1. Flink Checkpoint
1.1 Checkpoint 介绍
- Flink Checkpoint 是容错恢复机制的核心。这种机制保证了保证实时程序运行时的数据安全,即使突然遇到异常也能够进行自我恢复。
- Flink Checkpoint 机制保证 Flink 任务运行突然失败时,能够从最近 Checkpoint 进行状态恢复启动,进行错误容忍。它是一种自动容错机制,而不是具体的状态存储镜像。
- Flink Checkpoint 是 Flink 自身的系统行为。对于用户来说是透明的,用户会感觉程序一直在运行,但用户无法对其进行交互。
- 用户需要在程序启动之前,设置好实时程序 Checkpoint 相关参数,当程序启动之后,剩下的就全交给 Flink 自行管理。
- 当程序在已经失败,进程挂掉时 Checkpoint 机制不能恢复状态,如Flink On Yarn 模式,某个 Container 发生 OOM 异常,这种情况程序直接变成失败状态,此时 Flink 程序虽然开启 Checkpoint 也无法恢复,因为程序已经变成失败状态,所以此时可以借助外部参与启动程序,比如外部程序检测到实时任务失败时,从新对实时任务进行拉起。
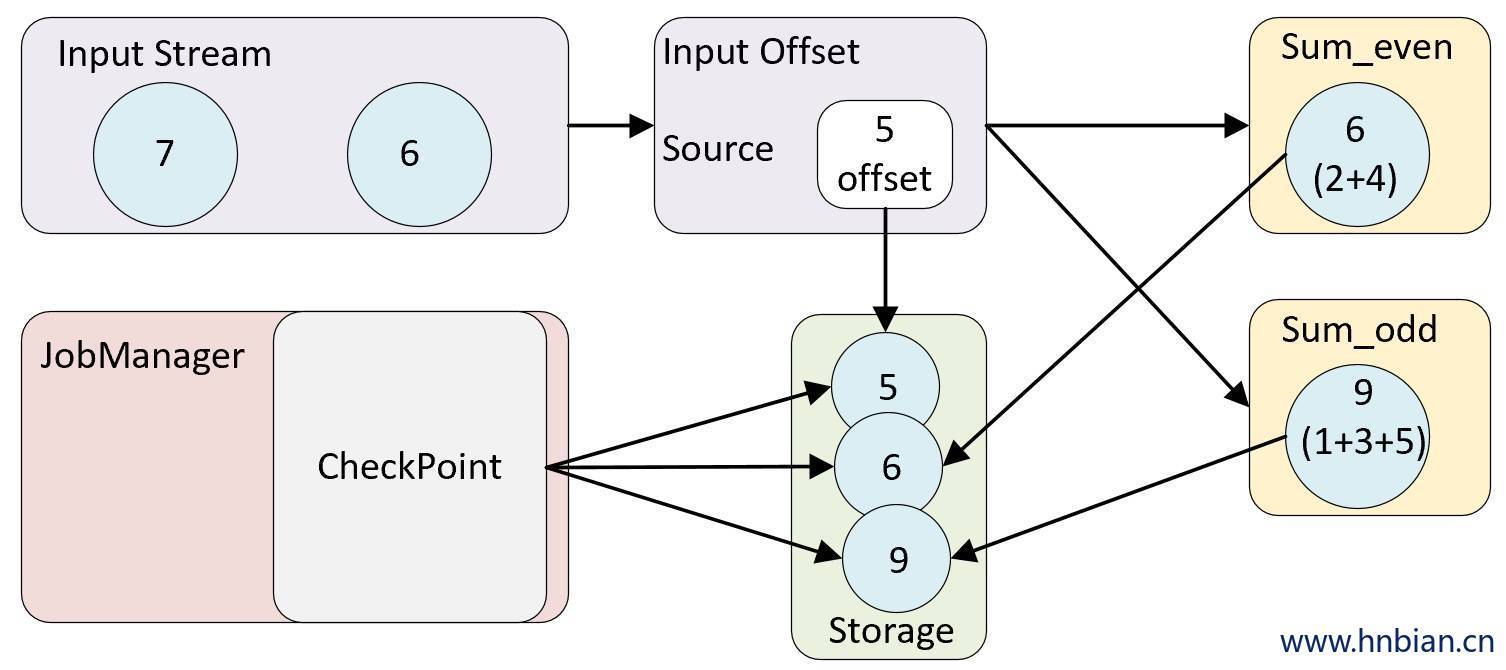
1.2 Checkpoint 与 State 的关系
State 是 Checkpoint 所做的主要持久化备份的主要数据,而 Checkpoint 是从 source 触发到下游所有节点完成的一次全局操作。
1.3 Checkpoint 的实现算法
基于 Chandy-Lamport 算法的分布式快照
将检查点的保存和数据处理分开,不暂停整个应用
检查点分界线(Checkpoint Barrier)
- Flink 的检查点算法用到了一种为分界线(barrier)的特殊数据形式,用来把一条流上的数据按照不同的检查点分开
- Flink 会定时在任务的 Source Task 触发 barrier,barrier是一种特殊的消息事件,会随着消息通道流入到下游的算子中
- barrier 之前到来的数据导致的状态更改,都会被包含在当前 barrier 所属的检查点中
- barrier 之后的数据导致的所有更改,就会被包含在之后的检查点中
- 在某些算子的 Task 有多个输入时,会存在 Barrier 对齐时间,我们可以在Web UI上面看到各个 Task 的Barrier 对齐时间
- 只有当最后 Sink 端的算子接收到 Barrier 并确认该次 Checkpoint 完成时,该次 Checkpoint 才算完成
1.4 Checkpoint 原理与实现过程
默认情况下,Checkpoint 并发为 1,当系统中有正在进行的 Checkpoint 操作时,不会重复触发Checkpoint 操作
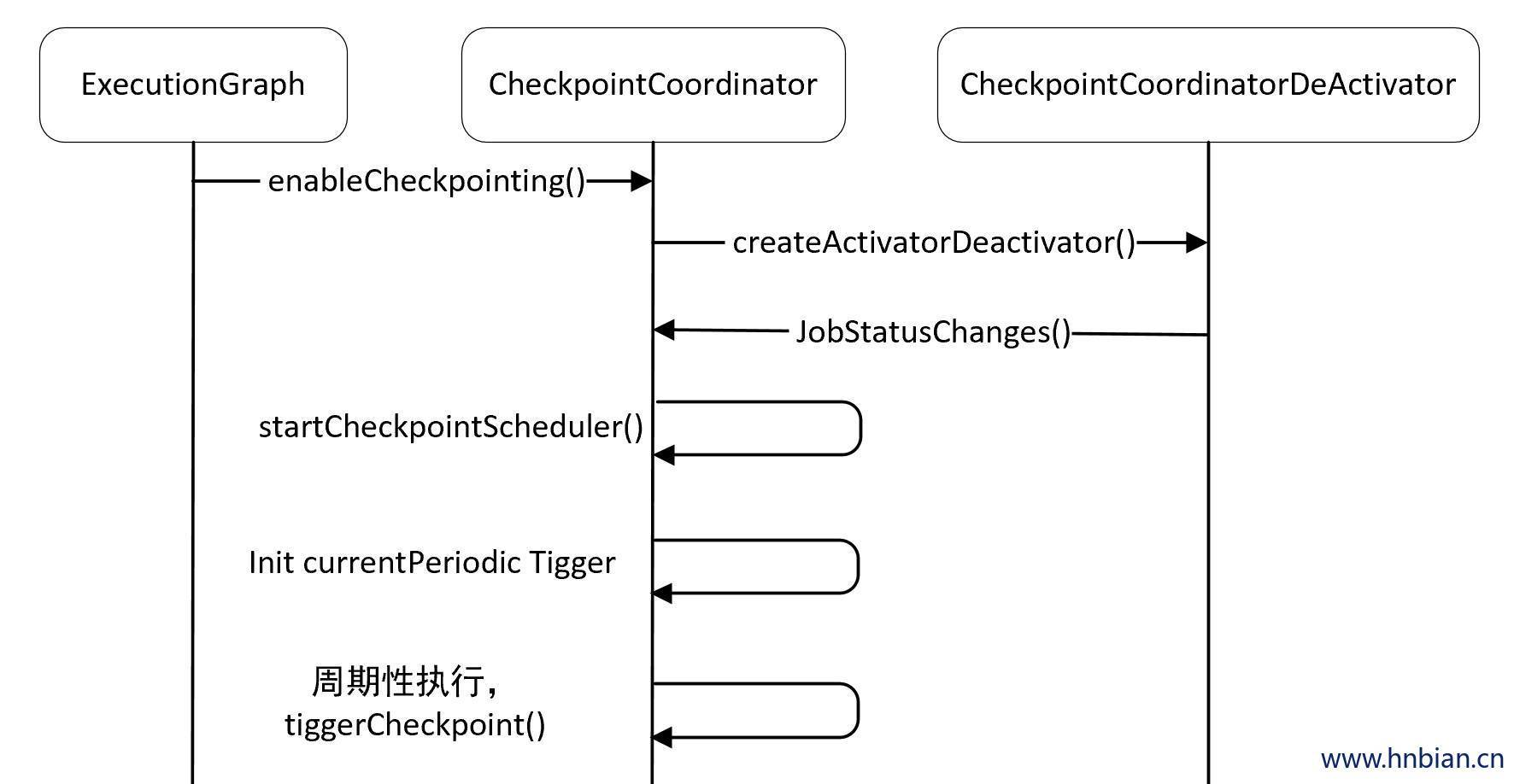
针对 Flink DataStream 任务,程序需要经历从 StreamGraph -> JobGraph -> ExecutionGraph -> 物理执行图四个步骤,
- 其中在 ExecutionGraph 构建时,会初始化 CheckpointCoordinator。
