1. 介绍
一个典型的机器学习构建包含若干个步骤
- 源数据ETL
- 数据预处理
- 特征选取
- 模型训练与验证
以上四个步骤可以抽象为一个包括多个步骤的流水线式工作,从数据收集开始至输出我们需要的最终结果,因此,对以上多个步骤,进行抽象模型,简化流水线式工作流存在着可能性,对利用spark进行机器学习的用户来说,流水线式机器学习比单个步骤独立建模更加高效、易用。
受到scikit-learn 项目的启发, 并且总结了MLlib在处理复杂机器学习问题的弊端(主要为工作繁杂, 流程不够清晰, ) 旨在向用户提供基于DataFrame 之上的更加高层次的API库, 以更加方便的构建复杂的机器学习工作流式应用。
一个Pipelines 在结构上会包含一个或者多个Stage, 每个stage都会完成一个任务, 如数据集处理转化, 模型训练, 参数设置或者数据预测等, 这样的Stage在ML里按照处理问题类型不同都会有响应的定义和实现, 主要的Stage为Transformer(转换器) 和Estimator(评估器),
2. DataFrame
Spark MLlib使用Spark SQL中的DataFrame作为数据集,它可以容纳各种数据类型。 相较于RDD,增加了包含schema 信息,更类似传统数据库中的二维表格。它被 ML Pipeline 用来存储源数据。例如,DataFrame中的列可以是存储的文本,特征向量,真实标签和预测的标签等。可以查看 Spark SQL DataType reference 来了解数据框支持的基础和结构化数据类型。 除了Spark SQL指南中提到的数据类型外, 数据框还可以使用机器学习向量类型。可以显式地建立数据框或隐式地从规则的RDD建立数据框, 下面的代码将会给出示例
数据框的列需要命名, 代码中的示例使用如:”text”, ”features” 和 ”lable” 的名字
3. Transformer
Transformer(转换器)是一种可以将一个DataFrame转换为另一个DataFrame的算法。比如一个模型就是一个 Transformer。它可以把 一个不包含预测标签的测试数据集 DataFrame 打上标签,转化成另一个包含预测标签的 DataFrame。技术上,Transformer实现了一个方法transform(),它通过附加一个或多个列将一个DataFrame转换为另一个DataFrame。
如:
1.一个特征转换器输入一个数据框, 读取一个文本列, 将其映射为新的特征向量列, 输出一个新的带有特征向量列的数据框
2.一个学习模型转换器出入一个数据框, 读取包括特征向量的列, 预测一个特征向量的标签, 输出一个新的带有预测标签列的数据框。
4. Estimator
评估器是学习算法或在训练数据上的训练方法的概念抽象。在 Pipeline 里通常是被用来操作 DataFrame 数据并生产一个 Transformer。从技术上讲,Estimator实现了一个方法fit(),它接受一个DataFrame并产生一个转换器。如一个随机森林算法就是一个 Estimator,它可以调用fit(),通过训练特征数据而得到一个随机森林模型。或者逻辑回归也是一个评估器, 通过 fit() 来产生给一个逻辑回归模型。
5. pipeline
