[root@hnode3 hdfs]# cd /var/log/hadoop/hdfs [root@hnode3 hdfs]# less hadoop-hdfs-datanode-hnode3.log 2020-04-27 19:55:55,350 WARN common.Storage (DataStorage.java:loadDataStorage(418)) - Failed to add storage directory [DISK]file:/hadoop/hdfs/data java.io.IOException: Incompatible clusterIDs in /hadoop/hdfs/data: namenode clusterID = CID-aa0d5fb0-2e14-4c91-90cb-2a27e3c961e6; datanode clusterID = CID-c13d7ddf-1e75-4f0f-9cf3-d3fb50064ee5 at org.apache.hadoop.hdfs.server.datanode.DataStorage.doTransition(DataStorage.java:736) at org.apache.hadoop.hdfs.server.datanode.DataStorage.loadStorageDirectory(DataStorage.java:294) at org.apache.hadoop.hdfs.server.datanode.DataStorage.loadDataStorage(DataStorage.java:407) at org.apache.hadoop.hdfs.server.datanode.DataStorage.addStorageLocations(DataStorage.java:387) at org.apache.hadoop.hdfs.server.datanode.DataStorage.recoverTransitionRead(DataStorage.java:551) at org.apache.hadoop.hdfs.server.datanode.DataNode.initStorage(DataNode.java:1718) at org.apache.hadoop.hdfs.server.datanode.DataNode.initBlockPool(DataNode.java:1678) at org.apache.hadoop.hdfs.server.datanode.BPOfferService.verifyAndSetNamespaceInfo(BPOfferService.java:390) at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.connectToNNAndHandshake(BPServiceActor.java:280) at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.run(BPServiceActor.java:817) at java.lang.Thread.run(Thread.java:748) 2020-04-27 19:55:55,352 ERROR datanode.DataNode (BPServiceActor.java:run(829)) - Initialization failed for Block pool <registering> (Datanode Uuid 2c37038d-0623-4735-9ba4-ac42aff239c0) service to hnode2/192.168.7.77:8020. Exiting. java.io.IOException: All specified directories have failed to load. at org.apache.hadoop.hdfs.server.datanode.DataStorage.recoverTransitionRead(DataStorage.java:552) at org.apache.hadoop.hdfs.server.datanode.DataNode.initStorage(DataNode.java:1718) at org.apache.hadoop.hdfs.server.datanode.DataNode.initBlockPool(DataNode.java:1678) at