Phoenix 官方函数说明地址:https://phoenix.apache.org/language/functions.html
1. 数字函数
1.1 ROUND
将数字或时间戳表达式四舍五入到指定的最接近的比例或时间单位。
如果表达式是数字类型,则第二个参数是用于四舍五入的数字的刻度,默认为零。
如果表达式是日期/时间类型,则第二个参数可以是列出的时间单位之一,以确定日期/时间的剩余精度。MILLISECONDS如果不存在,则使用默认值。乘数仅适用于日期/时间类型,用于舍入为时间单位的倍数(即10分钟),如果未指定,则默认为1。此方法返回与其第一个参数相同的类型。
例:
1 | ROUND(number) |
1 | select ROUND(1.6356); |


- CEIL
相同ROUND,除了它舍入任何分数值直到下一个偶数倍。
例:
1 | CEIL(number, 3) |
1 | SELECT CEIL(5.123456, 3); |

1 | select ROUND(TO_TIME('2005-10-01 14:03:22.559'), 'HOUR'); |

1.2 FLOOR
相同ROUND,除了它将任何小数值向下舍入为以前的偶数倍。
例:
1 | FLOOR(timestamp) |
1 | select FLOOR(TO_date('2005-10-01 14:03:22.559'), 'DAY', 7); |

1.3 TRUNC
与…一样 FLOOR
例:
1 | TRUNC(timestamp, 'SECOND', 30) |
1 | select TRUNC(TO_date('2005-10-01 14:03:22.559'), 'DAY', 7); |

1.4 TO_NUMBER
将字符串或日期/时间类型格式化为数字,可选择接受格式字符串。有关格式的详细信息,请参阅java.text.DecimalFormat。对于日期,时间和timeStamp项,结果是从纪元开始的时间(以毫秒为单位)。此方法返回一个十进制数。
例:
1 | TO_NUMBER('$123.33', '\u00A4###.##') |
1.5 RAND
在0.0(包含)和1.0(不包含)之间产生随机,均匀分布的双精度值的函数。如果提供了种子,则对于同一行的每个调用,返回的值都是相同的。如果未提供种子,则返回的值对于每个调用是不同的。种子必须是常数。
例:
1 | RAND() |
1 | select RAND(5); |

2. 字符串函数
2.1 SUBSTR
返回从基于1的位置开始的字符串的子字符串。如果使用零,则位置为零。如果起始索引为负,则起始索引相对于字符串的结尾。长度是可选的,如果未提供,则将返回字符串的其余部分。
例:
1 | SUBSTR('[Hello]', 2, 5) |
1 | SELECT SUBSTR('ABC',1,2); |

2.2 INSTR
返回第一个参数中第二个参数的初始出现的基于1的位置。如果第二个参数不包含在第一个参数中,则返回零。
例:
1 | INSTR('Hello World', 'World') |
1 | select INSTR('Hello World', 'World'); |

2.3 TRIM
从输入字符串中删除前导和尾随空格。
例:
1 | TRIM(' Hello ') |
1 | SELECT TRIM(' ABC '); |

2.4 LTRIM
从输入字符串中删除前导空格。
例:
1 | LTRIM(' Hello') |
1 | SELECT LTRIM(' ABC '); |

2.5 RTRIM
从输入字符串中删除结尾空格。
例:
1 | RTRIM('Hello ') |
1 | SELECT RTRIM(' ABC '); |

2.6 LPAD
使用特定的填充字符(默认空格)填充字符串表达式,直到长度参数。
例:
1 | LPAD('John',30) |
1 | select LPAD('John',30); |

2.7 LENGTH
返回字符串的长度(以字符为单位)。
例:
1 | LENGTH('Hello') |
1 | select LENGTH('abc'); |

2.8 REGEXP_SUBSTR
通过从基于1的位置的偏移应用正则表达式start返回字符串的子字符串。就像与SUBSTR,如果开始索引是负数,那么它是相对于字符串的结尾。如果未指定,则开始索引默认为1。
例:
1 | REGEXP_SUBSTR('na1-appsrv35-sj35', '[^-]+') evaluates to 'na1' |
1 | select REGEXP_SUBSTR('a1b2c3','\d'); |

2.9 REGEXP_REPLACE
通过应用正则表达式并使用替换字符串替换匹配项来返回字符串。如果未指定替换字符串,它将默认为空字符串。
例:
1 | REGEXP_REPLACE('abc123ABC', '[0-9]+', '#') evaluates to 'abc#ABC' |
1 | select REGEXP_REPLACE('a1b2c3','[0-9]','-'); |

