1. Broker
1.1 Broker 介绍
Broker 没有副本机制,一旦 Broker 宕机,该 Broker 的消息都将不可用。
Broker 不会保存 Consumer 消费 topic partition offset 的状态,订阅者自己采用不同模式保存。
无状态导致消息的删除成为难题(有可能会删除正在被消费的消息),kafka采用基于事件的 SLA(服务水平保证),消息保存一定时间(默认7天,168小时)会被自动删除
消费者可以将 offset 重新定位到任意位置进行重新消费,当 Consumer 故障时,可以选择最小的 offset 进行重新读取消费数据。
1.2 Broker 的启动过程
- Broker 启动后先根据其 ID 在 Zookeeper 的 / Broker s/ids/idsznode 下面创建临时子节点,
- 创建成功后 Controller 的 ReplicaStateMachine 注册其上的 Broker Change Watch 会被触发,从而通过回调 KafkaController.on Broker Startup 方法,
- 回调方法向所有新启动的 Broker 发送 UpdateMetadataRequest。
- 将新启动的 Broker 上的所有副本设置为 OnlineReplica 状态,同时这些 Broker 会为这些 Partition 启动 high watermark 线程。
- 通过 partitionStateMachine 触发 OnlinePartitionStateChange。
1.3 Kafka Controller(控制器)
Kafka 集群中会有一个或者多个 Broker ,有一个 Broke r会被选举为控制器(Kafka Controller),它负责整个集群中所有分区和副本的状态。
- 选择 Partition Leader:当某个分区副本出现故障时,由 Kafka Controller 负责为该分区选举新的 leader 副本。
- 更新元数据:从 Zookeeper 中获取当前所有 topic、partition 以及 Broker 相关信息进行相应的管理。
- 增/减/分配分区:当使用 kafka-topics.sh 脚本为某个 topic 增加分区数量时,同样还是由 Kafka Controller 负责新增分区的分配。
1.3.1 Controller 选举与具体功能
每个 Broker 在启动的时候都会去尝试读取 /controller 节点的 Brokerid 的值,
- 如果ZK中不存在 /controller 节点,或者这个节点值为-1,那么会尝试去创建 /controller 节点,在去创建 /controller 节点的时候,也有可能其他的 Broker 同时尝试创建这个节点,只有创建成功的 Broker 会成为控制器,创建失败的则意味着竞选失败会在 /controller 上注册一个Watch。
- 如果读取到 Brokerid 的值不为-1,则表示已经有其他 Broker 节点成功竞选为控制器,则该 Broker 就会放弃竞选,并且会在 /controller 上注册一个Watch。
- 当 Controller 挂掉时临时节点会自动消失,这时 Watch 会被触发,此时所有 active 的 Broker 都会去竞选成为新的 Controller。
/controller 临时节点值如下:
[zk: localhost:2181(CONNECTED) 2] get /controller
{"version":1," Brokerid":0,"timestamp":"1581320839809"}
# version:目前版本中固定为1
# Brokerid:表示控制器的 Broker 的id编号
#timestamp:表示竞选成为控制器的时间戳每个 Broker 都会在内存中保存当前控制器的 Brokerid 的值,这个值标识位 activeControllerId。当 /controller 节点的数据发生变化时,每个 Broker 都会更新自身内存中保存的 activeControllerId。
- 如果 Broker 在数据变更前是控制器,那么如果在数据变更后自身的 Brokerid值与新的activeControllerId值不一致的话,那么就需要“退位”,关闭相应的资源,比如关闭状态机、注销相应的监听器等。有可能控制器由于异常而下线,造成 /controller 这个临时节点会被自动删除;也有可能是其他原因将此节点删除了。
当 /controller 节点被删除时,每个 Broker 都会进行选举,
- 如果 Broker 在节点被删除前是控制器的话,在选举前还需要有一个“退位”的动作。
- 如果有特殊需要,可以手动删除 /controller 节点来触发新一轮的选举。当然关闭控制器所对应的 Broker 以及手动向 /controller 节点写入新的 Brokerid的所对应的数据同样可以触发新一轮的选举。
Zookeeper中还有一个与控制器有关的节点: /controller_epoch节点,这个节点是一个持久化节点(Persistent),它保存的是一个整型的controller_epoch值。这个值用于记录控制器发生变更的次数。即记录当前的控制器是第几代控制器,当控制器发生变更时,每选出一个新的控制器都会在该值的基础上 +1 ,每个和控制器交互的请求都会携带上controller_epoch的值。
[zk: localhost:2181(CONNECTED) 4] get /controller_epoch
3- 如果请求的 controller_epoch 值小于内存中 controller_epoch 的值,则认为这个请求是向已经过期的控制器发送的请求,那么这个请求会被认定为无效请求。
- 如果请求的 controller_epoch 值大于内存中 controller_epoch 的值,则说明已经有新的控制器当选了。
由此可见,kafka通过controller_epoch 来保证控制器的唯一性,进而保证相关操作的一致性。
1.3.2 Controller 选举成功后的操作
Broker 成功竞选为Controller后会触发KafkaController.onControllerFailover 方法,并在该方法中完成如下操作:
- 读取并在 /controller_epoch 的值基础上+1。
- 增加一系列监听用于处理集群环境的变化,具体有哪些监听可以查看 Controller 事件监听章节。
- 初始化 Controller 对象,设置当前所有 Topic、 Broker 列表、Partition的Leader 以及 ISR 等
- 启动 replicaStateMachine 和 partitionStateMachine
- 将 Broker State 状态设置为 partitionStateMachine
- 将每个Partition的Leadership 发送给所有active 的 Broker
- 若 auto.leader.rebalance.enable 设置为 true,则还会开启一个名为”auto-leader-rebalance-task”的定时任务来负责维护分区的有限副本的均衡。
- 如果 delete.topic.enable 值为 true,且 /admin/delete_topics 中有值,则删除对应的 topic
1.3.2 Controller 事件监听
在Kafka的早期版本中,并没有采用Kafka Controller这样一个概念来对分区和副本的状态进行管理,而是依赖于Zookeeper,每个 Broker 都会在Zookeeper上为分区和副本注册大量的监听器(Watcher)。当分区或者副本状态变化时,会唤醒很多不必要的监听器,这种严重依赖于Zookeeper的设计会有脑裂、羊群效应以及造成Zookeeper过载的隐患。
在目前的新版本的设计中,只有Kafka Controller在Zookeeper上注册相应的监听器,其他的 Broker 极少需要再监听Zookeeper中的数据变化,这样省去了很多不必要的麻烦。不过每个 Broker 还是会对 /controller 节点添加监听器的,以此来监听此节点的数据变化(参考ZkClient中的IZkDataListener)。
控制器在选举成功之后会读取Zookeeper中各个节点的数据来初始化上下文信息(ControllerContext),并且也需要管理这些上下文信息,比如为某个topic增加了若干个分区,控制器在负责创建这些分区的同时也要更新上下文信息,并且也需要将这些变更信息同步到其他普通的 Broker 节点中。
不管是监听器触发的事件,还是定时任务触发的事件,亦或者是其他事件(比如 ControlledShutdown )都会读取或者更新控制器中的上下文信息,那么这样就会涉及到多线程间的同步,如果单纯的使用锁机制来实现,那么整体的性能也会大打折扣。针对这一现象,Kafka的控制器使用单线程基于事件队列的模型,将每个事件都做一层封装,然后按照事件发生的先后顺序暂存到LinkedBlockingQueue中,然后使用一个专用的线程(ControllerEventThread)按照FIFO(First Input First Output, 先入先出)的原则顺序处理各个事件,这样可以不需要锁机制就可以在多线程间维护线程安全。
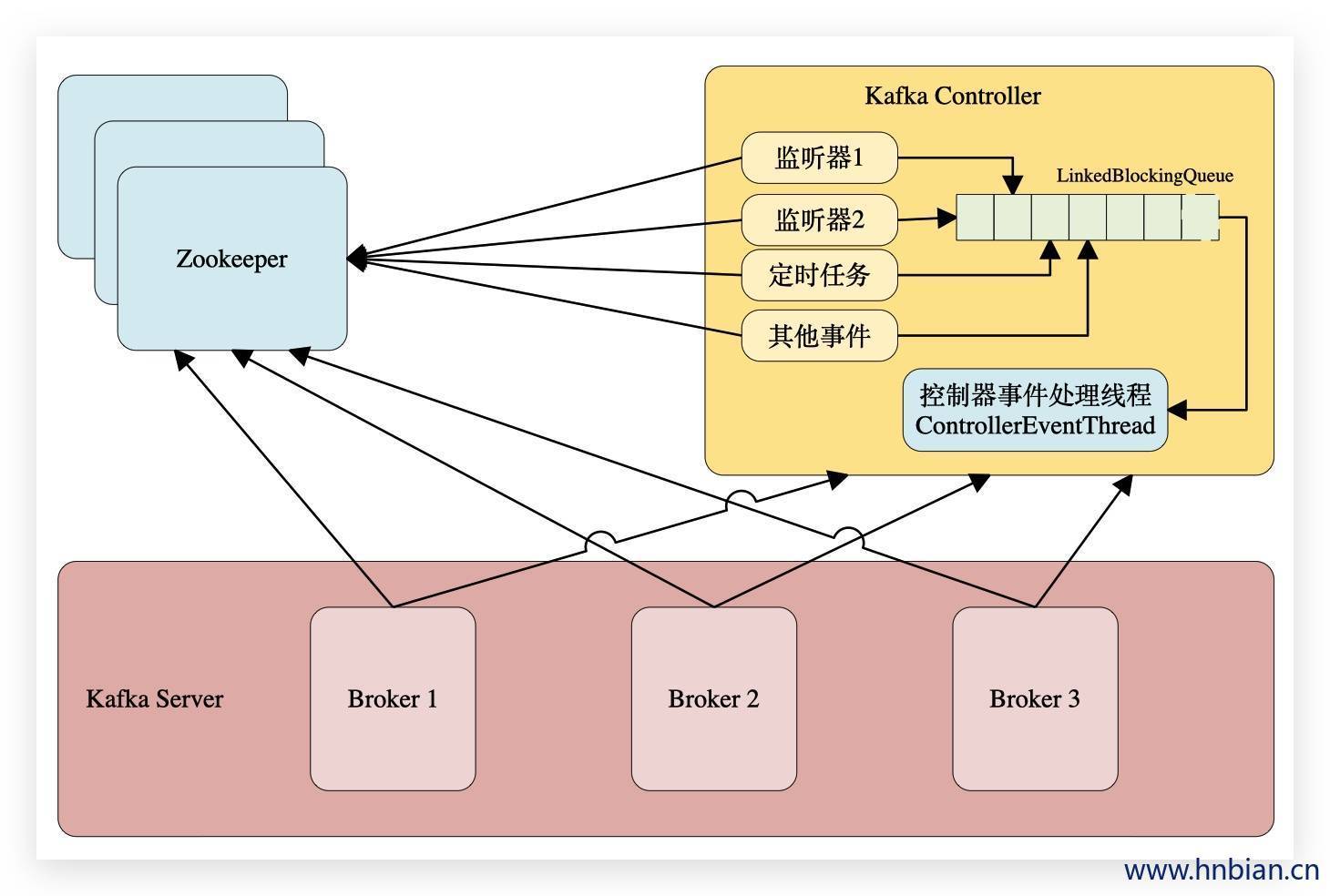
- 监听partition的变化
| 功能 | 添加监听的zk节点 | 添加的Listener |
|---|---|---|
| 处理分区重分配 | /admin/reassign_partitions | PartitionReassignmentListener |
| 处理优先副本选举 | /admin/preferred_replica_election | PreferredReplicaElectionListener |
| 处理ISR集合变更 | /isr_change_notification | IsrChangeNotificationListener |
- 监听topic相关变化
| 功能 | 添加监听的zk节点 | 添加的Listener |
|---|---|---|
| 处理topic增减的变化 | / Broker s/topics | TopicChangeListener |
