问用户数据之前,需要首先访问Zookepper,然后访问-ROOT-表,接着访问.META.表,最后才能找到用户数据的位置去访问
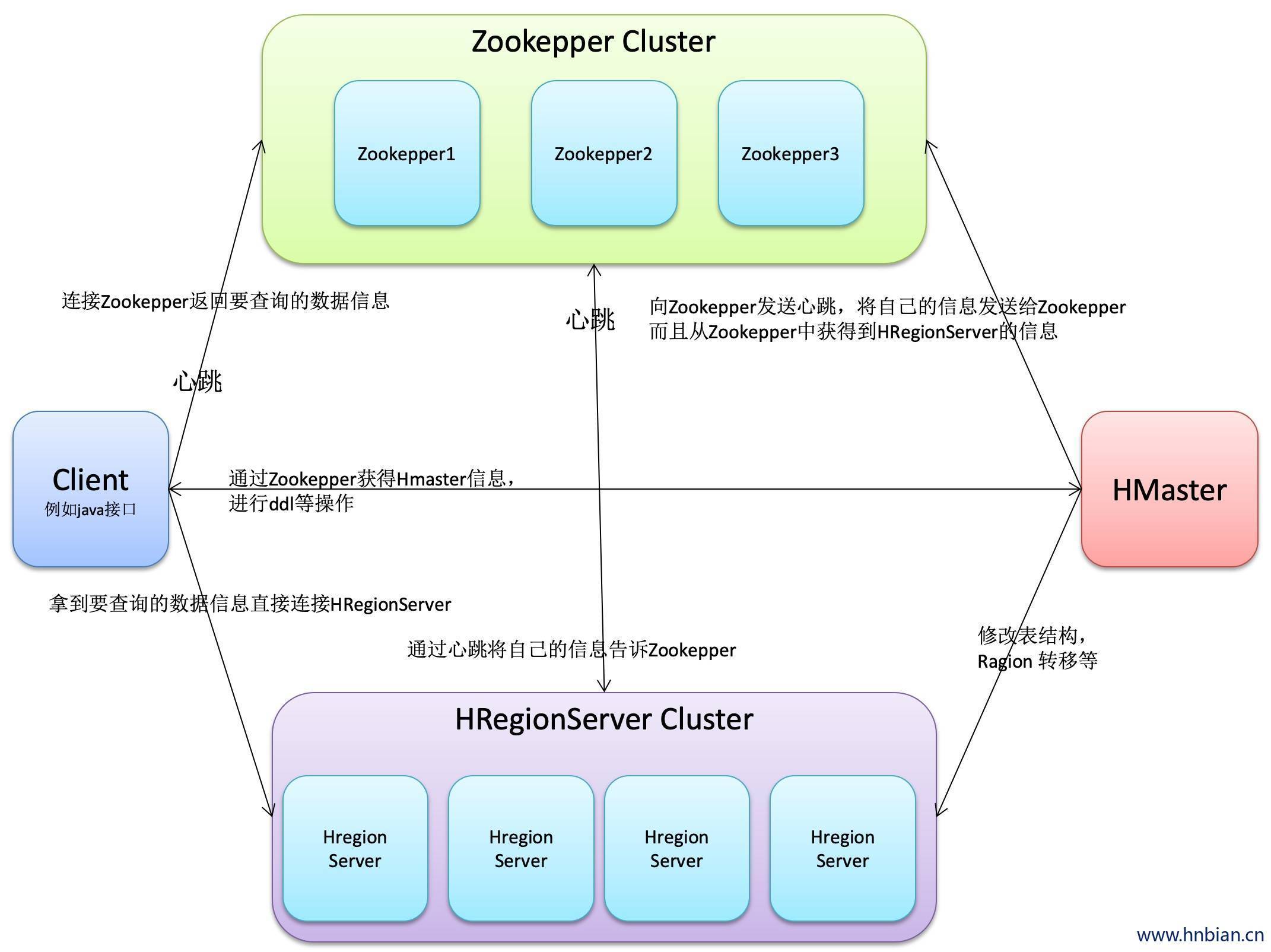
Hbase的体系结构是一个主从式的结构,主节点Hmaster在整个集群当中只有一个在运行,从节点HRegionServer有很多个在运行,主节点Hmaster与从节点HRegionServer实际上指的是不同的物理机器,即有一个机器上面跑的进程是Hmaster,很多机器上面跑的进程是HRegionServer,Hmaster没有单点问题,Hbase集群当中可以启动多个Hmaster,但是通过zookeeper的事件处理机制保证整个集群当中只有一个Hmaster在运行。
Hamster:为HRegionServer分配Region,负责HRegionServer的负载均衡,发现失效的HRegionServer并重新分配其上的Region(高可靠性),GFS上的垃圾文件回收,处理schema更新请求(进行ddl的操作)Client:包含访问 HBase 的接口,Client维护着一些cache(缓存)来加快对HBase的访问,比如Region的位置信息Zookepper(协调者):保证任何时候,集群中只有一个Hmaster,存储所有Region的寻址入口,实时监控HRegionServer的状态,将HRegionServer的上线下线信息实时通知给Hmaster,存储HBase的schema(元数据),包括有哪些table,每个table有哪些column familyHRegionServer:内部管理类一系列HRegion对象,每个HRegion对应 Table 中的一个Region。HRegion:由许多Store组成。Store:是HBase的存储核心,由MemStore和StoreFile组成,每个Store包含一个MemStore和0到多个StoreFile。Store对应 Table 中的一个Column Family的存储,即一个Store管理一个Region上的一个列族(CF)。数据在写入时,首先写入预写日志(Write Ahead Log),每个HRegionServer服务的所有Region的写操作日志都存储在一个日志文件中。数据并非直接写入HDFS,而是等缓存到一定数量再批量写入,写入完成后在日志中做标记
MemStore:是一个有序的内存缓冲区,用户写入的数据首先放入MemStore,当MemStore满了以后Flush成一个StoreFile(存储是应为HFile),当StoreFile数量到一定阈值,触发Compact合并,将多个StoreFile合并成一个StoreFile。StoreFiles合并后逐步形成越来越大的StoreFile,当Region内所有的StoreFiles(HFile)的总大小超过阈值(hbase.hregion.max.filesize)即触发分裂,把当前的Region Split成两个Region,父Region下线,新Split的两个子Region被HMaster分配到合适的Region Server上,使得原先一个Region的压力分流到2个Region上。
4. HBase 数据存储细节
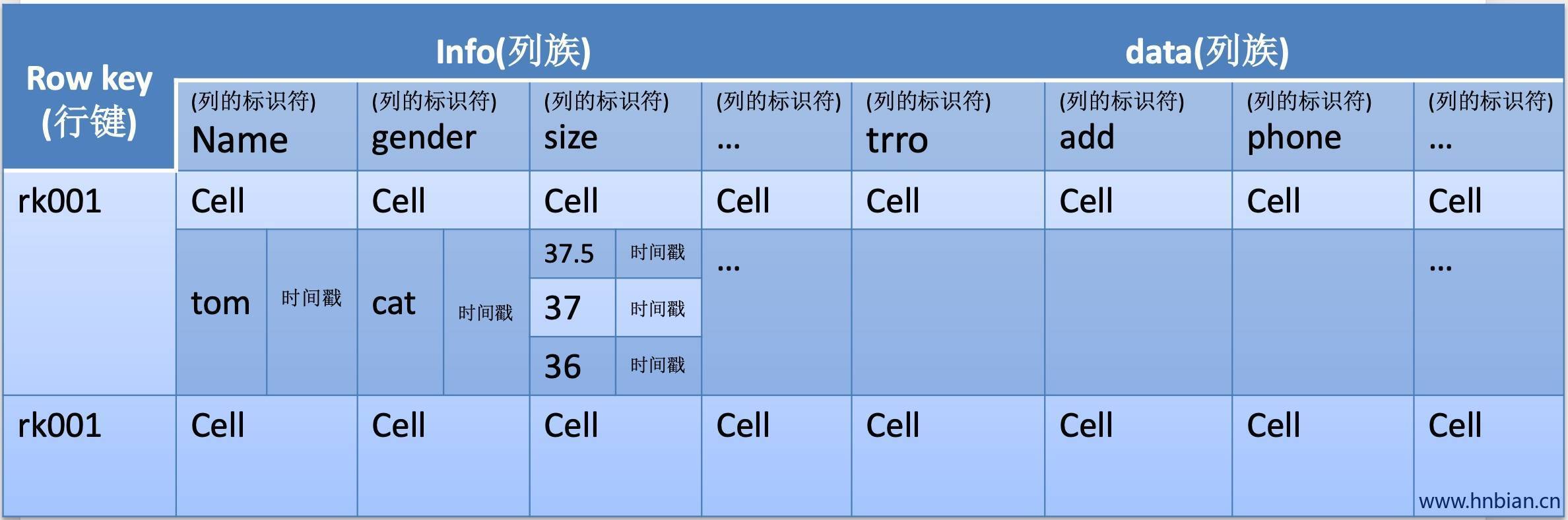
- 主键:Row Key
相当于关系表的主键,每一行数据的唯一标识。字符串、整数、二进制串都可以作为行键。HBase 中的数据按照RowKey排序后存储。访问Hbase table中的行,只有三种方式
1.通过单个row key
2.通过row key 的 range(范围 )
3.全表扫描
- 列族:Column Family
Column Family:简称CF,一个表在水平方向可以由一个到多个CF组成。一个CF可以由任意多个Column组成。Column是CF下的一组标签,可以在写数据时任意添加,因此CF支持动态扩展无须预先定义的Column的数量和类型。HBase中表的列非常稀疏,不同行的列个个数和类型都可以不同。此外每个CF都有独立的TTL(生存周期)。可以只对行上锁,对行的操作始终是原始的。
- 时间戳:timestamp
HBase中通过row和columns确定的为一个存贮单元称为cell。每个cell都保存着同一份数据的多个版本,版本通过时间戳来索引
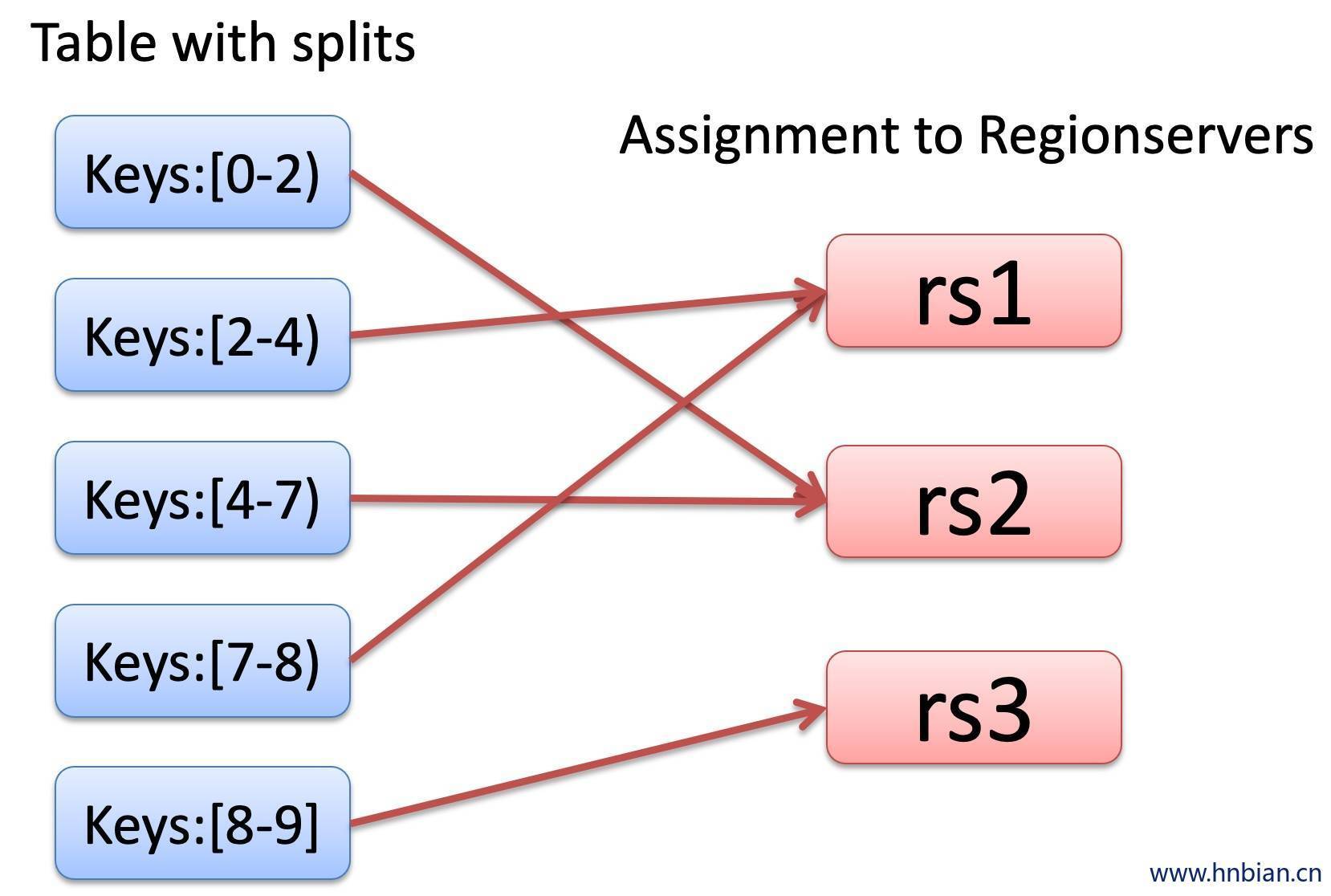
Hbase中的表会切分成若干个region进行存储,当Table随着记录数不断增加而变大后,Table在行的方向上会被切分成多个Region,一个Region由[startkey,endkey) 表示,每个Region会被Master分散到不同的HRegionServer上面进行存储,类似于我的block块会被分散到不同的DataNode节点上面进行存储。下面是Hbase表中的数据与HRegionServer的分布关系。
5. HBase shell
详细内容查看:https://www.hnbian.cn/posts/ec19e895.html
6. HBase API 中的常用类
6.1 Hbaseconfihuration
作用对Hbase进行配置
用法示例
HBaseConfiguration hconfig = new HBaseConfiguration;
Hconfig.set("hbase.zookepper.property.clientPort","2181");| 返回值 | 函数 | 描述 |
|---|---|---|
| Void | addResource(Path file) | 通过给定的路径所指的文件来添加资源 |
| void | dear | 清空所有已经设置的属性 |
| string | get(String name) | 获取属性名对应值 |
| string | getBoolean(String name,boolean defaultValue) | 获取为boolean类型的属性值,如果其属性值类型不为boolean,则返回其默认属性值 |
| void | set(String name,String value) | 通过属性名来设置值 |
| void | setBoolean(String name,boolean value) | 设置boolean类型的属性值 |
6.2 HBaseAdmin
包名:org.apache.hadoop.hbase.client.HBaseAdmin
作用:提供了一个接口来管理HBase数据库的表信息,它提供的方法包括:创建表,删除表,列出表项,使表无效,以及添加活删除表列族成员等
用法示例
HBaseAdmin admin = new HBaseAdmin(config);
admin.disableTable("tableName");| 返回值 | 函数 | 描述 |
|---|---|---|
| void | addColumn(String tableName,HColumnDescnptor column) | 向一个已经存在的表添加列 |
| void | checkHBaseAvailable(HBaseConfiguration conf) | 静态函数,查看Hbase 是否处于运行状态 |
