1. 前言
数据仓库代表的是一套全面的数据管理和使用策略,包含了诸如ETL、调度和建模等完整的理论体系。而现在的“大数据”更多的是指数据量的增加和工具的更新。这两者并没有冲突,实际上,它们可以更好地结合起来。单纯使用Hadoop、Spark、Flume等工具处理数据,其实只是掌握了几种新的工具,这些工具只是数据仓库中ETL的一部分。
技术的更新往往能引领一个时代的变革,例如Hadoop的出现。深入研究一个大数据组件就需要投入大量的时间和精力。因此,作为数据专业人士,我们需要始终关注技术的变化。但是,请记住,数据才是核心。在追求技术的极致时,我们不能忘记我们的主要目标是处理数据。
本文对数据分层的讨论适合下面一些场景
- 数据建设刚起步,大部分的数据经过粗暴的数据接入后就直接对接业务。
- 数据建设发展到一定阶段,发现数据的使用杂乱无章,各种业务都是从原始数据直接计算而得。
- 各种重复计算,严重浪费了计算资源,需要优化性能。
2. 为什么要分层
我们对数据进行分层的主要目的是为了在管理数据时,能对数据有一个更清晰的脉络,从而更容易掌控。
详细来说,主要有以下几个原因:
- 清晰的数据结构: 每个数据分层都有其作用域,这样我们在使用表的时候能更方便地定位和理解。
- 数据血缘追踪: 简单来说,当一张源表出问题时,我们希望能快速准确地定位问题,并清楚它的影响范围。
- 减少重复开发: 规范数据分层,开发一些通用的中间层数据,能极大地减少重复计算。
- 简化复杂问题: 将一个复杂的任务分解成多个步骤来完成,每层只处理单一的步骤,这样更简单,易于理解,也便于维护数据的准确性。
- **屏蔽业务的影响:**不必每次业务变动就需要重新接入数据。
3.数据仓库分层介绍
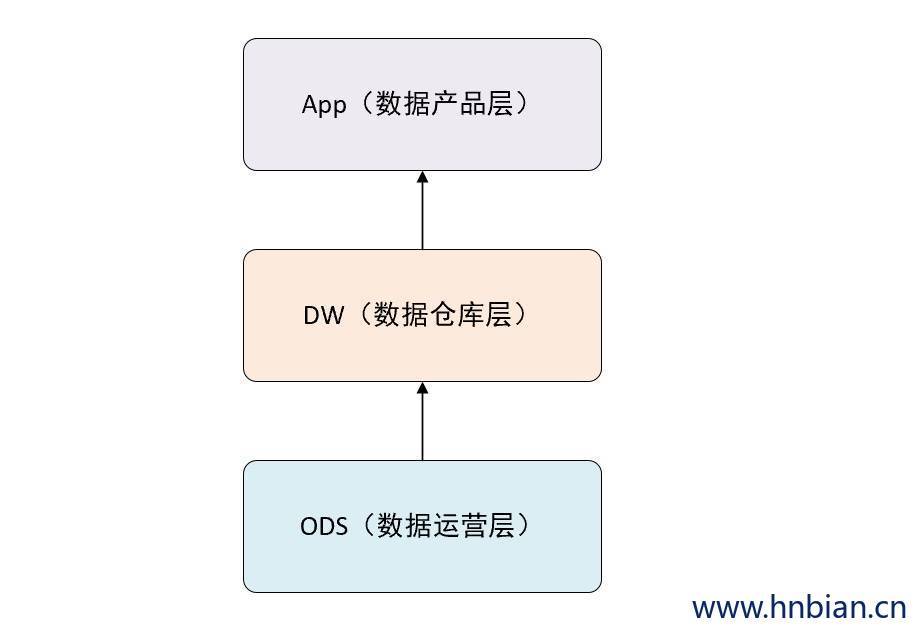
我们从理论上来做一个抽象,可以把数据仓库分为下面三个层,即:数据运营层、数据仓库层和数据产品层。
3.1 ODS
ODS 是 Operational Data Store 的简写,即操作数据存储层,或叫数据运营层。
ODS 是最接近数据源中数据的一层,数据源经过抽取、清洗、传输, 也就是传说中的 ETL 之后, 装入该层。
ODS 的数据,总体上大多是按照源头业务系统的分类方式进行分类的。
例如这一层可能包含的数据表为:
- 人口表(包含每个人的身份证号、姓名、住址等)
