1. ReplacingMergeTree
1.1 介绍
1
2
3
4
5
6
7
8
9
10
11
| CREATE TABLE [IF NOT EXISTS] [db_name.]table_name(
name1 [type] [DEFAULT|MATERIALIZED|ALIAS expr],
name2 [type] [DEFAULT|MATERIALIZED|ALIAS expr],
...
) ENGINE = ReplacingMergeTree(var)
[PARTITION BY expr]
[ORDER BY expr]
[PRIMARY KEY expr]
[SAMPLE BY expr]
[SETTINGS name=value, ...]
|
其中 var 是选填参数,会指定一个 UInt、Date或 DateTime 类型的段作为版本号,这个参数确定了去重时使用的算法。
1.2 使用示例
- 准备数据
| id |
code |
create_time |
| A01 |
102 |
2021-06-03 10:04:35 |
| A01 |
101 |
2021-06-03 10:05:35 |
| A02 |
104 |
2021-06-03 10:06:35 |
| A02 |
103 |
2021-06-03 10:07:35 |
| A03 |
105 |
2021-06-03 10:08:35 |
| A03 |
105 |
2021-06-03 10:09:35 |
- 创建测试表并插入数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
CREATE TABLE t_merge_replace
(
`id` String,
`code` UInt8,
`create_time` DateTime
)
ENGINE = ReplacingMergeTree
partition by toYYYYMM(create_time)
ORDER BY (id,code)
primary key id;
insert into t_merge_replace values
('A01',102,'2021-06-03 10:04:35'),
('A01',101,'2021-06-03 10:05:35'),
('A02',104,'2021-06-03 10:06:35'),
('A02',103,'2021-06-03 10:07:35'),
('A03',105,'2021-06-03 10:08:35'),
('A03',105,'2021-06-03 10:09:35');
|
- 执行分区合并删除重复数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
optimize table t_merge_replace;
select * from t_merge_replace;
┌─id──┬─code─┬─────────create_time─┐
│ A01 │ 101 │ 2021-06-03 10:05:35 │
│ A01 │ 102 │ 2021-06-03 10:04:35 │
│ A02 │ 103 │ 2021-06-03 10:07:35 │
│ A02 │ 104 │ 2021-06-03 10:06:35 │
│ A03 │ 105 │ 2021-06-03 10:09:35 │
└─────┴──────┴─────────────────────┘
|
- 不同分区数据去重
从上面的例子中可以看到去重效果还不错,但是当插入不同分区的重复数据时发现并不是想象的那样
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
insert into t_merge_replace values
('A01',102,'2021-07-03 10:04:35'),
('A01',101,'2021-07-03 10:05:35');
select * from t_merge_replace;
┌─id──┬─code─┬─────────create_time─┐
│ A01 │ 101 │ 2021-06-03 10:05:35 │
│ A01 │ 102 │ 2021-06-03 10:04:35 │
│ A02 │ 103 │ 2021-06-03 10:07:35 │
│ A02 │ 104 │ 2021-06-03 10:06:35 │
│ A03 │ 105 │ 2021-06-03 10:09:35 │
└─────┴──────┴─────────────────────┘
┌─id──┬─code─┬─────────create_time─┐
│ A01 │ 101 │ 2021-07-03 10:05:35 │
│ A01 │ 102 │ 2021-07-03 10:04:35 │
└─────┴──────┴─────────────────────┘
optimize table t_merge_replace;
select * from t_merge_replace;
┌─id──┬─code─┬─────────create_time─┐
│ A01 │ 101 │ 2021-07-03 10:05:35 │
│ A01 │ 102 │ 2021-07-03 10:04:35 │
└─────┴──────┴─────────────────────┘
┌─id──┬─code─┬─────────create_time─┐
│ A01 │ 101 │ 2021-06-03 10:05:35 │
│ A01 │ 102 │ 2021-06-03 10:04:35 │
│ A02 │ 103 │ 2021-06-03 10:07:35 │
│ A02 │ 104 │ 2021-06-03 10:06:35 │
│ A03 │ 105 │ 2021-06-03 10:09:35 │
└─────┴──────┴─────────────────────┘
|
1.3 版本号的用法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
CREATE TABLE t_merge_replace2
(
`id` String,
`code` UInt8,
`create_time` DateTime
)
ENGINE = ReplacingMergeTree(create_time)
partition by toYYYYMM(create_time)
ORDER BY (id)
primary key id;
insert into t_merge_replace2 values
('A01',102,'2021-06-03 10:04:35'),
('A01',101,'2021-06-03 10:05:35'),
('A02',104,'2021-06-03 10:06:35'),
('A02',103,'2021-06-03 10:07:35'),
('A03',105,'2021-06-03 10:08:35'),
('A03',105,'2021-06-03 10:09:35');
optimize table t_merge_replace2;
select * from t_merge_replace2;
┌─id──┬─code─┬─────────create_time─┐
│ A01 │ 101 │ 2021-06-03 10:05:35 │
│ A02 │ 103 │ 2021-06-03 10:07:35 │
│ A03 │ 105 │ 2021-06-03 10:09:35 │
└─────┴──────┴─────────────────────┘
|
1.4 总结
- 使用 order by 排序键作为判断数据是否重复的依据
- 只有在分区合并时触发删除重复数据的逻辑
- 以分区为单位删除重复数据,不同分区内的重复数据不会去重
- 进行数据去重时,因为分区内的数据已经按照order by 进行排序了,所以能够找到重复的数据
- 去重策略有联众
- 如果没有设置版本号(var) 保留同一组中最后一行数据
- 如果设置了版本号(var)保留同一组数据中保留var 字段取值最大的一行数据
2. SummingMergeTree
2.1 介绍
- SummingMergeTree是为了只关心汇总结果,不关心明细数据,且汇总条件固定不会随意修改的场景而设计的。
- SummingMergeTree能够在合并分区时按照预先定义的条件汇总聚合数据,将同一组下的多行数据合并成一行,这样既减少了数据量,有降低了查询汇总数据时的消耗。
2.2 排序键与主键
在 MergeTree 分区内数据会按照 order by (排序键)表达式排序,主键索引也会按照 primary key(主键) 表达式取值并排序,而 order by 可以取代 主键,在一般情形下,只需要定义 order by 即可,此时排序键与主键相同,即数据排序与主键索引相同。
如果需要同时定义 排序键 与 主键 通常只有一种情况,那就是希望排序键与主键不同,这种情况通常只在定义 SummingMergeTree 和 AggregratingMergeTree 时才会出现,这是因为,这两种表引擎的数据聚合都是根据排序键进行的,主键与聚合的条件定义分离,为修改聚合条件留下更大的空间。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
order by (A,B,C)
order by (A,B,C)
primary key A
order by (A,B,C)
primary key B
|
当业务发生变化,只需要根据需要增减排序键改变聚合规则即可,相对于不可修改的主键,便利了很多。
1
2
|
alter table table_name modify ordery by (A,B)
|
2.3 使用介绍
1
2
3
4
5
6
7
8
9
10
11
12
|
CREATE TABLE [IF NOT EXISTS] [db_name.]table_name(
name1 [type] [DEFAULT|MATERIALIZED|ALIAS expr],
name2 [type] [DEFAULT|MATERIALIZED|ALIAS expr],
...