| void | createTable(HTableDescriptor desc) | 创建一个表,同步操作 |
| void | deleteTable(byte[] tableName) | 删除一个已经存在的表 |
| void | enableTable(byte[] tableName) | 使表处于有效状态 |
| void | disableTable(byte[] tableName) | 使表处于无效状态 |
| HTableDescnptor | listTables | 列出所有用户控件表项 |
| void | modifyTable(byte[] tableName,HTableDescnptor htd) | 修改表的模式,是异步的操作,可能需要话费一定的时间 |
| boolean | tableExists(String tableName) | 检查表是否存在 |
6.3 HtableDescriptor
包名:org.apache.hadoop.hbase.HTableDescriptor
作用:包含了表的名字及其对应的列族
用法示例:
HtableDescriptor htd = new HtableDescriptor;
Htd.addFamily(new HcolumnDescriptor("family"));| 返回值 | 函数 | 描述 |
|---|---|---|
| void | addFamily(HcolumnDescriptor hcd) | 添加一个列族 |
| HcolumnDescriptor | removeFamily(byte[] column) | 移除一个列族 |
| Bte[] | getName; | 获取表的名字 |
| Byte[] | getValue; | 获取属性的名字 |
| void | setValue(String key,String value) | 设置属性的值 |
6.4 HColumnDescriptor
包名:org.apache.hadoop.hbase.HColumnDescriptor
作用:维护着关于列族的信息,比如版本号,压缩设置等,它通常在创建表或者为表太难家列族的时候使用,列族被创建后不能直接修改,只能通过删除然后从新创建的方式,列族被删除的时候,列族里面的数据会同时被删除
用法示例:
HtableDescriptor htd = new HtableDescriptor("tableName");
HColumnDescriptor col = new HColumnDescriptor ("content");
Htd.addFamily(col);| 返回值 | 函数 | 描述 |
|---|---|---|
| Byte[] | getName | 获取列族的名字 |
| Byte[] | getValue(byte[] key) | 获取对应属性的值 |
| void | setValue(String key,String value) | 设置对应属性的值 |
6.5 Htable
包名:org.apache.hadoop.hbase.client.HTable
作用:可以用来和HBase表直接通信,此方法对于更新操作来说是非线程安全的
用法示例:
Htable table = new Htable(conf,Bytes.toBytes("tableName"));
ResultScanner scanner = table.getScanner("family");| 返回值 | 函数 | 描述 |
|---|---|---|
| void | checkAndput(byte[] row,byte[] family,byte[] qualifier,byte[] value,Put put) | 自动的检查 row/family/qualifier 是否与给定的值匹配 |
| void | Close | 释放所有的资源或挂起内部缓冲区中的更新 |
| boolean | Exists(Get get) | 获取get 实例所指定的值是否存在于htable的实例中 |
| result | Get(Get get) | 获取指定行的某些单元格所对应的值 |
| Byte[][] | getEndKeys | 获取当前一打开的表每个区域的结束键值 |
| ResultScanner | getScanner(byte[] family) | 获取当前给定列族的scanner实例 |
| Byte[] | getTableName; | 获取表名 |
| Static boolean | isTableEnabled(HBaseConfiguration conf,String tableName); | 检查表是否有效 |
| void | Put(put put) | 向表中添加值 |
6.6 Put
包名:org.apache.hadoop.hbase.client.Put
作用:用来对表执行单个添加操作
用法示例:
HTable table = new HTable(conf,Bytes.toBytes(tablename));
Put p = new Put(brow);//为指定行创建一个Put操作
p.add(family,qualifier,value);
table.put(p);| 返回值 | 函数 | 描述 |
|---|---|---|
| void | checkAndput(byte[] row,byte[] family,byte[] qualifier,byte[] value,Put put) | 自动的检查 row/family/qualifier 是否与给定的值匹配 |
| void | Close | 释放所有的资源或挂起内部缓冲区中的更新 |
| boolean | Exists(Get get) | 获取get 实例所指定的值是否存在于htable的实例中 |
| result | Get(Get get) | 获取指定行的某些单元格所对应的值 |
| Byte[][] | getEndKeys | 获取当前一打开的表每个区域的结束键值 |
| ResultScanner | getScanner(byte[] family) | 获取当前给定列族的scanner实例 |
| Byte[] | getTableName; | 获取表名 |
| Static boolean | isTableEnabled(HBaseConfiguration conf,String tableName); | 检查表是否有效 |
| void | Put(put put) | 向表中添加值 |
6.7 Get
包名:org.apache.hadoop.hbase.client.Get
作用:用来获取单个行的相关信息
用法示例:
HTable table = new HTable(conf, Bytes.toBytes(tablename));
Get g = new Get(Bytes.toBytes(row));
table.get(g);| 返回值 | 函数 | 描述 |
|---|---|---|
