1. 分词器
1.1 算法介绍
- 类别:transformer【转换器】
- Tokenizer
Tokenization 将文本划分为单词。下面例子将展示如何把句子划分为单词。
RegexTokenizer基于正则表达式提供了更多的划分选项。默认情况下,参数“pattern”用来指定划分文本的分隔符。或者用户可以指定参数“gaps”设置为false 来指明正则 “patten” 表示获取的内容,而不是分隔符, 这样来为分词结果找到所有可能匹配的情况。
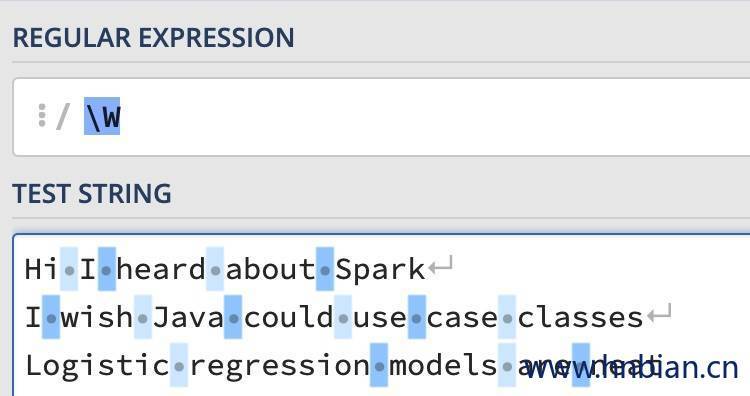
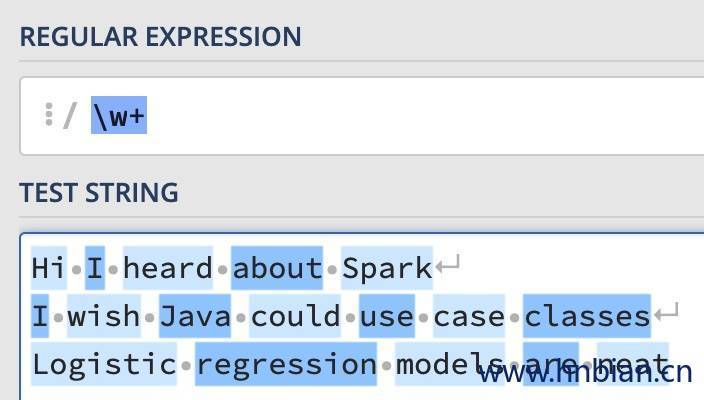
如下面的例子中我们是设置patten 分别为“\w+”与“\W” 的区别如下两幅图所示:
| \W |
\w+ |
 |
 |
1.2 代码示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
| package hnbian.spark.ml.feature.transforming
import org.apache.spark.sql.SparkSession
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.ml.feature.{RegexTokenizer, Tokenizer}
object Tokenizer extends App {
val conf = new SparkConf().setAppName("Tokenizer")
conf.setMaster("local[4]")
val sc = new SparkContext(conf)
val spark = SparkSession.builder().getOrCreate()
sc.setLogLevel("Error")
val sentenceDF = spark.createDataFrame(Seq(
(0, "Hi I heard about Spark"),
(1, "I wish Java could use case classes"),
(2, "Logistic,regression,models,are,neat")
)).toDF("label", "sentence")
sentenceDF.show(false)
val tokenizer = new Tokenizer().setInputCol("sentence").setOutputCol("words")
val tokenized = tokenizer.transform(sentenceDF)
tokenized.select("words", "label").take(3).foreach(println)
tokenized.show(false)
val regexTokenizer = new RegexTokenizer()
.setInputCol("sentence")
.setOutputCol("words")
.setPattern("\\W")
val regexTokenized = regexTokenizer.transform(sentenceDF)
regexTokenized.select("words", "label").take(3).foreach(println)
regexTokenized.show(false)
}
|
2. 停用词移除
2.1 算法介绍
- 类别:transformer【转换器】
- StopWordsRemover
停用词是在文档中频繁出现,但是没有太多实际意义的词语,这些词语不应该被包含在算法中。
StopWordsRemover的输入为一系列字符串(如分词器输入),输出删除了所有的停用词,停用词表示由StopWords参数提供。一些语言的默认停用词可以通过StopWordsRemover.loadDefaultStopWords(language)调用。布尔类型的参数caseSensitive指明是否区分大小写(默认为否,不区分)
假设我们有如下DataFrame, 有id和raw两列
| id |
raw |
| 0 |
[I,saw, the, red, baloon] |
| 1 |
[Mary, had, a, little, lamb] |
通过对raw列调用StopWordsRemover,我们可以筛选出结果列如下:
| id |
raw |
filtered |
| 0 |
[I,saw, the, red, baloon] |
[saw, red, baloon] |
| 1 |
[Mary, had, a, little, lamb] |
[Mary, little, lamb] |
其中,“I”, “the”, “had”以及“a”被移除。
2.2 代码示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
| package hnbian.spark.ml.feature.transforming
import hnbian.spark.SparkUtils
import org.apache.spark.sql.SparkSession
