1. Flink State 介绍
1.1 什么是 State(状态)
- 由一个任务维护,并且用来计算某个结果的所有数据,就属于这个任务的状态
- 可以认为状态就是一个本地变量,可以被任务的业务逻辑访问
- 当任务失败时,可以使用状态恢复数据
- 状态始终是与特定算子相关联的。
- 算子需要预先注册其状态,以便在Flink运行时能够了解算子状态
- Flink 会进行状态的管理,包括状态一致性、故障处理以及高效的存储和访问,以便开发人员可以专注于应用的业务逻辑。
Flink 内置的很多算子,数据源 source,数据存储 sink 都是有状态的,流中的数据都是 buffer records,会保存一定的元素或者元数据。例如: ProcessWindowFunction 会缓存输入流的数据,ProcessFunction 会保存设置的定时器信息等等。

1.2 有状态与无状态的计算
流式计算分为无状态和有状态两种情况。
无状态的计算 :观察每个独立事件,每次只转换一条输入记录,并且仅根据最新的输入记录输出结果。例如,流处理应用程序从传感器接收温度读数,并在温度超过 90 度时发出警告。
**有状态的计算 ** :基于多个事件输出结果,维护所有已处理记录的状态值,并根据每条新输入的记录更新状态,因此输出记录反映的是综合考虑多个事件之后的结果。
所有类型的窗口。例如,计算过去一小时的平均温度,就是有状态的计算。
所有用于复杂事件处理的状态机。例如,若在一分钟内收到两个相差 20 度以上的温度读数,则发出警告,这是有状态的计算。
流与流之间的所有关联操作,以及流与静态表或动态表之间的关联操作, 都是有状态的计算。
下图展示了 无状态流处理 和 有状态流处理 的 主要区别。无状态流处理分别接收每条数据记录,然后根据最新输入的数据生成输出数据。有状态流处理会维护状态,并基于最新输入的记录和当前的状态值生成输出记录。
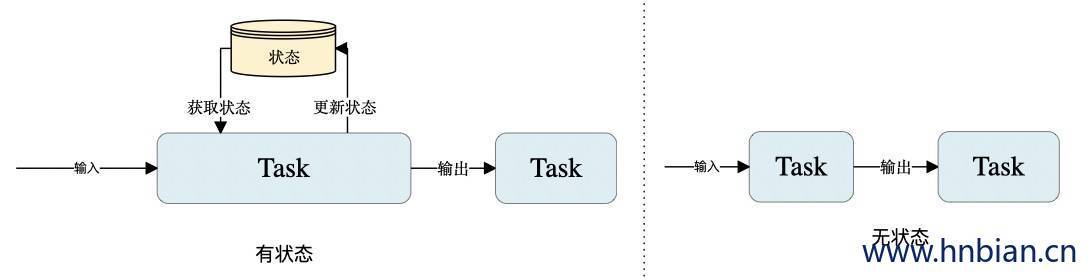
尽管无状态的计算很重要,但是流处理对有状态的计算更感兴趣。事实上,正确地实现有状态的计算比实现无状态的计算难得多。旧的流处理系统并不支持有状态的计算,而新一代的流处理系统则将状态及其正确性视为重中之重。
2. 状态描述(StateDescriptor)
StateDescriptor 是所有状态描述符的基类。 Flink 通过 StateDescriptor 定义状态,包括状态的名称,存储数据的类型,序列化器等基础信息。
2.1 StateDescriptor 种类
使用不同类型的 StateDescriptor 可以创建出不同类型的状态,flink 中提供了 ListStateDescriptor、MapStateDescriptor、ValueStateDescriptor、AggregatingStateDescriptor、ReducingStateDescriptor 、FoldingStateDescriptor(废弃) 状态描述符供使用。他们都继承自 StateDescriptor。
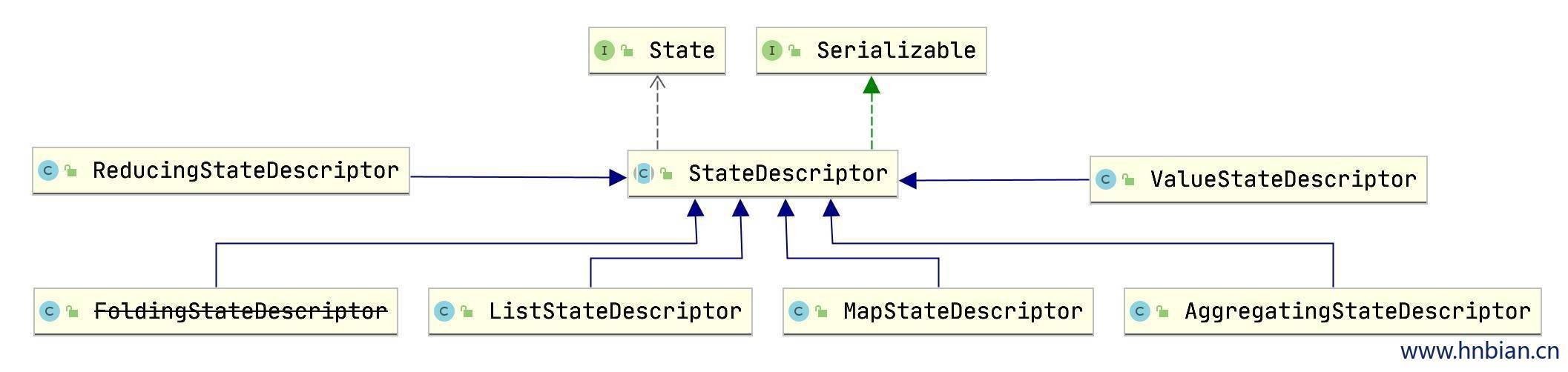
2.2 StateDescriptor源码
public abstract class StateDescriptor<S extends State, T> implements Serializable {
private static final Logger LOG = LoggerFactory.getLogger(StateDescriptor.class);
/**
* 枚举类型 包含所支持状态类型。 用于在写入和还原检查点和保存点时识别状态类型。
* 不要更改此枚举中元素的顺序,在数据序列化中使用该数据
*/
public enum Type {
UNKNOWN,VALUE,LIST,REDUCING,FOLDING,AGGREGATING,MAP
}
private static final long serialVersionUID = 1L;
/** 为标识此StateDescriptor 而创建的状态唯一的名称 */
protected final String name;
/**
* 类型的序列化器
* 可以在构造函数中手动初始化,
* 也可以使用 initializeSerializerUnlessSet(ExecutionConfig) 方法懒加载
*/
private final AtomicReference<TypeSerializer<T>> serializerAtomicReference = new AtomicReference<>();
/** 描述值类型的类型信息。 仅用于延迟创建序列化程序的情况。 */
@Nullable
private TypeInformation<T> typeInfo;
/** 针对从此StateDescriptor创建的状态进行查询的名称 */
@Nullable
private String queryableStateName;
/** Name for queries against state created from this StateDescriptor. */
@Nonnull
private StateTtlConfig ttlConfig = StateTtlConfig.DISABLED;
/** 当没有其他值绑定到键时,状态返回的默认值。 */
@Nullable
protected transient T defaultValue;
// --------构造函数----------------------------------------------------------------
/**
* 构造函数1:使用给定的名称和类型的序列化器创建一个新的 StateDescriptor
* @param name StateDescriptor的名称
* @param serializer 状态中值的类型序列化器
* @param defaultValue 在请求状态之前未设置值的情况下将设置的默认值。
*/
protected StateDescriptor(String name,TypeSerializer<T> serializer,
@Nullable T defaultValue) {
this.name = checkNotNull(name, "name must not be null");
this.serializerAtomicReference.set(
checkNotNull(serializer, "serializer must not be null")
);
this.defaultValue = defaultValue;
}
/**
* 构造函数2: 创建具有给定名称和给定类型信息的新 StateDescriptor
* @param name StateDescriptor的名称
* @param typeInfo 状态值的类型信息
* @param defaultValue 在请求状态之前未设置值的情况下将设置的默认值。
*/
protected StateDescriptor(String name, TypeInformation<T> typeInfo,
@Nullable T defaultValue) {
this.name = checkNotNull(name, "name must not be null");
this.typeInfo = checkNotNull(typeInfo, "type information must not be null");
this.defaultValue = defaultValue;
}
/**
* 构造函数3:创建具有给定名称和给定类型信息的新 StateDescriptor 。
*
* <p>如果此构造函数失败(因为无法通过类描述类型),
* 请考虑使用StateDescriptor(String, TypeInformation, Object)构造函数
*
* @param name StateDescriptor的名称
* @param type 状态值类型的类
* @param defaultValue 在请求状态之前未设置值的情况下将设置的默认值。
*/
protected StateDescriptor(String name, Class<T> type, @Nullable T defaultValue) {
this.name = checkNotNull(name, "name must not be null");
checkNotNull(type, "type class must not be null");
try {
this.typeInfo = TypeExtractor.createTypeInfo(type);
} catch (Exception e) {
throw new RuntimeException(
"Could not create the type information for '" + type.getName() + "'. " +
"The most common reason is failure to infer the generic type information, due to Java's type erasure. " +
"In that case, please pass a 'TypeHint' instead of a class to describe the type. " +
"For example, to describe 'Tuple2<String, String>' as a generic type, use " +
"'new PravegaDeserializationSchema<>(new TypeHint<Tuple2<String, String>>(){}, serializer);'", e);
}