2.10 REGEXP_SPLIT
VARCHAR ARRAY使用正则表达式将字符串拆分成一个。如果在正则表达式中具有特殊含义的字符将用作模式字符串中的常规定界符,则必须使用反斜线对其进行转义。
例:
1 | REGEXP_SPLIT('ONE,TWO,THREE', ',') evaluates to ARRAY['ONE', 'TWO', 'THREE'] |
1 | select REGEXP_SPLIT('ONE,TWO,THREE', ','); |

2.11 UPPER
返回字符串参数的大写字符串。
例:
1 | UPPER('Hello') |
1 | SELECT UPPER('AaBbCcDd'); |

2.12 LOWER
返回字符串参数的小写字符串。
例:
1 | LOWER('HELLO') |
1 | SELECT LOWER('AaBbCcDd'); |

2.13 REVERSE
返回字符串参数的反转字符串。
例:
1 | REVERSE('Hello') |
1 | SELECT REVERSE('AaBbCcDd'); |

2.14 TO_CHAR
将日期,时间,时间戳或数字格式化为字符串。默认日期格式为yyyy-MM-dd HH:mm:ss,默认数字格式为#,##0.###。有关详细信息,请参阅java.text.SimpleDateFormat日期/时间值和java.text.DecimalFormat数字。此方法返回一个字符串。
例:
1 | TO_CHAR(myDate, '2001-02-03 04:05:06') |
3. 时间函数
3.1 TO_DATE
解析字符串并返回日期。请注意,返回的日期在内部表示为自java纪元以来的毫秒数。最重要的格式字符是:y年,M月,d天,H小时,m分钟,s秒。默认格式字符串为yyyy-MM-dd HH:mm:ss。有关格式的详细信息,请参阅java.text.SimpleDateFormat。默认情况下,GMT将在解析日期时用作时区。然而,也可以提供时区id。这是时区ID,例如“ GMT+1”。如果提供“local”作为时区id,则本地时区将用于解析。配置设置phoenix.query.dateFormatTimeZone也可以设置为时区ID,这将导致使用配置的GMT时区ID覆盖默认设置。DATE请参阅数据类型参考指南,了解Apache Phoenix当前如何定义数据类型。此外,Phoenix支持ANSI SQL date类似于单参数TO_DATE函数的字面量。
例:
1 | TO_DATE('Sat, 3 Feb 2001 03:05:06 GMT', 'EEE, d MMM yyyy HH:mm:ss z') |
1 | select TO_DATE('2017-01-01', 'yyyy-MM-dd', 'GMT+1'); |

3.2 TO_TIME
将给定的字符串转换为TIME实例。当不提供日期格式时,它默认为yyyy-MM-dd HH:mm:ss.SSS或由配置属性定义的任何内容phoenix.query.dateFormat。配置设置phoenix.query.dateFormatTimeZone也可以设置为时区ID,这将导致使用配置的GMT时区ID覆盖默认设置。此外,Phoenix支持ANSI SQL time类似于单参数TO_TIME函数的字面量。
例:
1 | TO_TIME('2005-10-01 14:03:22.559') |
1 | select TO_TIME('2005-10-01 14:03:22.559'); |

3.3 TO_TIMESTAMP
将给定的字符串转换为TIMESTAMP实例。当不提供日期格式时,它默认为yyyy-MM-dd HH:mm:ss.SSS或由配置属性定义的任何内容phoenix.query.dateFormat。配置设置phoenix.query.dateFormatTimeZone也可以设置为时区ID,这将导致使用配置的GMT时区ID覆盖默认设置。此外,Phoenix支持ANSI SQL timestamp类似于单参数TO_TIMESTAMP函数的字面量。
例:
1 | TO_TIMESTAMP('2005-10-01 14:03:22.559') |
1 | select TO_TIMESTAMP('2005-10-01 14:03:22.559'); |

3.4 CURRENT_TIME
与CURRENT_DATE()相同,except返回类型的值TIME。在任一情况下,底层表示是时间段时间作为长值。请参阅数据类型参考指南,了解Apache Phoenix当前如何定义TIME数据类型。
例:
1 | CURRENT_TIME() |
1 | select CURRENT_TIME(); |

