1. Zookeeper 简介
1.1 什么是zookeeper
- zookeeper 直译 动物园管理员
- Apache Zookeeper 是Google的Chubby的一个开源对的实现,为分布式应用提供协调服务,用来解决分布式应用中的数据管理问题,如:配置管理、域名服务、分布式框架、集群管理等。
- zookeeper包含了一个简单的原语集,分布式应用程序可以基于它实现同步服务,配置维护和命名服务等
- 简单来说zookeeper=文件系统+监听通知机制
- 可以去 Apache Zookeeper官网 进行下载。
这里再介绍几个概念:
单机
单机就是把做的系统部署到一台服务器上,,所有的请求业务都由这台服务器处理。显然,当业务增长到一定程度的时候,服务器的硬件会无法满足业务需求。很多人就会想到多部署几台服务器,这就是集群。集群
集群就是单机的多实例,在多个服务器上部署多个服务,每个服务就是一个节点,部署N个节点,处理业务的能力就提升 N倍(大约),这些节点的集合就叫做集群。
- 优点:操作简单,容易部署;
- 缺点:每个节点负载相同(耦合度高),每个具体业务的访问量可能差异很大,比如美团外卖美食外卖的访问量一定大于鲜花外卖的访问量,这就造成了资源浪费
- 分布式(微服务)
分布式结构就是将一个完整的系统,按照业务功能,拆分成一个个独立的子系统,在分布式结构中,每个子系统就被称为“服务”。这些子系统能够独立运行在web容器中,它们之间通过RPC方式通信。
- 优点:资源利用率高
- 缺点:安全性低,如果一台服务器出现问题整个系统就会崩塌
1.2 应用场景
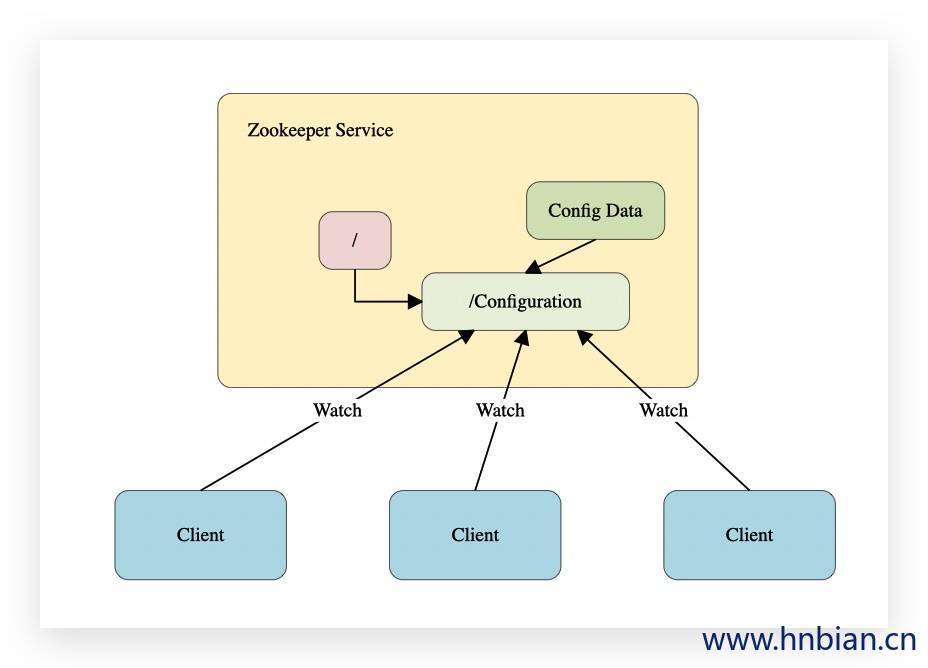
集群环境,服务器的许多配置都是相同的,如:数据库连接信息,当需要这些配置的同时,必须同时修改每台服务器。这时我们可以把配置信息保存在zookeeper某个目录下。然后所有的应用程序(客户端)对这个目录节点进行监视(Watch),一旦配置信息发生变化,Zookeeper会通知每个客户端,然后从Zookeeper中获取新的配置信息,并应用到系统中
在Hadoop集群中,使用Zookeeper的事件处理确保整个集群只有一个NameNode,存储配置信息。
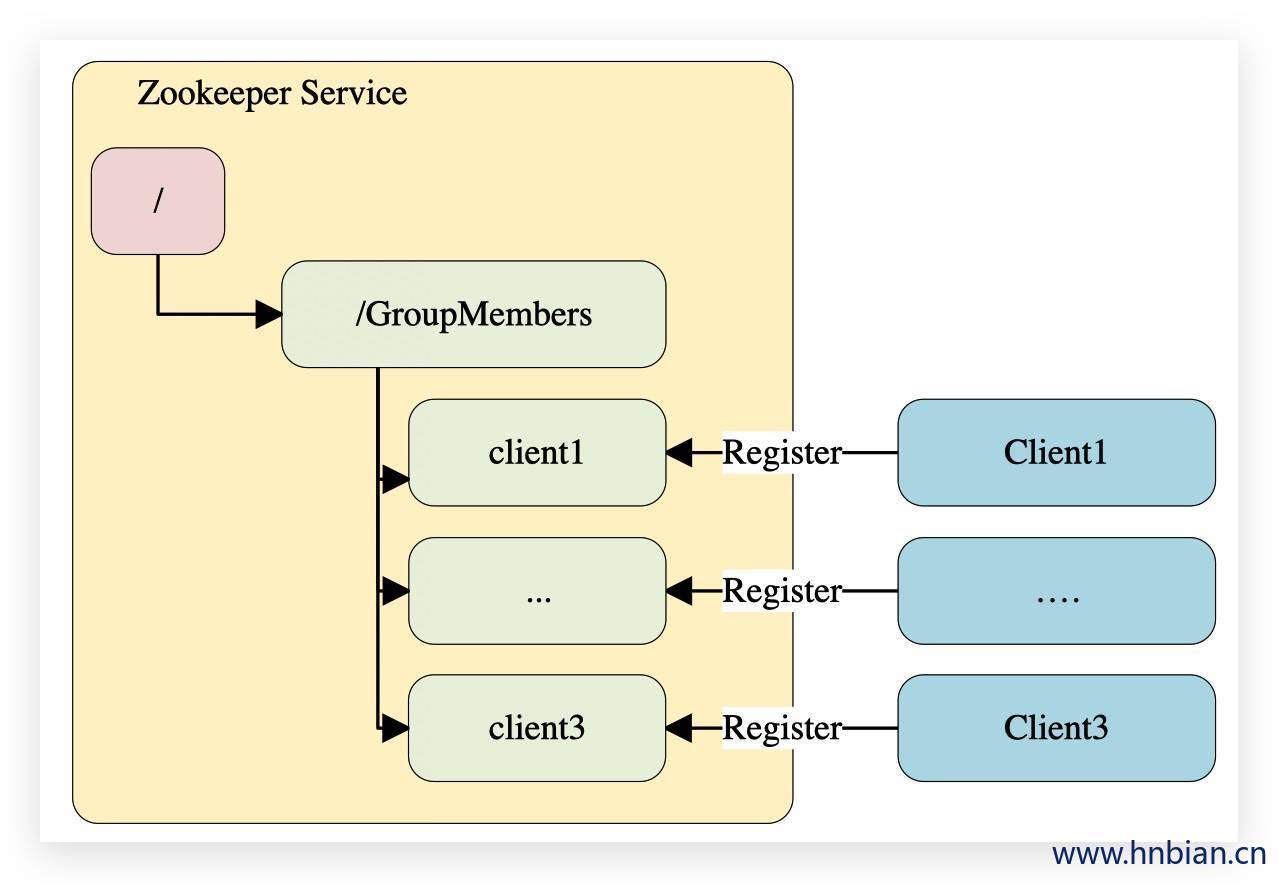
Hbase集群中,使用Zookeeper的事件处理确保整个集群只有一个HMaster,并察觉HRegionServer联机和宕机,存储访问控制列表等。在集群环境下,如何知道有多少台机器在工作?是否有机器退出或加入?需要选取一个master
解决:在父目录GroupMembers下为所有客户端创建临时目录节点,然后每个客户端都会监听GroupMembers下面节点的变化,一旦有机器挂掉(客户端与Zookeeper连接断开),其对应的临时目录节点就会被删除,所有的其他客户端都会收到通知,当有新的机器加入时也是相同的道理。
选举master:为所有客户端创建临时顺序编号目录节点,给每个客户端对应的临时节点编号,每次选取最小编号的节点为master
1.3 工作原理
- 每个Server在内存中存储了一份数据
- Zookeeper启动时,将从实例中选举一个leader(Paxos协议)
- leader负责处理数据更新等操作
- 一个操作更新成功,当且仅当超过半数Server在内存中成功修改数据。
2. 架构与组件介绍
2.1 Zookeeper的组件
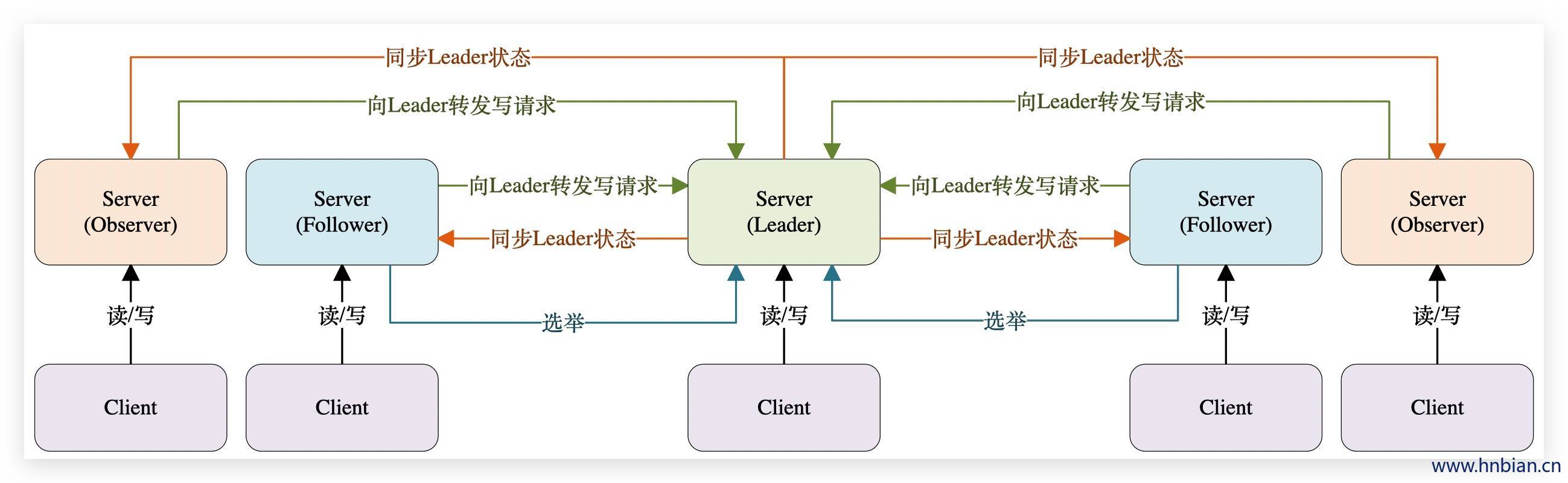
一个zookeeper集群中,有一个 Leader 和多个 Follower
- Leader:集群中同一时间只有一个Leader,负责进行投票的发起和决议、处理来自Learner的写请求,向Learner 同步状态。
- Follower:集群中会有多个Follower用于接收客户端请求,读请求直接返回结果给客户端,写请求则会将请求发送给leader处理,定时同步集群状态,并在选举过程中参与投票。
- Observer:用于接收客户端请求,读请求直接返回结果给客户端,写请求则会将请求发送给leader处理,定时同步集群状态,但observer不参与投票过程,observer的目的是为了扩展系统,提到读取速度。
- Learner(学习者):包括follower(跟随者)和观察者(observer)
- Client:请求发起方。
2.2 Server的三种状态
LOOKING:当前Server不知道Leader是谁,正在搜寻
LEADING:当前Server即为选举出来的Leader
FOLLOWING:Leader已经被选举出来,当前Server与之同步
2.3 集群特性
- 半数机制:集群中只要有半数以上的节点存活,集群就能正常工作
- 最终一致性:集群中每台服务器保存一份相同的数据副本
- 顺序性:来自同一个客户端的更新请求,按其发送顺序依次执行,前一个请求没执行完成,接下来的请求不会执行。
- 原子性:数据一次更新数据,要么成功,要么失败。
- 独立性:各个节点之间互不干预
- 实时性:在一定时间范围内,客户端能读取到最新数据。如果想更新到最新数据应该在读取数据之前调用synv()接口。
- 可靠性:如果消息被一台服务器接受,那么它将被所有的服务器接受
2.4 Leader选举机制
假如我们现在集群中有5台zookeeper服务器,分别是server1、server2、server3、server4、server5 对应myid分别是1-5
- 选举流程
- server1 启动,给自己投票,然后发送投票信息,由于其他服务器都还没有启动,所以它发出的信息收不到任何反馈,此时server1 为 Looking 状态
- server2 启动,给自己投票,然后与server1 交换投票信息,由于server2的myid值较大,所以server2生出,但是由于此时投票数未过半,所以此时server1和server2 都为Looking状态。
- server3 启动,给自己投票,然后与server1,server2 交换投票信息,由于server2的myid值较大,所以server3胜出,此时投票数已经过半,所以server3为Leader,server1和server2 为Follower。