| get | addColumn(byte[] family,byte[] qualifier) | 获取指定列族和列的修饰符对应的列 |
| Get | addFamily(byte[] family) | 通过指定的列族获取其对应的所有列 |
| Get | setTimeRange(Long.minStamp.long maxStamp) | 获取指定区间的版本号 |
| Get | setFilter(Filter filter) | 当执行get操作时设置服务器端的过滤器 |
6.8 Result
包名:org.apache.hadoop.hbase.client.Result
作用:存储get 或者scann操作后获取表的单行值,使用此类提供的方法可以直接获取值或者中map接口(key-value对)
| 返回值 | 函数 | 描述 |
|---|---|---|
| boolean | containsColumn(byte[] family,byte[]qualifier) | 检查指定的列是否存在 |
| NavigableMap<byte[],byte[]> | getFamilyMap(byte[] family) | 获取对应列族所包含的修饰符与值的键值对 |
| Byte[] | getValue(byte[] family,byte[] qualifier) | 获取对应列的最新值 |
6.9 ResultScanner
包名:org.apache.hadoop.hbase.client.ResultScanner
作用:存储Get或者Scan操作后获取表的单行值。使用此类提供的方法可以直接
获取值或者各种Map结构(key-value对)
| 返回值 | 函数 | 描述 |
|---|---|---|
| vlid | Close | 关闭scanner并释放分配给它的资源 |
| Result | Next | 获取下一行的值 |
6.10 HTablePool
包名:org.apache.hadoop.hbase.client.HTablePool
作用:可以解决HTable存在的线程不安全问题,同时通过维护固定数量的HTable对象,能够在程序运行期间复用这些HTable资源对象
说明:
HTablePool可以自动创建HTable对象,而且对客户端来说使用上是完全透明的,可以避免多线程间数据并发修改问题。
HTablePool中的HTable对象之间是公用Configuration连接的,能够可以减少网络开销。
HTablePool的使用很简单:每次进行操作前,通过HTablePool的getTable方法取得一个HTable对象,然后进行put/get/scan/delete等操作,最后通过
HTablePool的putTable方法将HTable对象放回到HTablePool中。
7. Java 操作 HBase示例
package hbase;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.KeyValue;
import org.apache.hadoop.hbase.MasterNotRunningException;
import org.apache.hadoop.hbase.ZooKeeperConnectionException;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.client.HConnection;
import org.apache.hadoop.hbase.client.HConnectionManager;
import org.apache.hadoop.hbase.client.HTableInterface;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.io.compress.Compression.Algorithm;
import org.apache.hadoop.hbase.io.encoding.DataBlockEncoding;
import org.apache.hadoop.hbase.util.Bytes;
public class HbaseConnection {
private String rootDir;
private String zkServer;
private String port;
private Configuration conf;
private HConnection hConn = null;
private HbaseConnection(String rootDir,String zkServer,String port) {
System.out.println("rootDir"+rootDir);
System.out.println("zkServer"+zkServer);
System.out.println("port"+port);
try {
this.rootDir = rootDir;
this.zkServer = zkServer;
this.port = port;
conf = HBaseConfiguration.create;
conf.set("hbase.rootdir", rootDir);
conf.set("hbase.zookepper.quorum", zkServer);
conf.set("hbase.zookeeper.quorum", zkServer);
conf.set("hbase.zookepper.property.clientPort", port);
} catch (IOException e) {
e.printStackTrace;
}
}
/**
* 创建表
* @author hnbian
* Apr 13, 201610:05:06 PM
* @param tname
* @param cols
*/
private void createTable(String tablename,List<String> cols){
try {
HBaseAdmin admin = new HBaseAdmin(conf);
if(admin.tableExists(tablename)){
throw new IOException("table exists");
}else{
HTableDescriptor tableDesc = new HTableDescriptor(tablename);
for(String col:cols){
HColumnDescriptor colDesc = new HColumnDescriptor(col);
colDesc.setCompressionType(Algorithm.GZ);
colDesc.setDataBlockEncoding(DataBlockEncoding.DIFF);
tableDesc.addFamily(colDesc);
}
admin.createTable(tableDesc);
}
} catch (MasterNotRunningException e) {