3.5 CONVERT_TZ
将日期/时间从一个时区转换为另一个时区,返回移动的日期/时间值。
例:
1 | CONVERT_TZ(myDate, 'UTC', 'Europe/Prague') |
1 | select CONVERT_TZ(TO_TIME('2005-10-01 14:03:22.559'), 'UTC', 'Europe/Prague'); |

3.6 TIMEZONE_OFFSET
返回特定日期/时间的时区(以分钟为单位)的偏移(以分钟为单位)。
例:
1 | TIMEZONE_OFFSET('Indian/Cocos', myDate) |
1 | select TIMEZONE_OFFSET('Indian/Cocos', TO_TIME('2005-10-01 14:03:22.559')); |

3.7 NOW
返回当前日期,根据拥有正在查询的表的元数据的区域服务器上的当前时间,在查询执行开始时绑定。
例:
1 | NOW() |
1 | select NOW(); |

3.8 YEAR
返回指定日期的年份。
例:
1 | YEAR(TO_DATE('2015-6-05')) |
1 | select YEAR(TO_DATE('2015-6-05')); |

3.9 MONTH
返回指定日期的月。
例:
1 | MONTH(TO_TIMESTAMP('2015-6-05')) |
1 | select MONTH(TO_TIMESTAMP('2015-6-05')); |

3.10 WEEK
返回指定日期的星期。
例:
1 | WEEK(TO_TIME('2010-6-15')) |
1 | select WEEK(TO_TIME('2010-6-15')); |

3.11 DAYOFMONTH
返回指定日期的月份中的某一天。
例:
1 | DAYOFMONTH(TO_DATE('2004-01-18 10:00:10')) |
1 | select DAYOFMONTH(TO_DATE('2004-01-18 10:00:10')); |

3.12 HOUR
返回指定日期的小时。
例:
1 | HOUR(TO_TIMESTAMP('2015-6-05')) |
1 | select HOUR(TO_TIMESTAMP('2015-6-05 12:12:12')); |

3.13 MINUTE
返回指定日期的分钟。
例:
1 | MINUTE(TO_TIME('2015-6-05')) |
1 | select MINUTE(TO_TIMESTAMP('2015-6-05 12:12:12')); |

3.14 SECOND
返回指定日期的第二个。
例:
1 | SECOND(TO_DATE('2015-6-05')) |
1 | select SECOND(TO_TIMESTAMP('2015-6-05 12:13:14')); |

4. 聚合函数
4.1AVG
平均值(平均值)。如果未选择行,则结果为NULL。仅允许在select语句中使用聚合。返回的值与参数的数据类型相同。
例:
1 | AVG() |
1 | select avg(CORE) from WEB_STAT; |

4.2 COUNT
所有行的计数,或非空值的计数。这个方法返回一个long。当DISTINCT使用时,它只计算不同的值。如果未选择任何行,则结果为0.仅在select语句中允许汇总。
例:
1 | COUNT(*) |
1 | select count(CORE) from WEB_STAT; |

4.3 MAX
最高值。如果未选择行,则结果为NULL。仅允许在select语句中使用聚合。返回的值与参数的数据类型相同。
例:
1 | MAX(NAME) |
1 | select max(CORE) from WEB_STAT; |

4.4 MIN
MIN ( term )
最低值。如果未选择行,则结果为NULL。仅允许在select语句中使用聚合。返回的值与参数的数据类型相同。
例:
1 | MIN(NAME) |
1 | select min(CORE) from WEB_STAT; |

4.5 SUM
SUM ( numericTerm )
所有值的总和。如果未选择行,则结果为NULL。仅允许在select语句中使用聚合。返回的值与参数的数据类型相同。
例:
1 | SUM(X) |
1 | select sum(CORE) from WEB_STAT; |

4.6 PERCENTILE_CONT
列中值的第n个百分位数。百分点值可以在0和1之间,包括0和1。仅允许在select语句中使用聚合。返回值为十进制数据类型。
例:
1 | PERCENTILE_CONT( 0.9 ) WITHIN GROUP (ORDER BY X ASC) |
1 | select PERCENTILE_CONT( 0.9 ) WITHIN GROUP (ORDER BY CORE ASC) from WEB_STAT; |

4.7 PERCENTILE_DISC
PERCENTILE_DISC是假定离散分布模型的逆分布函数。它需要百分点值和排序规范,并从集合中返回一个元素。在计算中忽略空值。
例:
1 | PERCENTILE_DISC( 0.9 ) WITHIN GROUP (ORDER BY X DESC) |
1 | select PERCENTILE_DISC( 0.9 ) WITHIN GROUP (ORDER BY CORE DESC) from WEB_STAT; |