) ENGINE = SummingMergeTree((col1,col2,...))
[PARTITION BY expr]
[ORDER BY expr]
[PRIMARY KEY expr]
[SAMPLE BY expr]
[SETTINGS name=value, ...]
|
- col1,col2,… 是选填项,为 columns 参数值,用于设置除主键外的其它数值类型字段,以指定被 sum 汇总的列字段,若不指定此字段,会将所有非主键的数值类型字段进行汇总
- ORDER BY 排序键,也作为数据聚合的依据
- PRIMARY KEY 主键,主键必须作为排序键的前缀
2.4 使用示例
- 准备数据
| id |
code |
num1 |
num2 |
create_time |
| A01 |
C01 |
102 |
10.3 |
2021-06-03 10:04:35 |
| A01 |
C01 |
101 |
5.7 |
2021-06-03 10:05:35 |
| A01 |
C02 |
104 |
9.7 |
2021-06-03 10:06:35 |
| A02 |
C02 |
103 |
5.8 |
2021-06-03 10:07:35 |
| A02 |
C02 |
105 |
3.2 |
2021-06-03 10:08:35 |
| A02 |
C03 |
105 |
1.3 |
2021-06-03 10:09:35 |
- 创建测试表并插入数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
CREATE TABLE db_merge.t_merge_sum (
`id` String,
`code` String,
`num1` UInt32,
`num2` Float32,
`create_time` DateTime
) ENGINE = SummingMergeTree()
partition by toYYYYMM(create_time)
ORDER BY (id,code)
primary key id;
insert into db_merge.t_merge_sum values
('A01','C01',102,9.3,'2021-06-03 10:04:35'),
('A01','C01',101,5.7,'2021-06-03 10:05:35'),
('A01','C02',104,9.7,'2021-06-03 10:06:35'),
('A02','C02',103,5.8,'2021-06-03 10:07:35'),
('A02','C02',105,3.2,'2021-06-03 10:08:35'),
('A02','C03',105,1.3,'2021-06-03 10:09:35');
optimize table db_merge.t_merge_sum final;
select * from db_merge.t_merge_sum;
┌─id──┬─code─┬─num1─┬─num2─┬─────────create_time─┐
│ A01 │ C01 │ 203 │ 15 │ 2021-06-03 10:04:35 │
│ A01 │ C02 │ 104 │ 9.7 │ 2021-06-03 10:06:35 │
│ A02 │ C02 │ 208 │ 9 │ 2021-06-03 10:07:35 │
│ A02 │ C03 │ 105 │ 1.3 │ 2021-06-03 10:09:35 │
└─────┴──────┴──────┴──────┴─────────────────────┘
|
- 嵌套类型数据聚合
SummingMergeTree 同样支持嵌套类型的字段,在使用嵌套类型段时,需要被 sum汇总的字段名称必须以map 后缀结尾,
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
CREATE TABLE db_merge.t_merge_sum_nested
(
`id` String,
`nestMap` Nested(id UInt32, key UInt32, val UInt32),
`create_time` DateTime
)
ENGINE = SummingMergeTree
PARTITION BY toYYYYMM(create_time)
ORDER BY id;
insert into db_merge.t_merge_sum_nested values
('A01', [1,1,2], [10,20,30],[10,11,12],'2021-06-03 10:04:35'),
('A01', [3,3,4], [40,50,60],[13,14,15],'2021-06-03 10:05:35'),
('A02', [5,5,6], [70,80,90],[16,17,18],'2021-06-03 10:06:35');
optimize table db_merge.t_merge_sum final;
select * from db_merge.t_merge_sum_nested;
┌─id──┬─nestMap.id─┬─nestMap.key───┬─nestMap.val───┬─────────create_time─┐
│ A01 │ [1,2,3,4] │ [30,30,90,60] │ [21,12,27,15] │ 2021-06-03 10:04:35 │
│ A02 │ [5,6] │ [150,90] │ [33,18] │ 2021-06-03 10:06:35 │
└─────┴────────────┴───────────────┴───────────────┴─────────────────────┘
|
在使用嵌套类型的时候,也支持使用复合 key 作为聚合条件为了使用复合 key ,在嵌套类型的字段中,除第一个字段外,任何以 key,id 或 type为后缀结尾的字段,都将和第一个字段组成复合 key。如将上面的 key 改为 Key,就会以 id 和 Key 作为聚合条件。
2.5 总结
- 用 order by 排序键作为聚合数据的条件 key
- 只有在分区合并的时候才会触发合并逻辑
- 以分区为单位聚合数据,合并分区时,同一分区内相同排序键的数据将会被合并汇总,不同分区间的数据不会被汇总
- 如果在定义引擎时指定了 columns 参数值,则会汇总被指定的列字段,若不指定此字段,会将所有非主键的数值类型字段进行汇总
- 在进行数据汇总时,因为分区内的数据已经进行了 order by 排序,所以能够找到相邻具有相同聚合 key 的数据。
- 在进行数据汇总时,同一分区内多行相同聚合 key 的数据会合并成一行,对于非聚合字段,会取第一行数据的值
- 支持嵌套结构,但列明字段必须以 Map 结尾,嵌套类型中,默认以第一个字段作为聚合 key,除第一个字段外,任何以Key、ID或Type为后缀的字段,都将与第一个字段一起组成复合 key。
3. AggregatingMergeTree
数据仓库领域有一个十分常见的模型,数据立方体,它通过以空间换时间的方式提升查询性能,将需要聚合的数据预先算出来,并将结果保存,在需要进行聚合查询时,直接查询结果
3.1 介绍
- AggregatingMergeTree 跟数据立方体有些相似,它能够在合并分区时,按照预先定义的条件聚合数据。
- AggregatingMergeTree 会根据预先定义的聚合函数计算数据并通过二进制的格式存入表中。
- AggregatingMergeTree 将同一分组下的多行数据聚合成一行,即减少了数据又降低了后续聚合查询的开销。
- AggregatingMergeTree 相当于是SummingMergeTree的升级版,二者有许多设计思路是一致的,比如 排序键与主键的设计。