| 处理删除topic动作 | /admin/delete_topics | TopicDeletionListener |
| 处理topic分区变化 | / Broker s/topics/[topic] | PartitionModificationsListener |
- 监听 Broker 相关的变化
| 功能 | 添加监听的zk节点 | 添加的Listener |
|---|---|---|
| 处理 Broker 增减变化 | / Broker s/ids | Broker ChangeListener |
1.3.4 Controller 对 Broker 的故障处理
Controller 在 Zookeeper 的 /Brokers/ids 节点上注册 Watch 用来处理 Broker 增减变化,一旦有 Broker 宕机对应的Zookeeper上的节点会自动删除,就会触发 Controller 的 Watch,Controller 即会获取最新的active的 Broker 列表。
Controller 决定 Set_p,该集合包含了宕机的 Broker 上的所有Partition副本分布。
对于 Set_p 中的每个Partition会做如下操作:
- 从 / Broker s/topics/topic-name/partitions/partition-id/state 读取该 partition 的 ISR。(ISR是什么会在下一个章节中介绍)
- 决定该partition的新leader,
- 如果当前ISR中至少有一个副本还处于active状态,则选择其中一个为新的Leader,新的ISR中包含当前ISR中所有幸存的副本
- 如果当前ISR中没有副本存活,则选择该partition任意一个存活的副本作为新的Leader以及ISR(这种场景会存在数据丢失的风险)
- 如果该partition所有的副本都宕机了,则将新的leader设置为-1
- 将新的Leader、新的leader_epochISR以及controller_epoch 写入/ Broker s/topics/topic-name/partitions/partition-id/state。
- 直接通过RPC向Set_p 相关的 Broker 发送LeaderAndISRRequest命令,Controller可以在一个RPC操作中发送多个命令从而提高效率。
1.3.5 LeaderAndISRRequest的响应过程
Broker 收到 LeaderAndISRRequest 主要通过ReplicaManager 的 becomeLeaderOrFollower 处理:
若请求中controller_epoch 值小于最新的 controller_epoch 的值,则认为这个请求是向已经过期的控制器发送的请求,那么这个请求会被认定为无效请求,直接返回ErrorMapping.StaleControllerEpochCode
对于请求中 partitionStateInfos 中的每一个元素,即((topic, partitionId), partitionStateInfo):
- 若 partitionStateInfo 中的 leader epoch 大于当前 ReplicManager 中存储的 (topic, partitionId) 对应的 partition 的 leader epoch,则:
- 若当前 Brokerid(或者说 replica id)在 partitionStateInfo 中,则将该 partition 及 partitionStateInfo 存入一个名为 partitionState 的 HashMap 中
- 否则说明该 Broker 不在该 Partition 分配的 Replica list 中,将该信息记录于 log 中
- 否则将相应的 Error code(ErrorMapping.StaleLeaderEpochCode)存入 Response 中
筛选出 partitionState 中 Leader 与当前 Brokerid 相等的所有记录保存到 partitionsTobeLeader 中,其它记录存入 partitionsToBeFollower 中
若 partitionsTobeLeader 不为空,则对其执行 makeLeaders 方
若 partitionsToBeFollower 不为空,则对其执行 makeFollowers 方法
若 highwatermak 线程还未启动,则将其启动,并将 hwThreadInitialized 设为 true
关闭所有 Idle 状态的 Fetcher
1.4 Broker 响应请求的流程
Broker 通过 kafka.network.SocketServer 及其相关模块接受各种请求并作出相应,整个网络通信模块基于Java NIO 开发,并采用 Reactor模式,其中包括1个Acceptor负责接受客户请求,N个Processor负责读写数据,M个Handle 处理业务逻辑。
- Acceptor:主要负责监听并接受客户端发送的请求,包括Producer、 Consumer 、Controller、Admin Tool 等的请求,并建立和客户端的数据传输通道,然后为该客户端指定一个 Processor,至此它对该客户端的该次请求的任务就结束了,可以去响应下一个客户端的连接请求了。
- Processor:主要负责从客户端读取数据并将响应返回给客户端,它本身并不处理具体的业务逻辑,并且其内部维护了一个队列来保存分配给它的所有 SocketChannel。Processor 会循环调用run方法从队列中取出新的SocketChannel,并将其SelectionKey.OP_READ 注册到selector 上,然后循环处理已就绪的读(请求)和写(响应)。Processor读完数据之后,将其封装成 Request对象,并将其交给RequestChannel。
- RequestChannel是Processor 和KafkaRequestHandler 交换数据的地方,它包含一个队列,requestQueue用来存放Processor 加入 Request 。
- Processor 会通过prosessNewReponses 方法依次将 requestChannel 中的ResponseQueue保存的Response取出,将其对应的SelectionKey.OP_WRITE事件注册到selector 上。当selector的select 方法返回时,对检测到的可写通道,调用write方法,将Response返回给客户端。
- Handler:KafkaRequestHandler 循环送 RequestChannel 中读取Request 并交给kafka.server.kafkaAPIs 处理具体业务逻辑。同时 这个Request还包含一个respondQueue,用来存放KafkaRequestHandler处理完Request后返还给客户端的Response.
2. Producer(生产者)
Producer:从外部系统获取数据发送给 Broker ,Producer直接发送数据到 Broker 上的 leader partition,不需要经过任何中介或其他路由。为了实现这个特性,kafka集群中每个 Broker 都可以响应producer的请求,并返回topic的一些元信息,这些原信息包括哪些机器是存活的,topic的leader partition都在哪,现阶段哪些 leader partition是可以直接被访问的。
不同的应用场景对消息有不同的需求,即是否允许消息丢失、重复、延迟以及吞吐量的要求。不同场景对Kafka生产者的API使用和配置会有直接的影响。
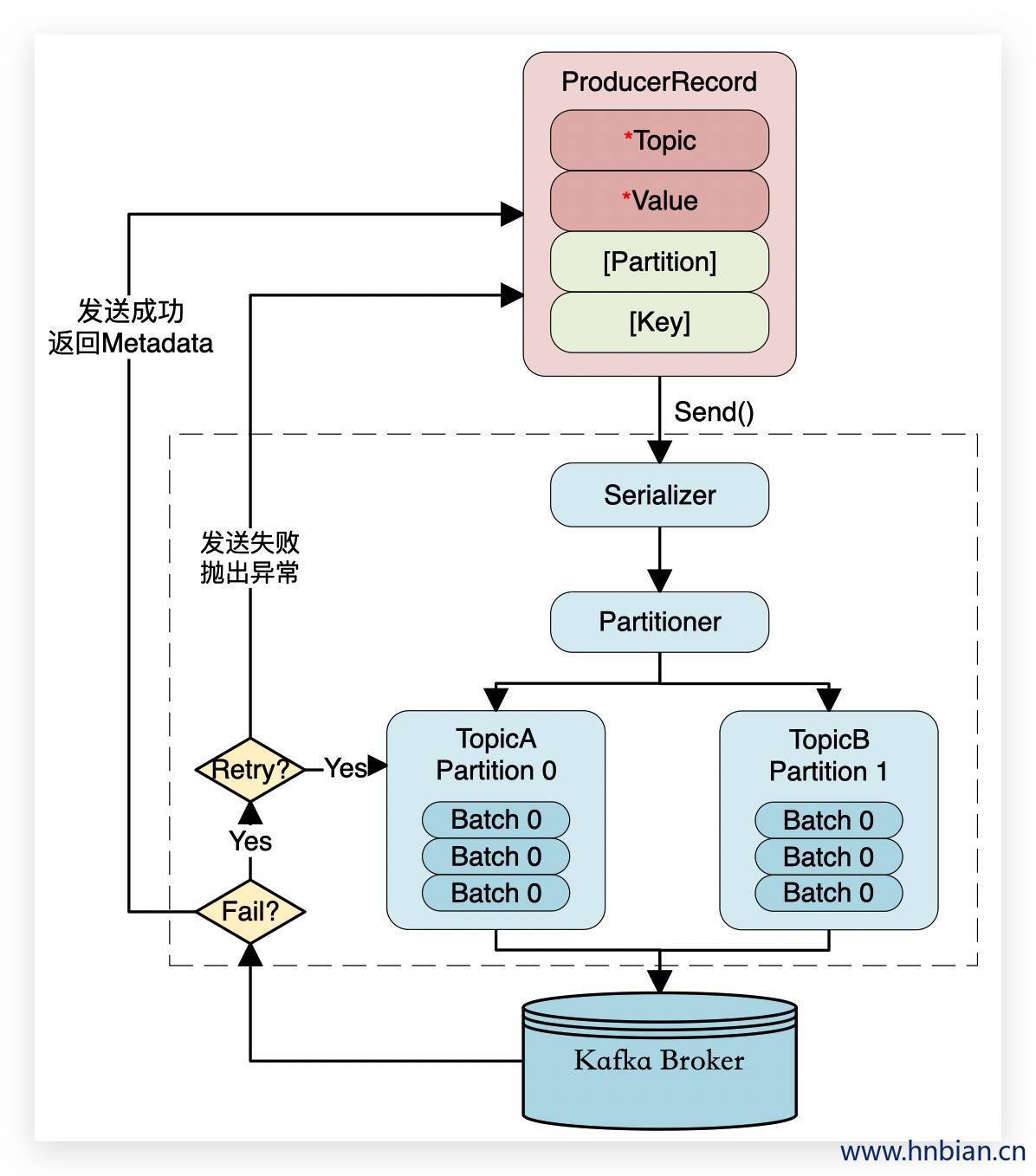
2.1 Producer发送消息的流程
消息格式:每个消息是一个ProducerRecord对象,必须的属性有Topic和消息Value值,此外还可以包含消息的Partition以及消息的Key。
序列化ProducerRecord有多个构造器,这里使用了三个参数的,topic、key、value
如果ProducerRecord中指定了Partition,则Partitioner不做任何事情;否则,Partitioner根据消息的key得到一个Partition。这时生产者就知道向哪个Topic下的哪个Partition发送这条消息。
消息被添加到相应的batch中,独立的线程将这些batch发送到 Broker 上
Broker 收到消息会返回一个响应。如果消息成功写入Kafka,则返回RecordMetaData对象,该对象包含了Topic信息、Patition信息、消息在Partition中的Offset信息;若失败,返回一个错误
2.2 自定义partitioner
Producer 客户端自己控制着消息数据被推送到哪个partition。发送的方式可以是随机分配或者是某类随机负载均衡或者指定一些分区算法。
kafka提供了接口供用户自己实现自定义partition。用户可以为每个消息指定一个partitionKey,在某些hash算法中通过key将数据分发到不同的partition,比如把userID作为partitionKey的话,相同的userID将会被推送到同一个partition中。
使用自定义partitioner 需要在producer端加入配置
//producer需要配置
properties.put("partitioner.class", PartitionerCLass.class.getName());
- 轮询Partitioner
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import org.apache.kafka.common.PartitionInfo;
import java.util.List;
import java.util.Map;
import java.util.concurrent.atomic.AtomicLong;
/**
* @Author haonan.bian
* @Description Round Robin Partitioner
* 不管key是什么样子 如果第一条消息发送0partition 第二条消息发送到1partition...
