1. 数据说明
- Orders表:
| OrderID | CustomerID | ItemID | Quantity | Date |
|---|---|---|---|---|
| 1630781 | C004 | I001 | 650 | 09-01-2013 |
| 1630782 | C003 | I006 | 2500 | 09-02-2013 |
| 1630783 | C002 | I002 | 340 | 09-03-2013 |
| 1630784 | C004 | I006 | 1260 | 09-04-2013 |
| 1630785 | C005 | I003 | 1500 | 09-05-2013 |
数据保存到 Orders.csv,内容格式为:
1 | 1630781,C004,I001,650,09-01-2013 |
- Customers表:
| CustomerID | CustomerName | Country |
|---|---|---|
| C001 | Telefunken | Germany |
| C002 | Logica | Belgium |
| C003 | Salora Oy | Finland |
| C004 | Alps Nordic AB | Sweden |
| C005 | Deister Electronics | Germany |
| C006 | Thales Nederland | Netherlands |
数据保存到 Customers.csv,内容格式为:
1 | C001,Telefunken,Germany |
- Items表:
| ItemID | ItemName | Price |
|---|---|---|
| I001 | BX016 | 15.96 |
| I002 | MU947 | 20.35 |
| I003 | MU3508 | 9.6 |
| I004 | XC7732 | 55.24 |
| I005 | XT0019 | 12.65 |
| I006 | XT2217 | 12.35 |
数据保存到 Items.csv,内容格式为:
1 | I001,BX016,15.96 |
2. 创建表
Orders.sql 文件内容为:
1 | create table IF NOT EXISTS Orders ( |
Customers.sql 文件内容为:
1 | create table IF NOT EXISTS Customers ( |
Items.sql 文件内容为:
1 | create table IF NOT EXISTS Items ( |
- 我们将上面的数据导入到创建的表中:
1 | bin/psql.py slave1,slave2,slave3:2181 Orders.sql Orders.csv |
3. 执行Join
1 | SELECT O.OrderID,C.CustomerName,C.Country, O.Date |
执行过程以及结果如下:
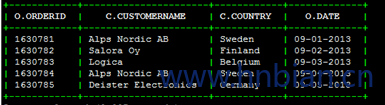
基于索引的 Join 操作
当执行 join 查询操作时,二级索引能够自动地被利用。如果我们在 Orders 和 Items 上分别创建索引,如下:
1 | CREATE INDEX iOrders ON Orders (ItemID) INCLUDE (CustomerID, Quantity); |
如果你创建可变的二级索引,出现如下的错误:
1 | Error: ERROR 1029 (42Y88): Mutable secondary indexes must have the hbase.regionserver.wal.codec property set to org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec in thehbase-sites.xml of every region server. tableName=IORDERS(state=42Y88,code=1029) |
那么需要在 RegionServe r每个节点的 hbase-site.xml 中配置参数:
1 | <property> |
然后重启 HBase 集群。
执行查询:
1 | SELECT ItemName,sum(Price * Quantity) AS OrderValue |
查询结果为:
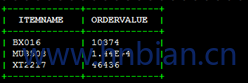
通过 explain 查询执行计划:
1 | explain SELECT ItemName,sum(Price * Quantity) AS OrderValue |

在这个案例中,可以看到索引 iItems 和索引 i2Orders 都有使用。
GroupedJoins and Derived Tables
Phoenix 也支持复杂的 Join 语法,比如 grouped joins(或子查询),以及 derived-tables(派生表)的join操作。
对于 grouped joins来说,如下:
1 | SELECT O.OrderID,C.CustomerID, I.ItemID |
通过使用一个子查询(derived table)替换 sub join,得到相等的查询:
1 | SELECT |
上面两个查询结果都为:

- Hash Join vs. Sort-Merge Join
基本的 Hash Join 通常比其他类型的 join 算法更好,但是它也有一些限制,其中最典型的一个特性是关系中的一张表要小到能够加载到内存中。Phoenix 同时支持 Hash Join 和 Sort-Merge Join 去实现快速的 join 操作以及两张大表之间的 join 操作。