this.defaultValue = defaultValue;
}
// --------构造函数----------------------------------------------------------------
/** 返回此StateDescriptor的名称 */
public String getName() {
return name;
}
/** 返回默认值 */
public T getDefaultValue() {
if (defaultValue != null) {
TypeSerializer<T> serializer = serializerAtomicReference.get();
if (serializer != null) {
return serializer.copy(defaultValue);
} else {
throw new IllegalStateException("Serializer not yet initialized.");
}
} else {
return null;
}
}
/**
* 返回可用于在状态中序列化值的 TypeSerializer 。
* 请注意,序列化程序可能会延迟初始化,并且只能保证在调用 initializeSerializerUnlessSet(ExecutionConfig) 之后存在。
*/
public TypeSerializer<T> getSerializer() {
TypeSerializer<T> serializer = serializerAtomicReference.get();
if (serializer != null) {
return serializer.duplicate();
} else {
throw new IllegalStateException("Serializer not yet initialized.");
}
}
@VisibleForTesting
final TypeSerializer<T> getOriginalSerializer() {
TypeSerializer<T> serializer = serializerAtomicReference.get();
if (serializer != null) {
return serializer;
} else {
throw new IllegalStateException("Serializer not yet initialized.");
}
}
/**
* 设置此描述符创建的状态查询的名称。
* 如果设置了名称,则将在运行时发布创建的状态以供查询。
* 每个作业的名称必须唯一。 如果存在另一个以相同名称发布的状态实例,则该作业将在运行时失败。
*
* @param queryableStateName 查询的状态名称(每个作业的唯一名称)
* @throws IllegalStateException 如果状态名称已经存在抛出此异常
*/
public void setQueryable(String queryableStateName) {
Preconditions.checkArgument(
ttlConfig.getUpdateType() == StateTtlConfig.UpdateType.Disabled,
"Queryable state is currently not supported with TTL");
if (this.queryableStateName == null) {
this.queryableStateName = Preconditions.checkNotNull(queryableStateName, "Registration name");
} else {
throw new IllegalStateException("Queryable state name already set");
}
}
/**
* 返回可查询的状态名称。
* @return Queryable 可查询的状态名称;如果未设置,则为 null
*/
@Nullable
public String getQueryableStateName() {
return queryableStateName;
}
/**
* 返回从此描述符创建的状态是否可查询。
*
* @return 如果状态可查询,则为true ,否则为false 。
* otherwise.
*/
public boolean isQueryable() {
return queryableStateName != null;
}
/**
* 配置状态生存时间(TTL)的可选激活。
*
* 状态用户值将过期,变得不可用并根据配置的StateTtlConfig在存储中StateTtlConfig
*
* @param ttlConfig 状态TTL的配置
*/
public void enableTimeToLive(StateTtlConfig ttlConfig) {
Preconditions.checkNotNull(ttlConfig);
Preconditions.checkArgument(
ttlConfig.getUpdateType() != StateTtlConfig.UpdateType.Disabled &&
queryableStateName == null,
"Queryable state is currently not supported with TTL");
this.ttlConfig = ttlConfig;
}
@Nonnull
@Internal
public StateTtlConfig getTtlConfig() {
return ttlConfig;
}
/**
* 检查序列化器是否已初始化。
* 如果序列化器的初始化是延迟的,以允许通过 initializeSerializerUnlessSet(ExecutionConfig) 使用 ExecutionConfig 对序列化器进行参数化
*
* @return True 如果序列化器已初始化,则为true,否则为false
*/
public boolean isSerializerInitialized() {
return serializerAtomicReference.get() != null;
}
/**
* 初始化序列化程序,除非之前已对其进行了初始化
*
* @param executionConfig 创建序列化程序时要使用的执行配置
*/
public void initializeSerializerUnlessSet(ExecutionConfig executionConfig) {
if (serializerAtomicReference.get() == null) {
checkState(typeInfo != null, "no serializer and no type info");
// try to instantiate and set the serializer
TypeSerializer<T> serializer = typeInfo.createSerializer(executionConfig);
// use cas to assure the singleton
if (!serializerAtomicReference.compareAndSet(null, serializer)) {
LOG.debug("Someone else beat us at initializing the serializer.");
}
}
}
@Override
public final int hashCode() {
return name.hashCode() + 31 * getClass().hashCode();
}
@Override
public final boolean equals(Object o) {
if (o == this) {
return true;
}
else if (o != null && o.getClass() == this.getClass()) {
final StateDescriptor<?, ?> that = (StateDescriptor<?, ?>) o;
return this.name.equals(that.name);
}
else {
return false;
}
}
@Override
public String toString() {
return getClass().getSimpleName() +
"{name=" + name +
", defaultValue=" + defaultValue +
", serializer=" + serializerAtomicReference.get() +
(isQueryable() ? ", queryableStateName=" + queryableStateName + "" : "") +
'}';
}
public abstract Type getType();
private void writeObject(final ObjectOutputStream out) throws IOException {
// write all the non-transient fields
out.defaultWriteObject();
// write the non-serializable default value field
if (defaultValue == null) {
// we don't have a default value
out.writeBoolean(false);
} else {
TypeSerializer<T> serializer = serializerAtomicReference.get();