* 不需要根据key去做定向的分发
* @Date 2020-02-13 22:31
**/
public class RoundRobinPartitioner implements Partitioner {
//首先定义一个全局计数器
private static AtomicLong next = new AtomicLong();
/**
* 重写 partition方法
* @param topic 发送到哪个topic
* @param key key 值
* @param keyBytes key字节数组
* @param value 发送消息内容
* @param valueBytes 发送消息内容字节数组
* @param cluster
* @return 返回值是int 返回消息应该发送到哪个partition
*/
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
//线程安全的 +1 去除
long nextIndex = next.incrementAndGet();
//对partition取余数
return (int) nextIndex % numPartitions;
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> map) {
}
}- Hash Partitioner
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import org.apache.kafka.common.PartitionInfo;
import org.apache.kafka.common.record.InvalidRecordException;
import java.util.List;
import java.util.Map;
/**
* @Author haonan.bian
* @Description Hash Partitioner
* 实现partition接口 重写 partition方法
* 一般取key的 在不考虑备份的情况下一个partition只会在一个 Broker 上面
* hash partition 一般取key的hash值 对 partition的总数取余数,这样相同的key会发送到一个partition中 比如相同的用户信息发送到一个partition上面
* @Date 2020-02-13 22:19
**/
public class HashPartitioner implements Partitioner {
/**
* 重写 partition方法
* @param topic 发送到哪个topic
* @param key key 值
* @param keyBytes key字节数组
* @param value 发送消息内容
* @param valueBytes 发送消息内容字节数组
* @param cluster
* @return 返回值是int 返回消息应该发送到哪个partition
*/
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
if(keyBytes == null) {
throw new InvalidRecordException("key cannot be null");
}
//对数值型的key直接取余数
if ((key instanceof Integer)) {
return Math.abs(Integer.parseInt(key.toString())) % numPartitions;
}
return Math.abs(key.hashCode() % numPartitions);
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> map) {
}
}- 随机Partitioner
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import org.apache.kafka.common.PartitionInfo;
import org.apache.kafka.common.record.InvalidRecordException;
import java.util.List;
import java.util.Map;
import java.util.Random;
/**
* @Author haonan.bian
* @Description 将数据随机发送到某个partition
* @Date 2020-02-13 21:58
**/
public class RandomPartitioner implements Partitioner {
/**
* 重写 partition方法
* @param topic 发送到哪个topic
* @param key key 值
* @param keyBytes key字节数组
* @param value 发送消息内容
* @param valueBytes 发送消息内容字节数组
* @param cluster
* @return 返回值是int 返回消息应该发送到哪个partition
*/
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
if(keyBytes == null) {
throw new InvalidRecordException("key cannot be null");
}
Random rand = new Random();
int i = rand.nextInt(numPartitions); //生成0-3以内的随机数
//i = (int) (Math.random() * 3); //0-3以内的随机数,用Matn.random()方式
System.out.println("发送到partition : "+i);
return i;
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> map) {
}
}
2.3 消息投递顺序
Kafka保证分区的顺序,也就是说,如果生产者以一定的顺序发送消息到Kafka的某个分区,那么Kafka在分区内部保持此顺序,而且消费者也按照同样的顺序消费。但是,应用调用send方法的顺序和实际发送消息的顺序不一定是一致的。
举个例子,如果retries参数不为0,而 max.in.flight.requests.per.connection参数大于1,那么有可能第一个批量消息写入失败,但是第二个批量消息写入成功,然后第一个批量消息重试写入成功,那么这个顺序乱序的。因此,如果需要保证消息顺序,建议设置max.in.flight.requests.per.connection 为1,这样可以在第一个批量消息发送失败重试时,第二个批量消息需要等待。
2.4 批量发送数据
生产者发送多个消息到同一个分区的时候,为了减少网络带来的系能开销,kafka会对消息进行批量发送
- batch.size:通过这个参数来设置批量提交的数据大小,默认是16k,当积压的消息达到这个值的时候就会统一发送(发往同一分区的消息)
- linger.ms:这个设置是为发送设置一定是延迟来收集更多的消息,默认大小是0ms(就是有消息就立即发送)
当这两个参数同时设置的时候,只要两个条件中满足一个就会发送。比如说batch.size设置16kb,linger.ms设置50ms,那么当消息积压达到16kb就会发送,如果没有到达16kb,那么在第一个消息到来之后的50ms之后消息将会发送。
- max.request.size:默认是1M,请求的最大字节数
2.5 同步Producer与异步Producer
- 同步Producer
- 低延迟
- 低吞吐率
- 无数据丢失
只有消息发送成功了才会发送下一条消息,不成功重试,三次失败之后抛出异常,自行进行操作
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.util.Properties;
import java.util.concurrent.Future;
/**
* @Author haonan.bian
* @Description 同步Producer
* @Date 2020-02-13 21:55
**/
public class TestSyncProducer {
private static final String KAFKA_BOOTSTRAP_SERVERS = "hnode1:9092,hnode2:9092,hnode3:9092";
private static final String KAFKA_TOPIC= "test1";
private static final int bath = 10;
public static void main(String[] args) {
Properties properties = new Properties();
properties.put("bootstrap.servers",KAFKA_BOOTSTRAP_SERVERS);
properties.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer");
properties.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer");
properties.put("producer.type", "sync"); //同步发送
properties.put("acks", "1"); //Leader 写成功才算成功