e.printStackTrace;
} catch (ZooKeeperConnectionException e) {
e.printStackTrace;
} catch (IOException e) {
e.printStackTrace;
}
}
/**
* 保存数据
* @author hnbian
* Apr 13, 201610:05:15 PM
* @param tname
* @param puts
*/
private void saveData(String tablename,List<Put> puts){
try {
HTableInterface table = hConn.getTable(tablename);
table.put(puts);
//关闭自动提交,为了提高效率
table.setAutoFlush(false);
//手动提交
table.flushCommits;
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace;
}
}
/**
* 查询数据
* @author hnbian
* Apr 13, 201610:05:15 PM
* @param tname
* @param puts
*/
private Result getData(String tablename,String rowKey){
try {
HTableInterface table = hConn.getTable(tablename);
Get get = new Get(Bytes.toBytes(rowKey));
return table.get(get);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace;
}
return null;
}
public static void main(String args[]){
String rootDir = "hdfs://ns1/hbase";
String zkServer="had5,had6,had7";
String port="2181";
HbaseConnection conn = new HbaseConnection(rootDir,zkServer,port);
//创建表
/*List<String> list = new ArrayList<String>;
list.add("baseinfo");
list.add("moreinfo");
conn.createTable("stu2", list);*/
//插入数据
/*List<Put> puts = new ArrayList<Put>;
Put put1 = new Put(Bytes.toBytes("tom"));
put1.add(Bytes.toBytes("baseinfo"), Bytes.toBytes("age"),Bytes.toBytes("18"));
put1.add(Bytes.toBytes("moreinfo"), Bytes.toBytes("tel"),Bytes.toBytes("15600560986"));
Put put2 = new Put(Bytes.toBytes("jim"));
put2.add(Bytes.toBytes("baseinfo"), Bytes.toBytes("age"),Bytes.toBytes("28"));
put2.add(Bytes.toBytes("moreinfo"), Bytes.toBytes("hero"),Bytes.toBytes("areman"));
puts.add(put1);
puts.add(put2);
conn.saveData("stu2", puts);*/
//查询数据
Result result = conn.getData("stu2","tom");
format(result);
}
/**
* 查看结果
* @author hnbian
* Apr 13, 201610:05:15 PM
* @param tname
* @param puts
*/
public static void format(Result re){
String rowKey = Bytes.toString(re.getRow);
KeyValue[] kvs = re.raw;
for(KeyValue kv:kvs){
String family = Bytes.toString(kv.getFamily);
String qualifier = Bytes.toString(kv.getQualifier);
System.out.println(rowKey);
System.out.println(family);
System.out.println(qualifier);
}
}
}
8. HBase扫描器
8.1扫描器简介
HBase 在扫描数据的时候,使用Scanner表扫描器
Htable 通过Scan实例,调用getScanner(scan) 来获取扫描器.可以配置扫描器起止位,以及其他过滤条件
通过迭代器返回查询结果,使用起来虽然不是很方便,不过并不复杂.
但是这里有一点可能被忽略的地方.就是返回scanner迭代器,每次调用next的获取下一条记录的时候,默认配置下会访问一次RegioServer,这在网络条件不是很好的情况下,对性能是很大的影响.
建议配置扫描器缓存
8.2扫描器缓存
Hbase.client.scanner.caching配置项可以设置Hbase scanner 一次从服务端抓去的数据条数,默认情况下一次是一条
通过将其设置成一个合理的值,可以减少scan的过程中next的开销时间,代价是scanner需要客户端的内存来维持这些被cache的行记录
- 配置扫描器缓存
有三个地方可以进行配置
1.在HBASE的conf配置文件中进行配置
2.通过调用Htable.setScannerCaching(int scannerCaching);进行配置
3.通过调用Scan.setCaching(int caching);//进行配置,1,2,3的优先级越来越高
8.3 代码示例
public void hbaseScan(String tablename){
try {
HTableInterface table = hConn.getTable(tablename);
Scan scan = new Scan;
//设置缓存数据的条数
scan.setCaching(1000);
ResultScanner rs = table.getScanner(scan);
for(Result r:rs){
format(r);
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace;
}
}9. 过滤器
过滤器详细介绍查看文档:https://www.hnbian.cn/posts/6e925cfa.html
10. 协处理器
Hbase作为列式数据库最经常被人诟病的特性包括:
无法轻易建立”二级索引”,难以执行求和,计数,排序等操作.