- 机场登机记录(包含乘机人身份证号、航班号、乘机日期、起飞城市等)
- 银联的刷卡信息表(包含银行卡号、刷卡地点、刷卡时间、刷卡金额等)
- 银行账户表(包含银行卡号、持卡人身份证号等) 等
这里我们可以看到,这一层的数据还具有鲜明的业务数据库的特征,甚至还具有一定的关系数据库中的数据范式的组织形式。
ODS 层的数据与原始数据的差别在于。在源数据转入这一层时,要进行数据清洗操作,如:
- **去燥:**从原始数据中去掉明显偏离正常水平的数据,如银行刷卡异常信息
- **去重:**数据去重,例如银行账户信息、公安局人口信息中均含有认得姓名,但是只保留一份即可)、
- **提脏:**清理脏数据,例如有人的银行卡被盗刷,在十分钟内同时有两笔分别在中国和日本刷卡信息,这便是脏数据
- 业务提取、单位统一:、砍字段,例如用于支撑前端系统工作,但是在数据挖掘中不需要的字段等操作
3.2 DW
- 数据仓库层(DW Data Warehouse ),是数据仓库的主体。
- DW 层从ODS(Operation Data Store)层中获得的数据按照主题建立各种数据模型。
- 例如以研究人的旅游消费为主题的数据集中,便可以结合航空公司的登机出行信息,以及银联系统的刷卡记录,进行结合分析,产生数据集。
- 在这里我们需要了解四个概念:维(dimension)、事实(fact)、指标(index) 和粒度(Granularity)
3.2.1 DWD 层
DWD 层(Detail Data Warehouse Data):也被称为细节数据层,这一层存储了从源系统获取的原始数据的详细记录。这些数据经过了一定程度的清洗和转换,以便在数据仓库中使用,但基本上保留了原始数据的所有细节。这意味着DWD层的数据通常包含大量的字段和记录,这使得它可以为多种不同的分析和报告需求提供支持。但是,由于其数据量大,通常不直接用于复杂的分析和报告。
3.2.2 DWS层
DWS层(Summary Data Warehouse Data):也被称为汇总数据层或者数据服务层,这一层存储了对DWD层数据进行汇总和进一步转换后的数据。这些汇总数据可以是按照不同维度(如时间、地理位置、客户等)进行的汇总,也可以是复杂的数据计算和转换的结果。这一层的数据通常用于高级分析和报告,因为它减少了需要处理的数据量,同时提供了更高层次的业务视角。
3.2.3 ODS 与 DWS 的区别?