checkNotNull(serializer, "Serializer not initialized.");
// we have a default value
out.writeBoolean(true);
byte[] serializedDefaultValue;
try (ByteArrayOutputStream baos = new ByteArrayOutputStream();
DataOutputViewStreamWrapper outView = new DataOutputViewStreamWrapper(baos)) {
TypeSerializer<T> duplicateSerializer = serializer.duplicate();
duplicateSerializer.serialize(defaultValue, outView);
outView.flush();
serializedDefaultValue = baos.toByteArray();
}
catch (Exception e) {
throw new IOException("Unable to serialize default value of type " +
defaultValue.getClass().getSimpleName() + ".", e);
}
out.writeInt(serializedDefaultValue.length);
out.write(serializedDefaultValue);
}
}
private void readObject(final ObjectInputStream in) throws IOException, ClassNotFoundException {
// read the non-transient fields
in.defaultReadObject();
// read the default value field
boolean hasDefaultValue = in.readBoolean();
if (hasDefaultValue) {
TypeSerializer<T> serializer = serializerAtomicReference.get();
checkNotNull(serializer, "Serializer not initialized.");
int size = in.readInt();
byte[] buffer = new byte[size];
in.readFully(buffer);
try (ByteArrayInputStream bais = new ByteArrayInputStream(buffer);
DataInputViewStreamWrapper inView = new DataInputViewStreamWrapper(bais)) {
defaultValue = serializer.deserialize(inView);
}
catch (Exception e) {
throw new IOException("Unable to deserialize default value.", e);
}
} else {
defaultValue = null;
}
}
}2.3 StateDescriptor 分类
ListStateDescriptor:可用于描述 ListState 类型状态
MapStateDescriptor:可用于描述 MapState 类型状态
ValueStateDescriptor:可用于描述 ValueState 类型状态
AggregatingStateDescriptor:可用于描述 AggregatingState 类型状态
ReducingStateDescriptor:可用于描述 ReducingState 类型状态
3. 状态的分类
3.1 Managed State 和 Raw State
Flink 状态主要分为托管状态(Managed State)和原始状态(Raw State)。托管状态是由 Flink 自动管理的,这包括状态的存储、恢复以及优化等操作。托管状态包括值状态(Value State),列表状态(List State),映射状态(Map State)等类型,这些类型的状态在 Flink 的检查点和保存点机制中,Flink 会负责处理这些状态的快照和恢复。
相反,原始状态(Raw State)是由用户管理的,用户需要自己定义状态的序列化和反序列化过程。这通常适用于一些特殊的情况,例如用户需要自定义序列化机制,或者需要对状态的存储和恢复有更精细的控制。虽然用户需要自己处理状态的序列化和反序列化,但 Flink 仍然提供了一些基础的支持和接口,以帮助用户更好地处理原始状态。
| - | Managed State | Raw State |
|---|---|---|
| 状态管理方式 | 由 Flink Runtime 托管,状态是自动存储、自动恢复的 | 用户自定义的状态,自己管理 |
| 状态数据结构 | 常用的数据结构,如ValueState、ListState、MapState | 字节数组,byte[] |
| 状态使用场景 | 绝大多数 Flink 算子都可以使用 | 用户自定义算子 |
通常在 DataStream 上的状态推荐使用托管的状态,当实现一个用 户自定义的operator时,会使用到原始状态。
3.2 Operator State 和 Keyed State
- Flink 的状态主要分为两种类型:Operator State 和 Keyed State。
- Operator State:Operator State 是每个并行操作符实例的私有状态,它是在分布式计算中一个任务的本地状态。比如说,我们在做数据重平衡时,就会用到 Operator State,因为这个过程中需要对数据进行缓存,并在适当的时候进行释放。如果一个流计算任务由多个并行子任务组成,每个子任务都会有一个独立的 Operator State。对于 Operator State,Flink 并不知道其内部的数据结构,只负责其存储和恢复。
- Keyed State:Keyed State 是当在 KeyedStream 上运行操作符时使用的状态。在 Flink 中,Keyed State 是绑定到数据流中的特定键(Key)的。这意味着 Flink 维护了数据流中每一个 key 的状态。当处理一个新的元素时,Flink 会将状态的键设置为该元素的键,然后调用对应的处理函数。Keyed State 的一个典型应用场景是计算每个键的滚动聚合。
3.2.1 Keyed State 介绍
Keyed State(键控状态)是根据输入数据流中定义的键(key)来维护和访问的。Flink 为每个键值维护一个状态实例,并将具有相同键的所有数据,都分区到同一个算子任务中,这个任务会维护和处理这个key 对应的状态。当任务处理一条数据时,它会自动将状态的访问范围限定为当前数据的 key。因此,具有相同 key 的所有数据都会访问相同的状态。Keyed State 很类似于一个分布式的 key-value map 数据结构,只能用于 KeyedStream( keyBy 算子处理之后)。
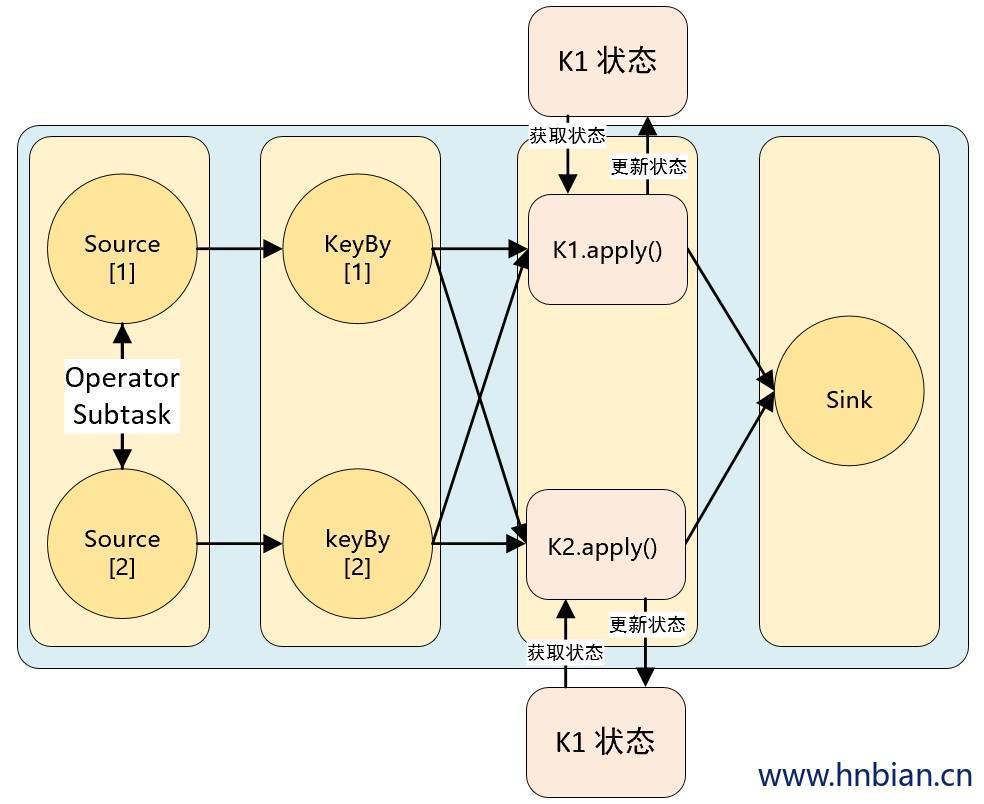
Keyed State 有五种类型:
- ValueState :值状态,保存单个类型为 T 的值
- ListState :列表状态,保存一个类型为 T 的列表
- MapState :映射状态,保存 Key-Value 对
- ReducingState :聚合状态
- AggregatingState:聚合状态
3.2.2 Operator State 介绍
KeyedState 是在进行 KeyBy 之后进行状态操作时使用的状态类型,那么像 Source、Sink算子是不会进行 KeyBy 操作的,当这类算子也需要用到状态,应该怎么操作呢?这时候就需要使用 Operator State(算子状态)。Operator State 是绑定在 Operator 的并行度实例上的,也就是说一个并行度一个状态。
例如当消费 kafka 数据的 Kafka Source 并行度为 3 时,默认每个并行度都是从一个 Kafka 的 topic 的某个分区中消费数据,而每个 kafka Source 为了保证在极端情况下也不丢失数据,就不能将 partition 对应的 offset 保存到默认的 zookeeper 中,而是需要将这些数据保存在状态中,自己来维护这部分数据。当并行度发生调整时,需要在 Operator 的并行度上重新分配状态。
在流数据开发的大多数场景中,我们都不需要使用 Operator State ,Operator State 的实现主要是针对一些没有 Keyed 操作的 Source 和 Sink 而设计的。
Operator State 的作用范围限定为算子任务。这意味着由同一并行任务所处理的所有数据都可以访问到相同的状态,状态对于同一任务而言是共享的。算子状态不能由相同或不同算子的另一个任务访问。
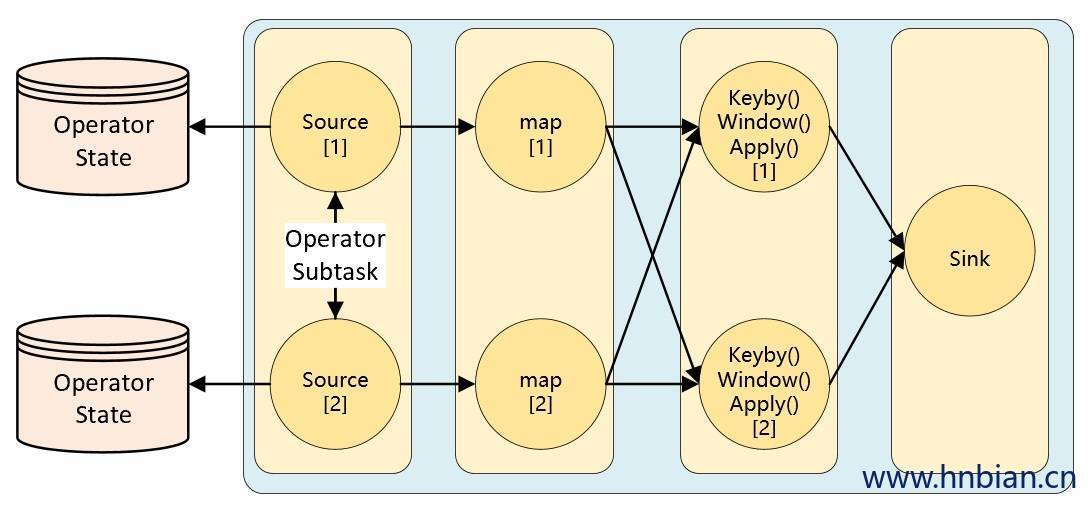

Flink 为算子状态提供三种基本数据结构:
- 列表状态( List state ):状态是一个 可序列化 对象的集合
List,彼此独立,方便在改变并发后进行状态的重新分派。 换句话说,这些对象是重新分配 non-Keyed State 的最细粒度。根据状态的不同访问方式,有如下两种重新分配的模式:
- Even-split redistribution: 每个算子都保存一个列表形式的状态集合,整个状态由所有的列表拼接而成。当作业恢复或重新分配的时候,整个状态会按照算子的并发度进行均匀分配。 比如说,算子 A 的并发读为 1,包含两个元素
element1和element2,当并发读增加为 2 时,element1会被分到并发 0 上,element2则会被分到并发 1 上。