KafkaProducer producer = null;
try{
producer = new KafkaProducer(properties);
for(int i=0;i<bath;i++){
ProducerRecord<String,String> record = new ProducerRecord<String, String>(KAFKA_TOPIC,String.valueOf(i),"message"+i);
Future<RecordMetadata> future = producer.send(record);
System.out.printf("partition=%s,offset=%s \n",future.get().partition(),future.get().offset());
Thread.sleep(1000);
}
}catch(Exception ex){
ex.printStackTrace();
}finally{
if(producer != null){
producer.close();
}
}
}
}- 异步Producer
- 高延迟
- 高吞吐率
- 可能会有数据丢失
数据send之后 将数据放进队列,队列数量到达一定程度之后,后台线程拿数据批量发送给 Broker ,如果队列数据满了阻塞超过一定时间,会直接丢掉新的数据
异步发送将多条消息暂时和客户端buff起来并将他们批量发送到 Broker ,小数据IO太多会拖慢整体的网络延迟,批量发会提高网络效率,不过这也有一定的隐患,比如当producer异常时那些尚未发送的数据将会丢失。
import org.apache.kafka.clients.producer.Callback;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.util.Properties;
import java.util.concurrent.Future;
/**
* @Author haonan.bian
* @Description kafka异步producer
* @Date 2020-02-13 21:29
**/
public class TestAsyncProducer {
private static final String KAFKA_BOOTSTRAP_SERVERS = "hnode1:9092,hnode2:9092,hnode3:9092";
private static final String KAFKA_TOPIC= "test1";
private static final int bath = 10;
public static void main(String[] args) {
Properties properties = new Properties();
properties.put("bootstrap.servers",KAFKA_BOOTSTRAP_SERVERS);
properties.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer");
properties.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer");
properties.put("producer.type", "async"); //异步发送
properties.put("acks", "1"); //Leader写成功才算成功
KafkaProducer producer = null;
try{
producer = new KafkaProducer(properties);
for(int i=0;i<bath;i++){
ProducerRecord<String,String> record = new ProducerRecord<String, String>(KAFKA_TOPIC,String.valueOf(i),"message"+i);
//在1.0 版本之前 异步producer不支持Java版本的回调函数
Future<RecordMetadata> future = producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
//如果Kafka返回一个错误,onCompletion方法抛出一个non null异常。
if (e != null) {
//对异常进行一些处理,这里只是简单打印出来
e.printStackTrace();
}
}
});
System.out.printf("partition=%s,offset=%s \n",future.get().partition(),future.get().offset());
Thread.sleep(1000);
}
}catch(Exception ex){
ex.printStackTrace();
}finally{
if(producer != null){
producer.close();
}
}
}
}
3. Consumer (消费者)
3.1 Consumer 介绍
Consumer :从kafka订阅数据供外部系统去使用,在kafka中当前消费到哪条消息的offset值是由 Consumer 来维护的。因此 Consumer 可以自己决定如何读取kafka的数据。比如, Consumer 可以通过重设 offset 值来重新消费已经消费的数据。kafka数据的生命周期是可配置的。只有到达规定时间数据才会被删除,不管该数据有没有被消费到。
3.2 Consumer Group
- 多个 Consumer 线程 可以组成一个 Consumer 组(Concumer Group)
- partition中的任意一条数据只能被同组内的一个 Consumer 消费,也就是说当一条消息在一个 Consumer Group 内的 Consumer 线程消费后,该 Consumer Group 内的其他 Consumer 线程就无法消费该数据了,
- 但是其他 Consumer Group 中的 Consumer 线程仍然能消费这条数据。所以如果想同时对一个topic做消费的话,启动多个 Consumer Group就可以了,但是需要注意的是,这里的多个 Consumer 的消费都是顺序读取partition里面的message,新启动的 Consumer 默认从partition队列最头端最新的地方阻塞的读message。
kafka为了提高吞吐量,一个partition最多只允许一个 Consumer Group 下的一个 Consumer 线程去消费,但是不同的 Consumer Group 中的 Consumer 线程还是可以去消费这个partition内的数据的。
- 当 Consumer Group中的 Consumer 线程数量小于partition 数量时,该 Consumer 线程还是会消费全部partition内的数据。
- 当 Consumer Group中的 Consumer 线程数量大于partition 数量时,每个 Consumer 线程消费一个partition的数据,会有超过partition数量个 Consumer 线程费不到数据。
- 当 Consumer Group中的 Consumer 线程数量等于partition 数量时,每个 Consumer 线程消费一个partition的数据,此时是最优设计,效率也是最高的。
当一份数据需要多次使用的时候就需要建立多个 Consumer Group 同时消费topic数据,这时offset的值互不影响,所以上面三点同样适用于该场景。当我们觉得数据消费效率不高时可以增加partition来横向扩展,同时增加相应数量的 Consumer 线程去消费新增partition的数据。在设定 Consumer group的时候,只需要指明里面有几个 Consumer 数量即可,无需指定对应的消费partition序号, Consumer 会自动进行rebalance。如下图
我们看一下下面图示的场景:
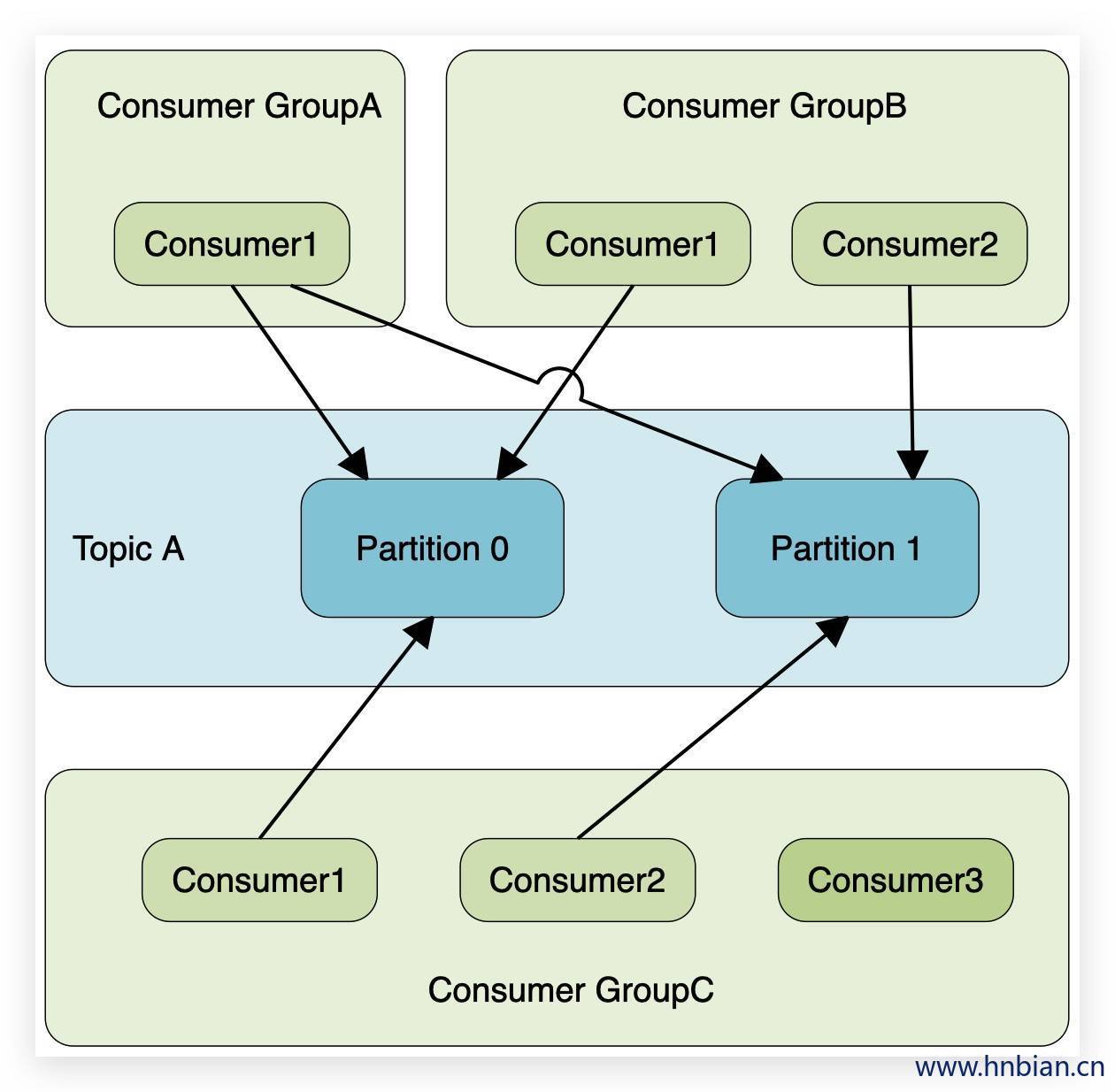
- TopicA 有2个partition
- GroupA有一个 Consumer 线程,那么这个线程消费两个分区的数据。
- GroupB有两个 Consumer 线程,这时 Consumer 与partition是一对一的消费关系。
- GroupC有三个 Consumer 线程,有两个线程能够消费到数据,会有一个 Consumer 线程处于空闲状态。当能够消费到数据的两个 Consumer 线程某个挂掉了,那么这个线程就可以消费到数据了。
3.3 Consumer Rebalance
3.3.1 Rebalance 介绍
为 Consumer Group 中的多个线程分配要进行消费的topic的分区的过程,称为 Consumer Rebalance。比如有10分区,5个消费线程,那么正常情况下每个消费线程会消费2个分区的数据,这个均衡的过程叫做 Consumer Rebalance。
3.3.2 Rebalance 触发条件
- Consumer 线程数增加或减少时
- 订阅的 Topic 个数发生变化时
- Topic 分区发生变化时
Consumer Rebalance 发生时,同一Group下的 Consumer 实例会共同参与,Kafka Controller 确保达到最公平的分配,在Rebalance 过程中 Consumer Group下面的所有线程需要停止工作,等待Rebalance完成,所以会对消费数据的效率有一些影响。
3.3.3 Group Coordinator
- kafka0.9.0版本的时候,在 Server 端增加了 GroupCoordinator 这个角色。
