<remote_servers> <!-- Test only shard config for testing distributed storage --> <test_shard_localhost> <!-- Inter-server per-cluster secret for Distributed queries default: no secret (no authentication will be performed) If set, then Distributed queries will be validated on shards, so at least: - such cluster should exist on the shard, - such cluster should have the same secret. And also (and which is more important), the initial_user will be used as current user for the query. Right now the protocol is pretty simple and it only takes into account: - cluster name - query Also it will be nice if the following will be implemented: - source hostname (see interserver_http_host), but then it will depends from DNS, it can use IP address instead, but then the you need to get correct on the initiator node. - target hostname / ip address (same notes as for source hostname) - time-based security tokens --> <!-- <secret></secret> -->
<shard> <!-- Optional. Whether to write data to just one of the replicas. Default: false (write data to all replicas). --> <!-- <internal_replication>false</internal_replication> --> <!-- Optional. Shard weight when writing data. Default: 1. --> <!-- <weight>1</weight> --> <replica> <host>localhost</host> <port>9000</port> <!-- Optional. Priority of the replica for load_balancing. Default: 1 (less value has more priority). --> <!-- <priority>1</priority> --> </replica> </shard> </test_shard_localhost> <test_cluster_two_shards_localhost> <shard> <replica> <host>localhost</host> <port>9000</port> </replica> </shard> <shard> <replica> <host>localhost</host> <port>9000</port> </replica> </shard> </test_cluster_two_shards_localhost> <!-- 配置 2 个分配,0 副本 --> <test_cluster_two_shards> <shard> <replica> <host>127.0.0.1</host> <port>9000</port> </replica> </shard> <shard> <replica> <host>127.0.0.2</host> <port>9000</port> </replica> </shard> </test_cluster_two_shards> <!--2 分片,0 副本--> <test_cluster_two_shards_internal_replication> <shard> <internal_replication>true</internal_replication> <replica> <host>127.0.0.1</host> <port>9000</port> </replica> </shard> <shard> <internal_replication>true</internal_replication> <replica> <host>127.0.0.2</host> <port>9000</port> </replica> </shard> </test_cluster_two_shards_internal_replication> <!