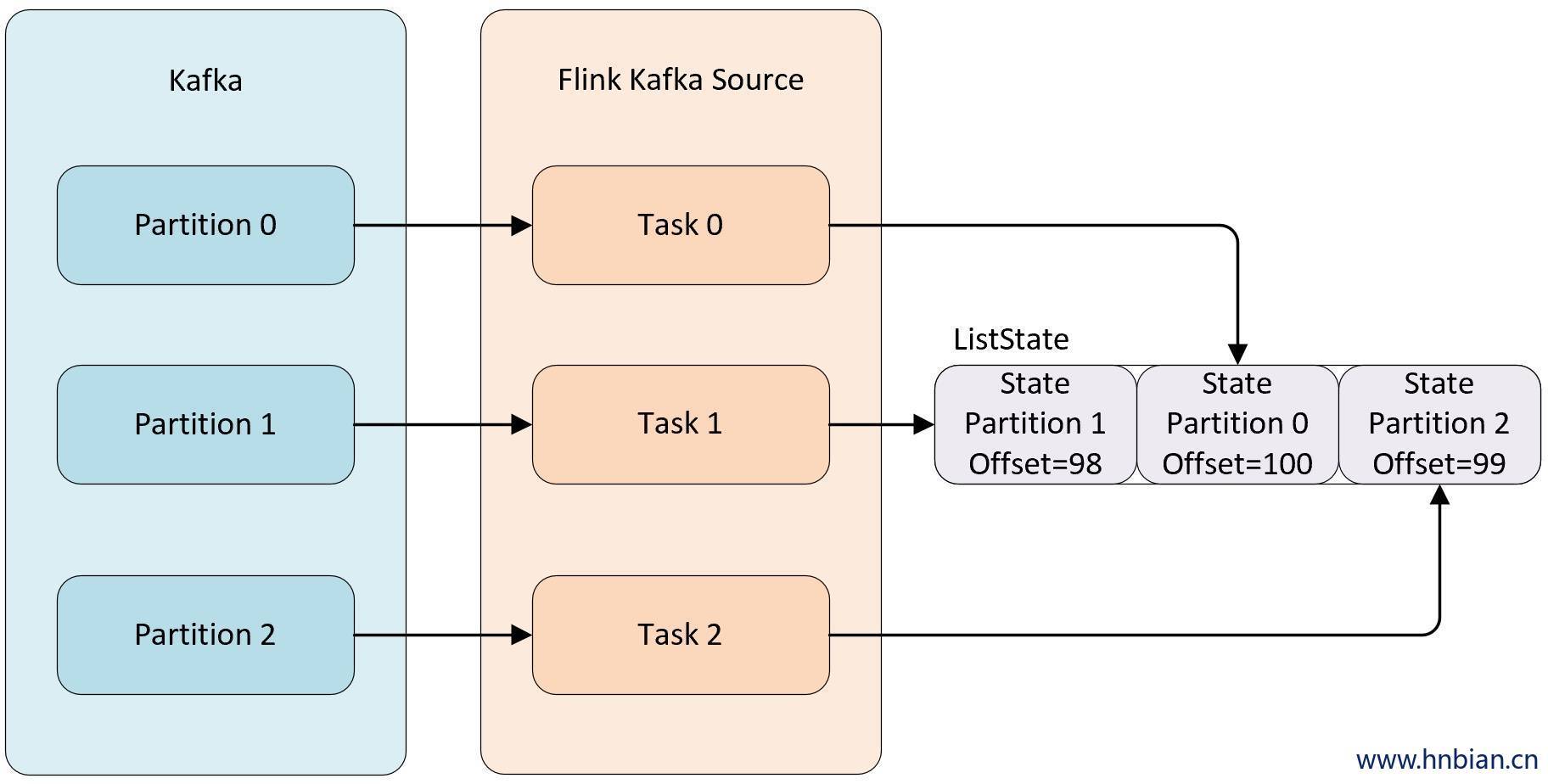
- Union redistribution: 每个算子保存一个列表形式的状态集合。整个状态由所有的列表拼接而成。当作业恢复或重新分配时,每个算子都将获得所有的状态数据。Union redistribution 模式下 checkpoint metadata会存储每个operator 的 subTask 的offset信息。如果List State的基数较大时,不要使用这种方式的redistribution。因为容易引起OOM。
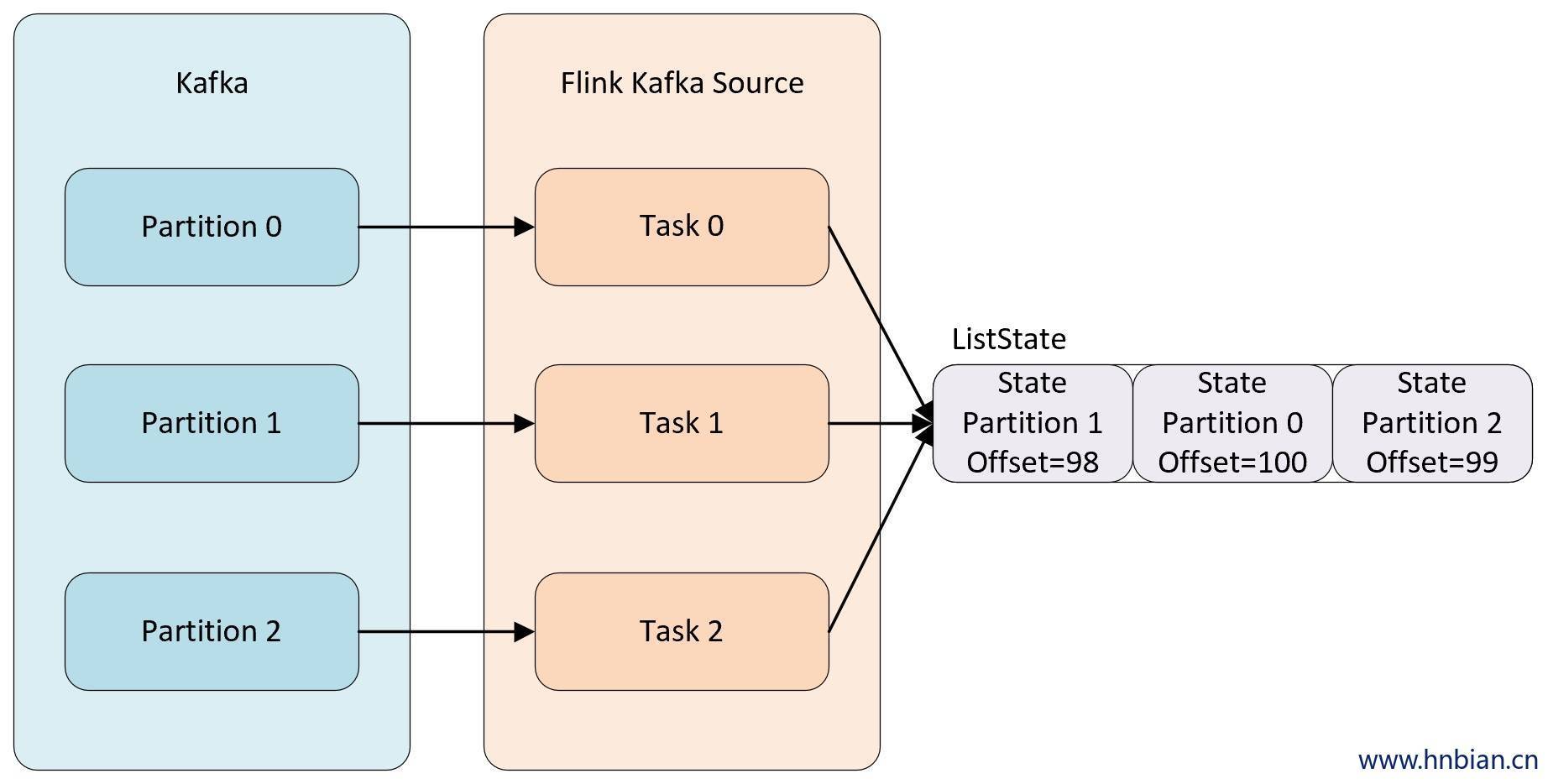
调用不同的获取状态对象的接口,会使用不同的状态分配算法。比如
getUnionListState(descriptor)会使用 union redistribution 算法, 而getListState(descriptor)则简单的使用 even-split redistribution 算法。当初始化好状态对象后,我们通过
isRestored()方法判断是否从之前的故障中恢复回来,如果该方法返回true则表示从故障中进行恢复,会执行接下来的恢复逻辑。
- 广播状态( Broadcast state ):如果一个算子有多项任务,而它的每项任务状态又都相同,那么这种特殊情况最适合应用广播状态。
4. Keyed State 使用示例
4.1 ValueState
单值状态:ValueState [T] 保存单个的值,值的类型为 T
获取状态值:ValueState.value()
更新状态值:ValueState.update(value: T)
import com.hnbian.flink.common.Obj1
import org.apache.flink.api.common.state.{ValueState, ValueStateDescriptor}
import org.apache.flink.api.scala.typeutils.Types
import org.apache.flink.streaming.api.functions.KeyedProcessFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.util.Collector
object TestValueState extends App {
// 创建执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream1: DataStream[String] = env.socketTextStream("localhost",9999)
private val value: DataStream[Obj1] = stream1
.map(data => {
val arr = data.split(",")
Obj1(arr(0), arr(1), arr(2).toLong)
})
private val value1: KeyedStream[Obj1, String] = value.keyBy(_.id)
value1
.process(new TestValueState)
.print("TestValueState")
env.execute()
}
class TestValueState extends KeyedProcessFunction[String, Obj1, String]{
// 定义状态描述符
val valueStateDescriptor = new ValueStateDescriptor[Obj1]("objs", Types.of[Obj1])
lazy val valueState: ValueState[Obj1] = getRuntimeContext.getState(valueStateDescriptor)
override def processElement(value: Obj1, ctx: KeyedProcessFunction[String, Obj1, String]#Context, out: Collector[String]) = {
val prev = valueState.value()
if (null == prev){
// 更新状态
valueState.update(value)
}else{
// 获取状态
val obj1 = valueState.value()
println(s"obj1.time=${obj1.time},value.time=${value.time}")
if (obj1.time < value.time){
// 如果 最新数据时间 大于之前时间,更新状态
valueState.update(value)
}
}
out.collect(value.name)
}
}4.2 ListState
列表状态:ListState [T] 保存一个列表,列表里的元素的数据类型为 T
获取列表状态:ListState.get() 返回 Iterable[T]
添加单个元素到列表状态:ListState.add(value: T)
添加多个元素到列表状态:ListState.addAll(values: java.util.List[T])
添加多个元素更新列表状态的数据:ListState.update(values: java.util.List[T])
import java.util
import com.hnbian.flink.common.Obj1
import org.apache.flink.api.common.state.{ListState, ListStateDescriptor}
import org.apache.flink.api.scala.typeutils.Types
import org.apache.flink.streaming.api.functions.KeyedProcessFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.util.Collector
import scala.collection.mutable.ListBuffer
object TestListState extends App {
// 创建执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream1: DataStream[String] = env.socketTextStream("localhost",9999)
private val value: DataStream[Obj1] = stream1
.map(data => {
val arr = data.split(",")
Obj1(arr(0), arr(1), arr(2).toLong)
})
private val value1: KeyedStream[Obj1, String] = value.keyBy(_.id)
value1
.process(new TestListState)
.print("TestListState")
env.execute()
}
class TestListState extends KeyedProcessFunction[String, Obj1, String]{
// 定义状态描述符
val listStateDescriptor = new ListStateDescriptor[Obj1]("objs", Types.of[Obj1])
private lazy val listState: ListState[Obj1] = getRuntimeContext.getListState(listStateDescriptor)
override def processElement(value: Obj1, ctx: KeyedProcessFunction[String, Obj1, String]#Context, out: Collector[String]) = {
// 获取状态
val iterable: util.Iterator[Obj1] = listState.get().iterator()
val list:ListBuffer[Obj1] = new ListBuffer[Obj1]
while(iterable.hasNext){
list.append(iterable.next())
}
list.append(value)
// 将单个元素加入 listState
//listState.add(value)
if (list.size > 2){
list.remove(0)
}
import scala.collection.JavaConverters.seqAsJavaListConverter
val javaList: util.List[Obj1] = list.toList.asJava
// 使用新的 list 更新 listState
listState.update(javaList)
out.collect(list.toString())
}
}4.3 MapState
映射状态:MapState [K, V] 保存 Key-Value 对
获取数据:MapState.get(key: K)
保存数据:MapState.put(key: K, value: V)
检查是否包含某个 key:MapState.contains(key: K)
移除某个key对应的数据:MapState.remove(key: K)
import com.hnbian.flink.common.Obj1
import org.apache.flink.api.common.state.{MapState, MapStateDescriptor}