比如,在小于0.92的版本中,统计表的总行数,需要使用counter方法,执行一次MapReduce job 才能得到,虽然Hbase在数据存储层中集成了MapReduce,能够有效用于表的分布式计算,
然而在很多情况下,做一些简单的相加或者聚合计算的时候,如果直接将计算过程放置在server端,能够减少通讯开销,从而获得很好的性能提升.于是,Hbase在0.92版本之后引入了协处理器(coprocessors),实现一些激动人心的新特性:能够轻易建立二级索引,复杂过滤器以及访问控制等.
Hbase协处理器的灵感来自于jeff dean 09年的演讲 ,它根据该演讲实现了类似于bigtable的协处理器,包括以下特性
1.每个表服务器的任务子表都可以运行代码
2.客户端的高层调用接口(客户端能够直接访问数据表的行地址,多行读写会自动分片成多个并行的RPC调用)
3.提供一个非常灵活的,可用于简历分布式服务的数据模型
4.能够自动化扩展,负载均衡,应用请求路由
Hbase的协处理器灵感来自bigtable,但是实现细节不尽相同。Hbase建立了一个框架,它为用户提供类库和运行时环境,使他们的代码能够在Hbase region server 和master上处理。
协处理器分为两种类型,
1.系统协处理器可以全局导入region server上的所有数据表,
2.表协处理器即是用户可以执行一张表使用协处理器。
协处理器框架为了更好支持其行为灵活性,提供了两种各不同方面的插件。
1.一个是观察者(observer),类似于关系型数据库的触发器。
2.另一个是终端(endpoint),动态的终端有点类似存储过程。
10.1 Observer
观察者的设计意图是允许用户通过插入代码来重载协处理器框架的upcall方法,而具体的事件触发的callback方法有Hbase的核心代码来执行。协处理器框架处理所有的callback调用细节,协处理器自身只需要插入添加或者改变的功能。
以Hbase0.92版本为例,它提供了三种观察者接口:
RegionObserver:提供客户端的数据操纵事件钩子:Get,Put,Delete,Scan等
WALObserver:提供WAL相关操作钩子
MasterObserver:提供DDL-类型的操作钩子,如创建,删除,修改数据表等
这些接口可以同事使用在同一个地方,按照不同优先级顺序执行,用户可以任意基于协处理器实现复杂的Hbase功能层,Hbase有很多种事件可以触发观察者方法,这些事件与方法从Hbase0.92版本起,都会集成在Hbase API中,不过这些API可能会由于各种原因有些改动,不同版本的接口改动较大。
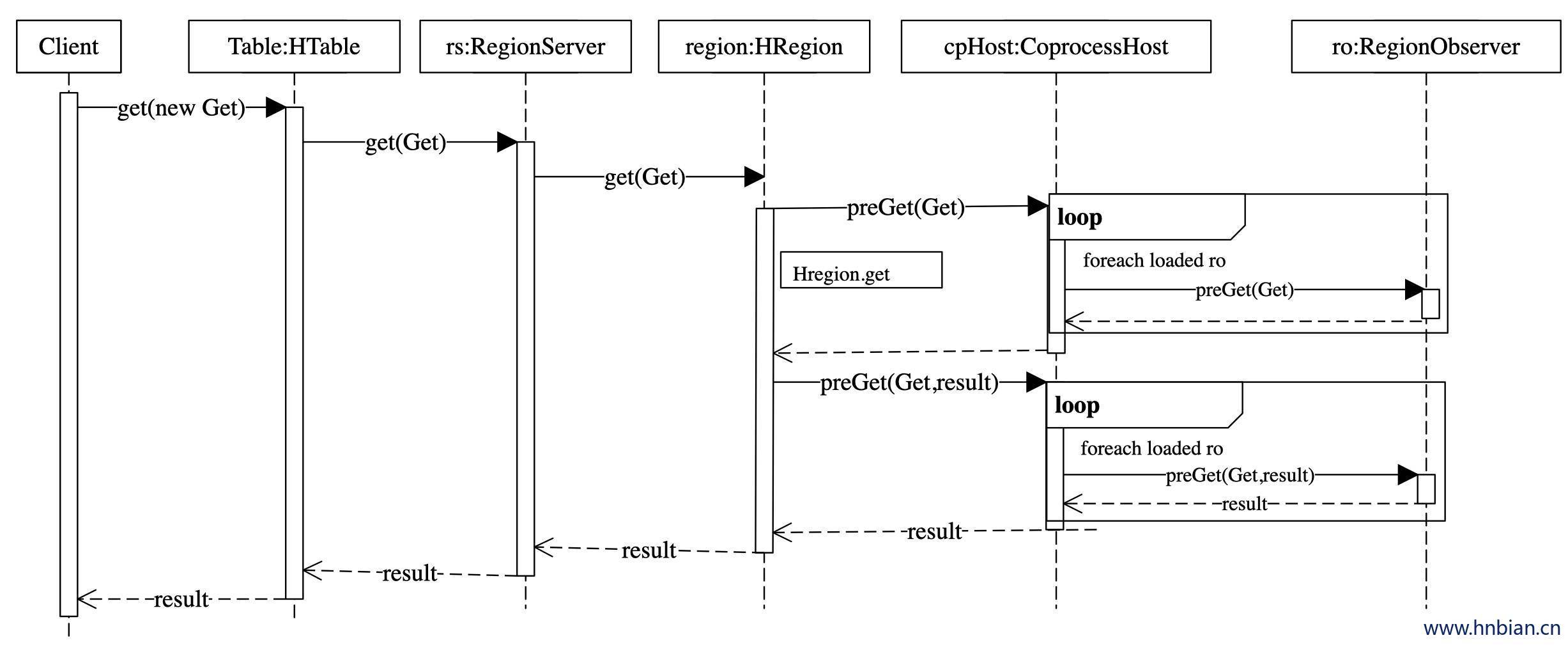
10.1.1 ObServer 使用示例
- 编写代码
package hbase;
import java.io.IOException;
import java.util.List;
import org.apache.hadoop.hbase.KeyValue;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.coprocessor.BaseRegionObserver;
import org.apache.hadoop.hbase.coprocessor.ObserverContext;
import org.apache.hadoop.hbase.coprocessor.RegionCoprocessorEnvironment;
import org.apache.hadoop.hbase.util.Bytes;
public class RegionObserverTest extends BaseRegionObserver {
private static byte[] find_rowkey = Bytes.toBytes("101");
@Override
public void preGet(ObserverContext<RegionCoprocessorEnvironment> c, Get get, List<KeyValue> result)
throws IOException {
if(Bytes.equals(get.getRow, find_rowkey)){
KeyValue kv = new KeyValue(get.getRow,Bytes.toBytes("time"),Bytes.toBytes("time"),Bytes.toBytes(System.currentTimeMillis));
result.add(kv);
}
}
}
- 将代码打成jar文件 并放到hdfs中
hadoop fs -put basehbaseobserver.jar /- 在Hbase shell客户端 添加observer 协处理器
hbase(main):014:0> disable 'persion'
0 row(s) in 1.3640 seconds
hbase(main):015:0> alter 'persion','coprocessor'=>'hdfs://ns1/basehbaseobserver.jar|hbase.RegionObserverTest||'
Updating all regions with the new schema...
1/1 regions updated.
Done.