- ExecutionGraph通过ExecutionGraphBuilder.buildGraph方法构建,在构建完时,会调用 ExecutionGraph 的enableCheckpointing方法创建CheckpointCoordinator。
- CheckpoinCoordinator 是 Flink 任务 Checkpoint 的关键,针对每一个 Flink 任务,都会初始化一个 CheckpointCoordinator 类,来触发 Flink 任务 Checkpoint。
1.4.1 checkpoint 状态保留模式
Checkpoint 保存的状态在程序取消时,默认会进行清除保存的状态数据。Checkpoint 状态保留策略有两种,用户可以结合业务情况,设置 Checkpoint 保留模式。
| 模式 | 说明 |
|---|---|
| DELETE_ON_CANCELLATION | 表示当程序取消时,删除 Checkpoint 存储文件 |
| RETAIN_ON_CANCELLATION | 表示当程序取消时,保存之前的 Checkpoint 存储文件 |
1.4.2 checkpoint 执行过程
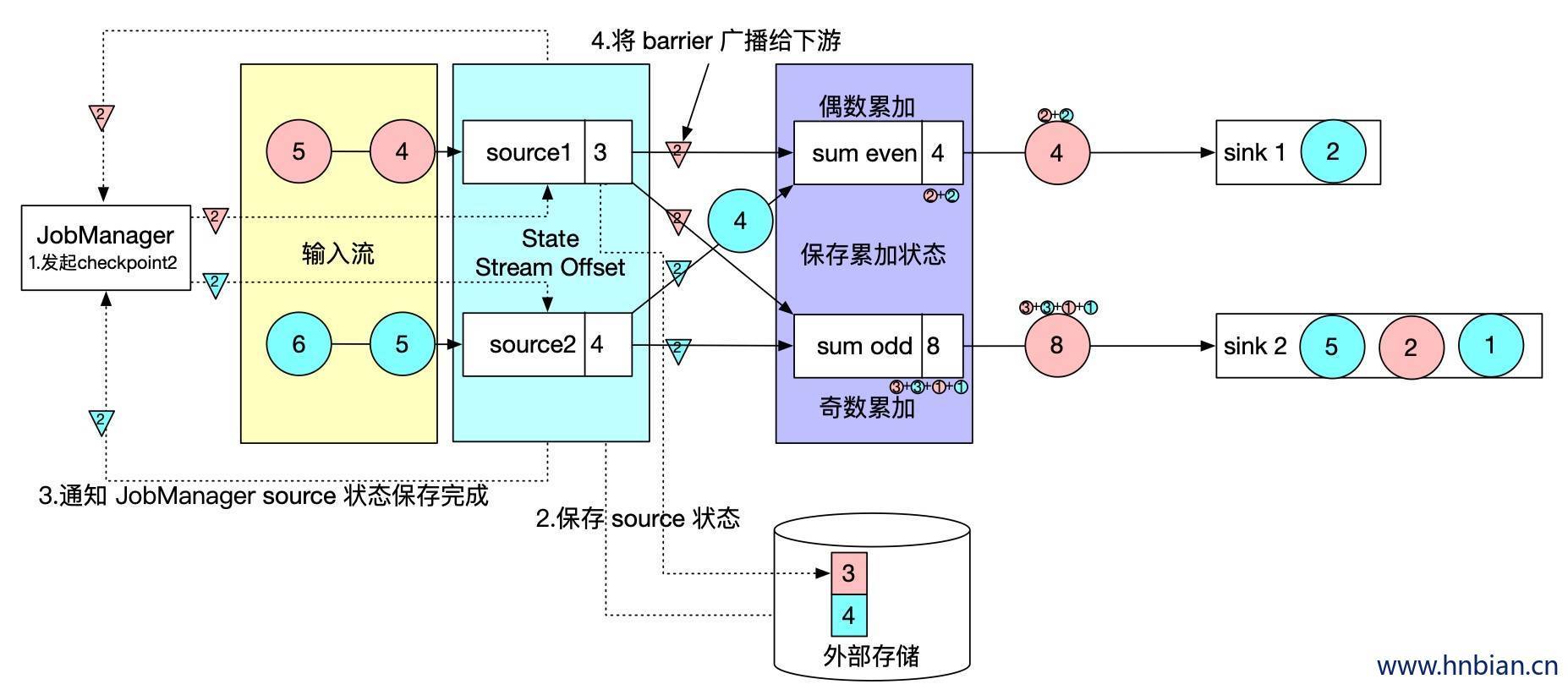
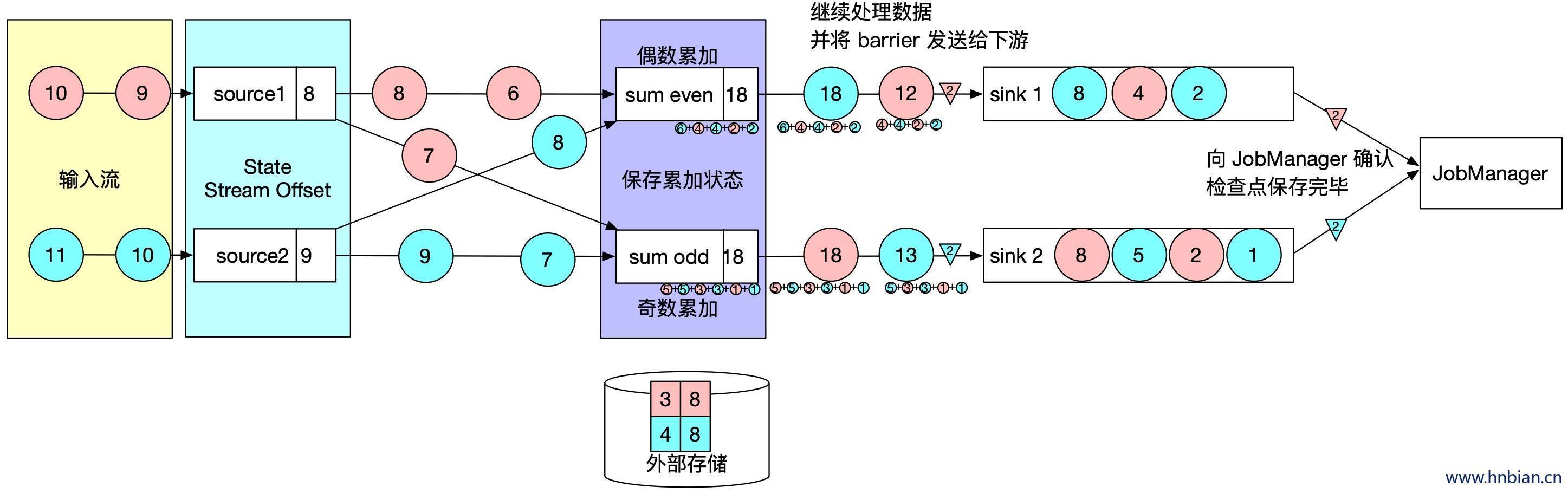
- 下图是一个有两个输入流的应用程序,用并行的两个 source 获取数据,并将结果写到两个sink中。
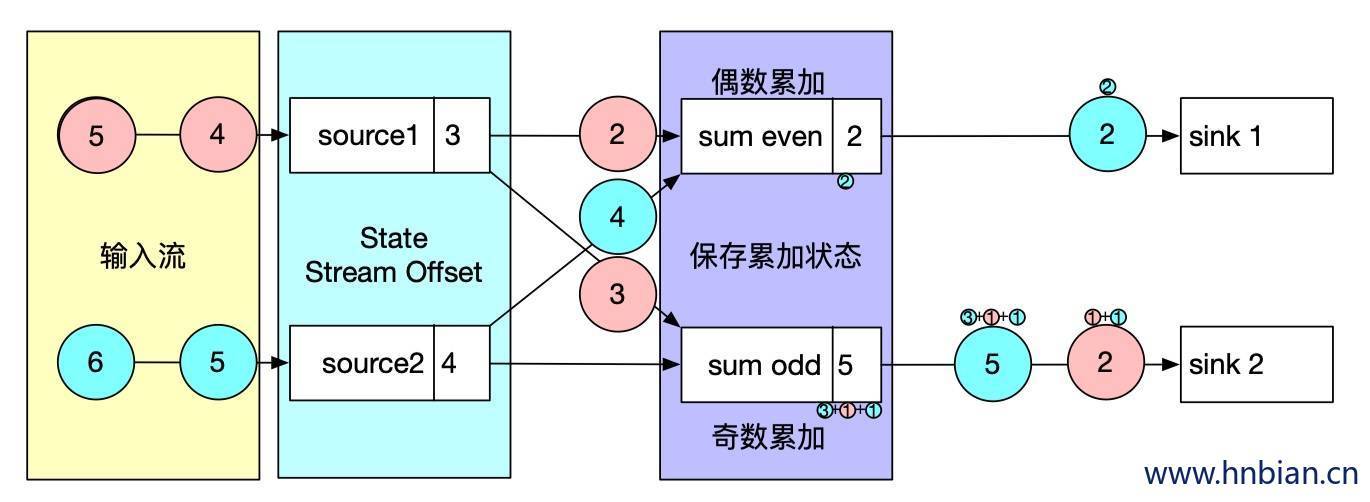
- 增加Barrier,JobManager 会向每个 source 任务发送带有新检查点 ID 的消息,通过这种方式来启动检查点
- 状态写入,数据源将他们的状态写入检查点,并发出一个检查点 barrier,状态后端在状态存入检查点以后,会发送通知带 source 任务,source 任务就会想 JobManager 确认检查点完成。
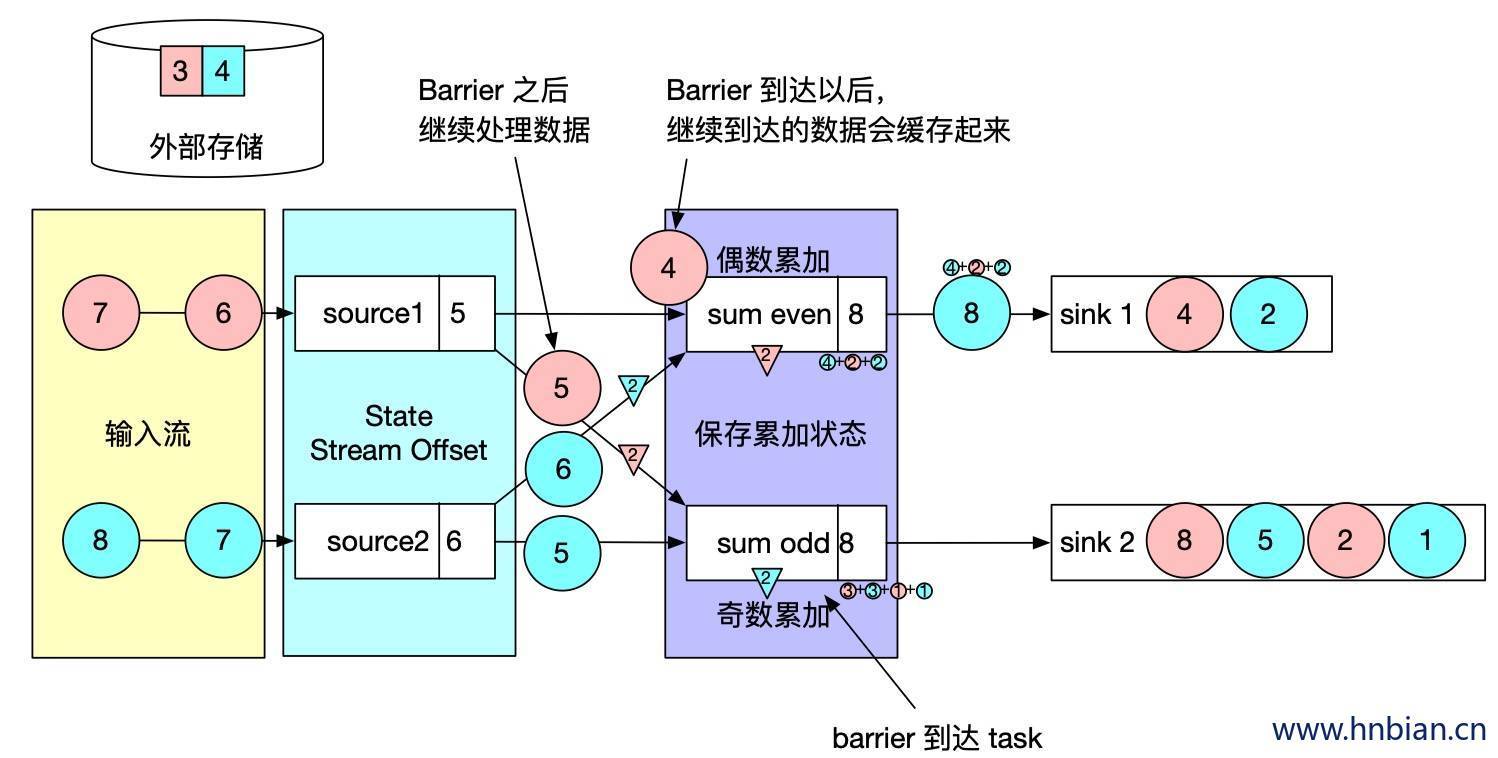
- barrier 对齐,barrier 向下游传递,sum 任务会等待所有输入分区的 barrier 到达,对于 barrier 已经到达的分区,继续到达地的数据会被缓存,而 barrier 尚未到达的分区,数据会被正常处理
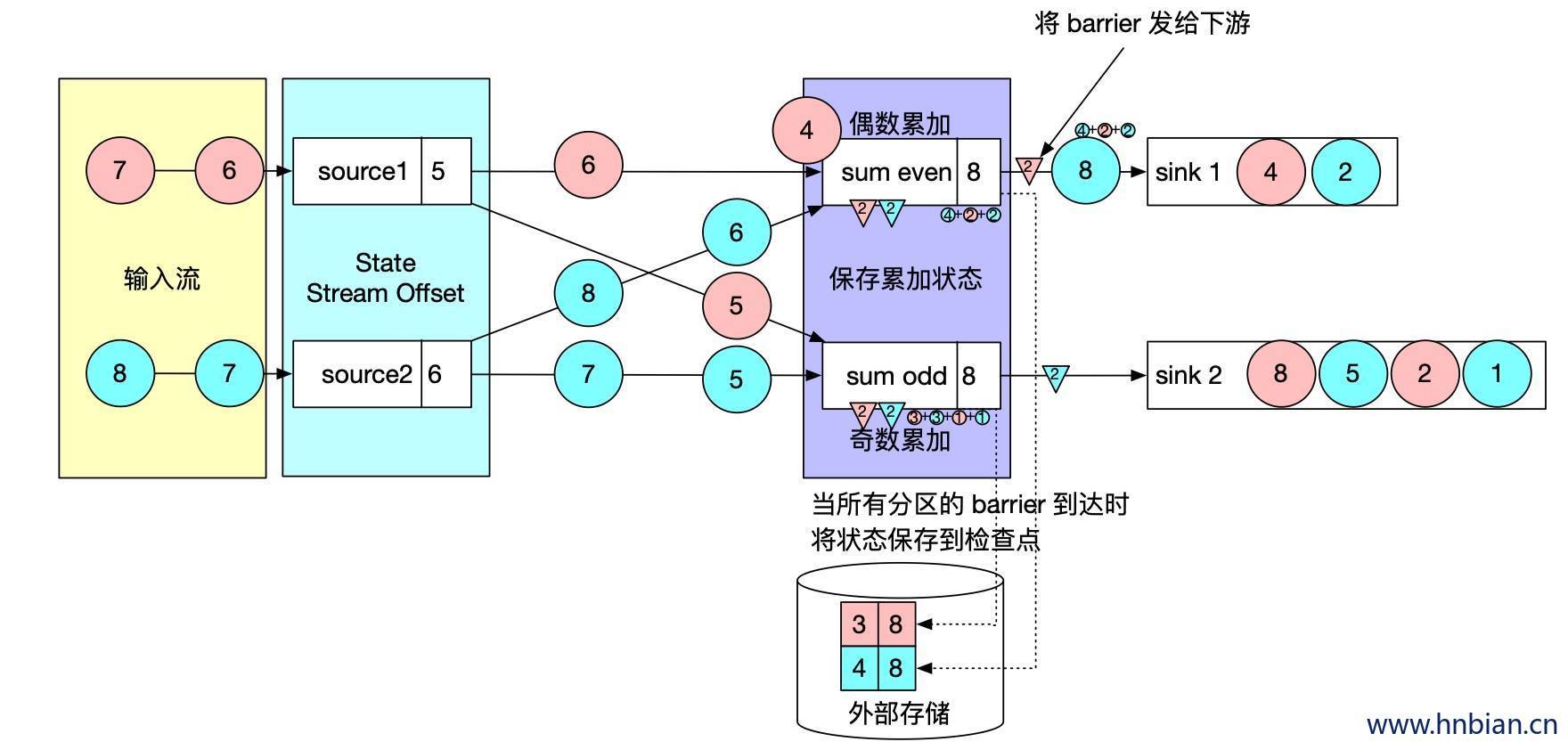
- 当收到所有输入分区的 barrier 时,任务就将其状态保存到状态后端的检查点中,然后将 barrier 继续向下游转发。
- 向下游转发检查点 barrier 后,任务继续正常的数据处理
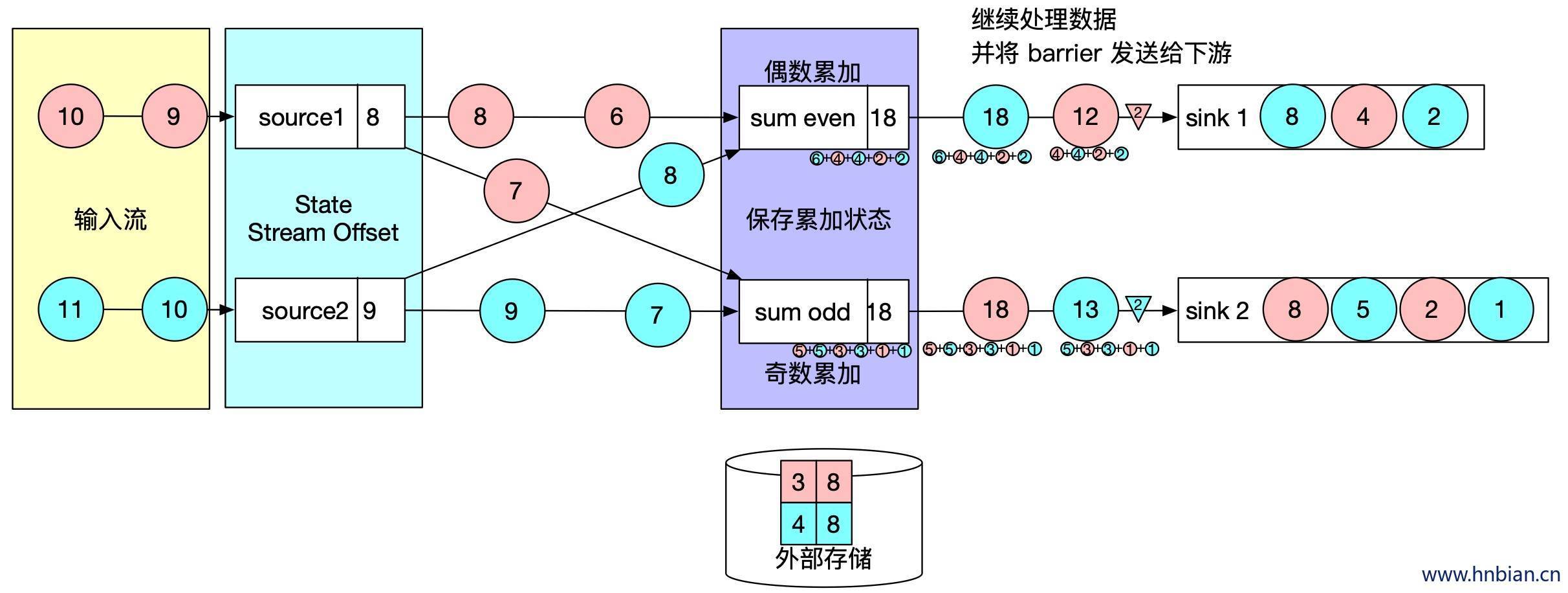
- Sink 任务向 JobManager 确认状态保存到 checkpoint 完毕,当所有任务都确认已成功将状态保存到检查点时,检查点操作就真正完成了。
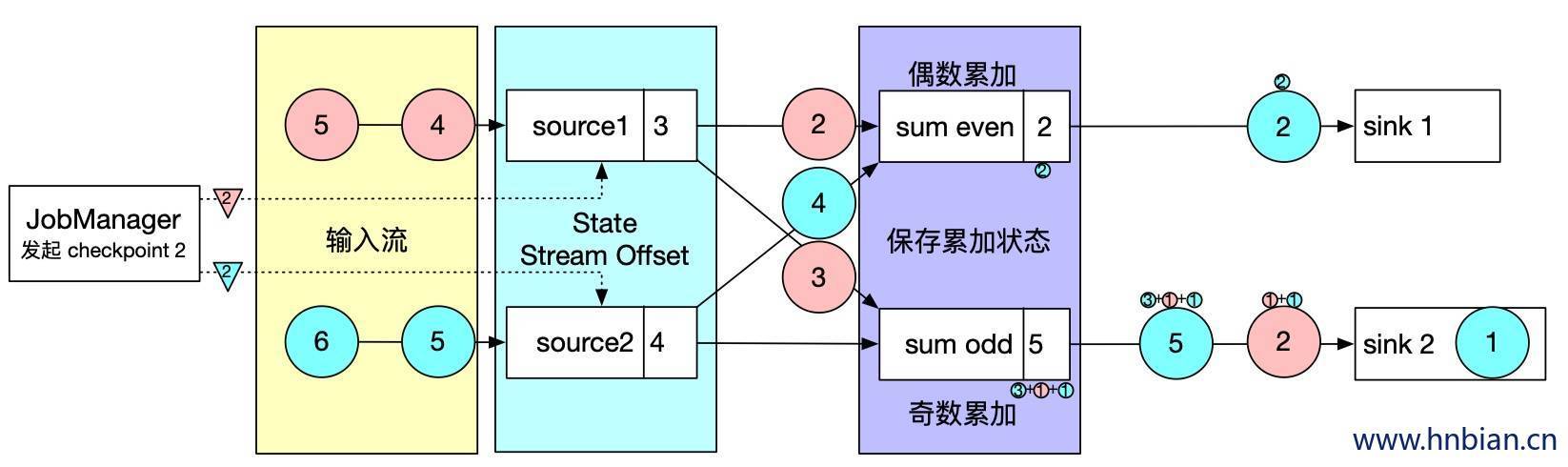
1.4.3 从 checkpoint 恢复状态过程
在执行流应用程序期间,flink 会定期保存状态一致性的检查点。
如果发生故障,Flink 将会使用最近的检查点来恢复应用程序的状态,并重新启动处理流程