import org.apache.flink.api.scala.typeutils.Types
import org.apache.flink.streaming.api.functions.KeyedProcessFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.util.Collector
import scala.collection.mutable.ListBuffer
object TestMapState extends App {
// 创建执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream1: DataStream[String] = env.socketTextStream("localhost",9999)
private val value: DataStream[Obj1] = stream1
.map(data => {
val arr = data.split(",")
Obj1(arr(0), arr(1), arr(2).toLong)
})
private val value1: KeyedStream[Obj1, String] = value.keyBy(_.id)
value1
.process(new TestMapState)
.print("TestMapState")
env.execute()
}
class TestMapState extends KeyedProcessFunction[String, Obj1, String]{
// 定义状态描述符
private val mapStateDescriptor = new MapStateDescriptor[String,ListBuffer[Obj1]]("objs", Types.of[String], Types.of[ListBuffer[Obj1]])
private lazy val mapState: MapState[String, ListBuffer[Obj1]] = getRuntimeContext.getMapState(mapStateDescriptor)
override def processElement(value: Obj1, ctx: KeyedProcessFunction[String, Obj1, String]#Context, out: Collector[String]): Unit = {
// 检查当前 key 是否已经存到 map state
if (mapState.contains(ctx.getCurrentKey)){
// 获取数据
val list: ListBuffer[Obj1] = mapState.get(ctx.getCurrentKey)
if (list.size >=2){
list.remove(0)
list.append(value)
// 添加数据
mapState.put(ctx.getCurrentKey,list)
}else{
list.append(value)
mapState.put(ctx.getCurrentKey,list)
}
}else{
val list: ListBuffer[Obj1] = ListBuffer(value)
// 添加数据
mapState.put(ctx.getCurrentKey,list)
}
out.collect(mapState.values().toString)
}
}4.4 ReducingState
Reduce 聚合操作的状态:ReducingState[T]
获取数据:ReducingState.get()
添加数据:ReducingState.add(T)
import com.hnbian.flink.common.Obj1
import org.apache.flink.api.common.functions.ReduceFunction
import org.apache.flink.api.common.state.{ReducingState, ReducingStateDescriptor}
import org.apache.flink.api.scala.typeutils.Types
import org.apache.flink.streaming.api.functions.KeyedProcessFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.util.Collector
/**
* @Author haonan.bian
* @Description //TODO
* @Date 2021/1/21 16:03
**/
object TestReducingState extends App {
// 创建执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream1: DataStream[String] = env.socketTextStream("localhost",9999)
private val value: DataStream[Obj1] = stream1
.map(data => {
val arr = data.split(",")
Obj1(arr(0), arr(1), arr(2).toLong)
})
private val value1: KeyedStream[Obj1, String] = value.keyBy(_.id)
value1
.process(new TestReducingState)
.print("TestReducingState")
env.execute()
}
class TestReducingState extends KeyedProcessFunction[String,Obj1,String]{
// 定义状态描述符
private val reducingStateDescriptor = new ReducingStateDescriptor[Obj1]("biggerTime", new Reduce,Types.of[Obj1])
lazy private val reducingState: ReducingState[Obj1] = getRuntimeContext.getReducingState(reducingStateDescriptor)
override def processElement(value: Obj1, ctx: KeyedProcessFunction[String, Obj1, String]#Context, out: Collector[String]): Unit = {
reducingState.add(value)
out.collect(reducingState.get().toString)
}
}
// 定义 一个比较 时间的 Reduce Function 函数
class Reduce extends ReduceFunction[Obj1]{
// 输出时间较大的数据
override def reduce(value1: Obj1, value2: Obj1): Obj1 = {
if (value1.time > value2.time){
value1
}else{
value2
}
}
}4.5 AggregatingState
Aggregate 聚合操作的状态:AggregatingState [I, O]
获取数据:AggregatingState.get()
添加数据:AggregatingState.add(T)
import com.hnbian.flink.window.TumblingTimeWIndow.Record
import com.hnbian.flink.window.function.AverageAccumulator
import org.apache.flink.api.common.functions.AggregateFunction
import org.apache.flink.api.common.state.{AggregatingState, AggregatingStateDescriptor}
import org.apache.flink.api.scala.typeutils.Types
import org.apache.flink.streaming.api.functions.KeyedProcessFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.util.Collector
import scala.collection.mutable.ArrayBuffer
object TestAggregatingState extends App {
// 创建执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream1: DataStream[String] = env.socketTextStream("localhost",9999)
private val value: DataStream[Record] = stream1
.map(data => {
val arr = data.split(",")
Record(arr(0), arr(1), arr(2).toInt)
})
private val value1: KeyedStream[Record, String] = value.keyBy(_.classId)
value1
.process(new TestAggregatingState)
.print("TestListState")
env.execute()
}