0 row(s) in 1.1640 seconds
hbase(main):016:0> enable 'persion'
0 row(s) in 2.4270 seconds
hbase(main):019:0> describe 'persion'
DESCRIPTION ENABLED
'persion', {TABLE_ATTRIBUTES => {coprocessor$1 => 'hdfs://ns1/basehbaseobserver.jar|hbase.RegionObserverTest||'}, true
{NAME => 'fam1', DATA_BLOCK_ENCODING => 'DIFF', BLOOMFILTER => 'ROW', REPLICATION_SCOPE => '0', COMPRESSION => 'GZ
', VERSIONS => '1', TTL => '2147483647', MIN_VERSIONS => '0', KEEP_DELETED_CELLS => 'false', BLOCKSIZE => '65536',
IN_MEMORY => 'false', BLOCKCACHE => 'true'}, {NAME => 'fam2', DATA_BLOCK_ENCODING => 'DIFF', BLOOMFILTER => 'ROW'
, REPLICATION_SCOPE => '0', COMPRESSION => 'GZ', VERSIONS => '1', TTL => '2147483647', MIN_VERSIONS => '0', KEEP_D
ELETED_CELLS => 'false', BLOCKSIZE => '65536', IN_MEMORY => 'false', BLOCKCACHE => 'true'}
1 row(s) in 0.0300 seconds
hbase(main):020:0>
- 在客户端调用ObServer
package hbase;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.KeyValue;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.HConnection;
import org.apache.hadoop.hbase.client.HConnectionManager;
import org.apache.hadoop.hbase.client.HTableInterface;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.util.Bytes;
public class CallObserverTest {
private static HConnection hConn = null;
public static void main(String args[]) throws Throwable{
String rootDir = "hdfs://ns1/hbase";
String zkServer="had5,had6,had7";
String port="2181";
Configuration conf = HBaseConfiguration.create;
conf.set("hbase.rootdir", rootDir);
//conf.set("hbase.zookepper.quorum", zkServer);
conf.set("hbase.zookeeper.quorum", zkServer);
conf.set("hbase.zookepper.property.clientPort", port);
hConn = HConnectionManager.createConnection(conf);
HTableInterface table = hConn.getTable("persion");
Get get = new Get(Bytes.toBytes("101"));
Result re = table.get(get);
String rowKey = Bytes.toString(re.getRow);
KeyValue[] kvs = re.raw;
for(KeyValue kv:kvs){
String family = Bytes.toString(kv.getFamily);
String qualifier = Bytes.toString(kv.getQualifier);
System.out.println(rowKey);
System.out.println(family);
System.out.println(qualifier);
System.out.println(Bytes.toString(kv.getValue));
}
}
}
10.2 EndPoint
终端是动态RPC插件接口,它的实现代码被安装在服务器端,从而能够通过Hbase RPC唤醒。客户端类库提供了非常方便的方法来调用这些动态的接口,他们可以在任意时候调用一个终端,它们的实现代码会被目标region远程执行,结果会返回到终端,用户可以结合使用这些强大的插件接口,为Hbase添加全新的特性,终端的使用,如下面流程所示:
定义一个新的protocol接口必须继承CoprocessorProtocol
实现终端接口,该实现会被导入region环境执行。
继承抽象类BaseEndPointCoprocessor
在客户端,终端可以被两个新的Hbase client API调用。
单个region:HTableInterface.coprocessorProxy(Class
regions区域:HTableInterface.coprocessorExec(Class
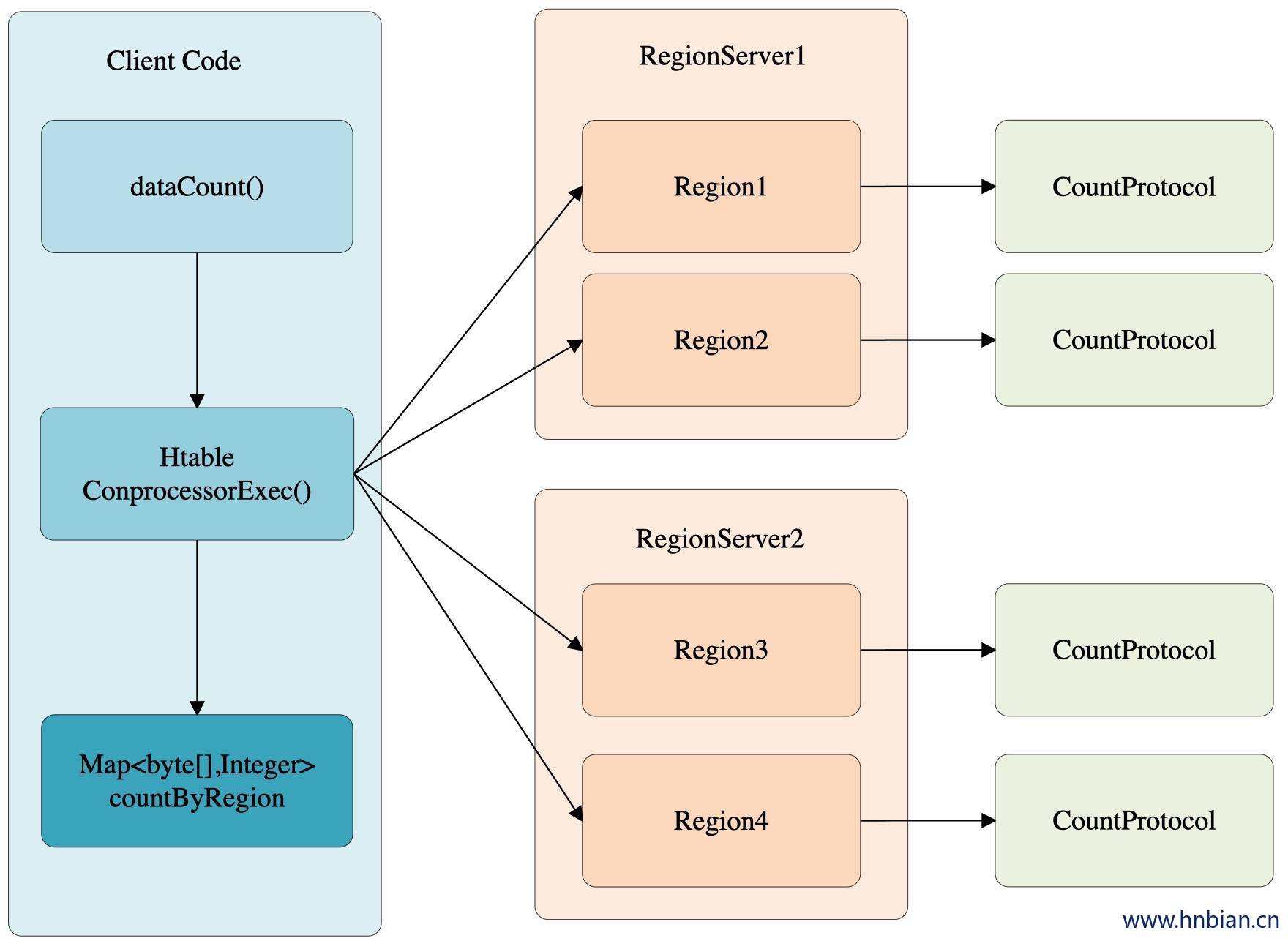
10.2.1 设置 EndPotin 的三种方式
- 启动全局aggregation,能够操作所有表上的数据,通过修改Hbase-site.xml这个文件来实现,只需要添加如下代码:
<property>
<name>hbase.coprocessor.user.region.classes</name>
<value>org.apache.hadoop.hbase.coprocessor.RowCountEndPoint</value>
</property>- 启用表aggregation,只对特定的表生效,通过Hbase shell来实现
# Disabled 执行表,
hbase>disable 'mytable'
# 添加 aggregation
hbase>alter 'mytable' METHOD=> 'table_att','coprocessor'=>'|org.apache.hadoop.hbase.coprocessor.RowCountEndpoint||'
# 重启指定表
Hbase>enable 'mytable'
hbase(main):006:0> disable 'persion'
0 row(s) in 1.4850 seconds
hbase(main):007:0> alter 'persion', 'coprocessor'=>'|org.apache.hadoop.hbase.coprocessor.example.RowCountEndpoint||'
Updating all regions with the new schema...