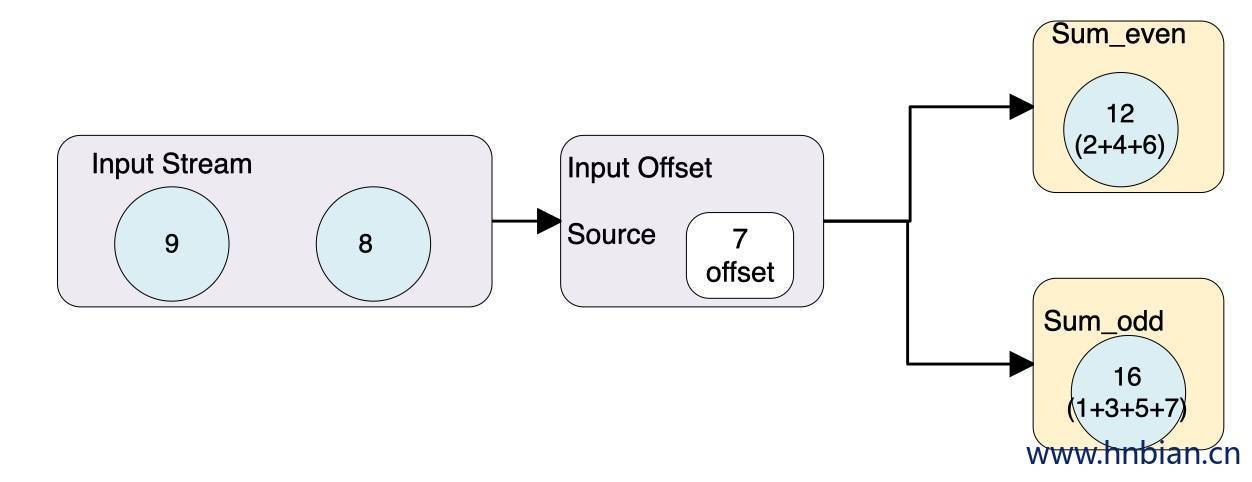
当 offset 为 7 的数据发生故障时 恢复故障步骤 如下:
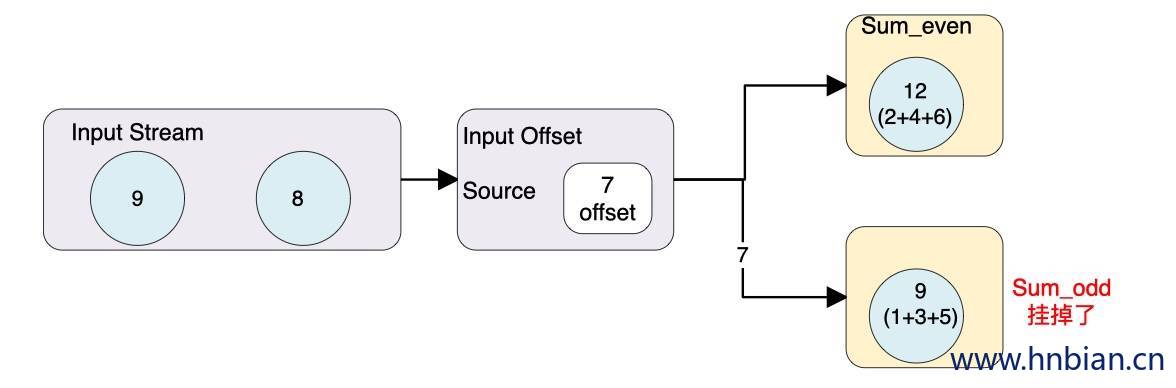
- 重启应用
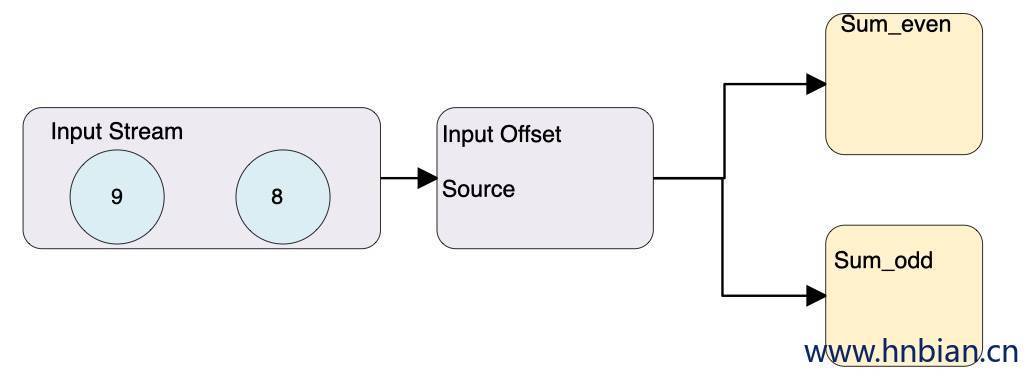
- 从检查点恢复状态,从 checkpoint 中读取状态,将状态重置,从检查点重新启动应用程序后,其内部状态与检查点完成时的状态完全相同
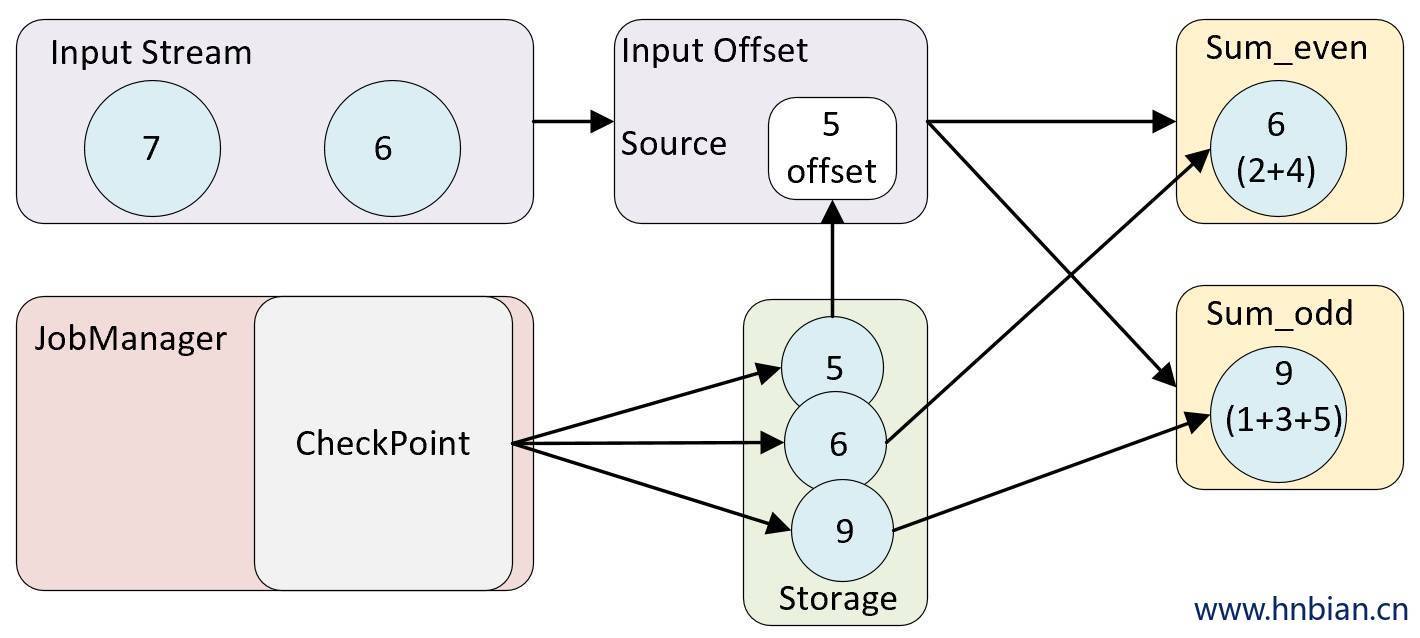
- 继续处理数据,开始消费并处理检查点到发生故障之间的所有数据
这种检查点的保存和恢复机制可以为应用程序提供“精确一次”(Exactly-once)的一致性,因为所有的算子都会保存检查点并恢复所有的状态,这样所有的输入流都会被重置到检查点完成时的位置
1.5 Checkpoint 语义
Flink Checkpoint 支持两种语义:Exactly Once 和 **At least Once,**默认的 Checkpoint 模式是 Exactly Once。
Exactly Once 和 At least Once 具体是针对 Flink 状态 而言。具体语义含义如下:
| 语义 | 说明 |
|---|---|
| Exactly Once | 每条数据只处理 1 次,既不会多也不会少 |
| At Least Once | 每条数据至少处理 1 次,不会漏掉数据,但有可能会重复消费数据 |
Flink 中 Exactly Once 和 At Least Once 具体是针对 Flink 任务 状态 而言的,并不是 Flink 程序对其处理一次。举个例子,当前 Flink 任务正在做 Checkpoint,该次Checkpoint还么有完成,该次 Checkpoint 时间端的数据其实已经进入 Flink 程序处理,只是程序状态没有最终存储到远程存储。当程序突然遇到异常,进行容错恢复,那么就会从最新的 Checkpoint 进行状态恢复重启,上一部分还会进入 Flink 系统处理:
如当前已经进行过一次 checkpoint 操作,但是在下次进行 checkpoint 之前出现异常,那么会从前一次 checkpoint 进行恢复数据,已经处理的这部分数据会再处理一次,因为状态恢复到前一次 checkpoint 状态,所以不会影响最终结果的正确性。
Exactly Once 和 At Least Once 具体在底层实现大致相同,具体差异表现在 Barrier 对齐方式处理:
| 语义 | 处理 barrier 方式 |
|---|---|
| Exactly Once | 某个算子的 Task 有多个输入通道时,当其中一个输入通道收到 Barrier 时,Flink Task 会阻塞处理该通道,其不会处理这些数据,但是会将这些数据存储到内部缓存中,一旦完成了所有输入通道的 Barrier 对齐,才会继续对这些数据进行消费处理。 |
| At Least Once | 同样针对某个算子的 Task 有多个输入通道的情况下,当某个输入通道接收到 Barrier 时,At Least Once 会继续处理接受到的数据,即使没有完成所有输入通道 Barrier 对齐。所以使用At Least Once 不能保证数据对于状态计算只有一次影响。 |