3.2 定义方式
1
2
3
4
5
6
7
8
9
10
11
12
| CREATE TABLE [IF NOT EXISTS] [db_name.]table_name(
name1 [type] [DEFAULT|MATERIALIZED|ALIAS expr],
name2 [type] [DEFAULT|MATERIALIZED|ALIAS expr],
name3 AggregateFunction(Function,type),
...
) ENGINE = AggregatingMergeTree()
[PARTITION BY expr]
[ORDER BY expr]
[PRIMARY KEY expr]
[SAMPLE BY expr]
[SETTINGS name=value, ...]
|
AggregatingMergeTree 没有额外设置的参数,合并分区时在每个数据分区内,会按照order by 聚合数据,而做哪种聚合操作会通过AggregateFunction 数据类型实现。
3.3 使用介绍
AggregatingMergeTree 是 clickhouse提供的一种特殊数据类型,它能够以二进制的形式存储中间状态结果。
AggregatingMergeTree 使用方式也有些特殊,对于AggregateFunction 类型的列,数据的查询与写入都与平常的列不同,
AggregatingMergeTree 在写入数据时需要调用 对应的State函数, 而在查询时,需要调用对应的 Merge 函数。
示例如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
CREATE TABLE db_merge.t_merge_agg (
`id` String,
`city` String,
`code` AggregateFunction(uniq,String),
`value` AggregateFunction(sum,UInt32),
`create_time` DateTime
) ENGINE = AggregatingMergeTree()
partition by toYYYYMM(create_time)
ORDER BY (id,city)
primary key id;
insert into table db_merge.t_merge_agg
select 'A01','shenzhen',uniqState('code1'),sumState(toUInt32(100)),'2021-06-04 15:27:22'
union all
select 'A01','shenzhen',uniqState('code2'),sumState(toUInt32(200)),'2021-06-04 15:28:22';
select id,city,uniqMerge(code),sumMerge(value) from db_merge.t_merge_agg group by id,city;
┌─id──┬─city─────┬─uniqMerge(code)─┬─sumMerge(value)─┐
│ A01 │ shenzhen │ 2 │ 300 │
└─────┴──────────┴─────────────────┴─────────────────┘
|
AggregatingMergeTree 更常用的方式是结合物化视图使用,将它作为物化视图的表引擎。
物化视图使用AggregatingMergeTree 表引擎用于特定场景的数据查询,比 MergeTree 的性能更高,
使用示例如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
|
CREATE TABLE db_merge.t_merge_basic (
`id` String,
`value` UInt32,
`create_time` DateTime
) ENGINE = MergeTree()
partition by toYYYYMM(create_time)
ORDER BY id;
CREATE MATERIALIZED VIEW db_merge.t_merge_basic_view
ENGINE = AggregatingMergeTree()
partition by month
ORDER BY (id)
as
select
id,
toYYYYMM(create_time) as month,
sumState(value) as value
from db_merge.t_merge_basic
group by id,month;
drop VIEW db_merge.t_merge_basic_view;
insert into db_merge.t_merge_basic values
('A01',102,'2021-06-03 10:04:35'),
('A01',101,'2021-06-03 10:05:35'),
('A02',104,'2021-06-03 10:06:35'),
('A02',103,'2021-06-03 10:07:35'),
('A03',105,'2021-06-03 10:08:35'),
('A03',105,'2021-06-03 10:09:35');
select * from db_merge.t_merge_basic;
┌─id──┬─value─┬─────────create_time─┐
│ A01 │ 102 │ 2021-06-03 10:04:35 │
│ A01 │ 101 │ 2021-06-03 10:05:35 │
│ A02 │ 104 │ 2021-06-03 10:06:35 │
│ A02 │ 103 │ 2021-06-03 10:07:35 │
│ A03 │ 105 │ 2021-06-03 10:08:35 │
│ A03 │ 105 │ 2021-06-03 10:09:35 │
└─────┴───────┴─────────────────────┘
select id,month,sumMerge(value) as value from db_merge.t_merge_basic_view group by id,month;
┌─id──┬──month─┬─value─┐
│ A01 │ 202106 │ 203 │
│ A02 │ 202106 │ 207 │
│ A03 │ 202106 │ 210 │
└─────┴────────┴───────┘
|
3.4 总结
用 order by 排序键作为聚合数据的条件 key
只有在分区合并的时候才会触发合并逻辑
以分区为单位聚合数据,合并分区时,同一分区内相同排序键的数据将会被聚合计算,不同分区间的数据不会被计算
在进行数据汇总时,因为分区内的数据已经进行了 order by 排序,所以能够找到相邻具有相同聚合 key 的数据
在进行数据聚合时,同一分区内多行相同聚合 key 的数据会合并成一行,对于非主键非聚合字段,会取第一行数据的值
使用 AggregateFunction 定义聚合函数与聚合字段
AggregateFunction 类型的字段使用二进制存储,在写入数据时需要调用 对应的State函数, 而在查询时,需要调用对应的 Merge 函数。
AggregatingMergeTree 通常作为物化视图的引擎表,与 MergeTree 配合使用
4. CollapsingMergeTree
4.1 介绍
海量数据的更新与删除,通常是一个让人头疼的问题,一种最符合常规思维的逻辑是先找到要修改数据的文件,接着修改文件,删除或修改有变化的数据,然而在大数据领域,或者说对于clickhouse 这类高性能分析性数据库而言,对数据源文件的修改是一件代价非常昂贵的操作,相较于直接修改源文件,更多时候会将删除与修改操作,转换为新增操作,即以增代删。