- Broker 在启动的时候都会启动一个GroupCoordinator实例,用于管理多个 Consumer Group和各 Consumer Group中各个成员,主要用于offset位移管理和 Consumer Rebalance。
- Group会选择一个Coordinator来完成自己组内各Partition的Offset信息,选择的规则如下:
- 计算 Group 对应在 __Consumer_offsets上的Partition
- 根据对应的Partition寻找该Partition的leader所对应的 Broker ,该 Broker 上的Group Coordinator即就是该Group的Coordinator
Partition计算规则:
//groupMetadataTopicPartitionCount对应offsets.topic.num.partitions参数值,默认值是50个分区
partition-Id(__Consumer_offsets) = Math.abs(groupId.hashCode() % groupMetadataTopicPartitionCount)3.3.4 Rebalance 过程分析
Consumer Rebalance 过程分为两步:Join 和 Sync。
- Join
所有成员都向coordinator发送JoinGroup请求,请求加入消费组。当所有成员都发送了JoinGroup请求,coordinator会从中选择一个 Consumer 担任leader的角色,并把组成员信息以及订阅信息发给leader——注意leader和coordinator不是一个概念。leader负责消费分配方案的制定。
- Sync
leader开始分配消费方案,即哪个 Consumer 负责消费哪些topic的哪些partition。分配完成后,leader会将这个方案封装进SyncGroup请求中发给coordinator,非leader也会发SyncGroup请求,只是内容为空。coordinator接收到分配方案之后会把方案塞进SyncGroup的response中发给各个 Consumer 。这样组内的所有成员就都知道自己应该消费哪些分区了。
3.3.5 Rebalance 场景分析
- 新的 Consumer 加入 Group
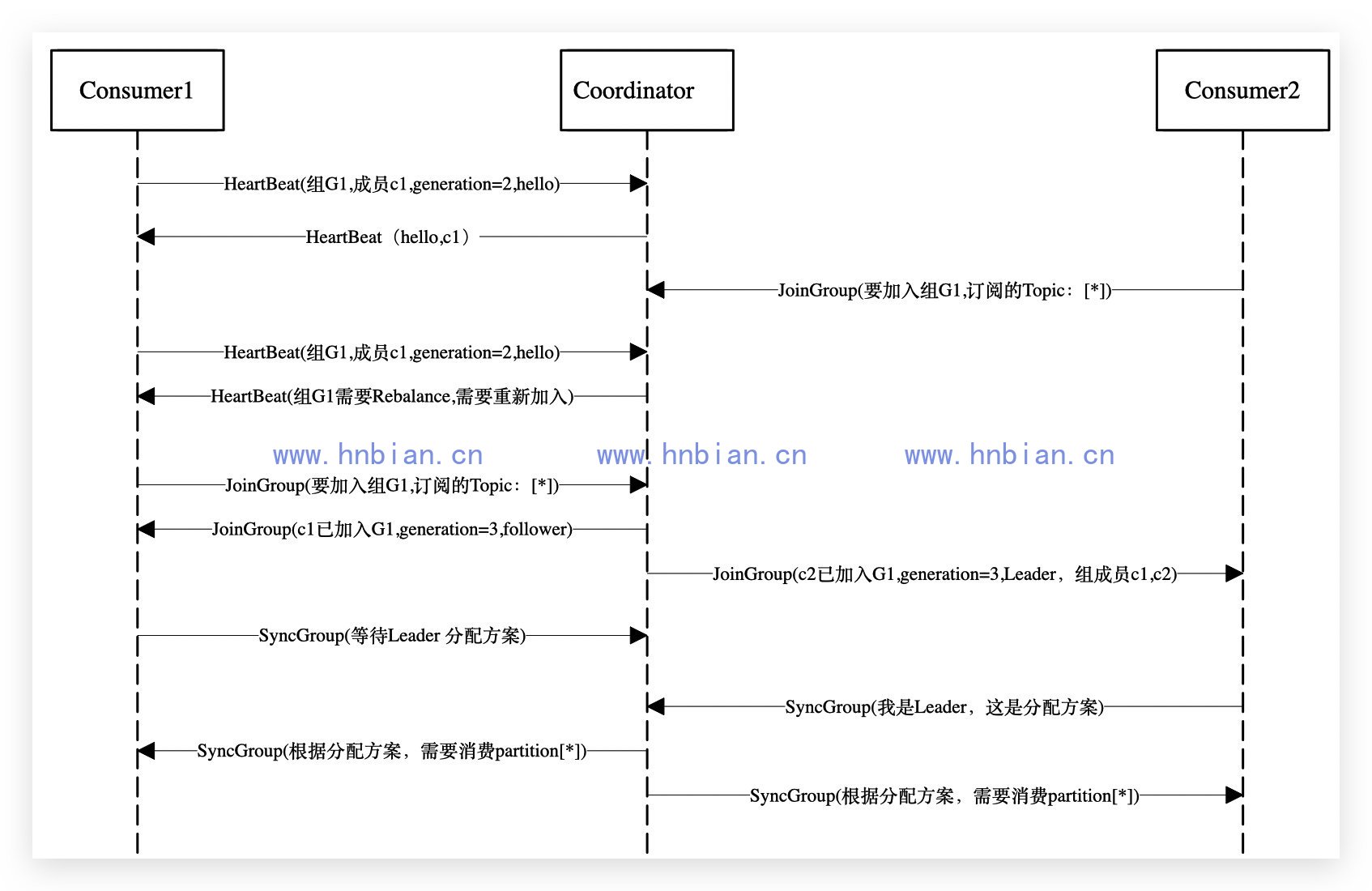
- Group 中的 Consumer 崩溃
崩溃则是被动地发起rebalance,崩溃时成员并不会主动地告知coordinator,coordinator有可能需要一个完整的session.timeout周期(心跳周期)才能检测到这种崩溃,而且会造成 Consumer 的滞后。
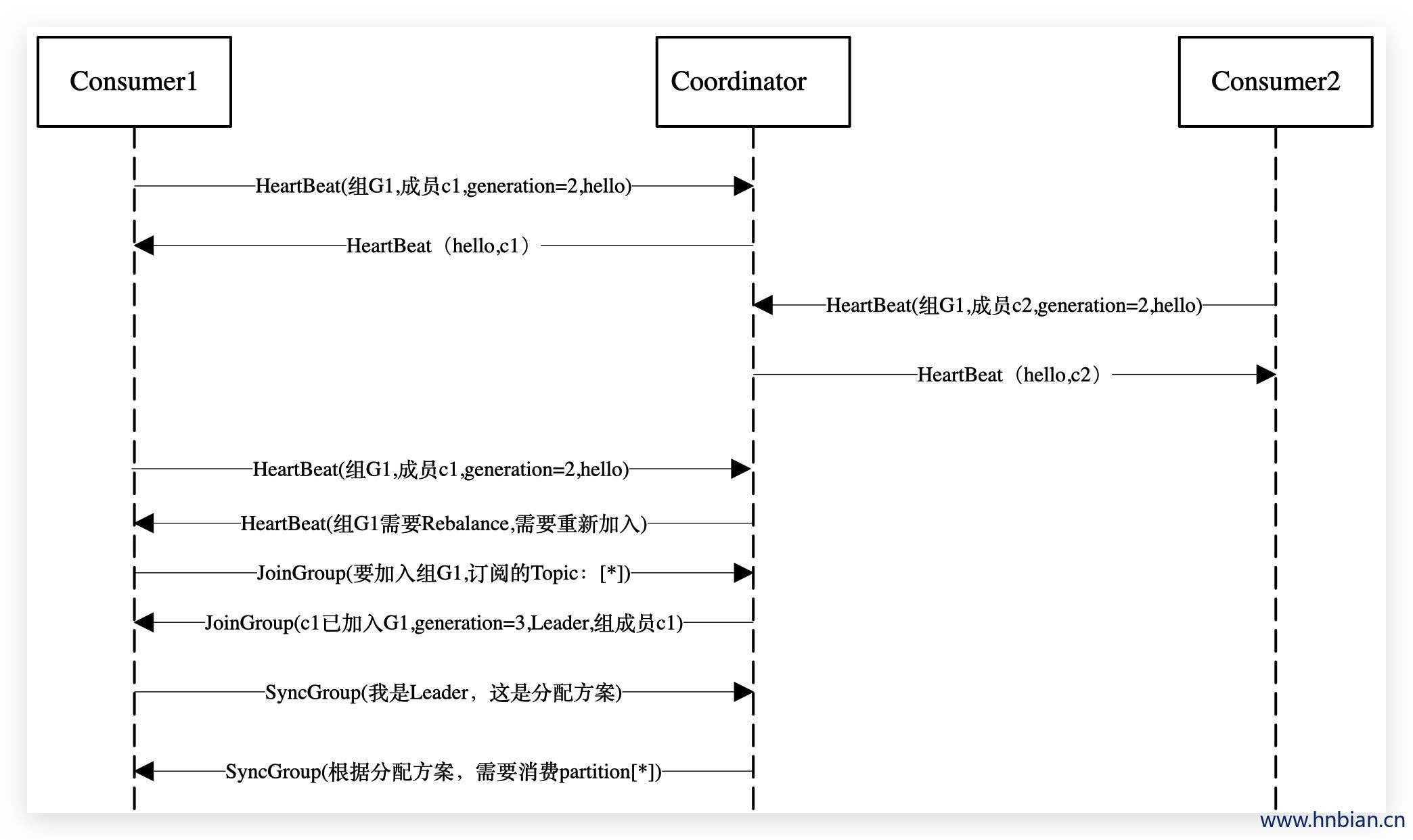
- Group 中的 Consumer 主动离开 (离开组会主动地发起rebalance)
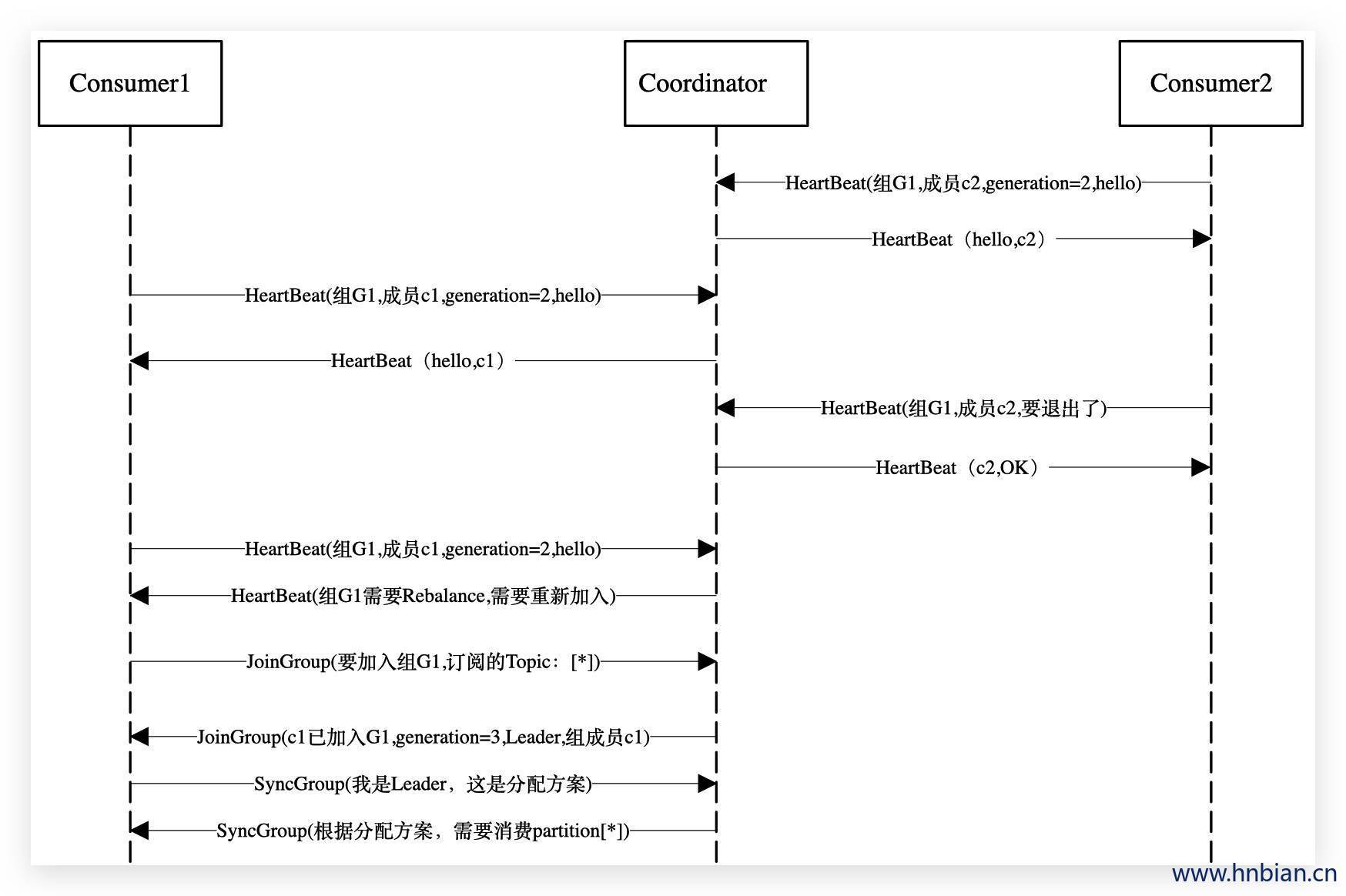
- Offset 提交
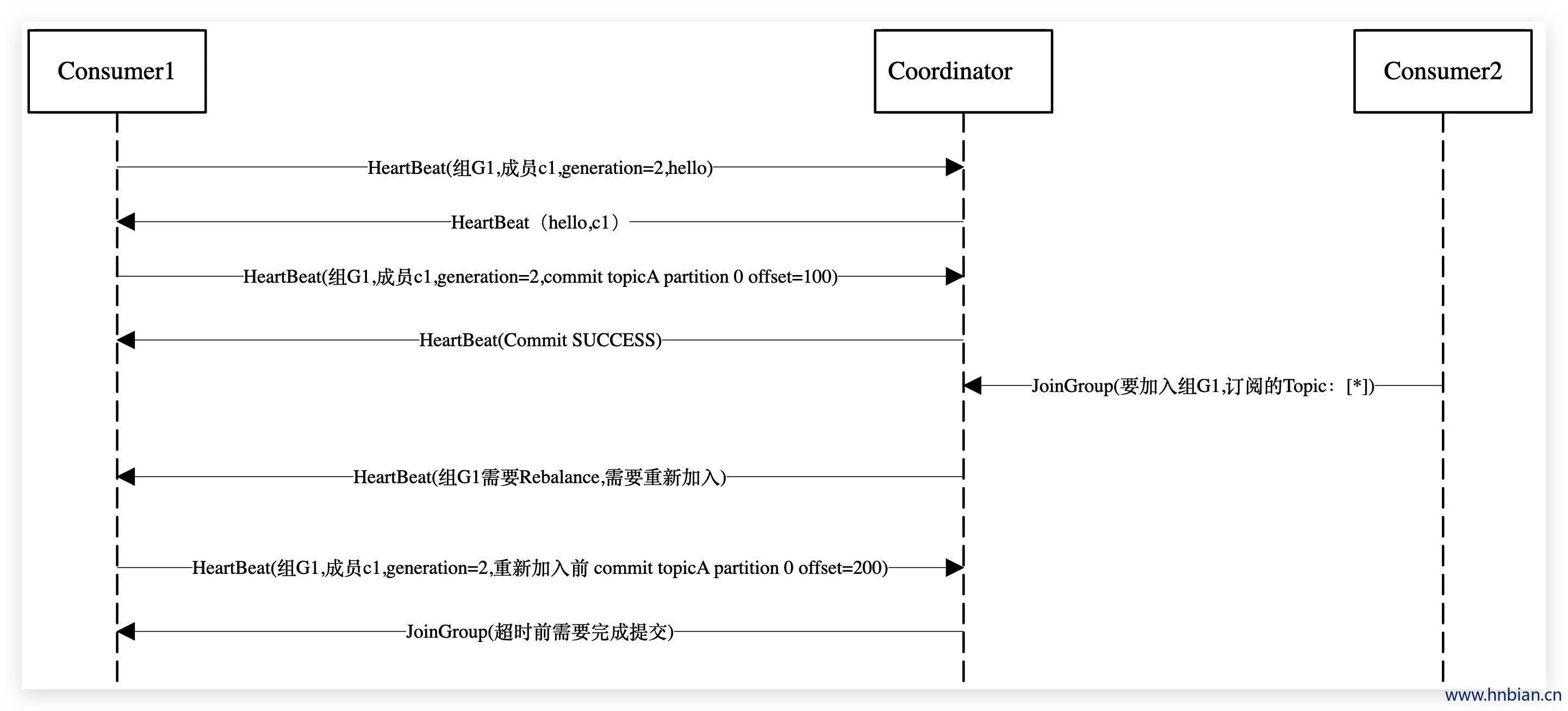
3.3.6 避免不必要的 Rebalance
调整参数:
| 参数 | 描述 |
|---|---|
| session.timeout.ms | 增大session超时时间,默认10s |
| heartbeat.interval.ms | 缩短心跳时间间隔,但是会增加资源消耗 |
| max.poll.interval.ms Consumer | 增大两次调用poll方法的最大时间间隔,默认5min |
3.4 Consumer 投递保证
- Consumer 消费partition 里面数据的时候是以 O(1) 顺序读取的,所以必须维护着上一次读到哪里的offset信息。
- high level API 的 offset 可以选择存储在 Zookeeper 或者 kafka 中。一般来说都是使用high level API 的。kafka为每条消息计算CRC校验,用于错误检测,CRC校验不通过的消息会被直接丢掉。
- low level API 的offset由自己维护。
访问指定元素时无需从头遍历,通过计算便可获得对应地址,其时间复杂度为O(1)
Producer向 Broker 发送消息时,一旦这条消息被commit,因为replication的存在,它就不会丢。
投递保证( Consumer delivery guarantee)有下面三种情况:
- At most once模式:
- 消息可能会丢,但绝不会重复传输
- 读完消息先commit再处理消息,在这种模式下,如果 Consumer 在commit后来没来得及处理消息就crash了,下次重新开始工作就就无法读到刚刚已提交而未处理的消息。这时这些未处理的数据就丢失了。
- At least once模式(默认):
- 消息绝不会丢,但可能会重复传输
- Kafka默认保证 At least once,并且允许通过设置Producer异步提交来实现At most once
- 读完消息先处理再commit。在这种模式下,如果在处理完消息之后commit之前 Consumer crash了,下次重新开始工作时还会处理刚刚未commit的消息,实际上该消息已经被处理过了,这就是导致该消息被处理多次,但不会丢数据。这种模式下数据处理相对于At most once会慢一些。
- Exactly once默认:
- Exactly once 每条消息肯定会被传输一次且仅传输一次,很多时候这是用户所想要的。
- Exactly once要求与外部存储系统写作,幸运的是Kafka提供的offset可以非常容易的使用这种方式。
- 如果一定要做到Exactly once 在0.11.0.0 之前的版本就需要协调offset和实际操作的输出。经典的做法是引入两个阶段提交。如果能让offset和操作输入存在同一个地方,会更简洁和通用。
3.5 kafka 对offset的管理
自动commit
将 Consumer 设置为autocommit,即 Consumer 一旦读到数据立即自动commit。该操作会在Zookeeper中保存该 Consumer 在该Partition中读取的消息的offset。该 Consumer 下次再读该Partition时会从该offset位置的下一条开始读取。如未commit,下次读取的开始位置会跟上一次commit之后的开始位置相同。
手动commit
手动commit全部offset
手动commit特定partition的offset
支持同步和异步commit并支持commit回调
消费流程控制 可暂停/恢复对某些Partition的消费
- pause 暂停消费指定的Partition
- resume 恢复对指定partition的消费
- wakeup 唤醒poll阻塞,并抛出WakeupException
3.6 Log compaction
3.6.1 Log compaction 介绍
Log Compaction是kafka提供的一种整理offset数据的方式。Log Compaction对于有相同key的的不同value值,只保留最后一个版本。如果应用只关心key对应的最新value值,可以开启Kafka的日志清理功能,Kafka会定期将相同key的消息进行合并,只保留最新的value值。

如果一个系统使用Kafka来保存topic消费数据的状态,每次有状态变更都会将其写入Kafka中。当某一时刻此系统异常崩溃,需要在恢复阶段通过读取Kafka中的消息来恢复其应有的状态,那么此时系统关心的是它原本的最新状态而不是历史时刻中的每一个状态。如果Kafka的日志保存策略是日志删除(Log Deletion),那么系统势必要一股脑的读取Kafka中的所有数据来恢复,而如果日志保存策略是Log Compaction,那么可以减少数据的加载量进而加快系统的恢复速度。Log Compaction在某些应用场景下可以简化技术栈,提高系统整体的质量。
Log Compaction执行前后,日志分段中的每条消息的偏移量和写入时的保持一致。Log Compaction会生成新的日志分段文件,日志分段中每条消息的物理位置会重新按照新文件来组织。Log Compaction执行过后的偏移量不再是连续的,会将大量过期数据过滤掉保留最新数据,大大增加了查询速度。Kafka中用于保存消费者消费位移的主题 _Consumer_offsets 使用的就是Log Compaction策略。
3.6.2 Log compaction 筛选文件
在配置文件中可以通过配置log.dir或者log.dirs参数来设置Kafka日志的存放目录,而对于每一个日志目录下都有一个名为 “cleaner-offset-checkpoint” 的文件,这个文件就是清理检查点文件,用来记录每个主题的每个分区中已清理的偏移量。
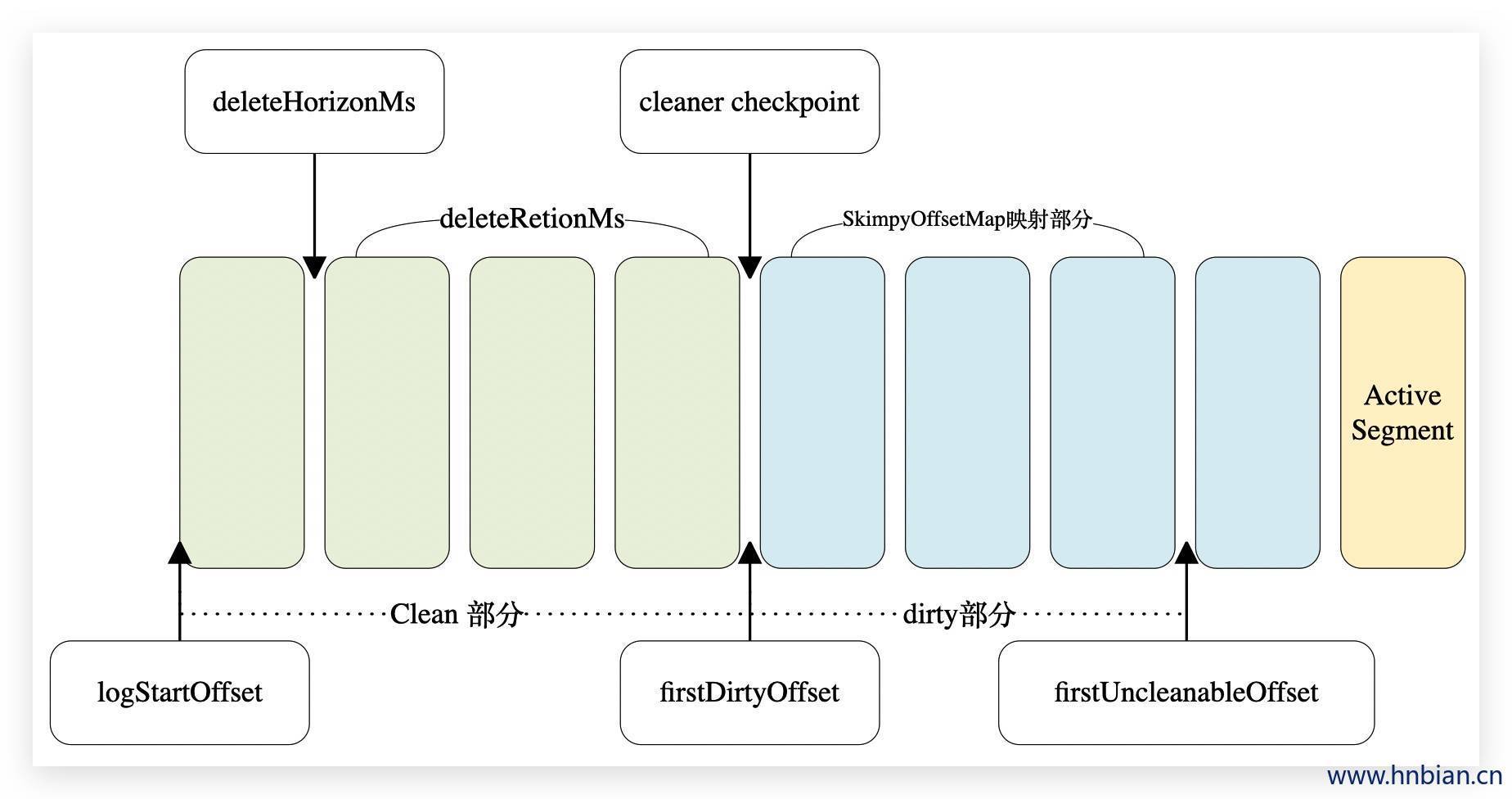
如上图通过检查点日志文件(Log)分成两个部分:
| 说明 | 范围 | |
|---|---|---|
| clean 部分 |
已经清理过,clean部分的消息偏移量是断续的 | [logStartOffset,firstDirtyOffset) |
| dirty 部分 |
还未清理的,在日志清理的同时,客户端也会读取日志,dirty部分的消息偏移量是逐一递增的,如果客户端总能赶上dirty部分,它就能读取到日志的所有消息,反之,就不可能读到全部的消息。 | [firstDirtyOffset,firstUncleanableOffset) |
activeSegment:当前活跃的日志文件,为避免activeSegment成为热点文件,activeSegment不会参与Log Compaction的操作。