pipeline被称为工作流或者管道。工作流将多个工作流阶段(转换器和估计器)连接在一起,形成机器学习的工作流,并获得结果输出。
在机器学习中, 运行一系列算法来处理和学习数据是非常常见的, 如一个文档数据的处理工作流可能包括以下步骤
- 将文档分为单个词语
- 将每个文档中的词语转为数字化的特征向量
- 使用特征向量和标签学习一个预测模型
MLlib将上述工作流描述为一个工作流,它包含一系列需要被执行的有顺序的工作流阶段(转换器和评估器)下面我们将使用上述文档处理的工作流作为例子
管道组件的特性
转换器的 transform() 方法和评估器的 fit() 方法都是无状态的,将来有状态的算法可能通过其它概念得到支持。
每个转换器和评估器实例都有唯一编码, 这个特征在指定参数的时候非常有用。
6. parameter
Parameter 被用来设置 Transformer 或者 Estimator 的参数。所有转换器和估计器都可共享用于指定参数的公共API。
MLlib评估器和转换器使用统一的接口来指定参数
Param是有完备文档的已命名参数。 ParamMap是一组 (参数 -> 值)对
有两种主要的方法来向算法传递参数
- 给实体设置参数。 比如, lr 是一个逻辑回归实体, 通过lr.setMaxlter(10) 来使得lr在拟合的时候最多迭代10次。 这个接口与spark.mllib包相似。
- 传递ParamMap 到fit() 或者 transform() 。 所有在ParamMap里的参数都将通过设置被重写。
参数属于指定评估器和转换器实体过程。 因此, 如果我们有两个逻辑回归实体 lr1和lr2, 我们可以建立一个ParamMap 来指定两个实体的最大迭代次数:
ParamMap(lr1.maxlter -> 10,lr2.maxlter -> 20)。 这在一个工作流内有两个算法都有最大迭代次数参数是非常有用的。
7. 工作原理
要构建一个 Pipeline工作流,首先需要定义 Pipeline 中的各个工作流阶段PipelineStage,(包括转换器和评估器),比如指标提取和转换模型训练等。有了这些处理特定问题的转换器和 评估器,就可以按照具体的处理逻辑有序的组织PipelineStages 并创建一个Pipeline。比如:
1 |
|
然后就可以把训练数据集作为输入参数,调用 Pipeline 实例的 fit() 方法来开始以流的方式来处理源训练数据。这个调用会返回一个 PipelineModel 类实例,进而被用来预测测试数据的标签。更具体的说,工作流的各个阶段按顺序运行,输入的DataFrame在它通过每个阶段时被转换。 对于Transformer阶段,在DataFrame上调用transform()方法。 对于估计器阶段,调用fit()方法来生成一个转换器(它成为PipelineModel的一部分或拟合的Pipeline),并且在DataFrame上调用该转换器的transform()方法。
下面的图说明简单的文档处理工作流的运行
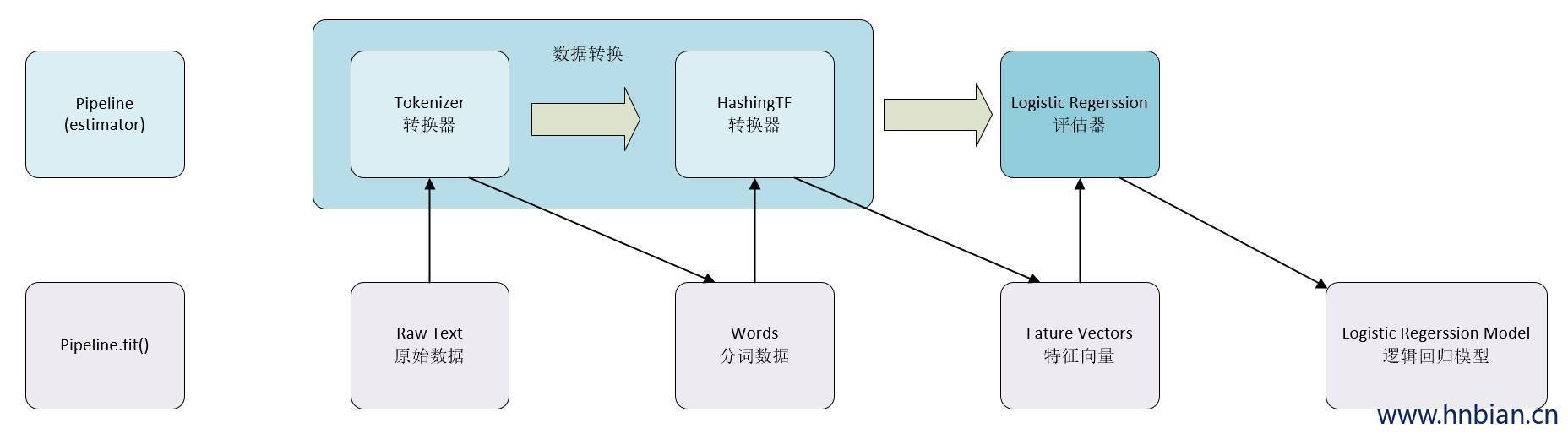
上面中,第一行表示具有三个阶段的流水线。
前两个Tokenizer(分词器)和HashingTF(哈希处理) 是转换器阶段(Transformers),
第三个LogisticRegression(逻辑回归)是评估器(Estimator)。