import org.apache.spark.{SparkConf, SparkContext}
object StopWordsRemover extends App {
val spark = SparkUtils.getSparkSession("StopWordsRemover",4)
import org.apache.spark.ml.feature.StopWordsRemover
val remover = new StopWordsRemover()
.setInputCol("raw")
.setOutputCol("filtered")
val dataDF = spark.createDataFrame(Seq(
(0, Seq("I", "saw", "the", "red", "baloon")),
(1, Seq("Mary", "had", "a", "little", "lamb"))
)).toDF("id", "raw")
dataDF.show(false)
val modelDF = remover.transform(dataDF)
modelDF.show(false)
}
|
3. n-gram
3.1 算法介绍
类别:transformer【转换器】
一个n-gram是一个长度为整数 n 的单词序列。 NGram可以用来将输入转换为n-gram
NGram的输入为一系列字符串(如分词器输入)。 参数n决定每个n-gram 包含的对象个数。 结果包含一系列n-gram, 其中每个n-gram代表一个空格分割的n个连续字符。 如果输入少于n个字符串,将没有输出结果。
3.2 调用示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
| package hnbian.spark.ml.feature.transforming
import hnbian.spark.SparkUtils
import org.apache.spark.ml.feature.NGram
object NGram extends App {
val spark = SparkUtils.getSparkSession("NGram",4)
val wordDF = spark.createDataFrame(Seq(
(0, Array("Hi", "I", "heard", "about", "Spark")),
(1, Array("I", "wish", "Java", "could", "use", "case", "classes")),
(2, Array("Logistic", "regression", "models", "are", "neat"))
)).toDF("label", "words")
wordDF.show(false)
val ngram = new NGram()
.setInputCol("words")
.setOutputCol("ngrams")
val ngramDF = ngram.transform(wordDF)
ngramDF.take(3).map(_.getAs[Stream[String]]("ngrams").toList).foreach(println)
ngramDF.show(false)
}
|
4. 二值化
4.1 算法介绍
类别:transformer【转换器】
二值化(Binarizer )是根据阈值将连续数值特征转换为0-1的特征的过程。
Binarizer参数有:输入、输出、阈值。特征值大于阈值将映射为1.0,否则映射为0.0
4.2调用示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
| package hnbian.spark.ml.feature.transforming
import hnbian.spark.SparkUtils
import org.apache.spark.ml.feature.Binarizer
object Binarizer extends App {
val spark = SparkUtils.getSparkSession("Binarizer", 4)
val dataDF = spark
.createDataFrame(Array((0, 0.1), (1, 0.8), (2, 0.2), (3, 0.6), (4, 0.5)))
.toDF("label", "feature")
dataDF.show(false)
val binarizer: Binarizer = new Binarizer()
.setInputCol("feature")
.setOutputCol("binarized_feature")
.setThreshold(0.5)
val binarizedDF = binarizer.transform(dataDF)
binarizedDF.show(false)
val binarizedFeatures = binarizedDF.select("binarized_feature")
binarizedFeatures.collect().foreach(println)
binarizedFeatures.show(false)
}
|
5. 降维,主成分分析
5.1 算法介绍