同时Kafka支持通过参数log.cleaner.min.compaction.lag.ms(默认值为0)来配置消息在被清理前的最小保留时间,默认情况下firstUncleanableOffset等于activeSegment的baseOffset。
Log Compaction是针对key的,所以在使用时应注意每个消息的key值不为null。每个 Broker 会启动log.cleaner.thread(默认值为1)个日志清理线程负责执行清理任务,这些线程会选择“污浊率”最高的日志文件进行清理。日志的污浊率为:
// dirtyRatio 表示日志的污浊率
// cleanBytes 表示clean部分的日志占用大小
// dirtyBytes 表示dirty部分的日志占用大小
dirtyRatio = dirtyBytes / (cleanBytes + dirtyBytes)为了防止日志不必要的频繁清理操作,Kafka还使用了参数 log.cleaner.min.cleanable.ratio(默认值为0.5)来限定可进行清理操作的最小污浊率。
3.6.3 Log compaction 筛选key
Kafka中的每个日志清理线程会使用一个名为“SkimpyOffsetMap”的对象来构建 key与offset 的映射关系的哈希表。日志清理需要遍历两次日志文件,
- 第一次遍历把每个key的哈希值和最后出现的offset都保存在SkimpyOffsetMap中,映射模型如下图所示。
- 第二次遍历检查每个消息是否符合保留条件,如果符合就保留下来,否则就会被清理掉。
假设一条消息的offset为O1,这条消息的key在SkimpyOffsetMap中所对应的offset为O2,如果O1>=O2即为满足保留条件。
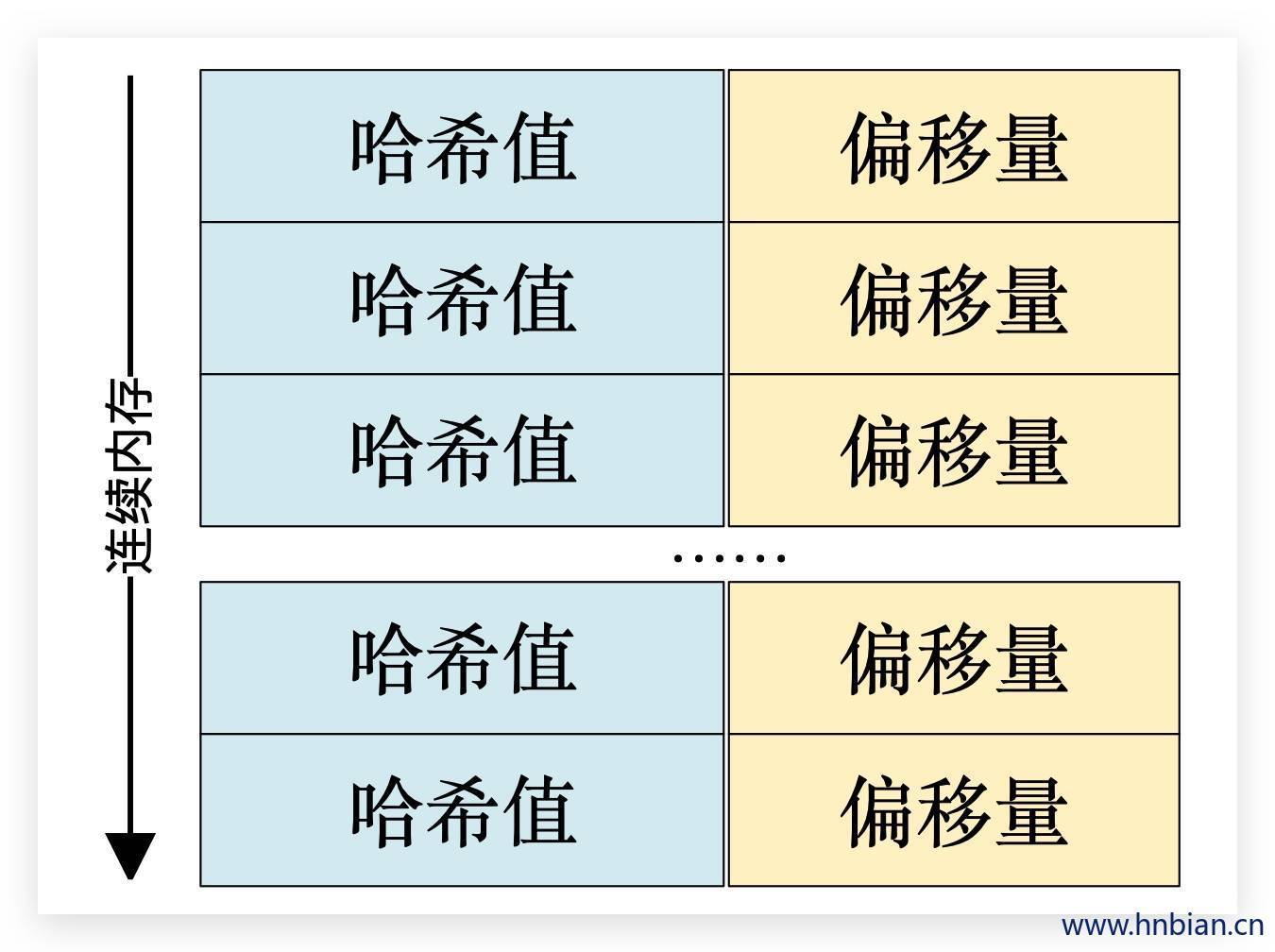
默认情况下SkimpyOffsetMap使用MD5来计算key的哈希值,占用空间大小为16B,根据这个哈希值来从SkimpyOffsetMap中找到对应的槽位,如果发生冲突则用线性探测法处理。为了防止哈希冲突过于频繁,我们也可以通过 Broker 端参数log.cleaner.io.buffer.load.factor(默认值为0.9)来调整负载因子。偏移量占用空间大小为8B,故一个映射项占用大小为24B。
每个日志清理线程的SkimpyOffsetMap的内存占用大小为log.cleaner.dedupe.buffer.size / log.cleaner.thread,默认值为 = 128MB/1 = 128MB。所以默认情况下SkimpyOffsetMap可以保存128MB * 0.9 /24B ≈ 5033164个key的记录。假设每条消息的大小为1KB,那么这个SkimpyOffsetMap可以用来映射4.8GB的日志文件,而如果有重复的key,那么这个数值还会增大,整体上来说SkimpyOffsetMap极大的节省了内存空间且非常高效。
Kafka中提供了一个墓碑消息(tombstone)的概念,如果一条消息的key不为null,但是其value为null,那么此消息就是墓碑消息。日志清理线程发现墓碑消息时会先进行常规的清理,并保留墓碑消息一段时间。墓碑消息的保留条件是当前墓碑消息所在的日志分段的最近修改时间lastModifiedTime大于deleteHorizonMs,这个deleteHorizonMs的计算方式为clean部分中最后一个日志分段的最近修改时间减去保留阈值deleteRetionMs(通过 Broker 端参数log.cleaner.delete.retention.ms配置,默认值为86400000,即24小时)的大小,即:
deleteHorizonMs = clean部分中最后一个LogSegment的lastModifiedTime - deleteRetionMs所以墓碑消息的保留条件为所在LogSegment的:
lastModifiedTime > deleteHorizonMs
也等于
lastModifiedTime > clean部分中最后一个LogSegment的lastModifiedTime - deleteRetionMs
也等于
lastModifiedTime + deleteRetionMs > clean部分中最后一个LogSegment的lastModifiedTime
Log Compaction执行过后的日志分段的大小会比原先的日志分段的要小,为了防止出现太多的小文件,Kafka在实际清理过程中并不对单个的日志分段进行单独清理,而是会将日志文件中offset从0至firstUncleanableOffset的所有日志分段进行分组,每个日志分段只属于一组,分组策略为:按照日志分段的顺序遍历,每组中日志分段的占用空间大小之和不超过segmentSize(可以通过 Broker 端参数log.segments.bytes设置,默认值为1GB),且对应的索引文件占用大小之和不超过maxIndexSize(可以通过 Broker 端参数log.index.interval.bytes设置,默认值为10MB)。同一个组的多个日志分段清理过后,只会生成一个新的日志分段。
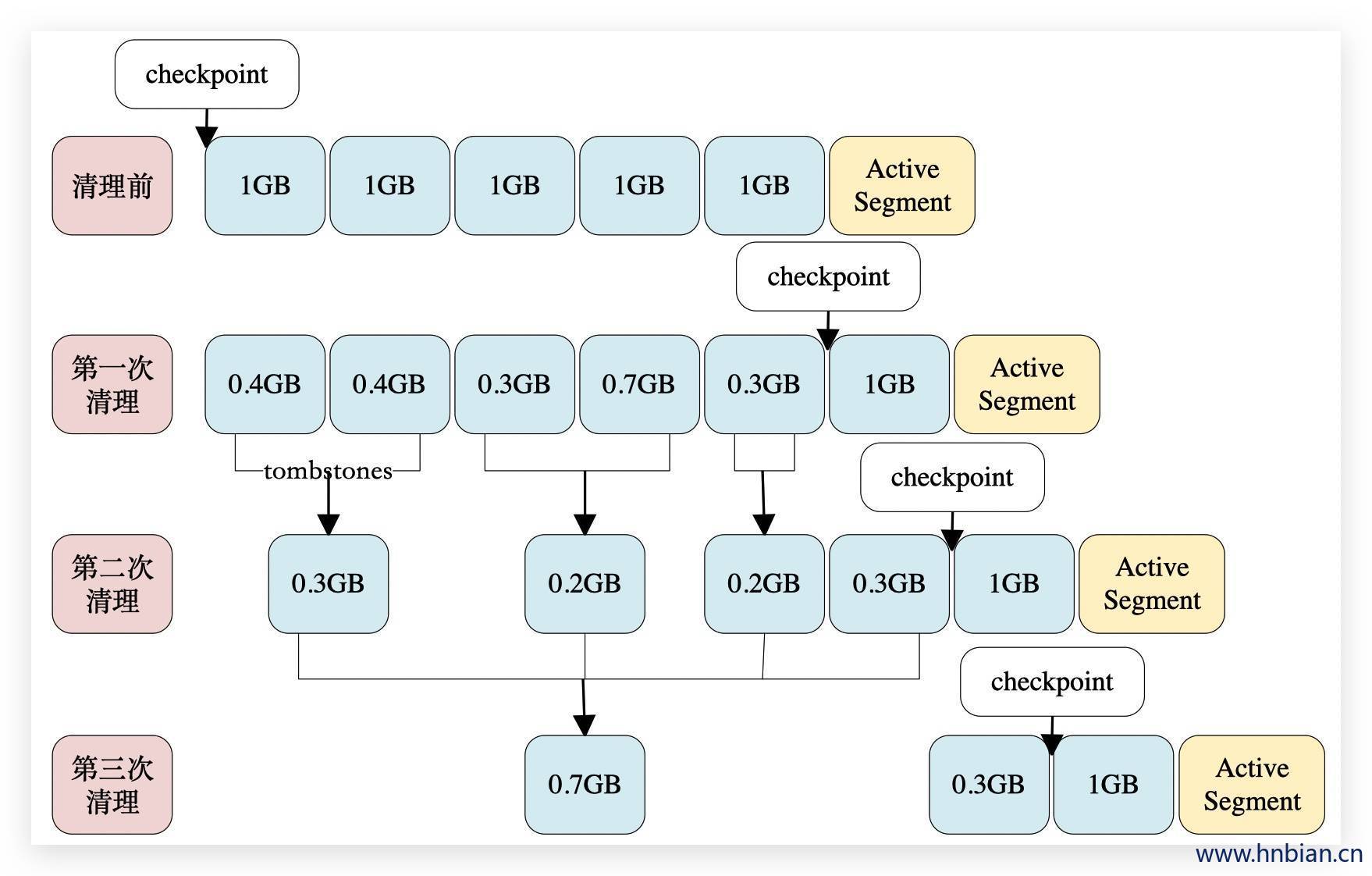
参考上图,假设所有的参数配置都为默认值,在Log Compaction之前checkpoint的初始值为0。
- 执行第一次Log Compaction之后,每个非活跃的日志分段的大小都有所缩减,checkpoint的值也有所变化。
- 执行第二次Log Compaction时会将组队成[0.4GB, 0.4GB]、[0.3GB, 0.7GB]、[0.3GB]、[1GB]这4个分组,并且从第二次Log Compaction开始还会涉及墓碑消息的清除。
- 执行第三次Log Compaction过后的情形可参考上图尾部。
Log Compaction 过程中 会将对每个日志分组中需要保留的消息拷贝到一个以“.clean”为后缀的临时文件中,此临时文件以当前日志分组中第一个日志分段的文件名命名,例如:000000000000000.log.clean。
Log Compaction 完成后 会将 “.clean” 的文件修改为以 “.swap” 后缀的文件,例如:000000000000000.log.swap,然后删除掉原本的日志文件,
最后才把文件的“.swap”后缀去掉,整个过程中的索引文件的变换也是如此,至此一个完整Log Compaction操作才算完成。
3.7 Consumer API
在1.0版本之前的kafka版本中,kafka Consumer 封装了两种API供用户使用:High-level API 和 Low-level API。而在1.0 版本之后将两种 API 进行合并优化。
3.7.1 High-level API
封装了对集群中一些列 Broker 的访问,可以透明的消费一个topic。它自己维护了已消费消息的状态,即每次消费的都是下一条数据。
还支持以组的方式消费topic,如果多个 Consumer 在同一个 Consumer group内,那么kafka就相当于一个队列消息服务,而各个 Consumer 均衡的消费响应partition的数据,若多个不同的 Consumer group同时消费一个topic数据,group之间也不会互相干扰。
Consumer 读取partition的offset是存在zookeeper上的(Kafka 0.8.2 版本中引入了native offset storage,将offset管理从zookeeper移出)在消费数据时也有几种模式。详细说明见 Consumer 投递保证章节。
offset 相关参数配置
| 参数 | 说明 | 参考值 |
|---|---|---|
| auto.commit.enable | 是否自动提交offset | true |
| auto.commit.interval.ms | 自从commit时间间隔 | 60*1000 |
| offsets.storage | offset存储位置 | zookeeper |
| dual.commit.enabled | 当offsets.storage=kafka时需要加上此参数(true) | true |
| Consumer Connector.commitOffsets(); | 手工管理offset |
- 代码示例
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.9.0.1</version>
</dependency>import org.apache.kafka.clients. Consumer . Consumer ;
import org.apache.kafka.clients. Consumer . Consumer Record;
import org.apache.kafka.clients. Consumer . Consumer Records;
import org.apache.kafka.clients. Consumer .Kafka Consumer ;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.util.Arrays;
import java.util.HashMap;
import java.util.Map;
import java.util.Properties;
public class KafkaComsumer {
private final String KAFKA_BOOTSTRAP_SERVERS = "node1:9092,node2:9092,node3:9092";
private final String KAFKA_TOPIC= "test1";