ODS(Operational Data Store)层和DWD(Detail Data Warehouse Data)层都包含详细的数据记录,但它们的设计目标、数据处理方式和使用场景有所不同:
- ODS层(Operational Data Store):ODS 是一个面向操作的、集成的、可变的、当前的详细数据的集合,通常用于支持企业的日常运营。ODS层包含的数据通常是实时或近实时的,这意味着它会持续更新以反映最新的业务操作。ODS层的数据通常来自多个源系统,并且经过一定的清洗和转换以提供一致的视图。然而,ODS层并不包含大量的历史数据或进行复杂的数据汇总和计算。
- DWD层(Detail Data Warehouse Data):DWD是数据仓库的一部分,存储了从源系统(包括ODS)获取的详细数据记录。与ODS层不同,DWD层的数据通常包含大量的历史数据,并且可以用于复杂的数据分析和报告。这些数据经过了更深入的清洗和转换,以便在数据仓库中使用。在DWD层,数据不再实时更新,而是通过批处理方式定期(如每日或每周)更新。
总的来说,ODS和DWD的主要区别在于数据的实时性、历史性以及它们所支持的业务需求。ODS主要用于支持实时的业务操作,而DWD则主要用于支持历史数据分析和报告。
3.3 APP 数据产品层
- APP层 即 数据产品层,为数据产品提供使用的结果数据。
- APP层 主要是提供给数据产品和数据分析使用的数据,
- APP层 的数据一般会存放在 ElasticSearch、MySQL 等系统中供线上系统使用,也可能会存在 Hive 或者 Druid 中供数据分析和数据挖掘使用。
- 比如我们经常说的报表数据或者大宽表一般都属于这一层。
3. 数据实践
这三层技术划分,相对来说比较粗粒度,后面我们会专门细分一下。在此之前,先聊一下每一层的数据一般都是怎么流向的。这仅仅简单介绍几个常用的工具,侧重开源界的主流。
3.1 数据来源层 → ODS 层
这里就是我们现在的大数据技术发挥作用的主要战场。我们的数据主要会有两个大的来源:
业务库:这里经常会使用 Sqoop 来抽取比如我们每天定时抽取一次。在实施方面,可以考虑 Canal 监听 MySQL 的 binlog ,实时接入即可。
