1. 介绍
内存类型表引擎有 Memory、Set、Join、Buffer 等。Memory 类型表引擎,直接将数据保存到内存当中,其余几种表引擎都会将数据写入磁盘,这样可以防止数据丢失,作为一种故障恢复手段,在数据表被加载时,它们会将数据全部加载到内存供查询使用。将全量数据都放在内存既有查询效率高的好处,也有带来极大的内存消耗和负担的坏处。
2. Memory 表引擎
- Memory 表引擎将数据保存在内存中,既不会被压缩,也不会被转换格式,内存中保存的数据形态与查询时看到的一致。写入数据后不会在磁盘中创建任何文件
- Memory 表引擎中的数据会在 clickhouse 重启时全部丢失。
- Memory 表引擎不需要读取磁盘与序列化等操作,所以在 1 亿数据量以内的查询中,查询效率与 MergeTree 系列表引擎性能相当
- Memory 表引擎中
- 使用介绍
1 | create table t_memory( |
Memory 表引擎更广泛应用于 clickhouse 的内存,它会被用作集群间数据分发的载体,例如在分布式IN 查询场景中,会利用 Memory 表存储IN 查询子句的查询结果,并通过网络将其传送到其他节点中。
3. Set 表引擎
Set 表引擎是有物理存储的,数据首先被写到内存,之后同步到磁盘上,当 clickhouse 重启后数据不会丢失,再次加载表时会将磁盘中的数据全量加载到内存中。
Set 表引擎具有 Set 结构的特点,所有元素都是唯一的,在写入数据时重复的数据会被忽略。
Set表引擎使用场景具有局限性,它能够支持 insert 但是不能被 select 。Set 表引擎的使用场景是作为 IN 查询的右侧条件被使用。
Set 表引擎有两部分组成:
- [num].bin 数据文件:保存了所有列字段的数据,num 是一个自增 ID 从 1 开始,每次写入数据时,都会生成一个新的[num].bin 文件,num 也会+1
- tmp临时目录:数据文件首先写入到该目录中,当数据写入完毕之后,数据文件会被从次目录中移除
- 使用介绍
1 | // 建表 |
4. JOIN 表引擎
4.1 介绍
- Join 表引擎是针对 join 场景而设计的,它是将join 查询做了一层封装
- Join 表引擎的底层实现中与 Set 表引擎共用了大部分逻辑,所以 join 和 set 表引擎有很多相似的地方。
- Join 表引擎在写入数据时首先被写入内存然后将数据保存至磁盘。
- Join 表引擎也有[num].bin 和 tmp 临时目录两个部分组成
- Join 表引擎既能被用在 join 查询场景也能被直接查询
4.2 语法
1 | CREATE TABLE -- 创建表 |
- join_strictness:连接经度,决定了 JOIN 查询连接数据时所使用的的策略。目前支持 ALL、ANY、ASOF 三种策略。