1.6 Checkpoint 参数配置
Checkpoint 其他的属性包括:
| 配置项 | 说明 |
|---|---|
| exactly-once 和 at-least-once | 通过向 enableCheckpointing(long interval, CheckpointingMode mode) 方法传入一个模式来选择 exactly-once(精确一次)或 at-least-once(至少一次)这两种保证等级中的一个。对于大部分应用来说,精确一次是更好的选择,因为它能确保数据的准确性和一致性。而至少一次的保证等级可能与那些对延迟要求极高(持续在几毫秒以下)的应用场景有关,它能在保证数据至少被处理一次的同时,尽可能地减小处理延迟。 |
| checkpoint 超时 | 如果 checkpoint 执行的时间超过了该配置的阈值,还在进行中的 checkpoint 操作就会被抛弃。 |
| checkpoints 之间的最小时间 | 属性定义了两个 checkpoint 之间所需的最小时间间隔,以确保流应用程序能够在 checkpoint 过程中取得足够的进展。如果将该属性设置为 5000 毫秒(5 秒),则无论 checkpoint 的持续时间和间隔设置为多长,下一个 checkpoint 只有在前一个 checkpoint 完成后至少过去 5 秒后才会开始。通过配置”checkpoints 之间的最小时间”属性,可以更轻松地调整应用程序的配置,而无需考虑具体的 checkpoint 间隔。该属性的设置不会受到 checkpoint 执行时间超过平均值的影响,因此即使目标存储系统突然变慢,也不会影响 checkpoint 的触发时间。 |
| 并发 checkpoint 的数目 | 默认情况下,在上一个 checkpoint 尚未完成(无论是失败还是成功)之前,系统不会触发另一个 checkpoint。这样可以确保拓扑不会花费过多时间在 checkpoint 上,从而不影响正常的处理流程。然而,允许多个 checkpoint 并行进行是可行的。这对于某些具有确定的处理延迟(例如调用耗时较长的外部服务的方法)但仍希望进行频繁 checkpoint 的 pipeline 来说是有意义的,因为这可以最小化故障后的重启时间。该选项不能和 “checkpoints 间的最小时间”同时使用。 |
| externalized checkpoints | 在 Flink 中,你可以配置周期性地将 checkpoint 存储到外部系统中,这就是外部化检查点(Externalized Checkpoints)。外部化检查点会将它们的元数据写入持久性存储,并且在作业失败时不会被自动删除。这意味着,如果你的作业发生故障,你可以使用现有的检查点进行恢复。你可以在 Externalized Checkpoints 的部署文档 中找到更多的细节。 |
| 异常选项 | 在 checkpoint 过程中出现错误时,可以选择使任务失败或继续进行任务。这个选项决定了在任务执行 checkpoint 过程中发生错误时的行为,默认情况下是使任务失败。当禁用该选项时,任务将简单地将 checkpoint 错误信息报告给 checkpoint coordinator 并继续正常运行。 |