埋点日志:线上系统会打入各种日志,这些日志一般以文件的形式保存,我们可以选择用 Flume 定时抽取,也可以用Spark Streaming 或者 Storm 来实时接入,这时 Kafka 也会是一个关键的角色。
其他数据源会比较多样性,这和具体的业务相关,不再赘述。
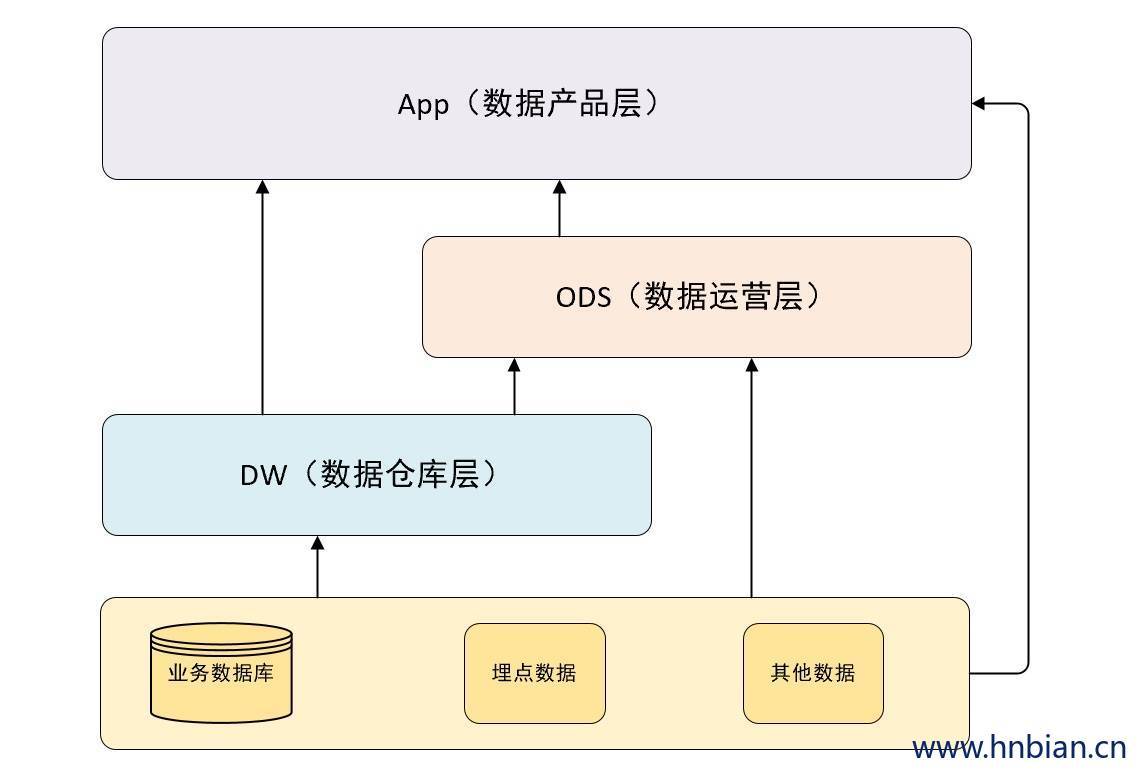
注意:在这层不是简单的接收数据,而要考虑一定的数据清洗,比如异常字段的处理、字段命名规范化、时间字段的统一等,一般这些很容易被忽略,但确实至关重要的。特别是后期我们做各种特征自动生成的时候,会十分有用。
4.2 ODS、DW → APP层
这里面也主要分为两种类型:
每日定时任务:比如我们典型的每日计算任务,每天凌晨算前一天的数据,早上起来看报表。这种任务经常使用Hive、Spark或者MR程序来计算,最终写入Hive、Hbase、Mysql、Es 或Redis中
实时数据:这部分主要是各种实时的系统使用,比如我们的实时推荐、实时用户画像、一般我们会使用 Spark streaming、Storm 或者 Flink 来计算,最后会落入 Es、HBase 或者 Redis 中。
- 举个例子
早期参与设计的数据分层例子。分析一下当初的想法,以及各种设计缺陷。当初设计共分6层,其中去掉元数据后还有5层。下面分析一下当初的一个设计思路。
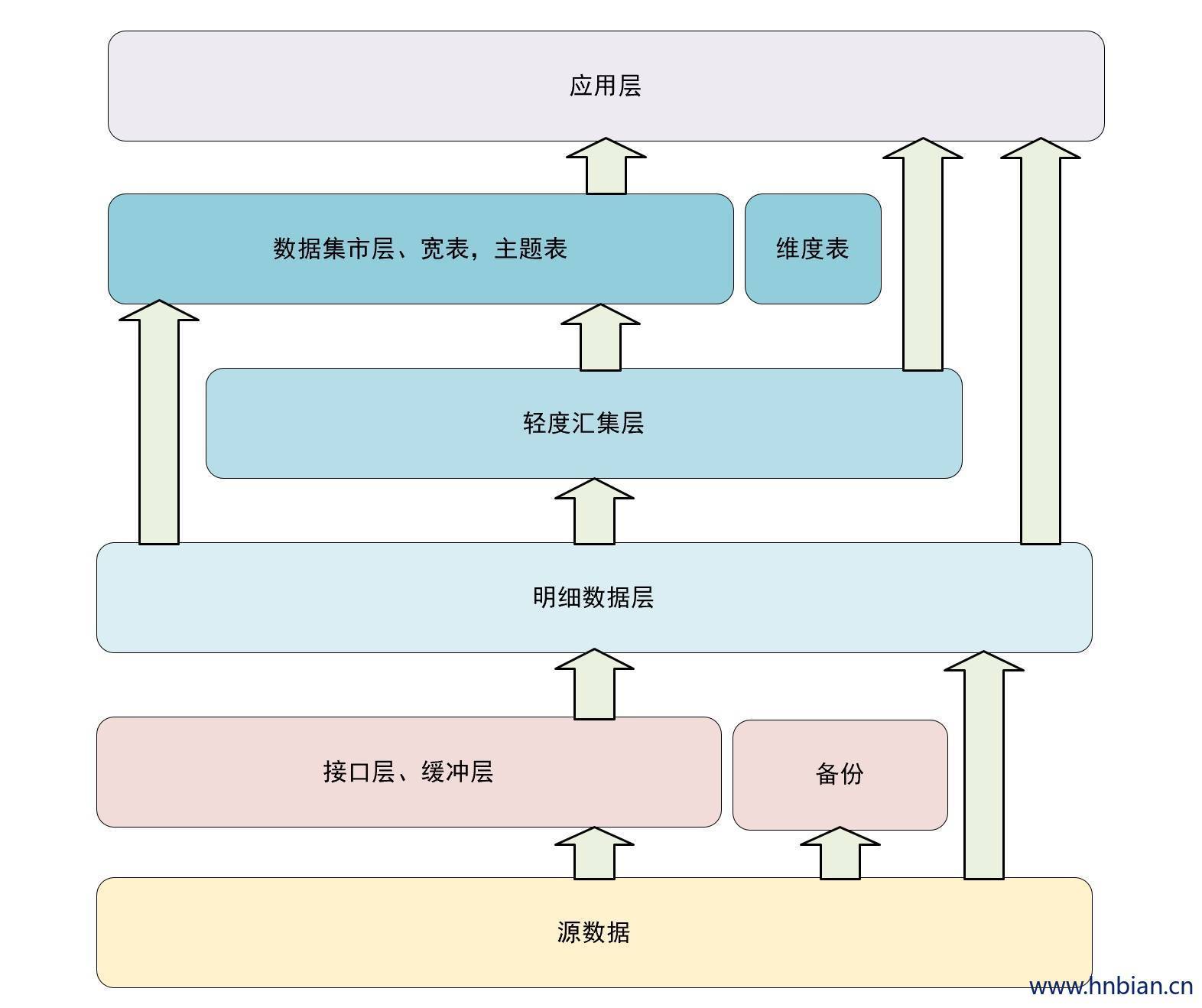
4.2.1 缓冲层
缓冲层(buffer)又称为接口层(Stage),用于存储每天的增量数据和变更数据,比如 Canal 接收的业务变更日志。
| 方案 | 实现 |
|---|---|
| 数据生成方式 | 直接从 Kafka 接收数据源,将每天业务表新增的数据,直接写入明细层。 |
| 讨论方案 | 把 Canal 日志直接写入缓冲层,如果其他有拉链数据的业务,也加入缓冲层。 |
| 日志存储方式 | 使用 Impala 外表, Parquet 文件格式,方便需要MR处理数据读取。 |
| 日志删除方式 | 长久存储,也可只存储最近几天的数据。 |
| 讨论方案 | 直接长久存储 |
| 表schema | Schema 一般与业务表相同,但是会一般按天创建分区 |
| 库与表命名 | 库名:buffer,表名:初步考虑格式为buffer-日期-业务表名 |
4.2.2 明细层