- server4 启动,给自己投票,然后与server1,server3 交换投票信息,尽管Server4 的myid值最大,但是由于集群中已经存在Leader,所以server4只能为Follower
- server5 启动,给自己投票,与server4的情况类似,所以只能为Follower
- leader选举机制总结
- 每个服务器在启动时都会选择自己为leader,然后将投票信息发送出去
- 服务器编号myid越大,在选择算法中的权重就越大
- 投票数必须过半才能选出Leader
- 在启动顺序的前(n/2+1)个服务器中,myid值最大的会称为Leader
- 半数通过机制
3台机器时挂一台 2 > 3/2
4台机器时挂一台 2! > 4/2
2.5 Zab协议
Zookeeper的核心是原子广播,这个机制保证了各个Server之间的同步,实现这个机制的协议叫做Zab(Zookeeper Atomic Broadcast)协议。Zab协议有两种模式:
- 恢复模式(选举):当服务启动或者在领导者崩溃后,Zab就进入恢复模式,当领导者被选举出来,且大多数Server完成了和leader的状态同步后,恢复模式就结束了。
- 广播模式(同步):状态同步保证了leader和Server都有相同的系统状态。
ZAB实现了主备模式下的系统架构,保持集群中各个副本之间的数据一致性。
ZAB协议定义了选举(election)、发现(discovery)、同步(sync)、广播(Broadcast)四个阶段。
选举(election)是选出哪台为主机;
发现(discovery)、同步(sync)当主选出后,要做的恢复数据的阶段;
广播(Broadcast)当主机和从选出并同步好数据后,正常的主写同步从写数据的阶段。
扩展阅读 十分钟了解ZAB协议
3. 单节点部署
3.1 下载安装文件
zookeeper 下载地址:http://archive.apache.org/dist/zookeeper/
根据自己的需要下载对应版本,这里下载的版本是 3.5.6
3.2 解压安装包
# 将下载的安装包上传到服务器
# 切换文件夹
[root@node1 ~]# cd /opt/
# 解压 安装包
[root@node1 opt]# tar -zxvf apache-zookeeper-3.5.6-bin.tar.gz
[root@node1 opt]# ll
总用量 30452
-rw-r--r-- 1 root root 9230052 10月 16 08:35 apache-zookeeper-3.5.6-bin.tar.gz
drwxr-xr-x 8 root root 4096 1月 30 11:34 zookeeper-3.5.6
3.3 创建所需文件夹
# 切换文件夹
[root@node1 opt]# cd zookeeper-3.5.6/
# 创建数据文件夹(Zookeeper之后产生的数据会存储在该文件夹中)
[root@node1 opt]# mkdir data
# 创建日志文件夹(Zookeeper之后产生的日志数据会存储在该文件夹中)
[root@node1 opt]# mkdir logs
[root@node1 zookeeper-3.5.6]# ll
总用量 48
drwxr-xr-x 2 1000 1000 4096 10月 9 04:14 bin
drwxr-xr-x 2 1000 1000 4096 1月 29 22:24 conf
drwxr-xr-x 3 root root 4096 1月 29 22:24 data # 数据文件夹
drwxr-xr-x 5 1000 1000 4096 10月 9 04:15 docs
drwxr-xr-x 2 root root 4096 1月 29 21:50 lib
-rw-r--r-- 1 1000 1000 11358 10月 5 19:27 LICENSE.txt
drwxr-xr-x 3 root root 4096 1月 29 22:12 logs # 日志文件夹
-rw-r--r-- 1 1000 1000 432 10月 9 04:14 NOTICE.txt
-rw-r--r-- 1 1000 1000 1560 10月 9 04:14 README.md
-rw-r--r-- 1 1000 1000 1347 10月 5 19:27 README_packaging.txt3.4 修改配置文件
# 切换文件夹
[root@node1 zookeeper-3.5.6]# cd conf
[root@node1 conf]# ll
总用量 16
-rw-r--r-- 1 1000 1000 535 10月 5 19:27 configuration.xsl
-rw-r--r-- 1 1000 1000 2712 10月 5 19:27 log4j.properties
-rw-r--r-- 1 1000 1000 922 10月 9 04:14 zoo_sample.cfg
# 修改配置文件名称,默认是使用zoo.cfg,固定的
[root@node1 conf]# cp zoo_sample.cfg zoo.cfg
[root@node1 conf]# vim zoo.cfg
在配置文件中增加或修改一下内容
# 指定数据文件夹
dataDir=/opt/zookeeper-3.5.6/data
# 指定数据日志文件夹
dataLogDir=/opt/zookeeper-3.5.6/logs
# the port at which the clients will connect
clientPort=2181
#2888,3888 are election port
server.0=node1:2888:38883.5 启动服务
[root@node1 conf]# cd /opt/zookeeper-3.5.6/bin
[root@node1 bin]#
[root@node1 bin]# ll
总用量 56
-rwxr-xr-x 1 1000 1000 2067 10月 9 04:14 zkCleanup.sh
-rwxr-xr-x 1 1000 1000 1621 10月 9 04:14 zkCli.sh # zookeeper 客户端