CollapsingMergeTree 就是一种通过以增代删的思路,支持行级数据修改和删除的表引擎。
CollapsingMergeTree 通过一个标记位 sign 来标识该行记录的状态,如果 sign 为 1 表示该行数据有效,如果 sign 为 -1 表示数据需要被删除
CollapsingMergeTree 合并分区时,同一分区内sign 标记为 1 和-1 的一组数据会被抵消删除
CollapsingMergeTree 以 order by 作为后续判断数据是否重复的唯一标准。
CollapsingMergeTree 支持对一行数据进行更新与删除操作。
4.2 使用介绍
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
|
CREATE TABLE [IF NOT EXISTS] [db_name.]table_name(
name1 [type] [DEFAULT|MATERIALIZED|ALIAS expr],
name2 [type] [DEFAULT|MATERIALIZED|ALIAS expr],
...
) ENGINE = CollapsingMergeTree(sign)
[PARTITION BY expr]
[ORDER BY expr]
[PRIMARY KEY expr]
[SAMPLE BY expr]
[SETTINGS name=value, ...]
CREATE TABLE db_merge.t_merge_collapse (
`id` String,
`code` UInt32,
`create_time` DateTime,
`sign` Int8
) ENGINE = CollapsingMergeTree(sign)
partition by toYYYYMM(create_time)
ORDER BY id;
insert into db_merge.t_merge_collapse values
('A01',100,'2021-06-04 17:21:01',1),
('A02',200,'2021-06-04 17:22:01',1),
('A03',300,'2021-06-04 17:23:01',1),
('A04',400,'2021-06-04 17:24:01',1);
select * from db_merge.t_merge_collapse;
┌─id──┬─code─┬─────────create_time─┬─sign─┐
│ A01 │ 100 │ 2021-06-04 17:21:01 │ 1 │
│ A02 │ 200 │ 2021-06-04 17:22:01 │ 1 │
│ A03 │ 300 │ 2021-06-04 17:23:01 │ 1 │
│ A04 │ 400 │ 2021-06-04 17:24:01 │ 1 │
└─────┴──────┴─────────────────────┴──────┘
insert into db_merge.t_merge_collapse values
('A01',500,'2021-06-04 17:21:01',1)
insert into db_merge.t_merge_collapse values
('A02',200,'2021-06-04 17:22:01',-1);
optimize table db_merge.t_merge_collapse;
select * from db_merge.t_merge_collapse;
┌─id──┬─code─┬─────────create_time─┬─sign─┐
│ A01 │ 500 │ 2021-06-04 17:21:01 │ 1 │
│ A03 │ 300 │ 2021-06-04 17:23:01 │ 1 │
│ A04 │ 400 │ 2021-06-04 17:24:01 │ 1 │
└─────┴──────┴─────────────────────┴──────┘
|
4.3 折叠规则
CollapsingMergeTree 折叠数据时遵循下面的规则:
当 sign = 1 与 sign = -1 一样多时:
- 最后一行是 <font color='green'>sign = 1</font>:保留第一行 <font color='red'>sign = -1</font> 和最后一行 <font color='green'>sign = 1</font>
- 最后一行是 <font color='red'>sign = -1</font>:什么也不保留
当sign = 1 比 sign = -1 多一行时:
当sign = -1 比 sign = 1 多一行时:
其余情况,clickhouse 会打印警告信息,但是不会报错,查询结果未可预知。
4.4 注意事项
- 数据折叠不是事实触发,而是在分区合并时触发,在分区合并之前,还能够查询到旧数据,这种情况有两种解决办法:
- 在查询前进行强制分区合并,但这种方法效率很低,生产环境慎用。
- 改变查询方式,如下示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
select
id,sum(code),count(code),avg(code)
from db_merge.t_merge_collapse
group by id
select
id,sum(code * sign),count(code * sign),avg(code * sign)
from db_merge.t_merge_collapse
group by id
having sum(sign) > 0;
|
- 只有相同分区内的数据可以被折叠,通常来说,修改或删除的数据都处于同一分区,所以这不是很严重的问题
- CollapsingMergeTree对写入数据的顺序有着严格的要求,
- 如果按照正常顺序写入,先写入 sign = 1 再写入 sign = -1 数据能够正常折叠
- 如果将写入顺序掉转,先写入sign = -1 再写入 sign = 1 则不能够折叠
这是 因为CollapsingMergeTree 的处理机制引起的,它要求sign = 1 和 sign = -1 数据相邻,而分区内数据基于 order by 排序,要按照sign = 1 和 sign = -1 数据相邻 只能严格按照顺序写入。
如果数据时单线程写入就会很好控制写入顺序,但想处理大量数据往往是多线程写入,这时就不太好控制写入顺序了这种情况下CollapsingMergeTree的工作机制就会出现问题,还好clickhouse 提供了VersionedCollapsingMergeTree 表引擎来解决这个问题。
5. VersionedCollapsingMergeTree
5.1 介绍
- VersionedCollapsingMergeTree 表引擎的作用于CollapsingMergeTree完全相同
- VersionedCollapsingMergeTree 与CollapsingMergeTree不同之处在于其对写入顺序没有要求
- VersionedCollapsingMergeTree 通过版本号来实现这一特性
- VersionedCollapsingMergeTree 在定义版本号字段(ver)之后,会自动将 ver 作为排序条件增加到order by 末端,所以无论写入顺序如何,在折叠处理时都能回到正确的顺序。
5.2 使用示例
1
2
3
4
5
6
7
8
9
10
11
| CREATE TABLE [IF NOT EXISTS] [db_name.]table_name(
name1 [type] [DEFAULT|MATERIALIZED|ALIAS expr],
name2 [type] [DEFAULT|MATERIALIZED|ALIAS expr],
...