明细层(ODS Operational Data Store, DWD:data warehouse detail)是数据仓库的细节数据层,是对stage 层数据进行沉淀,减少了抽取的复杂性,同时ODS/DWD的信息模型组织主要遵循企业业务事务处理的形式,将各个专业数据进行加一种,明细层跟stage层的粒度一致,术语分析的公共资源
| 方案 | 实现 |
|---|---|
| 日志生成方式 | 部分数据直接来自kafka, 部分数据为接口层数据与历史数据合成。 |
| canal 数据的合成 | 每天把明细层的前天全量数据和昨天数据合成一个新的数据表,覆盖旧表。 同时使用历史镜像, 按周/按月/按年存储一个历史镜像到新表。 |
| 日志存储方式 | 直接使用 Impala 外表, Parquet 文件格式。 Canal 合成数据为二次生成数据,建议使用内表, 下面几层都是从 Impala 生成的数据,建议都采用内表+静态/动态分区。 |
| 日志删除方式 | 长久存储。 |
| 表schema | 一般按天创建分区,没有时间概念的按具体业务选择分区字段 |
| 库与表命名 | 库名:ods, 表名:ods-日期-业务表名 |
| 旧数据更新方式 | 直接覆盖 |
4.2.3 轻度汇总层
概念:轻度汇总层(MID 或DWB ,data warehouse basis)是数据仓库中DWD层和DM层之间的一个过渡层,是对DWD层生产数据进行轻度综合和汇总统计(可以把复杂的清洗,处理包含在内,如根据PV日志生成的会话数据)。轻度综合层与DWD的主要区别在于二者的应用领域不同,DWD的数据源于生产型系统,并未满足一些不可预见的需求而进行产店,轻度综合层则面向分析型应用进行细粒度的统计和沉淀
| 方案 | 实现 |
|---|---|
| 数据生成方式 | 由明细层按照一定的业务需求生成轻度汇总表。 明细层需要复杂清洗的数据和需要MR处理的数据也经过处理后接入到轻度汇总层。 |
| 日志存储方式 | 内表, Parquet 文件格式。 |
| 日志删除方式 | 长久存储 |
| 表schema | 一般按天创建分区,没有时间概念的额按具体业务选择分区字段。 |
| 库与表名 | 库名:dwd, 表名:dwd-日期-业务表名 |
| 就数据更新方式 | 直接覆盖 |
4.2.4 主题层