类别:estimator【评估器】
PCA (principal component analysis) ,即主成分分析方法,是一种广泛使用的数据降维方法。PCA可以找出特征中最主要的特征,把原来的n个特征用k(k < n)个特征代替,去除噪音和冗余即降维。降维是对数据高纬度特征的一种预处理方法,
保留下高纬度数据中最重要的一些特征,去除噪声和不重要的特征,从而实现提升数据处理速度的目的。在实际的生产和应用中,在一定的信息损失范围内对数据做降维处理,可以为我们节省大量的时间和成本。降维也成为了非常广泛的数据预处理方法:
降维具有如下优点:
1.是的数据集更容易使用
2.降低算法计算时的开销
3.去除噪声
4.使结果更容易理解
在PCA中,数据从原来的坐标系转换到新的坐标系,由数据本身决定。转换坐标系使,以方差最大的方向作为坐标轴方向,因为数据的最大方差给出了数据的最重要的信息。第一个新坐标轴选择的是原始数据中方差最大的方法,第二个新坐标轴选择的是与第一个新坐标轴正交且方差次大的方向。重复该过程,重复次数为原始数据的特征维数。
通过这种方式获得的新坐标系,我们发现,大部分方差都包含在前面加个坐标中,后面的坐标轴所包含的方差几乎为0。于是我们可以忽略余下的坐标轴,只保留前面的几个包含有绝大部分方差的坐标轴。事实上,这样也就相当于只保留包含大部分方差的维度特征,而忽略包含方差几乎为0的特征维度,也就实现了对数据特征的降维处理。
Spark ML 中 pac的实现思路如下:
原始数据 3 行 4 列经过转换得到矩阵 $A_{3*4}$
得到矩阵 $A_{3*4}$ 的协方差矩阵 $B_{4*4}$
得到协方差矩阵 $B_{4*4}$ 的右特征向量
选取 K (如 k=2) 个大的特征值对应的特征向量,得到矩阵 $C_{4*2}$
对矩阵 $A_{3*4}$ 降维得到 $ A_{3*4}^{‘} $ = $ A_{3·4} $ * $ C_{4·2} $
5.2 代码示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
| package hnbian.spark.ml.feature.transforming
import hnbian.spark.SparkUtils
import org.apache.spark.ml.feature.PCA
import org.apache.spark.ml.linalg.Vectors
object PCA extends App {
val spark = SparkUtils.getSparkSession("PCA", 4)
val data = Array(
Vectors.sparse(5, Seq((1, 1.0), (3, 7.0))),
Vectors.dense(2.0, 0.0, 3.0, 4.0, 5.0),
Vectors.dense(4.0, 0.0, 0.0, 6.0, 7.0)
)
val df = spark.createDataFrame(data.map(Tuple1.apply)).toDF("features")
df.show(false)
val pca = new PCA()
.setInputCol("features")
.setOutputCol("pcaFeatures")
.setK(3)
.fit(df)
pca.transform(df).show(false)
}
|
6. 升维,多项式展开
6.1 算法介绍
类别:transformer【转换器】
多项式扩展(PolynomialExpansion)通过产生n维组合将原始特征扩展到多项式空间。
下面示例将会介绍将特征集扩展到3维多项式空间
6.2 代码示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
| package hnbian.spark.ml.feature.transforming
import org.apache.spark.ml.feature.PolynomialExpansion
import org.apache.spark.ml.linalg.Vectors
import hnbian.spark.SparkUtils
object PolynomialExpansion extends App {
val spark = SparkUtils.getSparkSession("PolynomialExpansion",4)
val data = Array(
Vectors.dense(-2.0, 2.3),
Vectors.dense(0.0, 0.0),
Vectors.dense(0.6, -1.1)
)
val df = spark.createDataFrame(data.map(Tuple1.apply)).toDF("features")
df.show(false)
val polynomialExpansion = new PolynomialExpansion()
.setInputCol("features")
.setOutputCol("polyFeatures")
.setDegree(3)
val polyDF = polynomialExpansion.transform(df)
polyDF.show(false)
}
|