-rwxr-xr-x 1 1000 1000 3690 10月 5 19:27 zkEnv.sh
-rwxr-xr-x 1 1000 1000 4573 10月 9 04:14 zkServer-initialize.sh
-rwxr-xr-x 1 1000 1000 9386 10月 9 04:14 zkServer.sh # zookeeper 服务器相关命令
-rwxr-xr-x 1 1000 1000 1385 10月 5 19:27 zkTxnLogToolkit.sh
#启动zookeeper服务,restart 重启
[root@node1 bin]# zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper-3.5.6/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[root@node1 bin]#
#查看zookeeper服务状态
[root@node1 bin]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper-3.5.6/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost.
Mode: standalone # 单节点模式
#停止zookeeper服务
[root@node1 bin]# zkServer.sh stop
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper-3.5.6/bin/../conf/zoo.cfg
Stopping zookeeper ... STOPPED3.6 查看zookeeper进程
# 查看Java进程
[root@node1 bin]# jps -l
7696 org.apache.zookeeper.server.quorum.QuorumPeerMain
8311 sun.tools.jps.Jps
[root@node1 bin]#
#根据端口查看进程信息
[root@node1 bin]# lsof -i:2181
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
java 7696 root 49u IPv4 1194504 0t0 TCP *:eforward (LISTEN)如果没有lsof服务可以使用 yum install lsof 安装
3.7 启动客户端
- 连接本机
[root@node1 bin]# zkCli.sh #默认连接本机
Connecting to localhost:2181
...
Welcome to ZooKeeper!
JLine support is enabled
...
WATCHER::
WatchedEvent state:SyncConnected type:None path:null
[zk: localhost:2181(CONNECTED) 0]
[zk: localhost:2181(CONNECTED) 0] quit # 退出客户端
WATCHER::
WatchedEvent state:Closed type:None path:null- 连接远程zookeeper服务
[root@node1 bin]# zkCli.sh -server localhost:2181 # 连接远程服务
Connecting to localhost:2181
...
Welcome to ZooKeeper!
JLine support is enabled
...
WATCHER::
WatchedEvent state:SyncConnected type:None path:null
[zk: localhost:2181(CONNECTED) 0]4. 集群部署
4.1 编辑配置文件
在单机安装的配置文件的基础上,每台服务器中的conf/zoo.cfg 中添加如下内容
server.1=ip1:2888:3888
server.2=ip2:2888:3888
server.3=ip3:2888:3888格式说明:server.A=B:C:D
- A表示这台服务器的编号ID,是一个数字
- B表示服务器的IP地址或者域名
- C表示这台服务器与集群中的Leader交换信息时用的端口
- D表示执行选举Leader服务器时相互通信的端口
4.2 创建 myid 配置文件
在集群环境下的dataDir里会放置一个myid文件,里面就一个数字(上面配置中的”A”),用来唯一标识这个服务。这个id是很重要的,一定要保证整个集群中唯一。zookeeper会根据这个id来取出server.x上的配置。比如当前id为1,则对应着zoo.cfg里的server.1的配置。
cd data
echo A的值 > myid 4.3 测试集群环境
启动所有zookeeper服务器,查看状态
此时在某台服务器上执行更新操作,其他服务器也会同步
#node1启动zookeeper
[root@node1 data]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/apache-zookeeper-3.5.6-bin/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost.
Mode: leader
#node2启动zookeeper
[root@node2 data]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/apache-zookeeper-3.5.6-bin/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost.
Mode: follower
#node3启动zookeeper
[root@node3 data]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/apache-zookeeper-3.5.6-bin/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost.