--1分片 0 副本,权重设为 1--> <test_shard_localhost_secure> <shard> <replica> <host>localhost</host> <port>9440</port> <secure>1</secure> </replica> </shard> </test_shard_localhost_secure> <test_unavailable_shard> <shard> <replica> <host>localhost</host> <port>9000</port> </replica> </shard> <shard> <replica> <host>localhost</host> <port>1</port> </replica> </shard> </test_unavailable_shard> <!-- 手动添加新的集群 --> <two_shard> <shard> <replica> <host>node3</host> <port>9977</port> </replica> </shard> <shard> <replica> <host>node2</host> <port>9977</port> </replica> </shard> </two_shard> </remote_servers>
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
-- 在 system.clusters 中查看配置情况 select cluster,host_name from system.clusters;
query: CREATE TABLE default.t_shard UUID \'d1679b02-9eae-4766-8032-8201a2746692\' ON CLUSTER two_shard (`id` UInt8, `name` String, `date` DateTime) ENGINE = ReplicatedMergeTree(\'/clickhouse/tables/{shard}/t_shard\', \'{replica}\') PARTITION BY toYYYYMM(date) ORDER BY id
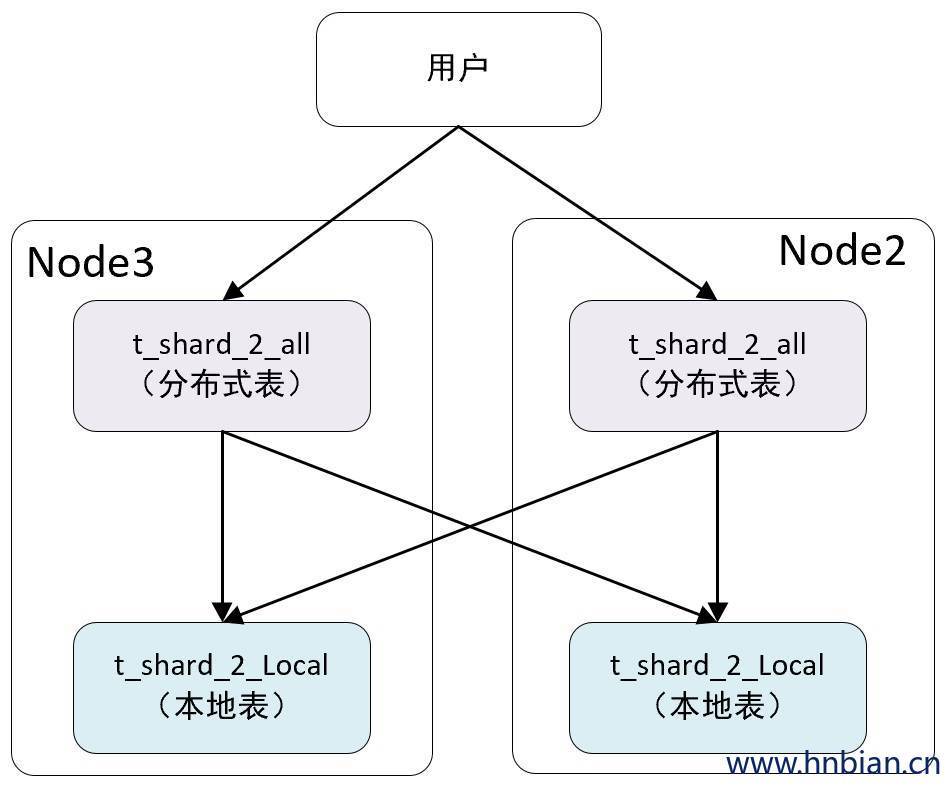
-- 尝试 查询 t_shard_2_all 分布式表 SELECT* FROM t_shard_2_all;
Received exception from server (version 21.4.3): Code: 60. DB::Exception: Received from localhost:9977. DB::Exception: Table default.t_shard_2_local doesn t exist.
SELECT uniq(id) FROM t_distributed_query_all WHERE (repo =100) AND ( id IN ( SELECT id FROM t_distributed_query_local WHERE repo =200 ) );
┌─uniq(id)─┐ │ 0 │ └──────────┘ -- 并没有查询出结果
-- 在分布式表在接收到查询后,将上面 SQL 替换成本地表的形式再发送到每个分片进行执行
SELECT uniq(id) FROM t_distributed_query_local WHERE (repo =100) AND ( id IN ( SELECT id FROM t_distributed_query_local WHERE repo =200 ) ); -- 单独在分片 1 或分片 2 都无法找到满足 同时等于 100 和 200 的数据
使用 global 优化查询
为了解决查询问题,可以使用 global in 或者 join 进行优化
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
SELECT uniq(id) FROM t_distributed_query_all WHERE (repo =100) AND (id GLOBALIN ( SELECT id FROM t_distributed_query_all WHERE repo =200 ))
Query id: 0a55d59d-c87b-4bc8-8985-dad26f0a39b9
┌─uniq(id)─┐ │ 1 │ └──────────┘
Global 查询流程:
将 in 子句单独提出,发起一次分布式查询
将分布式表转成 local 表后,分别在本地和远端分片执行查询
将 in 子查询结果进行汇总,放入一张临时的内存表进行保存
将内存表发送到远端分片节点
将分布式表转为本地表后,开始执行完整的 SQL 语句,in 子句直接使用临时表的数据
在使用 global 修饰符之后,clickhouse 使用内存表临时保存了 in 子查询到的数据,并将其发送到远端分片节点,以此达到了数据共享的目的,从而避免了查询放大的问题,in 或者 join 子句返回的数据不宜过大,如果内存表存在重复数据,可以实现在子句中增加 distinct 实现去重。