class TestAggregatingState extends KeyedProcessFunction[String,Record,(ArrayBuffer[Record], Double)]{
// 定义状态描述符
private val aggregatingStateDescriptor = new AggregatingStateDescriptor[Record, AverageAccumulator, (ArrayBuffer[Record], Double)]("agg", new AgeAverageAggregateFunction ,Types.of[AverageAccumulator])
lazy private val aggregatingState: AggregatingState[Record, (ArrayBuffer[Record], Double)] = getRuntimeContext.getAggregatingState(aggregatingStateDescriptor)
override def processElement(value: Record, ctx: KeyedProcessFunction[String, Record, (ArrayBuffer[Record], Double)]#Context, out: Collector[(ArrayBuffer[Record], Double)]): Unit = {
aggregatingState.add(value)
out.collect(aggregatingState.get())
}
}
class AgeAverageAggregateFunction extends AggregateFunction[Record, AverageAccumulator, (ArrayBuffer[Record], Double)] {
override def getResult(accumulator: AverageAccumulator): (ArrayBuffer[Record], Double)= {//
val avg = accumulator.sum./(accumulator.count.toDouble)
(accumulator.records,avg)
}
override def merge(a: AverageAccumulator, b: AverageAccumulator): AverageAccumulator = {
a.count += b.count
a.sum += b.sum
a.records.appendAll(b.records)
a
}
override def createAccumulator(): AverageAccumulator = {
new AverageAccumulator()
}
override def add(value: Record, accumulator: AverageAccumulator): AverageAccumulator = {
accumulator.records.append(value)
accumulator.sum += value.age
accumulator.count+=1
accumulator
}
}4.6 设置状态 TTL
状态还可以设置 TTL(Time To Live),来限制状态的有效时间,状态过期后,存储的值会被自动清理,如果state是集合类型,那么TTL是单独针对每个元素设置的,也就是说每一个List元素、或者是Map的entry都有独立的TTL。
设置TTL后,默认会在读取时自动删除,如果状态配置了backend,则是后台进行垃圾回收。也可以配置禁用后台垃圾回收。
import java.util
import com.hnbian.flink.common.Obj1
import org.apache.flink.api.common.state.{ListState, ListStateDescriptor, StateTtlConfig}
import org.apache.flink.api.common.time.Time
import org.apache.flink.api.scala.typeutils.Types
import org.apache.flink.streaming.api.functions.KeyedProcessFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.util.Collector
import scala.collection.mutable.ListBuffer
/**
* @Author haonan.bian
* @Description //TODO
* @Date 2021/2/8 17:26
**/
object TestTTL extends App {
// 创建执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream1: DataStream[String] = env.socketTextStream("localhost",9999)
private val value: DataStream[Obj1] = stream1
.map(data => {
val arr = data.split(",")
Obj1(arr(0), arr(1), arr(2).toLong)
})
private val value1: KeyedStream[Obj1, String] = value.keyBy(_.id)
value1
.process(new TestTTLValueState)
.print("TestTTL")
env.execute()
}
class TestTTLValueState extends KeyedProcessFunction[String, Obj1, String]{
private val stateTtlConfig: StateTtlConfig = StateTtlConfig
// 设置状态有效期为 10 秒
.newBuilder(Time.seconds(10))
// 在读写数据时都会检查过期数据
.setUpdateType(StateTtlConfig.UpdateType.OnReadAndWrite)
// 不返回过期的数据值
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
.build()
// 定义状态描述符
val listStateDescriptor = new ListStateDescriptor[Obj1]("objs", Types.of[Obj1])
// 设置 TTL
listStateDescriptor.enableTimeToLive(stateTtlConfig)
private lazy val listState: ListState[Obj1] = getRuntimeContext.getListState(listStateDescriptor)
override def processElement(value: Obj1, ctx: KeyedProcessFunction[String, Obj1, String]#Context, out: Collector[String]) = {
// 获取状态
val iterable: util.Iterator[Obj1] = listState.get().iterator()
val list:ListBuffer[Obj1] = new ListBuffer[Obj1]
while(iterable.hasNext){
list.append(iterable.next())
}
list.append(value)
import scala.collection.JavaConverters.seqAsJavaListConverter
val javaList: util.List[Obj1] = list.toList.asJava
// 更新 状态
listState.update(javaList)
out.collect(list.toString())
}
}5. Operator State 使用示例
要在自定义的函数或算子中使用Operator State,可以实现 CheckpointedFunction 接口,这是一个比较通用的接口,既可以管理 Operator State,也可以管理 Keyed State,灵活性比较强。
5.1 CheckpointedFunction 接口介绍
CheckpointedFunction 状态转换功能的核心接口,状态转换功能是指在各个流记录之间维护状态的功能。 虽然存在更多轻量级的接口作为各种类型状态的快捷方式,但此接口在管理键控状态和操作员状态方面提供了最大的灵活性。快捷方式部分说明了设置状态函数的常用轻量级方法,这些方法通常代替该接口表示的完整抽象使用。
- 初始化
当创建转换函数的并行实例进行分布式执行时,
会调用 initializeState(FunctionInitializationContext) 方法。
这个方法提供了对 FunctionInitializationContext 的访问,
而 FunctionInitializationContext 又提供了对 OperatorStateStore 和 KeyedStateStore 的访问。
OperatorStateStore 和 KeyedStateStore 是可以访问应存储状态的数据结构,
这使得 Flink 能够透明地管理和检查状态,
例如 org.apache.flink.api.common.state.ValueState 或 org.apache.flink.api.common.state.ListState。
- 快照