Mode: follower
observer的配置方式:
server.1=ip1:2888:3888
server.2=ip2:2888:3888
server.3=ip3:2888:3888:observer # server.3 即为observer4.4 配置文件说明
| 配置项 | 含义 | 说明 | 默认值 |
|---|---|---|---|
| tickTime | 心跳时间 | 维持心跳时间间隔,单位毫秒ms在zookeeper中所有的时间都是以这个时间为基础单元,以整数倍配置的 | 2000 |
| initLimit | 初始时通信时间限制 | 用于zookeeper集群,当有多台zookeeper服务器时,其中一个leader,其余为follower,该时限是leader与follower通信时间内完成数据同步 | 10*tickTime |
| syncLimit | 同步通信的时间限制 | 运行时leader与follower通过心跳检测,如果超过syncLimit未收到相应则认为该follower宕机 | 5*syncLimit |
| dataDir | 存储数据的目录 | 数据文件也称之为快照文件(snapshot) | /tmp/zookeeper |
| clientPort | 端口号 | 连接端口 | 2181 |
| maxClientCnxns | 客户端最大连接数 | 单个客户端最大连接数限制,0 无限制 | 60 |
| autopurge.snapRetainCount | 快照文件保留数量 | 保留快照文件数量 | 3 |
| autopurge.purgeInterval | 自动清理快照文件和事务日志的频率 | 0表示不开启,单位小时 | 1 |
| dataLogDir | 指定存储日志的目录 | 未指定时默认将日志文件存放到dataDir中,为了性能最大化考虑建议将两个文件夹分开并且放到不同的磁盘中 | - |
| server.0 server.1 |
集群中服务的列表 | server.1=ip1:2888:3888 server.2=ip2:2888:3888 server.3=ip3:2888:3888 上面的配置中有两个TCP port。后面一个是用于Zookeeper选举用的,而前一个是Leader和Follower或Observer交换数据使用的。我们还注意到server.后面的数字。这个就是myid |
5. 文件系统
5.1 数据模型
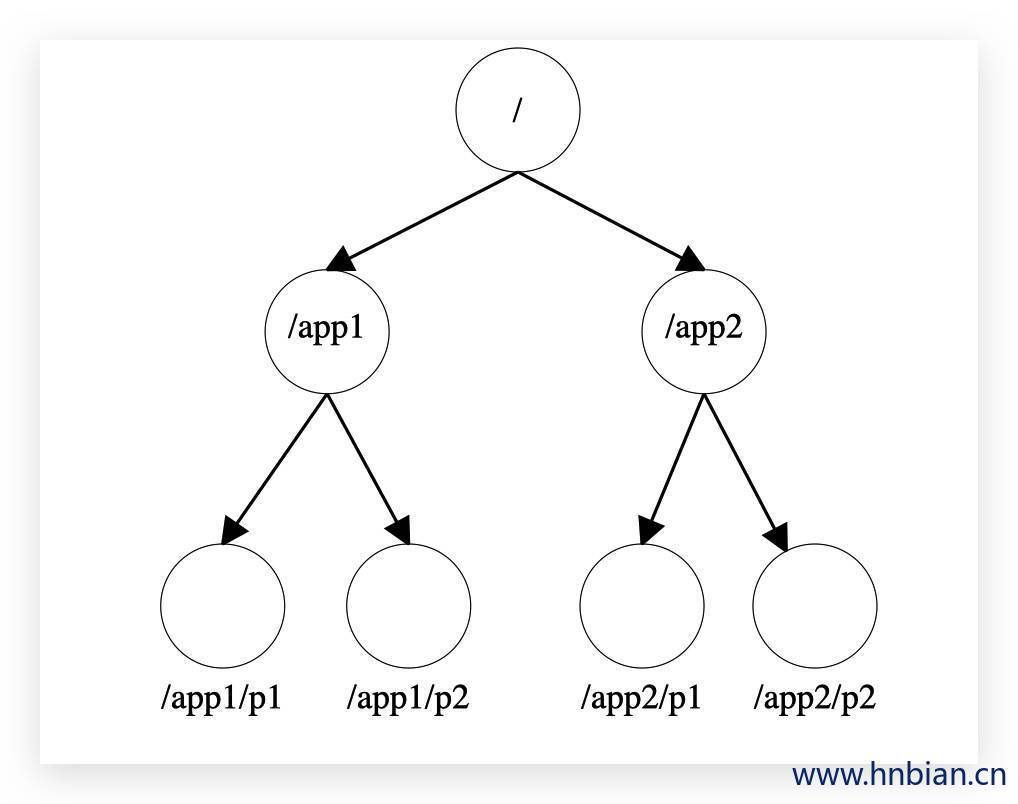
Zookeeper维护了一个类似Linux文件系统的数据结构,用于存储数据。
- 层次化的结构目录,命名符合常规文件系统规范
- 数据模型是一种树形的结构,由许多节点构成
- 每个节点在zookeeper中叫做znode(Zookeeper Node),并且有一个唯一的路径标识,可以通过该路径标识该节点
- 节点znode可以包含数据和子节点,每个节点都能存储大约1M的数据,
- Zonde中的数据可以有多个版本,如某一个路径下存有多个数据版本,查询这个路径下的数据就需要带上版本
- 客户端应用可以在节点上设置监视器(Watcher)
- 节点不支持部分读写,而是一次性完整读
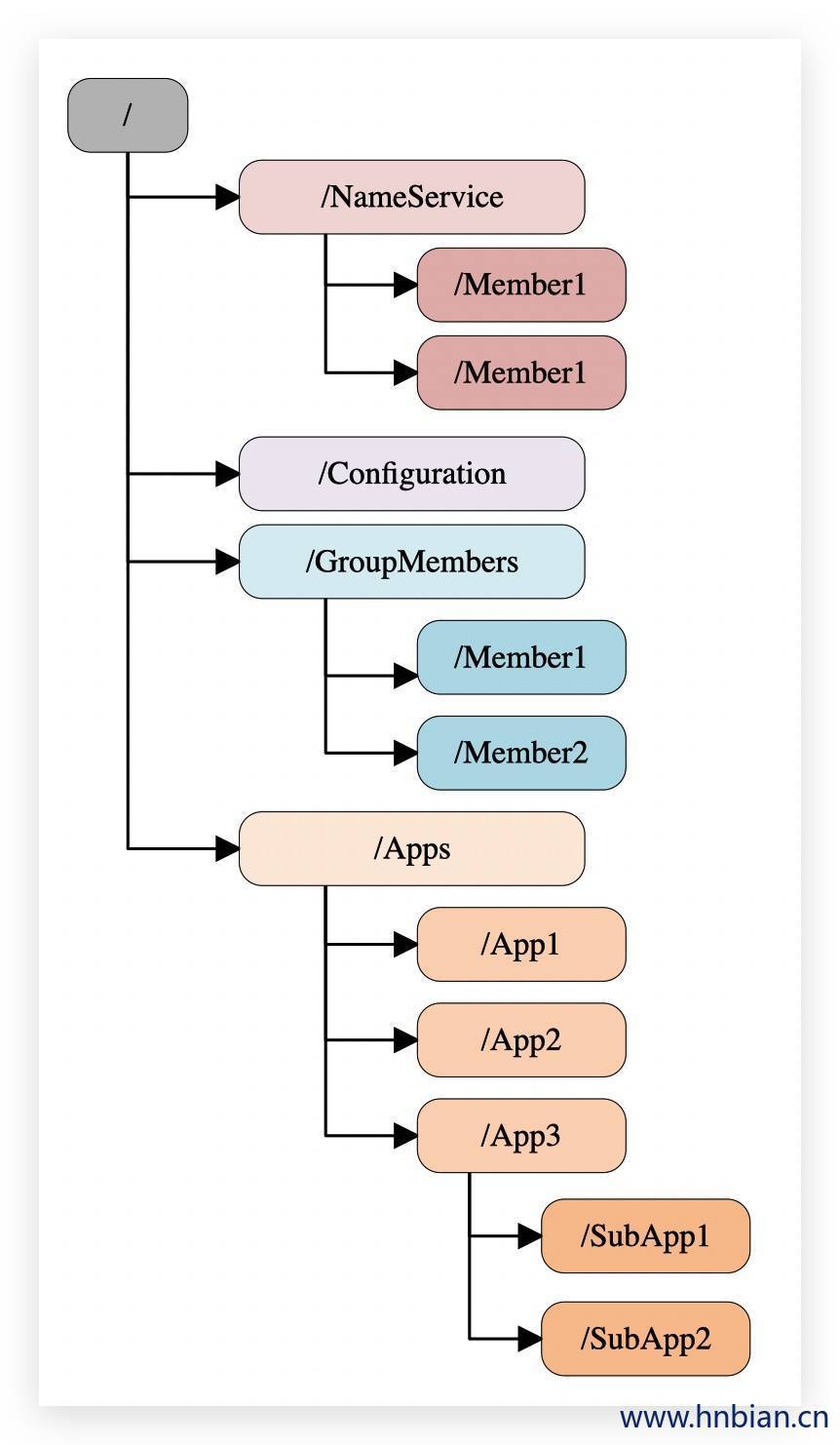
5.2 节点类型
- 节点时可以有类型的,基本类型有四种:
- 持久化目录节点(persistent):当客户端与服务器断开连接,之前所存在的节点仍然存在。
- 持久化顺序编号目录节点(persistent_sequential):当客户端与服务器断开连接,之前所存在的节点仍然存在。此时节点会被顺序编号,如:0001,0003….