) ENGINE = VersionedCollapsingMergeTree(sign,ver)
[PARTITION BY expr]
[ORDER BY expr]
[PRIMARY KEY expr]
[SAMPLE BY expr]
[SETTINGS name=value, ...]
|
1
2
3
4
5
6
7
8
9
10
11
|
CREATE TABLE db_merge.t_merge_version_collapse (
`id` String,
`code` UInt32,
`create_time` DateTime,
`sign` Int8,
`ver` UInt8
) ENGINE = VersionedCollapsingMergeTree(sign,ver)
partition by toYYYYMM(create_time)
ORDER BY id;
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
insert into db_merge.t_merge_version_collapse values ('A01',100,'2021-06-04 17:21:01',-1,1);
insert into db_merge.t_merge_version_collapse values ('A01',200,'2021-06-04 17:21:01',1,1);
select * from db_merge.t_merge_version_collapse;
┌─id──┬─code─┬─────────create_time─┬─sign─┬─ver─┐
│ A01 │ 200 │ 2021-06-04 17:21:01 │ 1 │ 1 │
└─────┴──────┴─────────────────────┴──────┴─────┘
┌─id──┬─code─┬─────────create_time─┬─sign─┬─ver─┐
│ A01 │ 100 │ 2021-06-04 17:21:01 │ -1 │ 1 │
└─────┴──────┴─────────────────────┴──────┴─────┘
optimize table db_merge.t_merge_version_collapse final;
select * from db_merge.t_merge_version_collapse;
Query id: 80e69d05-b279-4f7a-9f1a-3640628fa2a8
Ok.
0 rows in set. Elapsed: 0.003 sec.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
insert into db_merge.t_merge_version_collapse values ('A01',100,'2021-06-04 17:21:01',-1,1);
insert into db_merge.t_merge_version_collapse values ('A01',200,'2021-06-04 17:21:01',1,1);
insert into db_merge.t_merge_version_collapse values ('A01',300,'2021-06-04 17:21:01',1,1);
optimize table db_merge.t_merge_version_collapse final;