第二行表示流经管线的数据。
其中圆柱表示DataFrames。在原始DataFrame上调用Pipeline.fit() 方法,它具有原始文本文档和标签。
Tokenizer.transform() 方法将原始文本文档拆分为单词,向DataFrame添加一个带有单词的新列
HashingTF.transform()方法将字列转换为特征向量,向这些向量添加一个新列到DataFrame。
LogisticRegression是一个Estimator,Pipeline首先调用LogisticRegression.fit()产生一个LogisticRegressionModel(逻辑回归模型)。 如果工作流中有更多的阶段,则在将DataFrame传递到下一个阶段之前,将在DataFrame上调用LogisticRegressionModel的transform()方法。
值得注意的是,工作流本身也可以看做是一个评估器。在工作流的fit()方法运行之后,它产生一个PipelineModel,它是一个Transformer。 这个管道模型将在测试数据的时候使用。 下图说明了这种用法。
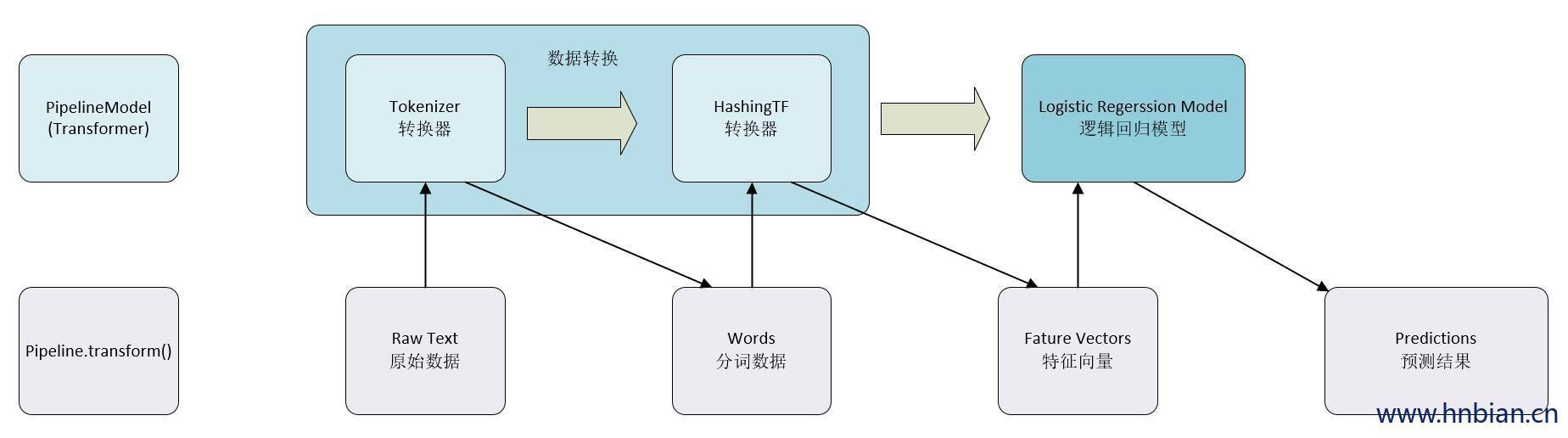
在上图中,PipelineModel具有与原始工作流有着相同的级数,但是原始流水线中的所有评估器都变为变换器。 当在测试数据集上调用PipelineModel的transform()方法时,数据按顺序通过拟合的工作流。 每个阶段的transform()方法更新数据集并将其传递到下一个阶段。工作流和工作流模型有助于确保培训和测试数据通过相同的特征处理步骤。
8. 详细信息
DAG Pipeline:工作流的状态是有序队列,上面给出的例子都是线性工作流,也就是说工作流的每个阶段都使用上一个阶段产生的数据。我们也可以产生非线性的管道,数据流向为有向无环图(DAG)。这种图通常需要明确地指定每个阶段的输入和输入的列名(通常以指定参数的形式)如果管道是DAG形式, 则每个阶段必须以拓扑的形式指定
运行时间检查:工作流可以运行在多种数据类型上,所以不能使用编译时类型检查。工作流与模型在实际运行工作流之前就会进行检查,通过DataFrame 的schema 中对DataFrame各个列类型的描述进行检查。
唯一的工作流阶段:工作流中的每个阶段都是唯一的。就如同“哈希变换”不可以再管道中执行两次,因为管道中的每个阶段必须有唯一的ID。然是“哈希变换1”和“哈希变换2”(都是哈希类型变换)可以在同一个工作流分别执行(共执行两次),因为他们有不同的ID
9. 持久化:保存与加载工作流
通常,我们会将工作流或模型保存到磁盘供以后使用。在Spark 1.6 中,已经在Pipeline API 中增加模型的导入/导出功能。到Spark2.3 spark.ml与pyspark.ml中基于DataFrame 的API 已经具有比较完善的功能。ML 的持久化适用于Scala、Java、Python。但是保存在R中的模型只能加载回R,这个问题在SPARK-15572中进行跟踪,预计之后的版本会修复此功能。
10. 代码示例
10.1 评估器、转换器、参数 代码示例
1 | package hnbian.spark.ml.pipeline |
10.2 工作流代码示例
1 |
|