- 临时目录节点(ephemeral_):当客户端与服务器断开连接以后会被删除。临时节点不能有子节点。
- 临时顺序编号目录节点(ephemeral_sequential):当客户端与服务器断开连接以后会被删除。此时节点会被顺序编号,如:0001,0003….
6. 监听机制
监听机制(Watch):是Zookeeper的一个核心功能,Watch可以监控目录节点的数据变化以及子界定的变化,一旦这些节点状态发生变化,服务器就会通知所有设置在这个目录节点上的Watcher,从而每个客户端都很快知道他所关注的节点状态发生变化而做出相应的反应
- 可以设置监听的操作有:exists、getChildren、getData
- 可以出发监听的操作有:create、delete、setData
- 监听事件是一个一次性的触发器,只能监听一次,如果数据再次发生改变则不会触发。
# 监听某个节点的值的变化
[zk: localhost:2181(CONNECTED) 54] get -w /rmiservers
/rmiservers
[zk: localhost:2181(CONNECTED) 55] set /rmiservers rmiservers2
WATCHER::
WatchedEvent state:SyncConnected type:NodeDataChanged path:/rmiservers
# 监听某个节点的子节点的变化
[zk: localhost:2181(CONNECTED) 56]
[zk: localhost:2181(CONNECTED) 56] ls -w /rmiservers
[]
[zk: localhost:2181(CONNECTED) 57] create /rmiservers/server1 server1
WATCHER::
WatchedEvent state:SyncConnected type:NodeChildrenChanged path:/rmiservers
Created /rmiservers/server1
[zk: localhost:2181(CONNECTED) 58]
7. ACL权限控制
7.1 权限特性
- ZooKeeper 的权限控制是基于每个 znode 节点的,需要对每个节点设置权限
- 每个 znode 支持设置多种权限控制方案和多个权限
- 子节点不会继承父节点的权限,客户端无权访问某节点,但可能可以访问它的子节点
7.2 权限类型
| 权限 | ACL简写 | 描述 |
|---|---|---|
| CREATE | c | 可以创建子节点 |
| DELETE | d | 可以删除子节点(仅下一级节点) |
| READ | r | 可以读取节点数据及显示子节点列表 |
| WRITE | w | 可以设置节点数据 |
| ADMIN | a | 可以设置节点访问控制列表权限 |
7.3 访问控制列表方案(ACL Schemes)
| 方案 | 描述 |
|---|---|
| world | 只有一个用户:anyone,代表所有人(默认) |
| ip | 使用 IP 地址认证 |
| auth | 使用已添加认证的用户认证 |
| digest | 使用“用户名:密码”方式认证 |
| ZooKeeper | 内置了一些权限控制方案,可以用以下方案为每个节点设置权限: |
7.4 权限相关命令
| 命令 | 使用方式 | 描述 |
|---|---|---|
| getAcl | getAcl |
读取 ACL 权限 |
| setAcl | setAcl |
设置 ACL 权限 |
| addauth | addauth |
添加认证用户 |
7.5 访问控制方案示例
7.5.1 World方案
- 设置方式:setAcl
world:anyone:
[zk: localhost:2181(CONNECTED) 2] create /app1 app1
Created /app1
# 查看权限
[zk: localhost:2181(CONNECTED) 3] getAcl /app1
'world,'anyone #默认为world方案
: cdrwa #任何人都拥有所有权限
[zk: localhost:2181(CONNECTED) 4]
#设置权限
[zk: localhost:2181(CONNECTED) 4] setAcl /app1 world:anyone:cdrwa
7.5.2 IP方案
- 设置方式:setAcl
ip: :
# 根据IP设置权限
[zk: localhost:2181(CONNECTED) 28] setAcl /app2 ip:172.16.72.150:cdrwa
[zk: localhost:2181(CONNECTED) 29]
[zk: localhost:2181(CONNECTED) 29]
[zk: localhost:2181(CONNECTED) 29] getAcl /app2
Authentication is not valid : /app2 ##没有权限
[zk: localhost:2181(CONNECTED) 30]
[zk: localhost:2181(CONNECTED) 30] get /app2
# 因为没有权限 获取节点值的时候会报错
org.apache.zookeeper.KeeperException$NoAuthException: KeeperErrorCode = NoAuth for /app2
[zk: localhost:2181(CONNECTED) 31] ls /
[app1, app2, rmiservers, zookeeper]
[zk: localhost:2181(CONNECTED) 32] set /app2 app3
Authentication is not valid : /app2
[zk: localhost:2181(CONNECTED) 33]
# 连接到有权限的节点
[zk: localhost:2181(CONNECTED) 33] connect 172.16.72.150:2181
WATCHER::
WatchedEvent state:Closed type:None path:null
2020-02-06 19:51:52,709 [myid:] - INFO [main:ZooKeeper@1422] - Session: 0x960000116b240000 closed
2020-02-06 19:51:52,709 [myid:] - INFO [main:ZooKeeper@868] - Initiating client connection, connectString=172.16.72.150:2181 sessionTimeout=30000 watcher=org.apache.zookeeper.ZooKeeperMain$MyWatcher@6bdf28bb
2020-02-06 19:51:52,711 [myid:] - INFO [main:ClientCnxnSocket@237] - jute.maxbuffer value is 4194304 Bytes
2020-02-06 19:51:52,711 [myid:] - INFO [main:ClientCnxn@1653] - zookeeper.request.timeout value is 0. feature enabled=
2020-02-06 19:51:52,709 [myid:] - INFO [main-EventThread:ClientCnxn$EventThread@524] - EventThread shut down for session: 0x960000116b240000
[zk: 172.16.72.150:2181(CONNECTING) 34] 2020-02-06 19:51:52,717 [myid:172.16.72.150:2181] - INFO [main-SendThread(172.16.72.150:2181):ClientCnxn$SendThread@1112] - Opening socket connection to server node1/172.16.72.150:2181. Will not attempt to authenticate using SASL (unknown error)