| 优先恢复 | 优先从 checkpoint 进行恢复(Prefer Checkpoint for Recovery):该属性决定作业在进行恢复时是否优先选择最新的 checkpoint,即使存在更新的 savepoint。这样做可以潜在地减少恢复时间,因为从 checkpoint 恢复的速度比从 savepoint 恢复的速度更快。 |
1 | // 每 1000ms 开始一次 checkpoint |
更多的属性与默认值能在 conf/flink-conf.yaml 中设置(完整教程请阅读 配置)。
| 属性 | 默认值 | 类型 | 描述 |
|---|---|---|---|
| state.backend | (none) | String | 用于保存checkpoint 状态的后端存储 |
| state.backend.async | true | Boolean | 选择状态后端是否使用异步快照。 FsStateBackend 默认使用异步快照 MemoryStateBackend 可以配置异步快照 RocksDBStateBackend 只支持异步快照 |
| state.backend.fs.memory-threshold | 20 kb | MemorySize | 状态数据文件的最小值。所有小于该状态的状态块都以内联方式存储在根检查点元数据文件中。此配置的最大内存阈值为1MB。 |
| state.backend.fs.write-buffer-size | 4096 | Integer | 写入文件系统的检查点流的写缓冲区的默认大小。实际的写缓冲区大小确定为该选项和选项“ state.backend.fs.memory-threshold”的最大值。 |
| state.backend.incremental | false | Boolean | 选择状态后端是否应创建增量检查点。对于增量检查点,仅存储与前一个检查点的差异,而不存储完整的检查点状态。启用后,Web UI中显示的状态大小或从rest API获取的状态大小仅表示增量检查点大小,而不是完整的检查点大小。 FsStateBackend 不支持增量快照 MemoryStateBackend 不支持增量快照 RocksDBStateBackend 支持增量快照 |
| state.checkpoints.dir | (none) | String | Flink 支持的文件系统中用于存储检查点的数据文件和元数据的默认目录。存储路径必须对所有参与的进程/节点(即所有 TaskManagers 和 JobManagers)可访问。 |
| state.checkpoints.num-retained | 1 | Integer | 保留的已完成检查点的个数 |
| state.savepoints.dir | (none) | String | 保存点的默认目录。由状态后端用于将保存点写入文件系统(MemoryStateBackend,FsStateBackend,RocksDBStateBackend)。 |