主题层(DM,data market或DWS data warehouse service)又称数据集市或宽表。按照业务划分,如流量,订单,用户等,生成字段比较多的宽表,用于提供后续的业务查询,OLAP分析,数据分发等。
| 方案 | 实现 |
|---|---|
| 数据生成方式 | 由轻度汇总层和明细层数据计算生成。 |
| 日志存储方式 | 使用 Impala 内表, Parquet 文件格式存储。 |
| 日志删除方式 | 长久存储 |
| 表schema | 一般按天创建分区,没有时间概念的按具体业务选择分区字段。 |
| 库名与表名 | 库名:dm,表名:dm-日期-业务表名。 |
| 旧数据更新方式 | 直接覆盖 |
4.2.5 应用层
应用层(APP)是根据业务需要,由前面三层数据统计而出的结果。可以直接提供查询展示,或导入mysql中使用。
| 方案 | 实现 |
|---|---|
| 数据生成方式 | 由明细层、轻度汇总层、数据集市层生成,一般要求数据主要来源于集市层。 |
| 日志存储方式 | 使用 Impala 内表, Parquet 文件格式存储。 |
| 日志删除方式 | 长久存储 |
| 表schema | 一般按天创建分区,没有时间概念的按具体业务选择分区字段。 |
| 库名与表名 | 库名:暂定apl,另外根据业务不同,不限定一定要一个库。 |
| 旧数据更新方式 | 直接覆盖 |
5. 更优雅的设计数据分层
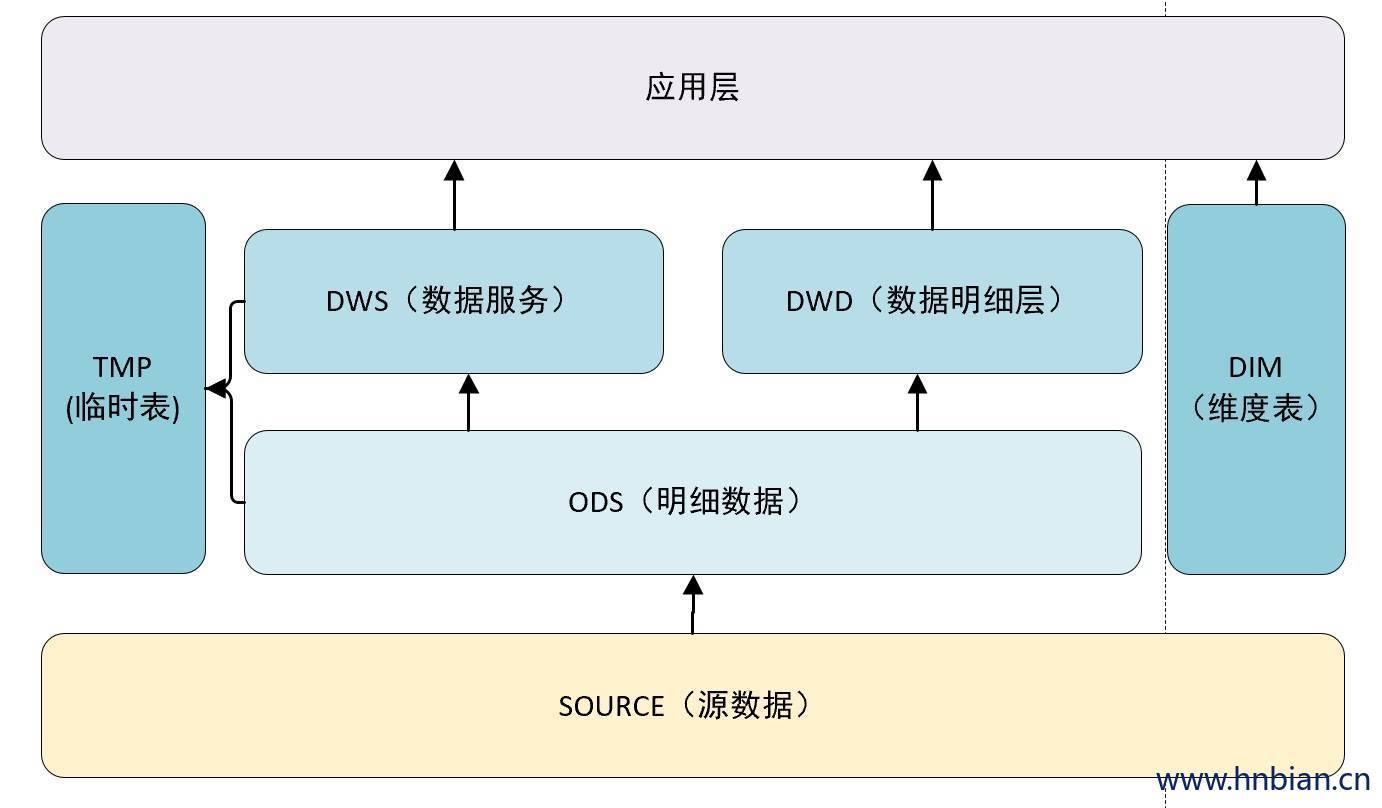
在我们的先前讨论中,数据仓库的设计已经相当详细,但可能层次过多,以至于在决定将特定表格存放在何处时可能产生一些困惑。因此,我们现在打算对数据仓库的分层进行再设计,在现有基础上考虑加入维度表和临时表,以提升我们的方案的精致性和优雅度。
下面做了一些小的改动,我们去掉了上一节的 Buff 层,把数据集市层和轻度汇总层放在同一个层级上,同时独立出来了维度表和临时表。
这里解释一下 DWS、DWD、DIM 和 TMP 的作用
| 层级 | 说明 |
|---|---|
| DWS | 轻度汇总层,对 ODS 层中用户的行为做一个初步的汇总,抽象出来一些通用的维度:时间、ip、id,并根据这些维度做一些统计值,比如用户每个时间段在不同登陆ip购买的商品数等。这里做轻度的数据汇总会让计算更加高效,在此基础上如果计算7天、30天、90天的行为的话会很快。我们希望80%的业务都能通过的DWS层计算而不是ODS |