select * from db_merge.t_merge_version_collapse;
┌─id──┬─code─┬─────────create_time─┬─sign─┬─ver─┐
│ A01 │ 300 │ 2021-06-04 17:21:01 │ 1 │ 1 │
└─────┴──────┴─────────────────────┴──────┴─────┘
|
6. MergeTree表引擎之间的关系
6.1 继承关系
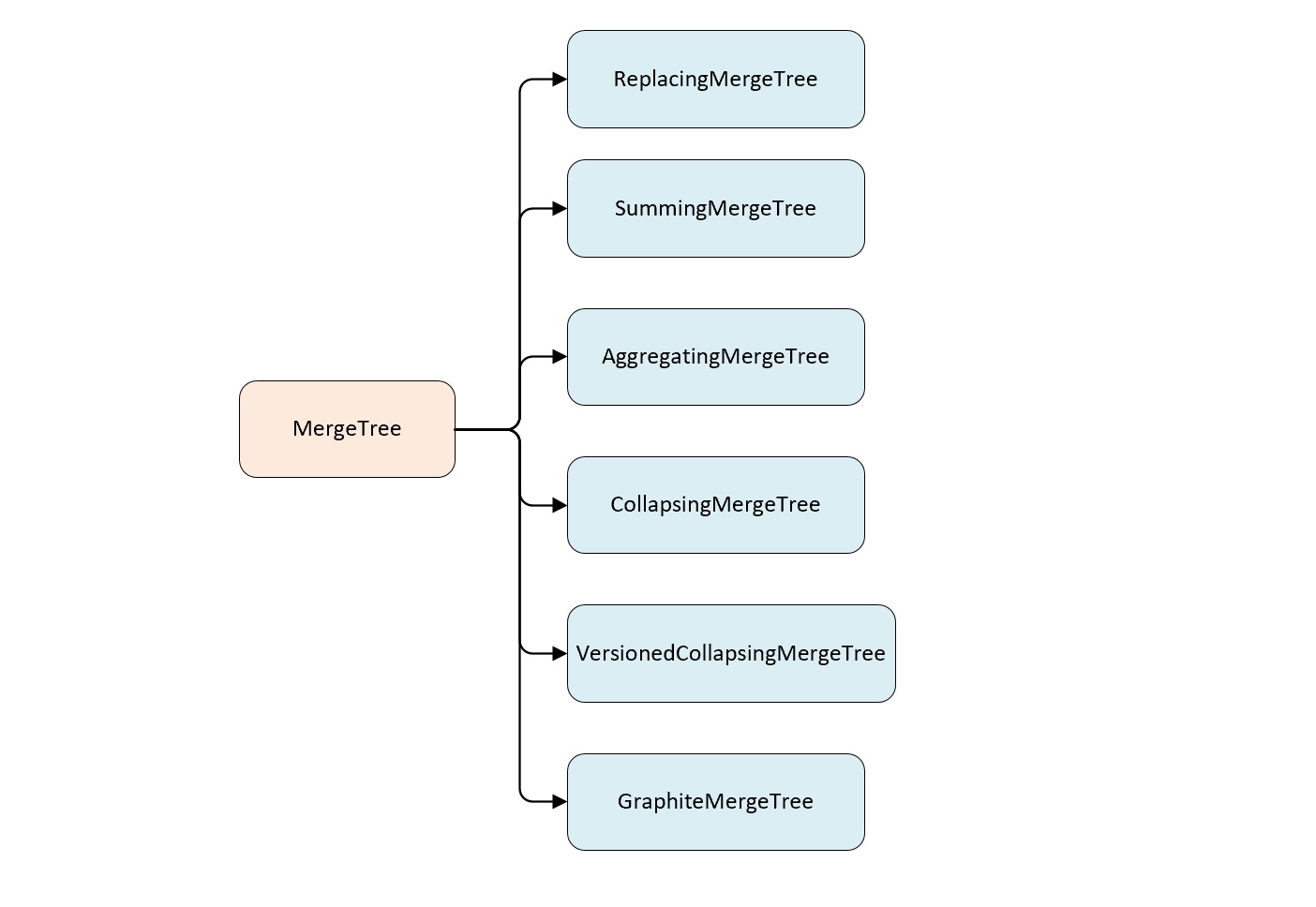
- MergeTree 表引擎下面有 6 个变种MergeTree 表引擎。
- 这 7 种表引擎主要区别在于,Merge 合并数据的逻辑上。
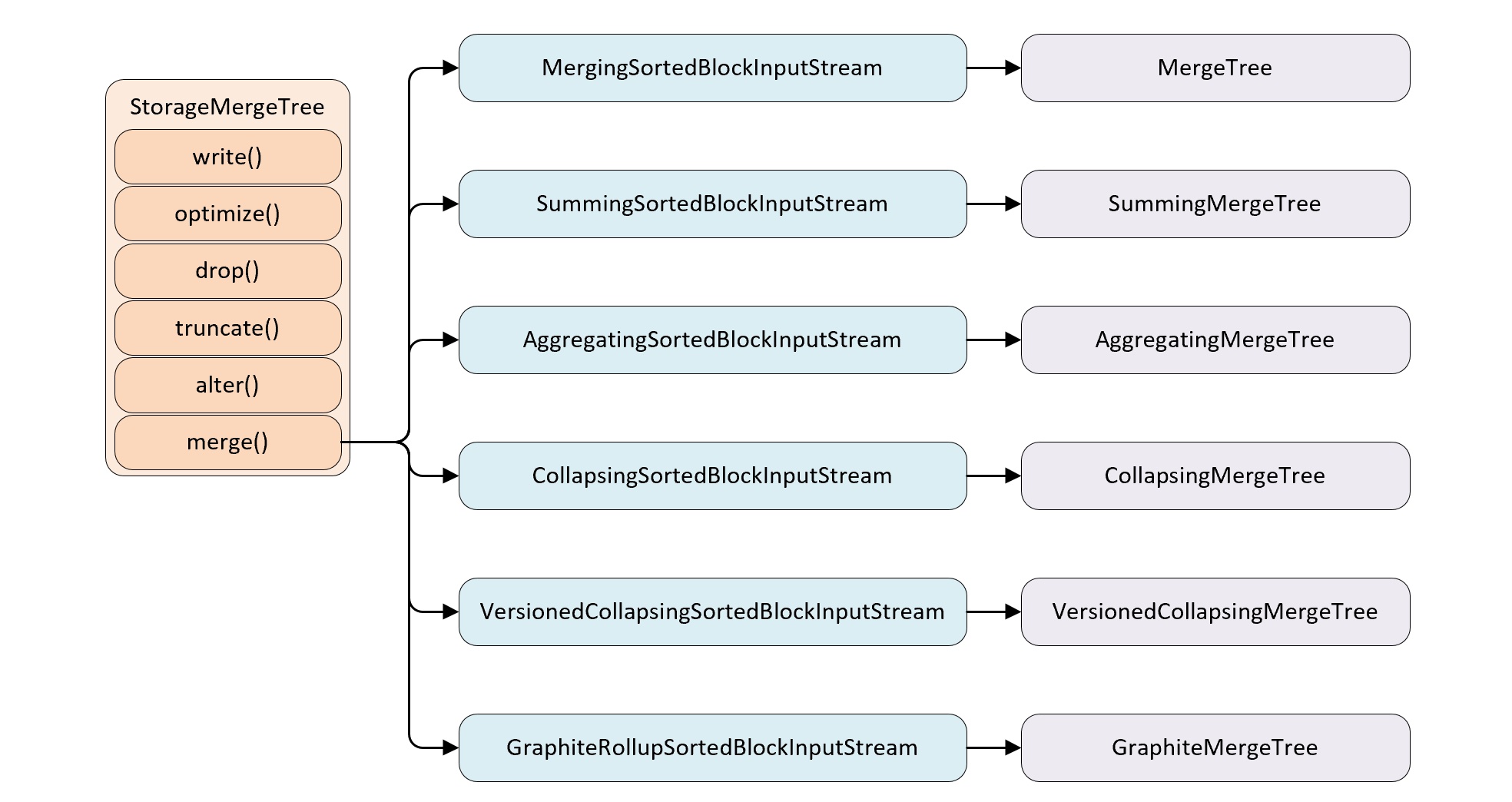
- 在具体实现逻辑部分,7 中 Merge 共用一个主体,在触发 merge动作时,它们分别实现了自己的合并逻辑。
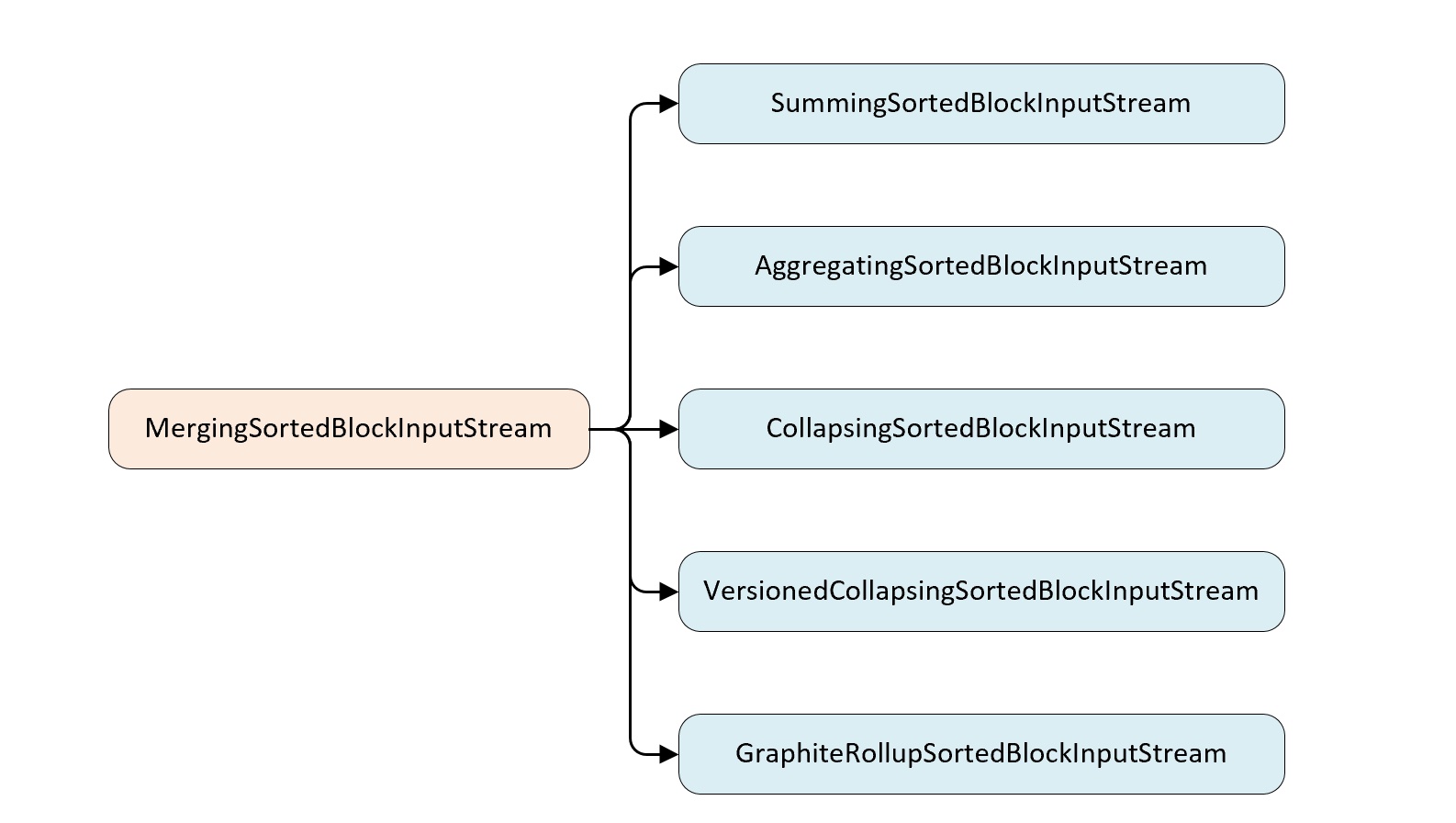
- 除了 MergeTree 之外,其它 6 个变种的 Merge 逻辑都是建立在MergeTree 之上的,并且均继承于MergingSortedBlockInputStream。
- MergingSortedBlockInputStream 的主要作用是按照order by 的规则保持新分区数据的有序性,其它 6 个变种在此基础上各有所长,或去除重复数据或进行汇总操作。
- 从继承角度看7 中 MergeTree 主要区别在于Merge 逻辑部分,所以特殊逻辑之后再 Merge 合并时触发。
6.2 组成关系
ReplicatedMergeTree 跟普通的 MergeTree 有什么关系呢?