private final String KAFKA_ Consumer _GROUPID = "groupb";
private Kafka Consumer <String, String> Consumer = null;
private Consumer Records<String, String> msgList;
public static void main(String[] args) {
KafkaComsumer data Consumer = new KafkaComsumer();
data Consumer . Consumer ();
}
public KafkaComsumer() {
Properties props = new Properties();
props.put("bootstrap.servers", KAFKA_BOOTSTRAP_SERVERS);
props.put("group.id", KAFKA_ Consumer _GROUPID);
props.put("enable.auto.commit", "true");
props.put("zookeeper.session.timeout.ms", "50000");
props.put("key.deserializer", StringDeserializer.class.getName());
props.put("value.deserializer", StringDeserializer.class.getName());
props.put("auto.offset.reset", "earliest");
this. Consumer = new Kafka Consumer <String, String>(props);
this. Consumer .subscribe(Arrays.asList(KAFKA_TOPIC));
}
public void Consumer () {
int messageNo = 1;
Map<String, Integer> deviceMap = new HashMap<String, Integer>();
try {
for (; ; ) {
msgList = Consumer .poll(1000);
if (null != msgList && msgList.count() > 0) {
for ( Consumer Record<String, String> record : msgList) {
System.out.println(record.value() + "," + record.partition() + "," + record.offset());
}
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
3.7.2 Low-level API
Consumer 消费 partition数据的offset在 Consumer 自己的程序中维护。这样的好处是因为offset是我们自己维护的,如果某个数据消费出现了异常,可以对异常消费数据进特殊处理。这样可以做到 exactly once 对数据的准确性有保证。
一般不会将offset信息同步到zookeeper上。但是为了kafkamanager能够方便监控,也会手动的同步到zookeeper上。
使用Low-level API 的主要原因是,用户比 Consumer Group更好的控制数据的消费。
- 同一条消息读多次,方便replay
- 只消费某个topic的部分Partition
- 管理事务,从而确保每条消息只被处理一次(Exactly once)
与High-level API相比 Low-level API 要求用户做大量额外的工作
在应用程序中跟踪处理offset,并决定下一条消息是哪条消息。
获知每个Partition的Leader
处理Leader的变化
处理多 Consumer 的协作
import kafka.api.FetchRequestBuilder;
import kafka.api.FetchRequest;
import kafka.javaapi.FetchResponse;
import kafka.javaapi. Consumer .Simple Consumer ;
import kafka.javaapi.message.ByteBufferMessageSet;
import kafka.message.MessageAndOffset;
import java.nio.ByteBuffer;
/**
* @Author haonan.bian
* @Description 旧的Low-level api
* kafka 1.0 之后已经标示这些api为过期状态
* @Date 2020-02-15 14:16
**/
public class LowLevelConsumerOld {
// 定义 Kafka 主题
private static final String KAFKA_TOPIC= "test4";
// 定义批处理大小
private static final int bath = 10;
public static void main(String[] args) {
try{
// 定义客户端 ID
String clientId = "LowLevelConsumerOld";
// 创建一个简单的消费者,连接到 Kafka 服务器
SimpleConsumer simpleConsumer = new SimpleConsumer("hnode3",9092,1000,64*1000,clientId);
// 创建一个获取请求,指定主题、分区和偏移量
FetchRequest req = new FetchRequestBuilder().clientId(clientId)
.addFetch(KAFKA_TOPIC,0,30L,1000000)
.addFetch(KAFKA_TOPIC,1,0L,1000000).build();
// 发送获取请求,获取消息
FetchResponse fetchResponse = simpleConsumer.fetch(req);
// 获取指定主题和分区的消息集
ByteBufferMessageSet messageSet0 = (ByteBufferMessageSet)fetchResponse.messageSet(KAFKA_TOPIC,0);
ByteBufferMessageSet messageSet1 = (ByteBufferMessageSet)fetchResponse.messageSet(KAFKA_TOPIC,1);
// 打印消息集的大小
System.out.println(messageSet0.sizeInBytes());
// 遍历消息集,打印每个消息的偏移量和内容
for(MessageAndOffset messageAndOffset: messageSet0){
ByteBuffer payload = messageAndOffset.message().payload();
long offset = messageAndOffset.offset();
byte[] bytes = new byte[payload.limit()];
payload.get(bytes);
System.out.println("offset="+offset+", payload="+new String(bytes,"UTF-8"));
}
}catch (Exception e){
// 打印异常信息
e.printStackTrace();
}
}
}3.7.3 最新API
在1.0 以及之后的版本中kafka将 High-level API 与Low-level API 进行了统一,以及下面一些变化:
- 将kafka. Consumer 和kafka.javaapi 两个包合并到kafka.clients.conumer中
- 支持 subscribe 动态 rebalance 和 assign 手动分配 partition
- 支持将 offset 存储与 kafka 和 Zookeeper 之外的存储中
- Consumer RebalanceListener
- 控制消费位置:通过API 控制从某个位置开始消费
- 控制消费流程:可以指定暂停某个partition的消费但是可以将继续消费其他partition
- subscribe 方式,相当于 High-level API 代码示例
import org.apache.kafka.clients. Consumer .*;
import org.apache.kafka.common.TopicPartition;
import java.util.Arrays;
import java.util.Collections;
import java.util.List;
import java.util.Properties;
/**
* @Author haonan.bian
* @Description 消费并提交指定分区的offset
* @Date 2020-02-15 21:05
**/
public class Consumer APINewSubscribePartition {
private static final String KAFKA_BOOTSTRAP_SERVERS = "hnode1:9092,hnode2:9092,hnode3:9092";
private static final String KAFKA_TOPIC= "test1";
private static final int batch = 10;