每当检查点获取转换函数的状态快照时,都会调用snapshotState(FunctionSnapshotContext) 。 在此方法内部,函数通常会确保检查点数据结构(在初始化阶段中获得)是最新的,以获取快照。 给定的快照上下文可以访问检查点的元数据。另外,函数可以使用此方法作为挂钩来与外部系统进行刷新/提交/同步。
- CheckpointedFunction 源码
package org.apache.flink.streaming.api.checkpoint;
import org.apache.flink.annotation.PublicEvolving;
import org.apache.flink.api.common.functions.RuntimeContext;
import org.apache.flink.api.common.state.KeyedStateStore;
import org.apache.flink.api.common.state.OperatorStateStore;
import org.apache.flink.runtime.state.FunctionInitializationContext;
import org.apache.flink.runtime.state.FunctionSnapshotContext;
public interface CheckpointedFunction {
/**
* 当请求检查点的快照时,将调用此方法
* 每当执行checkpoint时,会触发该方法
* 这充当函数的钩子,以确保通过初始化FunctionInitializationContext时以前通过FunctionInitializationContext提供的方法或现在由FunctionSnapshotContext本身提供的方法来公开所有状态
*
* @param context operator快照的上下文
* @throws Exception
*/
void snapshotState(FunctionSnapshotContext context) throws Exception;
/**
* 在分布式执行期间创建并行函数实例时,将调用此方法。 函数通常使用此方法设置其状态存储数据结构。
* 每次初始化用户自定义的Function时,会自动调用initializeState()方法
* 从某个checkpoint中恢复,也会调用 initializedState()方法
* 所以,我们在initializedState中初始化不同类型的状态,并且将状态恢复的逻辑也放在里面。
* @param context 用于初始化 operator 的上下文
* @throws Exception
*/
void initializeState(FunctionInitializationContext context) throws Exception;
}进行 checkpoint 时会调用 snapshotState()。 用户自定义函数初始化时会调用 initializeState(),初始化包括第一次自定义函数初始化和从之前的 checkpoint 恢复。 因此 initializeState() 不仅是定义不同状态类型初始化的地方,也需要包括状态恢复的逻辑。
5.2 ListCheckpointed 接口介绍
ListCheckpointed 接口是 CheckpointedFunction 接口的一个简化版本,只支持均匀分布的ListState,并在还原时使用偶数拆分的重新分配方案。不支持全量广播的UnionListState,
该接口可以实现状态重分配功能,当operator的并行度发生更改时,会对状态进行重新分配。Operator State 的状态重新分配始终通过检查点,因此转换功能看起来像故障/恢复组合,其中恢复以不同的并行度进行。
从概念上讲,检查点中的状态是并行转换函数实例返回的所有列表的串联列表。 从检查点还原时,该列表分为分配给每个并行功能实例的子列表。
下图说明了状态重新分配,该函数以并行性运行共有三个 subTask前两个并行实例返回带有两个状态元素的列表,第三个并行实例返回带有以个状态元素

使用 parallelism = 5 恢复检查点将产生以下状态分配:
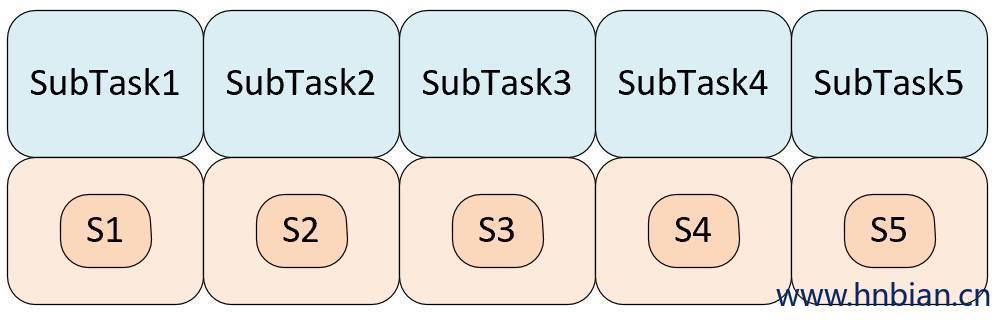
使用 parallelism = 2 恢复检查点将产生以下状态分配:
- ListCheckpointed 源码
package org.apache.flink.streaming.api.checkpoint;
import org.apache.flink.annotation.PublicEvolving;
import org.apache.flink.api.common.functions.RichFunction;
import org.apache.flink.api.common.state.OperatorStateStore;
import org.apache.flink.configuration.Configuration;
import java.io.Serializable;
import java.util.List;
@PublicEvolving
public interface ListCheckpointed<T extends Serializable> {
/**
* 跟CheckpointedFunction中的snapshotState方法一样,这里的snapshotState也是在做备份,但这里的参数列表更加精简,其中checkpointId是一个单调递增的数字,用来表示某次Checkpoint,timestamp是Checkpoint发生的实际时间,这个方法以列表形式返回需要写入存储的状态。
* 还有两种特殊的状态,
* 1. 返回的列表可以为null或为空(如果operator还没有状态),
* 2. 单个元素(如果operator的状态不可分割)。
* @param checkpointId 检查点的ID-唯一且单调递增的值
* @param timestamp 主节点触发检查点时的时间戳。
* @return 可再分配的原子子状态列表中的运算符状态。 不应该返回null,而是返回空列表。
* @throws Exception 如果状态对象的创建失败,则抛出该Exception 。 这将导致检查点失败。 系统可能会决定使操作失败(并触发恢复),或者放弃此检查点尝试并继续运行,并尝试下一次检查点尝试。
*/
List<T> snapshotState(long checkpointId, long timestamp) throws Exception;
/**
* 用来初始化状态,包括作业第一次启动或者作业失败重启
* 故障恢复后执行该功能时,将调用此方法。 如果该功能的特定并行实例不恢复任何状态,则状态列表可能为空。
*
* Important: 与RichFunction一起实现此接口时,将在RichFunction.open(Configuration)之前调用restoreState()方法。
*
* @param state 要恢复为原子子状态列表的状态,是一个列表形式的状态,均匀分布给这个算子子任务的状态数据
* @throws Exception 在此方法中引发异常会导致恢复失败。 确切的结果取决于配置的故障处理策略,但是通常系统会重新尝试恢复,或者尝试从其他检查点恢复。
*/
void restoreState(List<T> state) throws Exception;
}示例
下面示例说明了如何实现MapFunction来对通过它的所有元素进行计数,并在重新缩放(更改或并行)的情况下保持总计数准确:
public class CountingFunction<T> implements MapFunction<T, Tuple2<T, Long>>, ListCheckpointed<Long> {
// 记录并行子任务中的元素数的计数器
private long count;
{@literal @}Override
public List<Long> snapshotState(long checkpointId, long timestamp) {
// 返回 count
return Collections.singletonList(count);
}
{@literal @}Override
public void restoreState(List<Long> state) throws Exception {
// in case of scale in, this adds up counters from different original subtasks
// in case of scale out, list this may be empty
// 如果减少并行度,则将来自不同原始子任务的计数器相加
// 如果增加并行度,列表可能为空
for (Long l : state) {
count += l;
}
}
{@literal @}Override
public Tuple2<T, Long> map(T value) {
count++;
return new Tuple2<>(value, count);
}
}5.3 List state 使用示例
import java.lang
import org.apache.flink.api.scala.createTypeInformation
import org.apache.flink.configuration.Configuration
import org.apache.flink.runtime.state.{FunctionInitializationContext, FunctionSnapshotContext}
import org.apache.flink.streaming.api.checkpoint.CheckpointedFunction