| DWD | 明细数据层,这一层主要解决一些数据质量问题和数据的完整度问题。比如用户的资料信息来自于很多不同的表,而且经常出现延迟丢数据等问题,为了方便各使用方更好地使用数据,我们可以在这一层做数量质量保证 |
| DIM | 维度层(也被称为维度模型或者星型模型)是一种常用的数据组织和表示方式,它是由维度表(Dimension Tables)和事实表(Fact Tables)组成的。 维度表主要存放的是描述性或者分类性的数据,也就是我们常说的维度数据。这些数据用于定义和描述事实数据的各个方面或者维度,比如时间(年份、季度、月份、日期、星期)、地理位置(国家、省份、城市)、产品(产品分类、产品名称、产品规格)等。 |
| TMP | 每一层的计算都会有很多临时表,专设一个TMP 层来存储我们数据仓库的临时表 |
6.问答
问:dws 和 dwd 是并行而不是先后顺序?
答:并行的 dw 层
问:那其实对于同一个数据,这两个过程是串行的?
答:dws 会做汇总,dwd 和 ods 的粒度相同,这两层没有依赖关系
问:那这样 dws 里面的数据汇总没有经过数据质量和完整度的处理,或者单独做了这种质量相关的处理,为什么不在 dwd 之上再做汇总呢?我的疑问其实就是,dws 的轻度汇总数据结果,有没有做数据质量的处理?
答:ods 直接到 dws 就好,没必要经过 dwd,我举个例子,你的浏览商品行为,我做一层轻度汇总,就直接放在 dws 了。但是你的资料表,要从好多表凑成一份,我们从四五分个人资料表中凑出来了一份完整地资料表放在了dwd中,然后在app层,我们要出一个画像表,包含用户资料和用户最近一年的行为,我们就直接从 dwd 中拿资料,然后再 dws 的基础上做一哥统计, 就成了一个 app 表
问:最后一个疑问,在现实生产中,可不可能存在计算 dws 时,会用到 dwd表 的情况?
答:不,dws 不会依赖 dwd,dws 只接轻度汇总,业务用的话都取app层。
问:dws 针对的是行为,可以在某些维度上上卷的行为
答:你这样理解吧,dws 存事实表,dwd 维度表
7.总结
数据分层在数据仓库中扮演着至关重要的角色,其影响并不仅限于层次结构。它直接影响到后续的血缘分析、特征自动生成、元数据管理等一系列的构建工作。因此,应尽早考虑这个因素。此外,对于每一层的命名,不必过于担心。可以根据个人喜好来决定。