| taskmanager.state.local.root-dirs | (none) | String | 定义用于存储基于文件的状态以进行本地恢复的根目录。本地恢复当前仅涵盖键控状态后端。MemoryStateBackend目前不支持本地恢复,请忽略此选项 |
| state.backend.local-recovery | false | Boolean | 使用 checkpoint 恢复状态时,是否使用本地状态后端。默认情况下false。 |
当 Checkpoint 时间比设置的 Checkpoint 间隔时间要长时,可以设置 Checkpoint 间最小时间间隔 。这样在上次 Checkpoint 完成时,不会立马进行下一次 Checkpoint,而是会等待一个最小时间间隔,然后在进行该次 Checkpoint。否则,每次 Checkpoint 完成时,就会立马开始下一次 Checkpoint,系统会有很多资源消耗 Checkpoint。
如果Flink状态很大,在进行恢复时,需要从远程存储读取状态恢复,此时可能导致任务恢复很慢,可以设置 Flink Task 本地状态恢复。任务状态本地恢复默认没有开启,可以设置参数
state.backend.local-recovery值为true进行激活。Checkpoint保存数,Checkpoint 保存数默认是1,也就是保存最新的 Checkpoint 文件,当进行状态恢复时,如果最新的Checkpoint文件不可用时(比如HDFS文件所有副本都损坏或者其他原因),那么状态恢复就会失败,如果设置 Checkpoint 保存数2,即使最新的Checkpoint恢复失败,那么Flink 会回滚到之前那一次Checkpoint进行恢复。考虑到这种情况,用户可以增加 Checkpoint 保存数。
1.7 checkpoint 代码示例
1 | import com.hnbian.flink.common.Obj1 |
1.8 Checkpoint 目录结构
运行完前面的代码之后,我们可以看一下在文件系统中经过 checkpoint 操作之后存储的状态的文件目录的结构
1 | /user-defined-checkpoint-dir |
1.9 使用 Checkpoint 恢复程序状态示例
- 编写代码
1 | import java.lang |
- 启动 Flink 集群,将代码打包提交任务到 flink 集群,然后查看结果
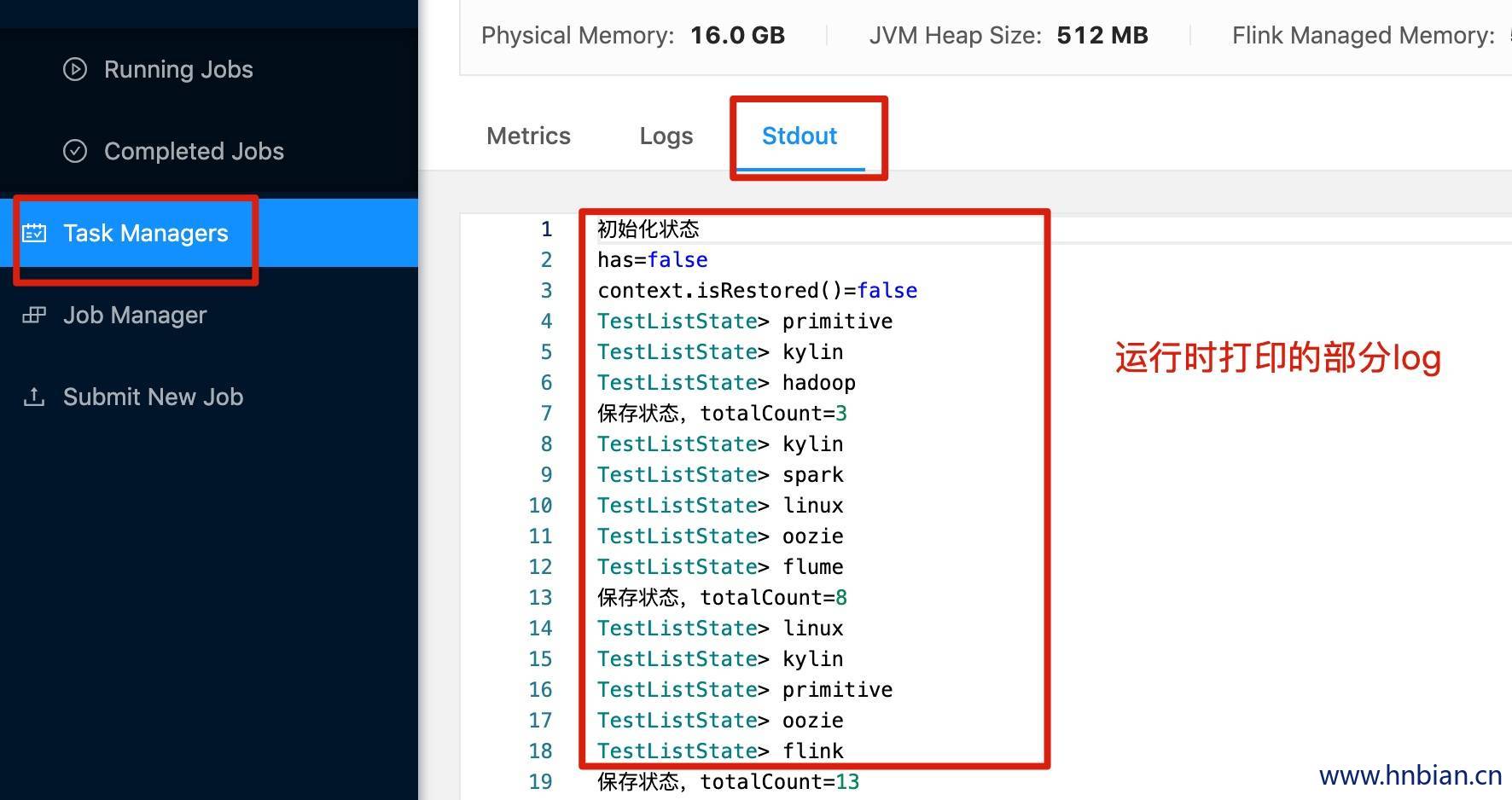
- 查看打印的日志
- 查看 checkpoint 保存的状态数据
1 | hnbiandeMacBook-Pro:~ hnbian$ cd /opt/flink-1.10.2/checkpoint/9a4163a1d00b4ed51a4387c2bd341d72/ |
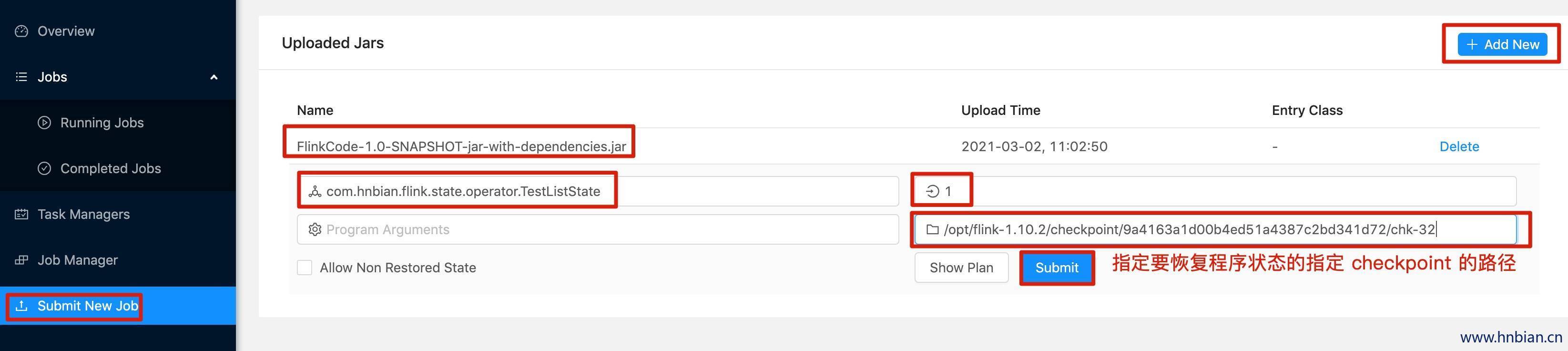
- 关闭程序,并从 checkpoint 恢复程序状态
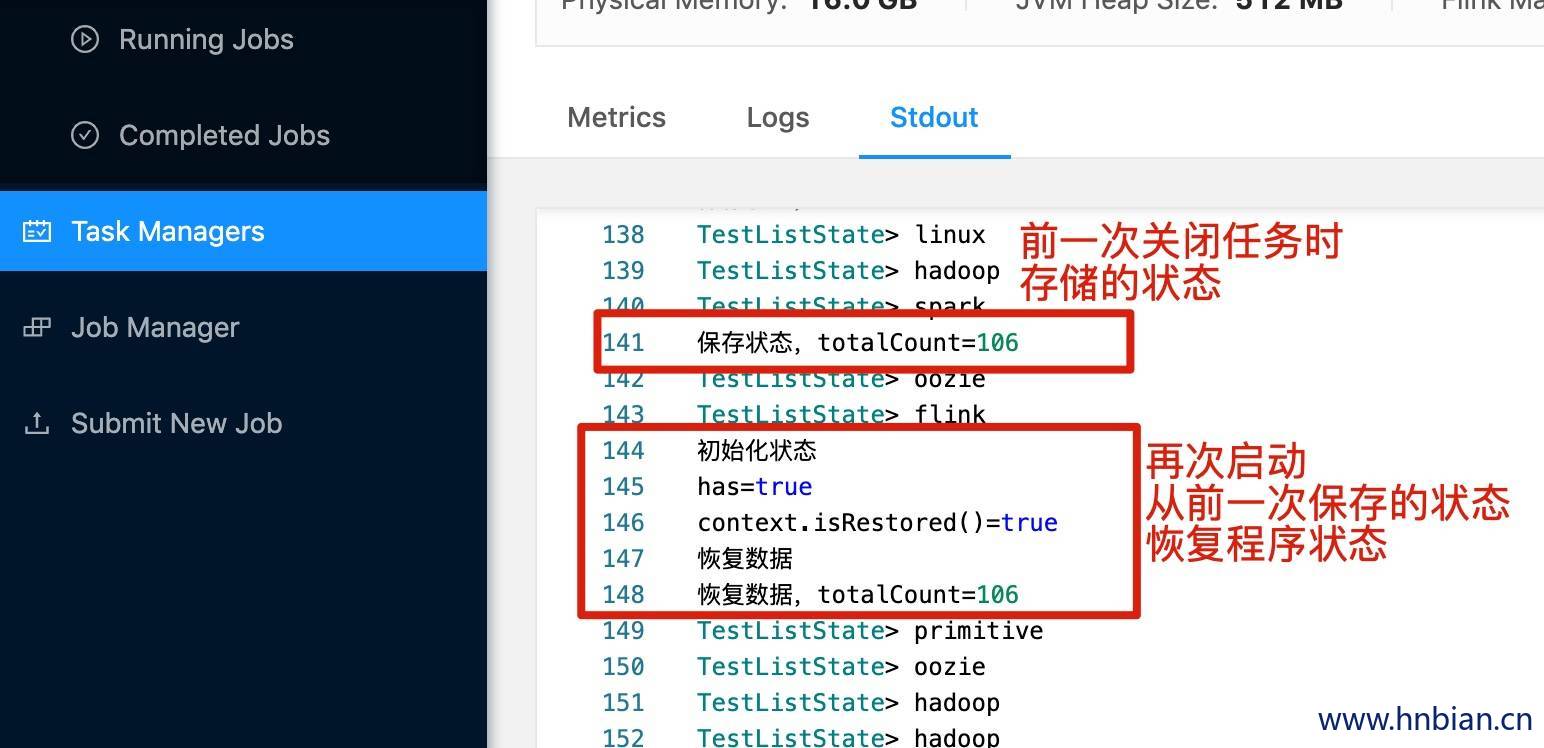
2. Flink SavePoint
2.1 Savepoint 介绍
- 可以认为 Flink Savepoint 是某个时间点程序状态全局镜像,除了故障恢复之外,保存点还可以用于有计划的手动备份,更新应用程序,版本迁移,暂停和重启应用等