2020-02-06 19:51:52,718 [myid:172.16.72.150:2181] - INFO [main-SendThread(172.16.72.150:2181):ClientCnxn$SendThread@959] - Socket connection established, initiating session, client: /172.16.72.150:43201, server: node1/172.16.72.150:2181
2020-02-06 19:51:52,722 [myid:172.16.72.150:2181] - INFO [main-SendThread(172.16.72.150:2181):ClientCnxn$SendThread@1394] - Session establishment complete on server node1/172.16.72.150:2181, sessionid = 0x960000116b240001, negotiated timeout = 30000
WATCHER::
WatchedEvent state:SyncConnected type:None path:null
#查看该节点权限
[zk: 172.16.72.150:2181(CONNECTED) 34] getAcl /app2
'ip,'172.16.72.150
: cdrwa
#切换到无权限服务器 删除该节点,发现可以删除,(因为设置DELETE权限仅对下一级子节点有效,并不包含此节点)
[zk: localhost:2181(CONNECTED) 0] delete /app27.5.3 Auth 方案
- 设置方式
addauth digest: #添加认证用户
setAclauth: :
[zk: localhost:2181(CONNECTED) 0] addauth digest hn:123
[zk: localhost:2181(CONNECTED) 5] create /app3 app3
Created /app3
[zk: localhost:2181(CONNECTED) 6]
[zk: localhost:2181(CONNECTED) 6] setAcl /app3 auth:hn:cdrwa
[zk: localhost:2181(CONNECTED) 7]
[zk: localhost:2181(CONNECTED) 7] getAcl /app3
'digest,'hn:5AuV34pEw3oWr6NifYnevXcCU7g=
: cdrwa
[zk: localhost:2181(CONNECTED) 8]
[zk: localhost:2181(CONNECTED) 8]
[zk: localhost:2181(CONNECTED) 8] get /app3 # 因为刚刚添加了认证用户,所以可以直接读取数据,回话断开重连需要重新addauth 认证用户
app3
[zk: localhost:2181(CONNECTED) 9]
#断开连接重新get
[zk: localhost:2181(CONNECTED) 0] get /app3
org.apache.zookeeper.KeeperException$NoAuthException: KeeperErrorCode = NoAuth for /app3
[zk: localhost:2181(CONNECTED) 1]
#重新添加认证用户
[zk: localhost:2181(CONNECTED) 1] addauth digest hn:123
[zk: localhost:2181(CONNECTED) 2] get /app3
app37.5.4 Digest 方案
- 设置方式:setAcl
digest: : :
这里的密码是经过 SHA1 及 BASE64 处理的密文,在 SHELL 中可以通过以下命令计算:
echo -n
# 首先计算明文密码
[root@node1 ~]# echo -n hn:123 | openssl dgst -binary -sha1 | openssl base64
5AuV34pEw3oWr6NifYnevXcCU7g=
[zk: localhost:2181(CONNECTED) 0] create /app4 app4
Created /app4
[zk: localhost:2181(CONNECTED) 1]
# 设置权限
[zk: localhost:2181(CONNECTED) 2] setAcl /app4 digest:hn:5AuV34pEw3oWr6NifYnevXcCU7g=:cdrwa
[zk: localhost:2181(CONNECTED) 3]
[zk: localhost:2181(CONNECTED) 3] getAcl /app4
Authentication is not valid : /app4 # 没有权限
[zk: localhost:2181(CONNECTED) 4]
# 添加认证用户
[zk: localhost:2181(CONNECTED) 4] addauth digest hn:123
[zk: localhost:2181(CONNECTED) 5]
# 添加完认证用户之后再访问数据就有权限了
[zk: localhost:2181(CONNECTED) 5] getAcl /app4
'digest,'hn:5AuV34pEw3oWr6NifYnevXcCU7g=
: cdrwa8. 其他扩展
8.1 HDFS 高可用中对于Zookeeper的应用
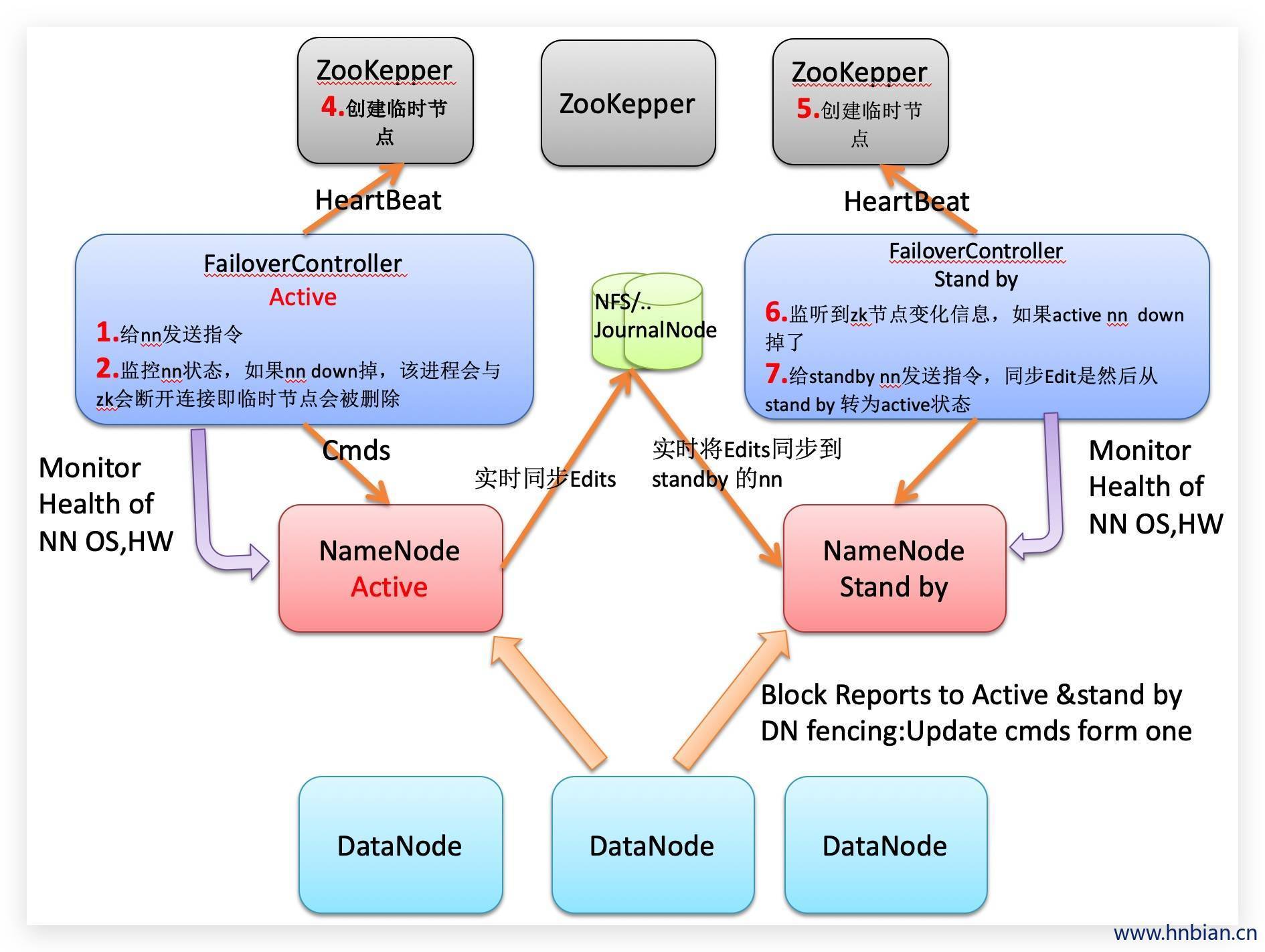
8.2 负载均衡
Zookeeper本身不提供负载均衡,需要自己实现,准确的说,是在负载均衡中使用Zookeeper来做集群的协调(也称为软负载均衡)。
实现思路:
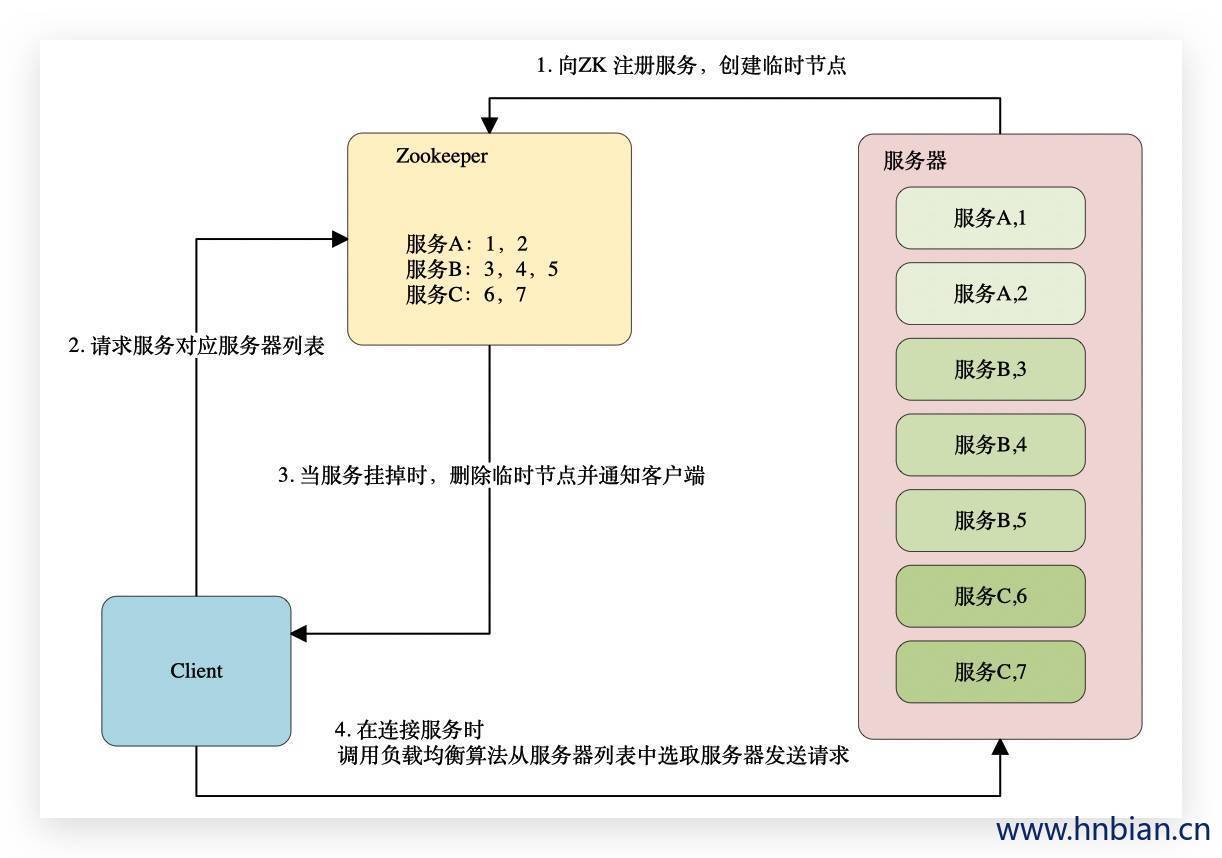
实际上利用了Zookeeper的文件系统和通知机制的特性,将Zookeeper作为服务的注册和变更通知中心。
9. Java 操作zookeeper
- 添加依赖
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.5.6</version>
</dependency>9.1 调用ZookeeperJavaAPI的操作
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.ZooKeeper;
import org.apache.zookeeper.data.Stat;
/**
* @Author haonan.bian
* @Description 测试Java操作zookeeper
* @Date 2020-02-02 14:58
**/
public class ZkTest {
public static void main(String[] args) {
try{
/**服务器地址*/
String connectionString = "hnode1:2181,hnode2:2181,hnode3:2181";
/**超时时间,单位毫秒 这里超时时间为三秒 超时时间后才会把临时节点删除*/
int sessionTimeout = 6000;
Watcher watcher = new ZkWatcher();
//获取zookeeper连接 创建zookeeper客户端
ZooKeeper zooKeeper = new ZooKeeper(connectionString,sessionTimeout,watcher);
Thread.sleep(6000);
System.out.println(zooKeeper.getState());
// CONNECTING: 正在连接,CONNECTED: 已经连接上
// 1. 查看根节点下面的内容并监视节点变化
/*List<String> list=zooKeeper.getChildren("/",true);
System.out.println(list);*/
//[zookeeper]
// 2. 创建节点 ,OPEN_ACL_UNSAFE 表示权限列表是开放的
/*String result = zooKeeper.create("/hello","hello".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
System.out.println(result);*/