- join_type:连接类型,它决定了 JOIN 查询组合左右两个数据集合的策略,目前两个数据集形成的结果有交集,并集,笛卡尔积或其它形式。目前支持INNER、OUTER、CROSS三种类型。当join_type 设置为ANY 时,在写入数据时,join_type 的重复数据会被自动过滤。
- key:连接键,它决定了使用哪些键进行关联
4.3 使用示例
1 | create table t_test( |
5. Buffer 表引擎
5.1 介绍
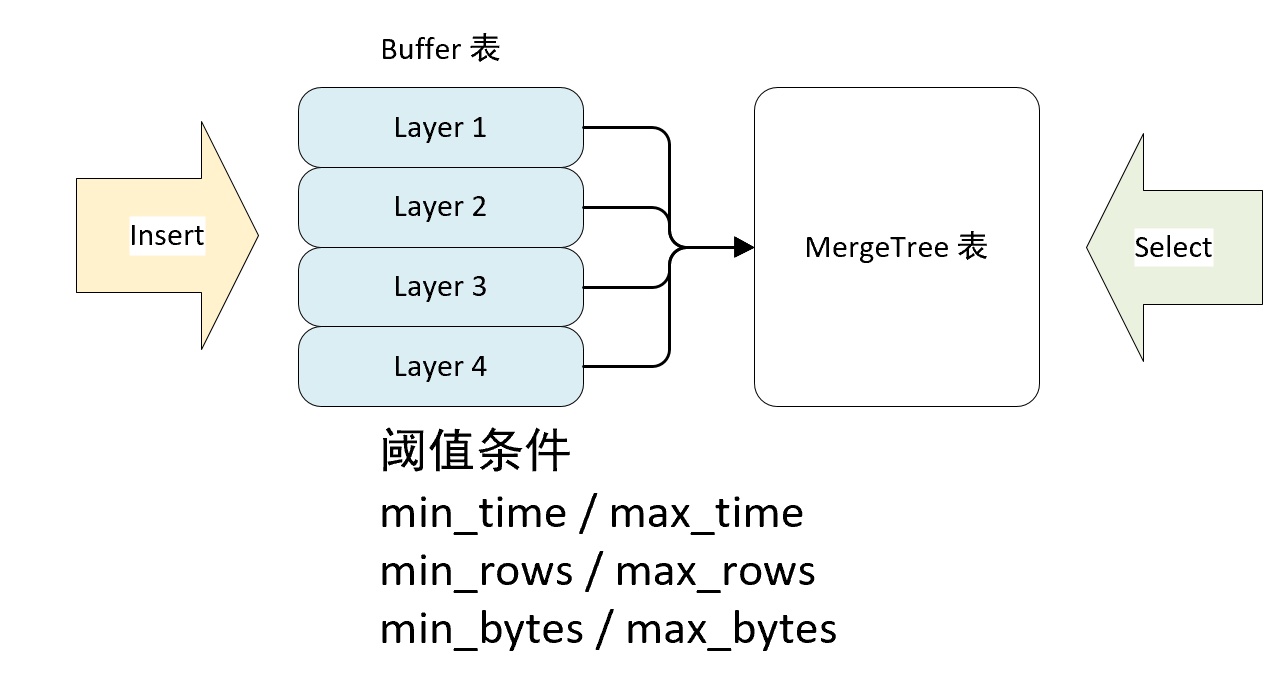
Buffer 表引擎完全使用内存装载数据,不支持数据的持久化,所以当服务重启之后,表内的数据会被清空。
Buffer 表引擎并不是为了查询场景设计的,它的作用是充当缓冲区的角色。
假如我们向 MergeTree 表 A 中写入数据,但是并发数很高,写入速度很快,可能写入速度大于合并速度,这时会导致分区数越来越大,总是有些分区来不及合并,我们可以使用 Buffer 表引擎来解决这个问题,数据先被写入到 buffer 表,当满足一定条件时会自动写入 MergeTree 表。
5.2 语法
1 | CREATE TABLE -- 创建表 |
参数可以分为基础参数和条件参数两类,
- 基础参数:
| 参数 | 说明 |
|---|---|
| database | 目标表的数据库名称 |
| table | 目标表,Buffer 表内的数据会自动刷新到目标表 |
| num_layers | 线程数,Buffer 表会按照该配置的数量开启线程,并以并行的方式想数据刷新到目标表,建议设置为 16 |
- 条件参数
Buffer 表并不是实时刷新数据到目标表的,而是只有达到阈值条件时才会刷新,阈值条件有三组条件组成。
| 参数 | 说明 |
|---|---|
| min_time,max_time | 时间条件最小值和最大值,单位秒,从第一次向内存写入数据的时候开始计算 |
| min_rows,max_rows | 数据行条件的最小值和最大值 |
| min_bytes,max_bytes | 数据量条件的最小值和最大值,单位字节 |
根据上述条件,Buffer 表刷新的判断依据有三个,满足其中任意一个,Buffer 表就会刷新数据:
- 如果三组条件所有的最小阈值都已经满足,则触发刷新动作
- 如果三组条件至少有一个最大阈值条件满足,则触发刷新动作
- 如果写入的一批数据的行数大于 max_rows 或者 数据量大于 max_bytes 则数据直接写入目标表。
上述的三组条件针对 num_layers 中的每个线程是独立计算的,假如设置 num_layers = 16,那么 Buffer表会开启 16 个线程以轮询的方式来响应数据的写入,每个线程内,会独立进行上述条件的判断过程,假如设置 max_bytes = 100MB,那么 16 个线程同时处理的最大数据量约为 1.6GB。
5.3 使用示例
1 | // 创建数据持久化表 |