- 保存点是一个强大的功能,
- Savepoint 是依据 Flink checkpointing 机制 所创建的流作业执行状态的一致镜像。
- Savepoint 由两部分组成:
- 稳定存储:稳定存储上( HDFS,S3,…) 包含二进制文件的目录文件表示作业执行状态的数据镜像,通常会很大。
- 元数据文件:Savepoint 的元数据文件以(绝对路径)的形式包含(主要)指向作为 Savepoint 一部分的稳定存储上的所有文件的指针,相对较小。
- 可以使用命令行客户端来触发 Savepoint,触发 Savepoint 并取消作业,从 Savepoint 恢复,以及删除 Savepoint。
- 从 Flink 1.2.0 开始,还可以使用 webui 从 Savepoint 恢复。
2.2 分配算子 ID
如果打算使用 Savepoint ,建议在开发程序阶段通过 uid(String) 方法手动指定算子 ID,因为只要这些 ID 不变,就可以从 Savepoint 自动恢复。生成的 ID 取决于程序的结构,并且对程序更改很敏感。因此,强烈建议手动分配这些 ID
假如在修改作业时,即使导致程序拓扑图改变,由于相关算子 ID没有变,那么这些算子还能够继续使用之前的状态。
如果不手动指定 ID ,则会自动生成 ID 。如果用户修改了程序,可能导致之前的状态程序不能再进行复用。。
1 | // 手动指定 ID 示例 |
2.2.1 Savepoint 算子 ID 状态
你可以将 Savepoint 想象为每个有状态的算子保存一个映射“算子 ID ->状态”:
1 | Operator ID | State |
在上面的示例中,print sink 是无状态的,因此不是 Savepoint 状态的一部分。默认情况下,我们尝试将 Savepoint 的每个条目映射回新程序。
2.3 触发 Savepoint
当触发 Savepoint 时,将创建一个新的 Savepoint 目录,其中存储数据和元数据。可以通过配置默认目标目录或使用触发器命令指定自定义目标目录(参见:targetDirectory参数来控制该目录的位置。
以 FsStateBackend 或 RocksDBStateBackend 为例:
1 | # Savepoint 目标目录 |
请注意,如果使用 MemoryStateBackend,则元数据和 Savepoint 状态将存储在 _metadata 文件中。 由于它是自包含的,你可以移动文件并从任何位置恢复。
2.3.1 触发 Savepoint
这将触发 ID 为 :jobId 的作业的 Savepoint,并返回创建的 Savepoint 路径。 你需要此路径来还原和删除 Savepoint 。
1 | bin/flink savepoint :jobId [:targetDirectory] |
2.3.2 使用 YARN 触发 Savepoint
这将触发 ID 为 :jobId 和 YARN 应用程序 ID :yarnAppId 的作业的 Savepoint,并返回创建的 Savepoint 的路径。
1 | bin/flink savepoint :jobId [:targetDirectory] -yid :yarnAppId |