// /hello
// 3. 获取节点的内容
Stat st = new Stat();
/*byte[] data=zooKeeper.getData("/hello",true,st);
System.out.println(data.toString());
System.out.println(st);*/
//12884901894,12884901894,1580888167625,1580888167625,0,0,0,0,5,0,12884901894
// 4. 修改节点的数据
//version 表示当前版本,版本设置错误将会报错,一般先获取数据状态的版本之后再设置版本
//zooKeeper.setData("/hello","hello1".getBytes(),st.getVersion());
//org.apache.zookeeper.KeeperException$BadVersionException: KeeperErrorCode = BadVersion for /hello
// 5. version 可以设置为-1,设置为不检测
//zooKeeper.setData("/hello","hello1".getBytes(),-1);
//6. 删除节点
//zooKeeper.delete("/hello",-1);
// 7. 判断节点是否存在
Stat helloStat =zooKeeper.exists("/hello",true);
System.out.println(helloStat);
//节点不存在返回null,节点存在返回节点状态
// 8. 关闭连接
zooKeeper.close();
}catch (Exception e){
e.printStackTrace();
}
}
}
9.2 基于Zookeeper 实现 RMI Server的HA
/**
* @Author haonan.bian
* @Description //TODO
* @Date 2020-02-05 18:50
**/
public class Constant {
public static final String ZOOKEEPER_PATH = "/rmiservers";
public static final String ZOOKEEPER_PATH_SERVER = "server";
/**
* 服务器地址
*/
public static final String HOSTS = "hnode1:2181,hnode2:2181,hnode3:2181";
/**
* 超时时间,单位毫秒 这里超时时间为6秒 超时时间后才会把临时节点删除
*/
public static final int SESSION_TIMEOUT = 6000;
}
import java.rmi.Remote;
import java.rmi.RemoteException;
/**
* @Author haonan.bian
* @Description //TODO
* @Date 2020-02-02 22:34
**/
public interface HelloService extends Remote {
String sayHello(String name) throws RemoteException;
}
import java.rmi.RemoteException;
import java.rmi.server.UnicastRemoteObject;
/**
* @Author haonan.bian
* @Description //TODO
* @Date 2020-02-02 22:35
**/
public class HelloServiceImpl extends UnicastRemoteObject implements HelloService {
protected HelloServiceImpl() throws RemoteException {
}
@Override
public String sayHello(String name) {
System.out.println("server print> hello: "+name);
return "hello: "+name;
}
}
/**
* @Author haonan.bian
* @Description //TODO
* @Date 2020-02-02 22:35
**/
public class RmiClient {
public static void main(String[] args) throws Exception {
ServiceConsumer serviceConsumer = new ServiceConsumer();
// 测试zookeeper
while(true){
HelloService helloService = (HelloService)serviceConsumer.lookup();
if(null != helloService){
String result = helloService.sayHello("world");
System.out.println(result);
}else{
System.out.println("helloService is null");
}
Thread.sleep(10000);
}
}
}
/**
* @Author haonan.bian
* @Description //TODO
* @Date 2020-02-02 22:38
**/
public class RmiServer {
public static void main(String[] args) throws Exception {
/*int port = 9999;
String url = "rmi://localhost:9999/com.hnbian.ha.HelloServiceImpl";
LocateRegistry.createRegistry(port);
Naming.rebind(url,new HelloServiceImpl());*/
int port = 9996;
String host = "127.0.0.1";
HelloService helloService = new HelloServiceImpl();
ServiceProvider serviceProvider = new ServiceProvider();
serviceProvider.publish(helloService,host,port);
}
}import com.hnbian.zk.ZkWatcher;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.ZooKeeper;
import java.rmi.Naming;
import java.rmi.Remote;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ThreadLocalRandom;
/**
* @Author haonan.bian
* @Description //TODO
* @Date 2020-02-05 18:44
**/
public class ServiceConsumer {
private volatile List<String> urlList = new ArrayList<>();
/**
* 用于等待SyncConnected 事件出发后继续执行当前线程
*/
private CountDownLatch latch = new CountDownLatch(1);
//构造方法
public ServiceConsumer(){
ZooKeeper zk = getConnection();
if(null != zk){
watchNode(zk);
}
}
public Remote lookup() throws Exception{
Remote service = null;
int size = urlList.size();
System.out.println("urlList.size():"+urlList.size());
if(size > 0 ){
String url;
if(size == 1){
//若urlList中只有一个元素,则直接获取该元素
url = urlList.get(0);