Phoenix 目前尽可能地使用 Hash Join 算法,因为通常更快。但是我们可以使用 USE_SORT_MERGE_JOIN 的 hint 在查询中使用 Sort-Merge Join。对于这两种 join 的算法的选择将来会根据表的统计信息自动选择。
- Foreign Key to Primary Key Join Optimization
通常情况下,一个 join 发生在一个 child 表到一个 parent 表,通过 child 表的外键映射到一个 parent 表的主键。因此代替对 parent 表的全表扫描,Phoenix 将基于 child 表的外键值对 parent 表进行 skip-scan 或 range-scan 扫描。
下面我们举个例子,parent 表为 Employee,child 表为 Patent。
1 | CREATE TABLE Employee ( |
1 | CREATE TABLE Patent ( |
1 | SELECT E.Name, E.Region, P.PCount |
上面的查询语句通过Region和LocalID两个join的key对表“Employee”使用skip-scan扫描。下面是查询使用和不使用这个优化的执行时间(“Employee”大概5000000 行,“Patent”大约1000 行记录):
| W/O(没有) Optimization | W/(有) Optimization |
|---|---|
| 8.1s | 0.4s |
然而,当考虑到child外键的值完全在parent表的主键空间中,因此使用skip-scan只会慢不会快的。你可以总是通过指定“NO_CHILD_PARENT_OPTIMIZATION”的hint关闭这个优化。将来,通过表的统计信息智能地选择这两种模式。
4. 配置
前面我们提到,使用Hash Join时,前提条件是将关联中的一张表加载到内存中,以便广播到所有的服务器,因此需要考虑RegionServer服务器的堆内存足够大以便容纳较小的表,我们也需要关注一下使用Hash Join的几个关键性的配置参数。
服务器端缓存用于存放哈希表,缓存的大小和生存时间由下面的几个参数控制。
- phoenix.query.maxServerCacheBytes
一个relation在被压缩和发送到RegionServer前的最大原始数据大小(bytes)。
如果尝试去序列化一个relation原始数据大小超过这个值的话,会导致MaxServerCacheSizeExceededException错误。
默认值为:104857600
- phoenix.query.maxGlobalMemoryPercentage
所有threads使用的堆内存百分比(Runtime.getRuntime().maxMemory())。
默认值为:15
- phoenix.coprocessor.maxServerCacheTimeToLiveMs
服务器端缓存的最大生存时间。
当在服务器端出现IO异常(“Could not find hash cache for joinId”),就考虑调整这个参数了。
如果获取到“Earlier hash cache(s) might have expired on servers”告警日志时,可以提升这个参数的值。
默认值为:30000(30s)
尽管有时可以通过修改参数来解决上面提到的一些异常问题,但是强烈建议首先要考虑优化join的查询,大家可以学习下面的优化部分内容。
5. 查询优化
下面是默认 join 的顺序(没有表统计信息的存在),查询的一边作为“smaller”relation并且将被加载到服务器的内存中:
lhs INNER JOIN rhs:rhs将在服务器的内存中建立hash表
lhs LEFT OUTER JOIN rhs:rhs将在服务器的内存中建立hash表
lhs RIGHT OUTER JOIN rhs:lhs将在服务器的内存中建立hash表
对于多个join查询来说,join 的顺序是比较复杂的,你可以使用 explain 来查询真正的执行计划。对于 multiple-inner-join 查询来说,Phoenix 默认应用 star-join 优化,意味着 join 所有右手边的表的同时,leading 的表(即左手边的表)将仅仅被扫描一次。当所有右手边的表的大小超过内存限制时,你可以通过使用 NO_STAR_JOIN 的hint来关闭这个优化。
下面我们来看一下之前的查询示例:
1 | explain SELECT O.OrderID, C.CustomerName, I.ItemName, I.Price,O.Quantity |
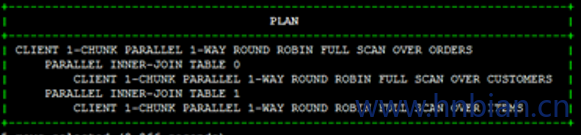
默认的 Join 顺序为(使用 star-join 优化):
- SCAN Customers –> BUILD HASH[0]
SCAN Items –> BUILD HASH[1]
- SCAN Orders JOIN HASH[0], HASH[1] –> Final Resultset
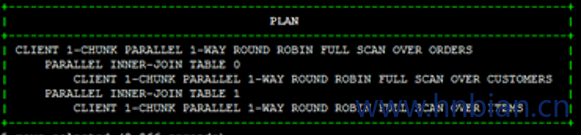
另外,如果我们使用 NO_STAR_JOIN 的 hint,如下:
1 | SELECT /*+ NO_STAR_JOIN*/ O.OrderID, C.CustomerName, I.ItemName, I.Price, O.Quantity |
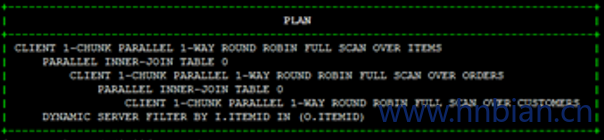
这次的 Join 顺序为:
SCAN Customers –> BUILD HASH[0]
SCAN Orders JOIN HASH[0]; CLOSE HASH[0] –> BUILD HASH[1]
SCAN Items JOIN HASH[1] –> Final Resultset
这里需要说明的是,并不是表的整个数据集都计算到内存占用的,而是只有查询使用的列数据并且过滤后的记录才会在服务器端建立Hash表。