1/1 regions updated.
Done.
0 row(s) in 1.4330 seconds
hbase(main):008:0> enable 'persion'
0 row(s) in 0.4800 seconds
# 删除协处理器
hbase(main):005:0> alter 'persion', METHOD => 'table_att_unset',NAME=>'coprocessor$1'
Updating all regions with the new schema...
0/1 regions updated.
1/1 regions updated.
Done.
0 row(s) in 3.0840 seconds
hbase(main):006:0> describe 'persion'- API调用
HTableDescriptor htd = new HTableDescriptor("testTable");
Htd.setValue("CORPROCESSOR$1",path.toString+"|"+RowCountEndPoint.class.getCanonicalName+"|"+Coprocessor.Priority.USER);几点说明:
1.协处理器配置的加载顺序:先加载配置文件中定义的协处理器,后加载表描述符中的协处理器
2.COPROCESSOR$
3.协处理器的加载格式:
alter 'tablename',METHOD=>'table_att', 'coprocessor1'=>'hdfs:///foo.jar|Com.foo.fooregion.Observer|1001|arg1=1|arg2=2'10.2.2 Endpoint 代码示例
endpoint协处理器功能实现代码
import com.google.protobuf.RpcCallback;
import com.google.protobuf.RpcController;
import com.google.protobuf.Service;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.Coprocessor;
import org.apache.hadoop.hbase.CoprocessorEnvironment;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.coprocessor.CoprocessorException;
import org.apache.hadoop.hbase.coprocessor.CoprocessorService;
import org.apache.hadoop.hbase.coprocessor.RegionCoprocessorEnvironment;
import org.apache.hadoop.hbase.coprocessor.example.generated.ExampleProtos.CountRequest;
import org.apache.hadoop.hbase.coprocessor.example.generated.ExampleProtos.CountResponse;
import org.apache.hadoop.hbase.coprocessor.example.generated.ExampleProtos.CountResponse.Builder;
import org.apache.hadoop.hbase.coprocessor.example.generated.ExampleProtos.RowCountService;
import org.apache.hadoop.hbase.filter.FirstKeyOnlyFilter;
import org.apache.hadoop.hbase.protobuf.ResponseConverter;
import org.apache.hadoop.hbase.regionserver.HRegion;
import org.apache.hadoop.hbase.regionserver.InternalScanner;
import org.apache.hadoop.hbase.util.Bytes;
public class RowCountEndpoint extends ExampleProtos.RowCountService
implements Coprocessor, CoprocessorService
{
private RegionCoprocessorEnvironment env;
public Service getService
{
return this;
}
public void getRowCount(RpcController controller, ExampleProtos.CountRequest request, RpcCallback<ExampleProtos.CountResponse> done)
{
Scan scan = new Scan;
scan.setFilter(new FirstKeyOnlyFilter);
ExampleProtos.CountResponse response = null;
InternalScanner scanner = null;
try {
scanner = this.env.getRegion.getScanner(scan);
List results = new ArrayList;
boolean hasMore = false;
byte[] lastRow = null;
long count = 0L;
do {
hasMore = scanner.next(results);
for (Cell kv : results) {
byte[] currentRow = CellUtil.cloneRow(kv);
if ((lastRow == null) || (!Bytes.equals(lastRow, currentRow))) {
lastRow = currentRow;
count += 1L;
}
}
results.clear;
}while (hasMore);
response = ExampleProtos.CountResponse.newBuilder.setCount(count).build;
}
catch (IOException ioe) {
ResponseConverter.setControllerException(controller, ioe);
} finally {
if (scanner != null)
try {
scanner.close;
} catch (IOException ignored) {
}
}
done.run(response);
}
public void getKeyValueCount(RpcController controller, ExampleProtos.CountRequest request, RpcCallback<ExampleProtos.CountResponse> done)
{
ExampleProtos.CountResponse response = null;
InternalScanner scanner = null;
try {
scanner = this.env.getRegion.getScanner(new Scan);
List results = new ArrayList;
boolean hasMore = false;
long count = 0L;
do {
hasMore = scanner.next(results);
for (Cell kv : results) {
count += 1L;
}
results.clear;
}while (hasMore);
response = ExampleProtos.CountResponse.newBuilder.setCount(count).build;
}
catch (IOException ioe) {
ResponseConverter.setControllerException(controller, ioe);
} finally {
if (scanner != null)
try {
scanner.close;
} catch (IOException ignored) {
}
}
done.run(response);
}
public void start(CoprocessorEnvironment env)
throws IOException
{
if ((env instanceof RegionCoprocessorEnvironment))
this.env = ((RegionCoprocessorEnvironment)env);
else
throw new CoprocessorException("Must be loaded on a table region!");
}
public void stop(CoprocessorEnvironment env)
throws IOException
{
}
}
10.2.3 Java 调用 Endpoint 示例
package hbase;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.coprocessor.Batch;
import org.apache.hadoop.hbase.coprocessor.example.generated.ExampleProtos;
import org.apache.hadoop.hbase.ipc.BlockingRpcCallback;
import org.apache.hadoop.hbase.ipc.ServerRpcController;
import java.io.IOException;
import java.util.Map;
import org.apache.hadoop.conf.Configuration;
public class ComproessorRowcount {
public static void main(String args[]) throws Throwable{
String rootDir = "hdfs://ns1/hbase";
String zkServer="had5,had6,had7";
String port="2181";
Configuration conf = HBaseConfiguration.create;
conf.set("hbase.rootdir", rootDir);
conf.set("hbase.zookeeper.quorum", zkServer);
conf.set("hbase.zookepper.property.clientPort", port);
HTable table = new HTable(conf,"persion");
final ExampleProtos.CountRequest request = ExampleProtos.CountRequest.getDefaultInstance;
Map<byte[],Long> results = table.coprocessorService(//调用协处理器
ExampleProtos.RowCountService.class, null, null, new Batch.Call<ExampleProtos.RowCountService,Long> {
public Long call(ExampleProtos.RowCountService counter) throws IOException{
ServerRpcController controller = new ServerRpcController;
BlockingRpcCallback<ExampleProtos.CountResponse> rpcCallback = new BlockingRpcCallback<ExampleProtos.CountResponse>;
counter.getRowCount(controller, request, rpcCallback);
ExampleProtos.CountResponse response = rpcCallback.get;
if(controller.failedOnException){
throw controller.getFailedOn;
}
return (response !=null && response.hasCount)? response.getCount : 0;
}
});
Long sum = 0L;
int count = 0;
for(Long l:results.values){
sum+=l;
count ++;
}
System.out.println("row count==>"+sum);
System.out.println("ragin count==>"+count);
}
}
11. MapReduce on Hbase
可以使用MapReduce的方法操作Hbase数据库
Hadoop MapReduce提供了相关的API,可以与Hbase数据库无缝连接
- 相关类
| Hbase MapReduce | Hadoop MapReduce |
|---|---|