System.out.println(url);
}else{
//若urlList中有多个元素,则随机获取一个元素
url = urlList.get(ThreadLocalRandom.current().nextInt(size));
System.out.println(url);
}
// 从JNDI中查找RMI服务
service = lookupService(url);
}
return service;
}
private Remote lookupService(String url) throws Exception{
/*HelloService helloService = (HelloService) Naming.lookup(url);
return helloService;*/
return Naming.lookup(url);
}
// 观察 /rmiservice 节点下的子节点是否有变化
private void watchNode(final ZooKeeper zk){
try{
List<String> nodeList = zk.getChildren(Constant.ZOOKEEPER_PATH, new Watcher() {
@Override
public void process(WatchedEvent watchedEvent) {
if(watchedEvent.getType() == Event.EventType.NodeChildrenChanged){
System.out.println("发生变化,重新生成服务地址列表");
watchNode(zk);
}
}
});
//用于存放 /rmiservers 所有子节点中的数据
List<String> dataList = new ArrayList<>();
for(String node: nodeList){
byte[] data = zk.getData(Constant.ZOOKEEPER_PATH+"/"+node,false,null);
dataList.add(new String(data));
}
urlList = dataList;
}catch (Exception e){
e.printStackTrace();
}
}
//连接zookeeper服务器
private ZooKeeper getConnection() {
ZooKeeper zk = null;
try {
Watcher watcher = new ZkWatcher();
//获取zookeeper连接 创建zookeeper客户端
zk = new ZooKeeper(Constant.HOSTS, Constant.SESSION_TIMEOUT, new Watcher() {
@Override
public void process(WatchedEvent watchedEvent) {
if (watchedEvent.getState() == Event.KeeperState.SyncConnected) {
latch.countDown(); //唤醒当前正在执行的线程
}
}
});
latch.await(); // 使当前线程处于等待状态
System.out.println(zk.getState());
// CONNECTING: 正在连接,CONNECTED: 已经连接上
} catch (Exception e) {
e.printStackTrace();
}
return zk;
}
}import com.hnbian.zk.ZkWatcher;
import org.apache.zookeeper.*;
import java.rmi.Naming;
import java.rmi.Remote;
import java.rmi.registry.LocateRegistry;
import java.util.concurrent.CountDownLatch;
/**
* @Author haonan.bian
* @Description //TODO
* @Date 2020-02-05 16:56
**/
public class ServiceProvider {
/**
* 用于等待SyncConnected 事件出发后继续执行当前线程
*/
private CountDownLatch latch = new CountDownLatch(1);
//发布RMI服务并注册RMI 服务到zookeeper中
public void publish(Remote remote, String host, int port) {
String url = publishService(remote, host, port);
if (null != url) {
ZooKeeper zk = getConnection();
if (null != zk) {
//创建ZNode 并将RMI地址放入ZNode上。
createNode(zk, url);
}
}
}
//创建ZNode
private void createNode(ZooKeeper zk, String url) {
try {
byte[] data = url.getBytes();
//
String path = zk.create(Constant.ZOOKEEPER_PATH+"/"+Constant.ZOOKEEPER_PATH_SERVER,data, ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
System.out.println("created path:"+path);
} catch (Exception e) {
e.printStackTrace();
}
}
//发布RMI服务
public String publishService(Remote remote, String host, int port) {
String url = null;
try{
url = String.format("rmi://%s:%d/%s",host,port,remote.getClass().getName());
System.out.println(url);
LocateRegistry.createRegistry(port);
Naming.rebind(url,new HelloServiceImpl());
}catch (Exception e){
e.printStackTrace();
}
return url;
}
//连接zookeeper服务器
private ZooKeeper getConnection() {
ZooKeeper zk = null;
try {
Watcher watcher = new ZkWatcher();
//获取zookeeper连接 创建zookeeper客户端
zk = new ZooKeeper(Constant.HOSTS, Constant.SESSION_TIMEOUT, new Watcher() {
@Override
public void process(WatchedEvent watchedEvent) {
if (watchedEvent.getState() == Event.KeeperState.SyncConnected) {
latch.countDown(); //唤醒当前正在执行的线程
}
}
});
latch.await(); // 使当前线程处于等待状态
// CONNECTING: 正在连接,CONNECTED: 已经连接上
} catch (Exception e) {
e.printStackTrace();
}
return zk;
}
}import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
/**
* @Author haonan.bian
* @Description //TODO
* @Date 2020-02-02 15:02
**/
public class ZkWatcher implements Watcher {
@Override
public void process(WatchedEvent watchedEvent) {
System.out.println("ZkWatcher.process"+watchedEvent);
}
}