public static void main(String[] args) {
Properties props = new Properties();
props.put( Consumer Config.BOOTSTRAP_SERVERS_CONFIG, KAFKA_BOOTSTRAP_SERVERS);
props.put( Consumer Config.GROUP_ID_CONFIG, "Demo Consumer ");
//是否开启自动提交
props.put( Consumer Config.ENABLE_AUTO_COMMIT_CONFIG, "false");
//每次取出的数据最大数
props.put( Consumer Config.MAX_POLL_RECORDS_CONFIG, batch);
props.put( Consumer Config.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000");
props.put( Consumer Config.SESSION_TIMEOUT_MS_CONFIG, "30000");
props.put( Consumer Config.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
props.put( Consumer Config.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
props.put("auto.AotoCommitDemo.reset", "latest");
Kafka Consumer <String,String> Consumer =new Kafka Consumer <String, String>(props);
Consumer .assign(Arrays.asList(new TopicPartition(KAFKA_TOPIC,0)));
while(true){
Consumer Records<String,String> records= Consumer .poll(10000);
//根据分区消费数据
records.partitions().forEach(topicPartition -> {
List< Consumer Record<String,String>> partitionRecords= records.records(topicPartition);
partitionRecords.forEach(record->{
System.out.printf("partition: %s,offset: %s,key: %s,key: %s \n",
record.partition(),record.offset(),record.key(),record.value());
});
//从已有的最早的数据开始消费
// Consumer .beginningOffsets()
//从最后的数据开始消费
// Consumer .endOffsets()
//指定从哪条数据开始消费
// Consumer .seek();
long lastOffset = partitionRecords.get(partitionRecords.size()-1).offset();
Consumer .commitSync(
Collections.singletonMap(topicPartition,new OffsetAndMetadata(lastOffset + 1))
);
});
}
}
}
- assign 方式,相当于 Low-level API 代码示例
import org.apache.kafka.clients. Consumer . Consumer Config;
import org.apache.kafka.clients. Consumer . Consumer Records;
import org.apache.kafka.clients. Consumer .Kafka Consumer ;
import org.apache.kafka.clients. Consumer .OffsetAndMetadata;
import org.apache.kafka.common.TopicPartition;
import java.util.Arrays;
import java.util.Map;
import java.util.Properties;
import java.util.concurrent.atomic.AtomicLong;
/**
* @Author haonan.bian
* @Description //TODO
* @Date 2020-02-15 20:26
**/
public class Consumer APINewAssign {
private static final String KAFKA_BOOTSTRAP_SERVERS = "hnode1:9092,hnode2:9092,hnode3:9092";
private static final String KAFKA_TOPIC= "test1";
private static final int bath = 10;
public static void main(String[] args) {
Properties props = new Properties();
props.put( Consumer Config.BOOTSTRAP_SERVERS_CONFIG, KAFKA_BOOTSTRAP_SERVERS);
//是否开启自动提交
props.put( Consumer Config.ENABLE_AUTO_COMMIT_CONFIG, "false");
//每次取出的数据最大数
props.put( Consumer Config.MAX_POLL_RECORDS_CONFIG, 2);
props.put( Consumer Config.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000");
props.put( Consumer Config.SESSION_TIMEOUT_MS_CONFIG, "30000");
props.put(
Consumer Config.KEY_DESERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringDeserializer"
);
props.put(
Consumer Config.VALUE_DESERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringDeserializer"
);
props.put("auto.AotoCommitDemo.reset", "latest");
Kafka Consumer <String,String> Consumer =new Kafka Consumer <String, String>(props);
Consumer .assign(Arrays.asList(new TopicPartition(KAFKA_TOPIC,0),new TopicPartition(KAFKA_TOPIC,1),new TopicPartition(KAFKA_TOPIC,2)));
AtomicLong atomicLong = new AtomicLong();
while(true){
//超时时间过后如果没有返回数据进行下一次轮询,
Consumer Records<String,String> records= Consumer .poll(10000);
System.out.println(records.count());
records.forEach(record-> System.out.printf("partition: %s,offset: %s,key: %s,key: %s \n",
record.partition(),record.offset(),record.key(),record.value()));
if(atomicLong.get() % 10 ==0){
// Consumer .commitSync(); //同步提交,待提交成功后返回,否则会阻塞在这里
//异步提交
Consumer .commitAsync((Map< TopicPartition,OffsetAndMetadata > offsets,Exception ex)->{
offsets.forEach((TopicPartition partition,OffsetAndMetadata offset)->{
System.out.println(
"commit topic"+partition.topic()
+", partition "+partition.partition()
+", offset "+offset.offset()
);
});
if(null != ex ){
ex.printStackTrace();
}
});
}
}
}
}参考资料:
https://blog.csdn.net/u013256816/article/details/80865540
https://blog.csdn.net/u013256816/article/details/80487758
https://www.infoq.cn/article/kafka-analysis-part-3
https://www.cnblogs.com/yoke/p/11405397.html#autoid-0-5-0