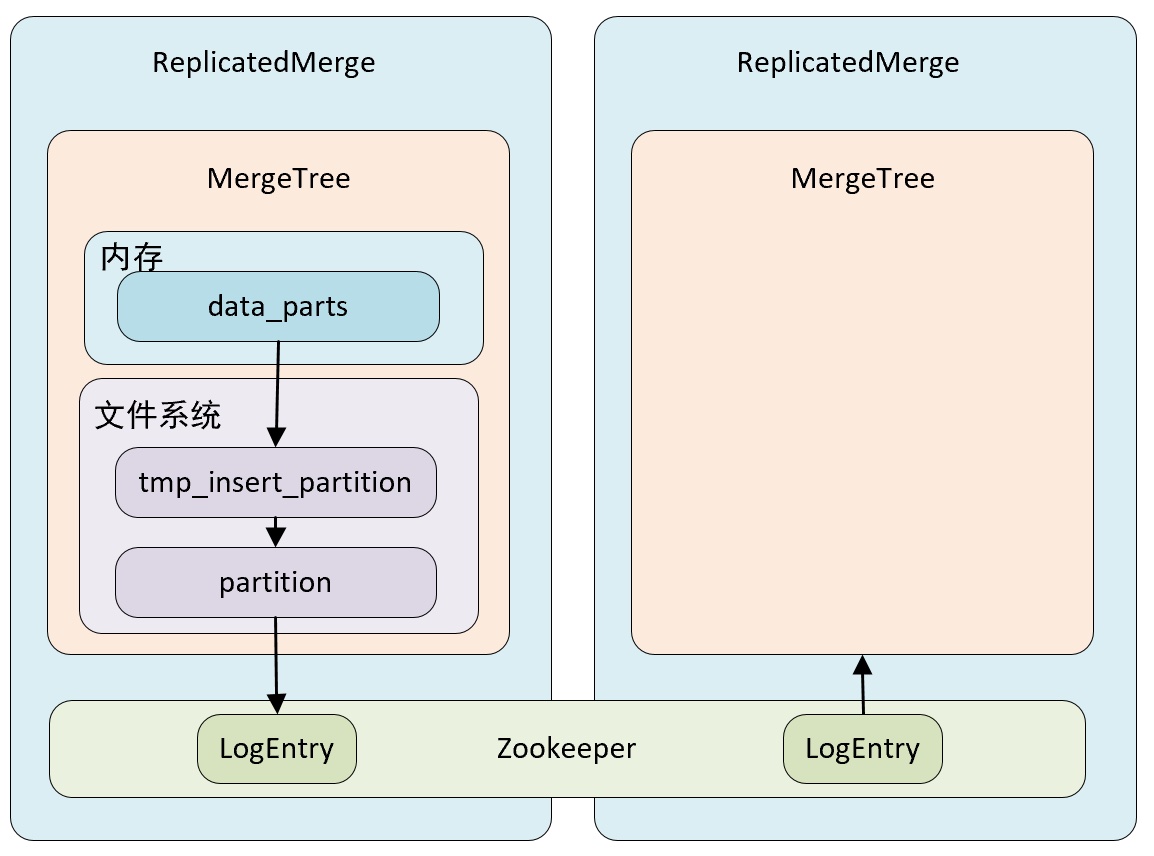
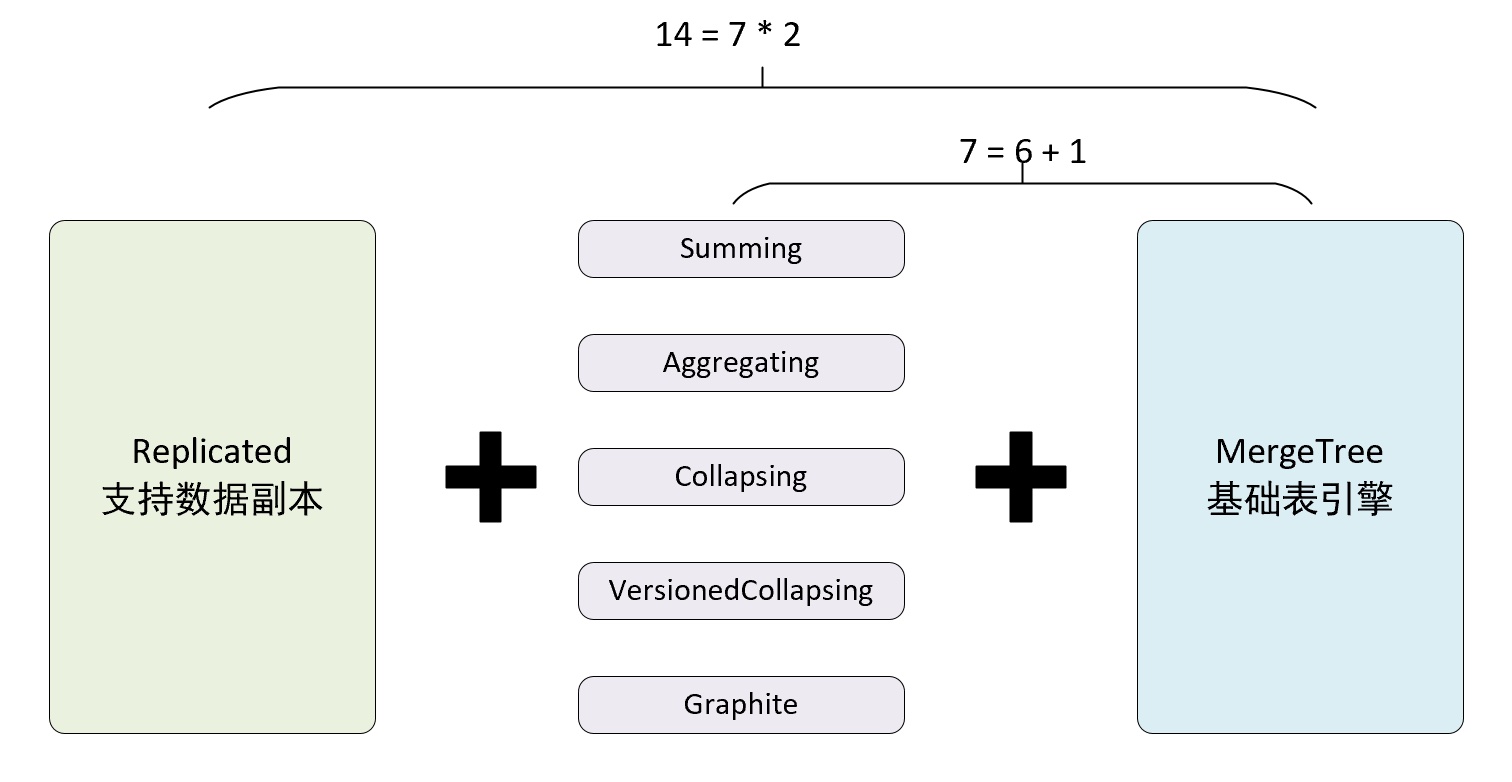
- ReplicatedMergeTree 在 MergeTree 的基础上增加了分布式协调处理的能力,借助 Zookeeper 的消息广播功能,实现了副本之间的数据同步。
- ReplicatedMergeTree 系列可以用组合关系来理解
- 7 种 MergeTree 引擎前面加上 Replicated 又能组合出 7 种新的引擎,这些引擎拥有副本协同能力