| org.apache.hadoop.hbase.mapreduce.TableMapper | org.apache.hadoop.mapreduce.Mapper |
| org.apache.hadoop.hbase.mapreduce.TableReducer | org.apache.hadoop.mapreduce.Reducer |
| org.apache.hadoop.hbase.mapreduce.TableInputFormat | org.apache.hadoop.mapreduce.InputFormat |
| org.apache.hadoop.hbase.mapreduce.TableOutputFormat | org.apache.hadoop.mapreduce.OutputFormat |
- MapReduce onHbase 代码示例
package hbase;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.HConnection;
import org.apache.hadoop.hbase.client.HConnectionManager;
import org.apache.hadoop.hbase.client.HTableInterface;
import org.apache.hadoop.hbase.client.Mutation;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
public class HbaseMR {
public static void main(String args[]) throws IOException, ClassNotFoundException, InterruptedException{
String rootDir = "hdfs://ns1/hbase";
String zkServer="had5,had6,had7";
String port="2181";
Configuration conf = HBaseConfiguration.create;
conf.set("hbase.rootdir", rootDir);
//conf.set("hbase.zookepper.quorum", zkServer);
conf.set("hbase.zookeeper.quorum", zkServer);
conf.set("hbase.zookepper.property.clientPort", port);
Job job = new Job(conf,"mr on hbase");
job.setJarByClass(HbaseMR.class);
Scan sc = new Scan;
/* HConnection hConn = HConnectionManager.createConnection(conf);
HTableInterface table = hConn.getTable("persion");*/
sc.setCaching(100);
TableMapReduceUtil.initTableMapperJob("persion", sc,HMapper.class, Text.class, Text.class, job);
TableMapReduceUtil.initTableReducerJob("result", HReduce.class, job);
job.waitForCompletion(true);
}
}
class HMapper extends TableMapper<Text,Text>{
@Override
protected void map(ImmutableBytesWritable key, Result value,
Mapper<ImmutableBytesWritable, Result, Text, Text>.Context context)
throws IOException, InterruptedException {
Text k = new Text(Bytes.toString(key.get));
Text v = new Text(value.getValue(Bytes.toBytes("fam1"), Bytes.toBytes("col1")));
System.out.println(k);
System.out.println(v);
context.write(v, k);
}
}
class HReduce extends TableReducer<Text,Text,ImmutableBytesWritable>{
@Override
protected void reduce(Text key, Iterable<Text> values,
Reducer<Text, Text, ImmutableBytesWritable, Mutation>.Context context)
throws IOException, InterruptedException {
Put put = new Put(Bytes.toBytes(key.toString));
for(Text value:values){
put.add(Bytes.toBytes("f1"),Bytes.toBytes(value.toString),Bytes.toBytes(value.toString));
System.out.println(put);
}
context.write(null, put);
}
}12. Hbase 二级索引
MapReduce方案
Coprocessor 方案
solr+hbase 方案
12.1 MapReduce 方案
indexBuilder:利用MR的方式构建Index
优先:并发批量构建index
缺点:不能实时构建index
举例:
原表:
row 1 f1:name zhangsan
row 2 f1:name lisi
row 3 f1:name wangwu
索引表
row zhangsan f1:name 1
row lisi f1:name 2
row wangwu f1:name 3
- 代码实例:
package hbase;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Mutation;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.MultiTableOutputFormat;
import org.apache.hadoop.hbase.mapreduce.TableInputFormat;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.util.GenericOptionsParser;
/**
* 通过mapreduce并发建立索引
* hnbian
* Jun 5, 20163:49:01 PM
*/
public class IndexBuilderByMR {
@SuppressWarnings("deprecation")
public static void main(String args[]) throws IOException, ClassNotFoundException, InterruptedException{
String rootDir = "hdfs://ns1/hbase";
String zkServer="had5,had6,had7";
String port="2181";
Configuration conf = HBaseConfiguration.create;
conf.set("hbase.rootdir", rootDir);
//conf.set("hbase.zookepper.quorum", zkServer);
conf.set("hbase.zookeeper.quorum", zkServer);
conf.set("hbase.zookepper.property.clientPort", port);
/**
* tablename
* columnFamily
* Qualifier
*/
String []otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs;
if(otherArgs.length<3){
System.out.println("参数传递异常");
System.exit(-1);
}
String tableName = otherArgs[0];
String columnFamily = otherArgs[1];
//String Qualifier = args[2];
conf.set("tableName", tableName);
conf.set("columnFamily", columnFamily);
String []qualifier = new String [otherArgs.length-2];
for(int i=0;i<qualifier.length;i++){
qualifier[i]=otherArgs[i+2];
}
conf.setStrings("qualifiers", qualifier);
Job job = new Job(conf,tableName);
job.setJarByClass(IndexBuilderByMR.class);
job.setMapperClass(HMapper2.class);
job.setNumReduceTasks(0);
job.setInputFormatClass(TableInputFormat.class);
//job.setInputFormatClass(TableInputFormat.class);
job.setOutputFormatClass(MultiTableOutputFormat.class);
Scan sc = new Scan;
sc.setCaching(100);
TableMapReduceUtil.initTableMapperJob(tableName, sc,HMapper2.class, ImmutableBytesWritable.class, Put.class, job);
//TableMapReduceUtil.initTableReducerJob("result", HReduce.class, job);
job.waitForCompletion(true);
}
}
class HMapper2 extends TableMapper<ImmutableBytesWritable,Put>{
Map<byte[],ImmutableBytesWritable> indexes = new HashMap;
private String familyName;
@Override
protected void map(ImmutableBytesWritable key, Result value,
Mapper<ImmutableBytesWritable, Result, ImmutableBytesWritable, Put>.Context context)
throws IOException, InterruptedException {
Set<byte[]> set = indexes.keySet;
for(byte[] k :set){
ImmutableBytesWritable indexTableName = indexes.get(k);
byte[] val = value.getValue(Bytes.toBytes(familyName), k);
if(val !=null){
Put put = new Put(val);
put.add(Bytes.toBytes("f1"),Bytes.toBytes("id"),key.get);
context.write(indexTableName, put);
}
}
}
@Override
protected void setup(Mapper<ImmutableBytesWritable, Result, ImmutableBytesWritable, Put>.Context context)
throws IOException, InterruptedException {
Configuration conf = context.getConfiguration;
String tableName = conf.get("tableName");
//String columnFamily = conf.get("columnFamily");
String familyName = conf.get("familyName");
String qualifiers[] = conf.getStrings("qualifiers");
for(String q:qualifiers){
indexes.put(Bytes.toBytes(s), new ImmutableBytesWritable(Bytes.toBytes(tableName+"-"+q)));
}
super.setup(context);
}
}
12.2 基于solr的实时查询
hbase 提供海量数据存储
solr提供索引与构建查询
Hbase indexer 提供自动化构建索引(从Hbase到solr)