4.8 PERCENT_RANK
如果插入列中,则假设值的百分位数。仅允许在select语句中使用聚合。返回值为十进制数据类型。
例:
1 | PERCENT_RANK( 100 ) WITHIN GROUP (ORDER BY X ASC) |
1 | select PERCENT_RANK( 100 ) WITHIN GROUP (ORDER BY CORE ASC) from WEB_STAT; |

4.9 FIRST_VALUE
每个不同组中的第一个值根据ORDER BY规范排序。
例:
1 | FIRST_VALUE( name ) WITHIN GROUP (ORDER BY salary DESC) |
1 | select FIRST_VALUE( CORE ) WITHIN GROUP (ORDER BY CORE DESC) from WEB_STAT; |

4.10 LAST_VALUE
每个不同组中的最后一个值根据ORDER BY规范排序。
例:
1 | LAST_VALUE( name ) WITHIN GROUP (ORDER BY salary DESC) |
1 | select LAST_VALUE( CORE ) WITHIN GROUP (ORDER BY CORE DESC) from WEB_STAT; |

4.11 NTH_VALUE
每个不同组中的第n个值根据ORDER BY规范排序。
例:
1 | NTH_VALUE( name, 2 ) WITHIN GROUP (ORDER BY salary DESC) |
1 | select NTH_VALUE( CORE, 2 ) WITHIN GROUP (ORDER BY CORE DESC) from WEB_STAT; |

4.12 STDDEV_POP
所有值的总体标准偏差。仅允许在select语句中使用聚合。返回值为十进制数据类型。
例:
1 | STDDEV_POP( X ) |
1 | select STDDEV_POP( CORE ) from WEB_STAT; |

4.13 STDDEV_SAMP
所有值的样本标准偏差。仅允许在select语句中使用聚合。返回值为十进制数据类型。
例:
1 | STDDEV_SAMP( X ) |
1 | select STDDEV_SAMP( CORE ) from WEB_STAT; |

5. 数组函数
5.1 ARRAY_ELEM
使用数组下标符号访问数组元素的替代方法。返回在给定位置的数组中的元素。位置是基于1的。
例:
1 | ARRAY_ELEM(my_array_col, 5) |
1 | select ARRAY_ELEM(ARRAY[1,2,3], 3); |

5.2 ARRAY_LENGTH
返回数组的当前长度。
例:
1 | ARRAY_LENGTH(my_array_col) |
1 | select ARRAY_LENGTH(ARRAY[1,2,3]); |

5.3 ARRAY_APPEND
将给定元素追加到数组的末尾。
例:
1 | ARRAY_APPEND(my_array_col, my_element_col) |
1 | select ARRAY_APPEND(ARRAY[1,2,3], 4); |

5.4 ARRAY_PREPEND
将给定元素追加到数组的开头。
例:
1 | ARRAY_PREPEND(my_element_col, my_array_col) |
1 | select ARRAY_PREPEND(0, ARRAY[1,2,3]) ; |

5.5 ARRAY_CAT
连接输入数组并返回结果。
例:
1 | ARRAY_CAT(my_array_col1, my_array_col2) |
1 | select ARRAY_CAT(ARRAY[1,2], ARRAY[3,4]); |

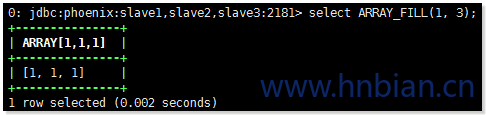
5.6 ARRAY_FILL
返回使用提供的值和长度初始化的数组。
例:
1 | ARRAY_FILL(my_element_col, my_length_col) |
1 | select ARRAY_FILL(1, 3); |
5.7 ARRAY_TO_STRING
使用提供的定界符和可选的空字符串连接数组元素,并返回结果字符串。如果省略了nullString参数,或者NULL简单地跳过数组中的任何空元素,并且不在输出字符串中表示。
例:
1 | ARRAY_TO_STRING(my_array_col, my_delimiter_col, my_null_string_col) |
1 | select ARRAY_TO_STRING(ARRAY['a','b',null,'c'], ',', 'NULL'); |