org.apache.hadoop.hdfs.server.datanode.BPOfferService.verifyAndSetNamespaceInfo(BPOfferService.java:390) at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.connectToNNAndHandshake(BPServiceActor.java:280) at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.run(BPServiceActor.java:817) at java.lang.Thread.run(Thread.java:748) 2020-04-27 19:55:55,353 WARN datanode.DataNode (BPServiceActor.java:run(853)) - Ending block pool service for: Block pool <registering> (Datanode Uuid 2c37038d-0623-4735-9ba4-ac42aff239c0) service to hnode2/192.168.7.77:8020 2020-04-27 19:55:55,464 INFO datanode.DataNode (BlockPoolManager.java:remove(102)) - Removed Block pool <registering> (Datanode Uuid 2c37038d-0623-4735-9ba4-ac42aff239c0) 2020-04-27 19:55:57,471 WARN datanode.DataNode (DataNode.java:secureMain(2890)) - Exiting Datanode 2020-04-27 19:55:57,560 INFO datanode.DataNode (LogAdapter.java:info(51)) - SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down DataNode at hnode3/192.168.7.78 ************************************************************/
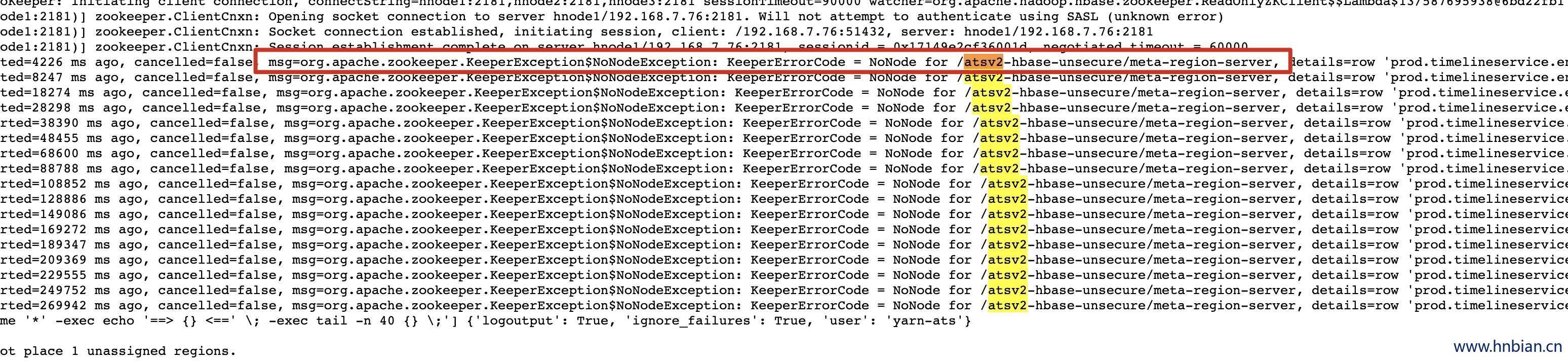
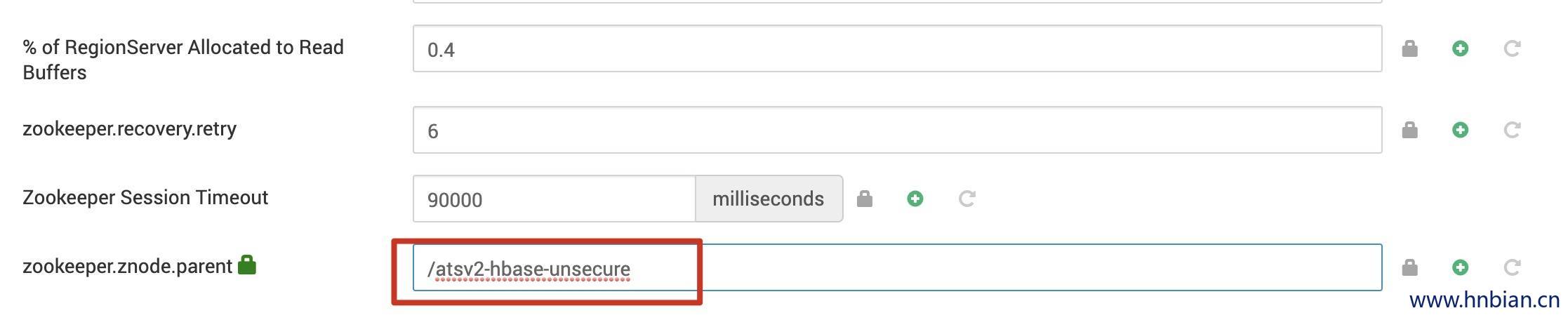
org.apache.zookeeper.KeeperException$NoNodeException: KeeperErrorCode = NoNode for /atsv2-hbase-unsecure/meta-region-server, details=row 'prod.timelineservice.entity' on table 'hbase:meta' at null
Traceback (most recent call last): File "/var/lib/ambari-agent/cache/stacks/HDP/3.0/services/YARN/package/scripts/timelinereader.py", line 119, in <module> ApplicationTimelineReader().execute() File "/usr/lib/ambari-agent/lib/resource_management/libraries/script/script.py", line 355, in execute self.execute_prefix_function(self.command_name, 'post', env) File "/usr/lib/ambari-agent/lib/resource_management/libraries/script/script.py", line 382, in execute_prefix_function method(env) File "/usr/lib/ambari-agent/lib/resource_management/libraries/script/script.py", line 424, in post_start raise Fail("Pid file {0} doesn't exist after starting of the component.".format(pid_file)) resource_management.core.exceptions.Fail: Pid file /var/run/hadoop-yarn-hbase/yarn-ats/hbase-yarn-ats-regionserver.pid doesn't exist after starting of the component.