2.4 使用 Savepoint 取消作业
将自动触发 ID 为 :jobid 的作业的 Savepoint,并取消该作业。此外,你可以指定一个目标文件系统目录来存储 Savepoint 。该目录需要能被 JobManager(s) 和 TaskManager(s) 访问。
1 | $ bin/flink cancel -s [:targetDirectory] :jobId |
2.5 从 Savepoint 恢复
1 | $ bin/flink run -s :savepointPath [:runArgs] |
这将提交作业并指定要从中恢复的 Savepoint 。 你可以给出 Savepoint 目录或 _metadata 文件的路径。
2.5.1 跳过无法映射的状态恢复
默认情况下,resume 操作将尝试将 Savepoint 的所有状态映射回你要还原的程序。 如果删除了运算符,则可以通过 --allowNonRestoredState(short:-n)选项跳过无法映射到新程序的状态:
1 | $ bin/flink run -s :savepointPath -n [:runArgs] |
2.6 删除 Savepoint
1 | $ bin/flink savepoint -d :savepointPath |
这将删除存储在 :savepointPath 中的 Savepoint。
请注意,还可以通过常规文件系统操作手动删除 Savepoint ,而不会影响其他 Savepoint 或 Checkpoint(请记住,每个 Savepoint 都是自包含的)。 在 Flink 1.2 之前,使用上面的 Savepoint 命令执行是一个更乏味的任务。
2.7 配置 Savepoint
你可以通过 state.savepoint.dir 配置 savepoint 的默认目录。 触发 savepoint 时,将使用此目录来存储 savepoint。 你可以通过使用触发器命令指定自定义目标目录来覆盖缺省值(请参阅:targetDirectory参数)。
1 | # 默认 Savepoint 目标目录 |
如果既未配置缺省值也未指定自定义目标目录,则触发 Savepoint 将失败。
3. Savepoint 与 Checkpoint 的区别
- Flink 的 Savepoint 与 Checkpoint 的不同之处类似于传统数据库中的备份与恢复日志之间的差异。
- 除去一些概念上的和使用方式上的差异,Checkpoint 和 Savepoint 的当前实现基本上使用相同的代码并生成相同的格式。
| CheckPoint | SavePoint | |
|---|---|---|
| 概念 | 自动容错机制 | 程序全局状态镜像 |
| 目的 | 程序自动容错,快速恢复 | 程序修改后继续从状态恢复,程序升级等 |
| 交互 | 生命周期由 Flink 管理,即 Flink 创建、管理和删除 无需用户交互。 作为一种恢复和定期触发的方法 |
生命周期由用户管理,用户通过命令触发创建与删除或恢复状态 |
| 保留 策略 |
Checkpoint默认程序删除,可以设置CheckpointConfig中的参数进行保留 | Savepoint 会一直保存,除非用户删除 |