5.8 ANY
用于比较表达式的右侧,以测试任何数组元素是否满足左侧的比较表达式。
例:
1 | 1 = ANY(my_array) |
1 | select 10 > ANY(ARRAY[1,2,3]) as result; |

1 | select 10 > ANY(ARRAY[11,21,13]) as result; |

5.9 ALL
用于比较表达式的右侧,以测试所有数组元素是否满足左侧的比较表达式。的数组。
例:
1 | 1 = ALL(my_array) |
1 | select 10 > ALL(ARRAY[1,2,3]) as result; |

1 | select 10 > ALL(ARRAY[12,2,3,9]) as result; |

6. 数学函数
6.1 SIGN
返回给定数字表达式的signum函数INTEGER。如果给定的数字表达式为负,返回值为-1; 0,如果给定的数字表达式为零; 如果给定的数值表达式为正,则为1。
例:
1 | SIGN(number) |
1 | select SIGN(24); |

6.2 ABS
返回保持相同类型的给定数值表达式的绝对值。
例:
1 | ABS(number) |
1 | select ; |

6.3 SQRT
将给定非负数值表达式的正确倒圆的平方根返回为a DOUBLE。
例:
1 | SQRT(number) |
1 | select SQRT(1.1); |

6.4 CBRT
将给定数值表达式的多维数据集根返回为DOUBLE。
例:
1 | CBRT(number) |
1 | select CBRT(-1); |

6.5 EXP
返回欧拉数e增加到给定数值的权力为a DOUBLE。
例:
1 | EXP(number) |
1 | select EXP(-1); |

6.6 POWER
返回第一个参数的值为第二个参数的幂的a DOUBLE。
例:
1 | POWER(number, number) |
1 | select POWER(2, 3); |

6.7 LN
返回给定正表达式的自然对数(基e)DOUBLE。
例:
1 | LN(number) |
1 | select LN(2); |

6.8 LOG
返回在第二个参数的底部计算的第一个参数的对数为a DOUBLE。如果省略,基数为10将用于第二个参数。
例:
1 | LOG(3, 2) |
1 | select LOG(2); |

7. 其他函数
7.1 MD5
计算MD5参数的哈希值,将结果作为BINARY(16)返回。
例:
1 | MD5(my_column) |
1 | select MD5(123) as result; |

7.2 INVERT
反转参数的位。返回类型将与参数相同。
例:
1 | INVERT(my_column) |
1 | select INVERT(123) as result; |

7.3 ENCODE
根据提供的编码格式编码表达式,并返回结果字符串。对于’ BASE62’,将给定的基数10数字转换为基数62数字,并返回一个表示数字的字符串。
例:
1 | ENCODE(myNumber, 'BASE62') |
1 | select ENCODE(123456, 'BASE62') as result; |

7.4 DECODE
根据提供的编码格式解码表达式,并将结果值返回为VARBINARY。对于’ HEX’,将十六进制字符串表达式转换为其二进制表示形式,提供通过控制台输入二进制数据的机制。
例:
1 | DECODE('000000008512af277ffffff8', 'HEX') |
1 | select DECODE('000000008512af277ffffff8', 'HEX') as result; |

7.5 COALESCE
返回第一个参数的值(如果不为空)和第二个参数的值。用于确保UPSERT SELECT命令中的列将求值为非空值。
例:
1 | COALESCE(last_update_date, CURRENT_DATE()) |
1 | select COALESCE('b', 'a'); |

7.6 GET_BIT
在给定的二进制值中检索给定索引处的位。
例:
1 | GET_BIT(CAST('FFFF' as BINARY), 1) |
1 | Select GET_BIT(CAST('FFFF' as BINARY), 1); |

7.7 GET_BYTE
在给定的二进制值中检索给定索引处的字节。
例:
1 | GET_BYTE(CAST('FFFF' as BINARY), 1) |
1 | select GET_BYTE(CAST('FFFF' as BINARY), 1); |

7.8 OCTET_LENGTH
返回二进制值中的字节数。
例:
1 | OCTET_LENGTH(NAME) |
7.9 SET_BIT
将二进制值中给定索引处的位替换为提供的newValue。
例:
1 | SET_BIT(CAST('FFFF' as BINARY), 1, 61) |
1 | SELECT SET_BIT(CAST('FFFF' as BINARY), 1, 61) AS RESULT; |

7.10 SET_BYTE
将二进制值中给定索引处的字节替换为提供的newValue。
例:
1 | SET_BYTE(CAST('FFFF' as BINARY), 1, 61) |
1 | SELECT SET_BYTE(CAST('FFFF' as BINARY), 1, 61) AS RESULT; |