import org.apache.flink.streaming.api.functions.source.{RichSourceFunction, SourceFunction}
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
import scala.collection.mutable.ArrayBuffer
import scala.util.Random
object TestListState extends App {
// 创建执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
import org.apache.flink.runtime.state.filesystem.FsStateBackend
import org.apache.flink.streaming.api.CheckpointingMode
import org.apache.flink.streaming.api.environment.CheckpointConfig
env.enableCheckpointing(5000)
// 使用文件存储的状态后端
val stateBackend = new FsStateBackend("file:///opt/flink-1.10.2/checkpoint",true)
env.setStateBackend(stateBackend)
// 设置检查点模式(精确一次 或 至少一次)
env.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE)
// 设置两次检查点尝试之间的最小暂停时间
env.getCheckpointConfig.setMinPauseBetweenCheckpoints(500)
// 设置检查点超时时间
env.getCheckpointConfig.setCheckpointTimeout(30 * 1000)
// 设置可能同时进行的最大检查点尝试次数
env.getCheckpointConfig.setMaxConcurrentCheckpoints(1)
// 使检查点可以在外部保留
env.getCheckpointConfig.enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION)
private val stream: DataStream[String] = env.addSource(new WordDataSourceWithState)
stream.print("TestListState")
env.execute()
}
class WordDataSourceWithState extends RichSourceFunction[String] with CheckpointedFunction{
var isCancel:Boolean = _
val words = ArrayBuffer("hadoop", "spark", "linux", "flink", "flume", "oozie", "kylin")
var totalCount:BigInt = _
var random:Random = _
import org.apache.flink.api.common.state.ListState
var listState: ListState[BigInt] = null
override def open(parameters: Configuration): Unit = {
isCancel = false
totalCount = 0
random = new Random
}
override def run(ctx: SourceFunction.SourceContext[String]): Unit = {
while(!isCancel){ // 如果 source 启动,
if (totalCount.intValue() % 10 == 0){
// 发送数据
ctx.collect("primitive");
}else{
ctx.collect(words(random.nextInt(words.length)))
}
totalCount = totalCount+1
Thread.sleep(random.nextInt(3000))
}
}
override def snapshotState(context: FunctionSnapshotContext): Unit = {
// 快照状态
listState.clear
listState.add(totalCount)
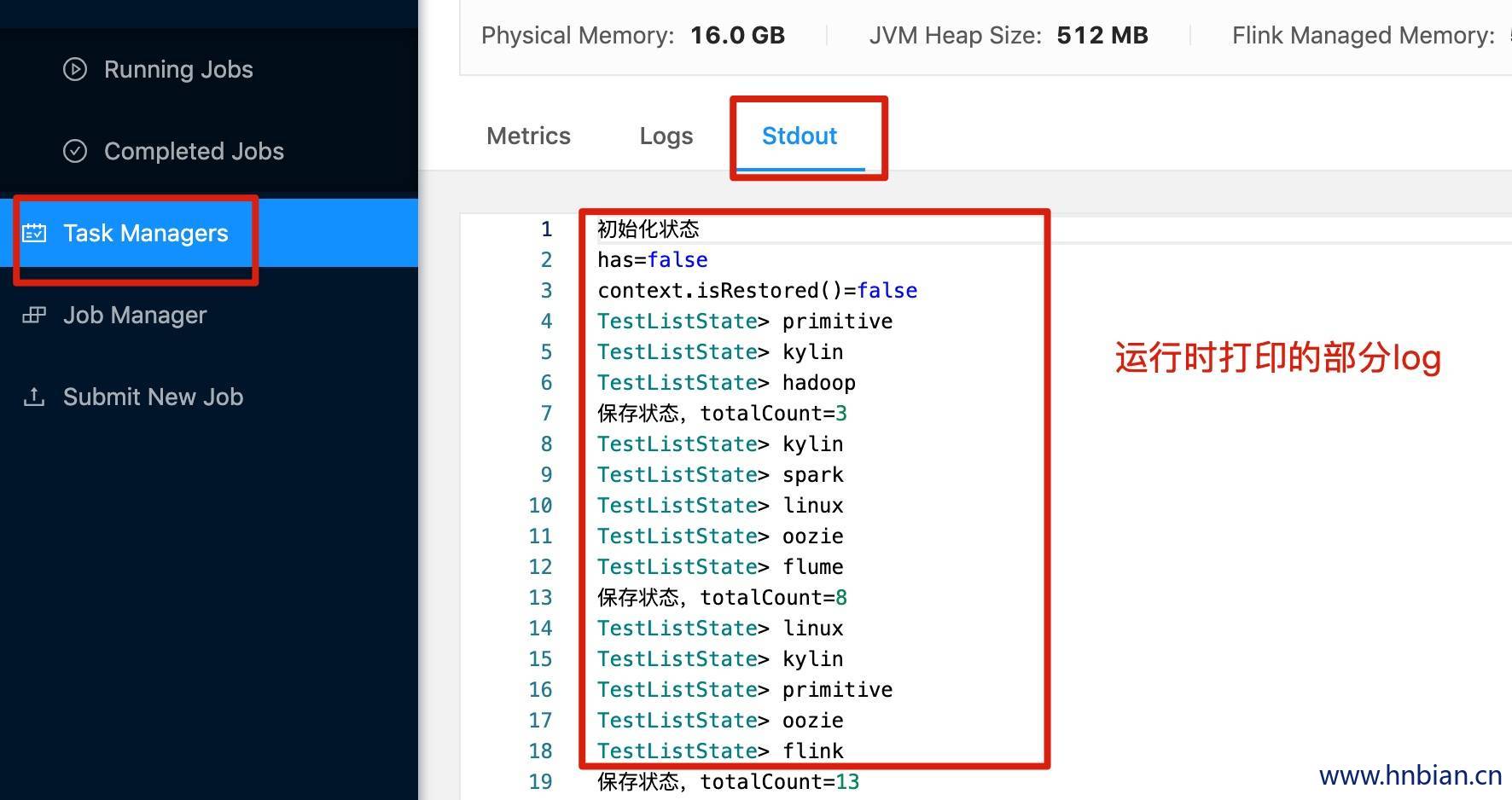
println(s"保存状态,totalCount=${totalCount}")
}
/**
* initializeState 方法接收一个 FunctionInitializationContext 参数,
* 会用来初始化 non-Keyed State 的 “容器”。
* 这些容器是一个 ListState 用于在 checkpoint 时保存 non-Keyed State 对象。
* @param context
*/
override def initializeState(context: FunctionInitializationContext): Unit = {
import org.apache.flink.api.common.state.ListStateDescriptor
import org.apache.flink.api.common.typeinfo.TypeInformation
println("初始化状态")
// 1. 构建StateDesccriptor
val totalCountListStateDescriptor = new ListStateDescriptor[BigInt]("total_count", TypeInformation.of(classOf[BigInt]))
// 2. 构建Operator State 使用的是 Even-split redistribution 数据分布模式
listState = context.getOperatorStateStore().getListState(totalCountListStateDescriptor)
// 2. 构建Operator State 使用的是 Union redistribution 数据分布模式
// listState = context.getOperatorStateStore().getListState(totalCountListStateDescriptor)
val iterTotalCnt2: lang.Iterable[BigInt] = listState.get
val has = iterTotalCnt2.iterator().hasNext
println(s"has=$has")
println(s"context.isRestored()=${context.isRestored()}")
// 恢复 totalCount
if (context.isRestored()){
println("恢复数据")
val iterTotalCnt: lang.Iterable[BigInt] = listState.get
import java.util
val iterator: util.Iterator[BigInt] = iterTotalCnt.iterator
if (iterator.hasNext) {
totalCount = iterator.next
println(s"恢复数据,totalCount=${totalCount}")
}
}
}
override def cancel(): Unit = {
isCancel = true
}
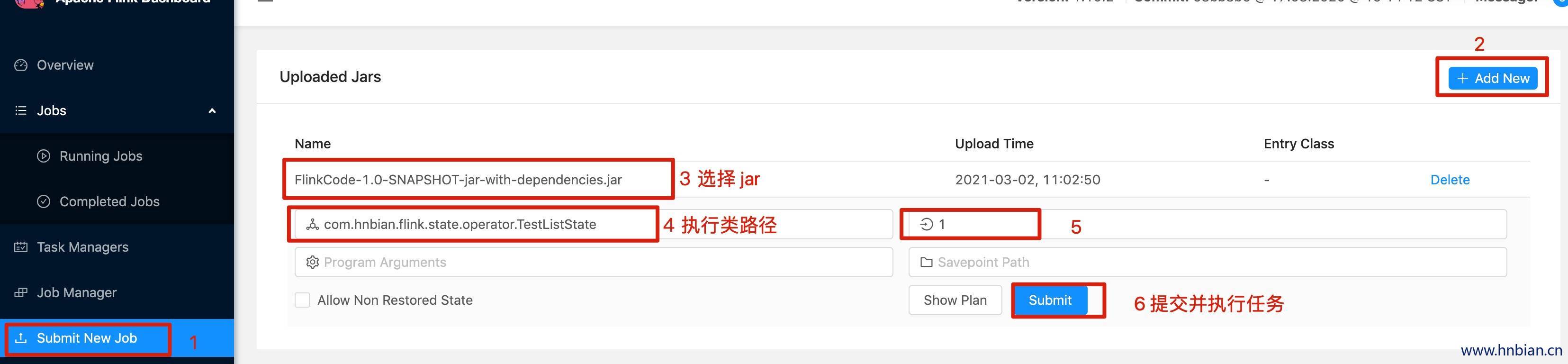
}- 启动 Flink 集群,将代码打包提交任务到 flink 集群,然后查看结果
- 查看打印的日志
- 查看 checkpoint 保存的状态数据
hnbiandeMacBook-Pro:~ hnbian$ cd /opt/flink-1.10.2/checkpoint/9a4163a1d00b4ed51a4387c2bd341d72/
hnbiandeMacBook-Pro:9a4163a1d00b4ed51a4387c2bd341d72 hnbian$ pwd
/opt/flink-1.10.2/checkpoint/9a4163a1d00b4ed51a4387c2bd341d72
hnbiandeMacBook-Pro:9a4163a1d00b4ed51a4387c2bd341d72 hnbian$ ll
total 0
drwxr-xr-x 2 hnbian wheel 64B Mar 2 11:04 shared
drwxr-xr-x 2 hnbian wheel 64B Mar 2 11:04 taskowned
drwxr-xr-x 3 hnbian wheel 96B Mar 2 11:06 chk-32
hnbiandeMacBook-Pro:9a4163a1d00b4ed51a4387c2bd341d72 hnbian$ cd chk-32/
hnbiandeMacBook-Pro:chk-32 hnbian$ ll
total 8
-rw-r--r-- 1 hnbian wheel 903B Mar 2 11:06 _metadata
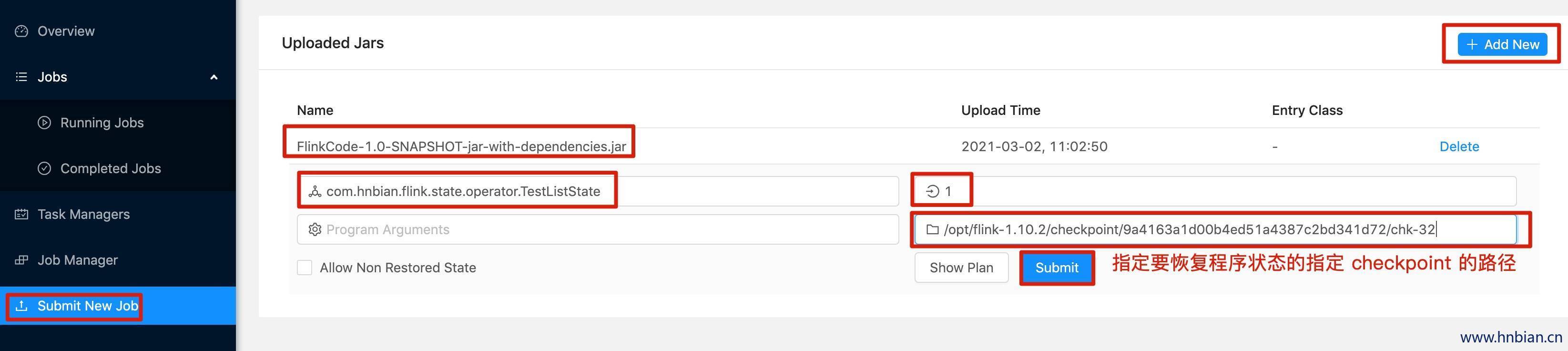
# 能够看到,状态数据已经保存到 checkpoint 路径中- 关闭程序,并从 checkpoint 恢复程序状态
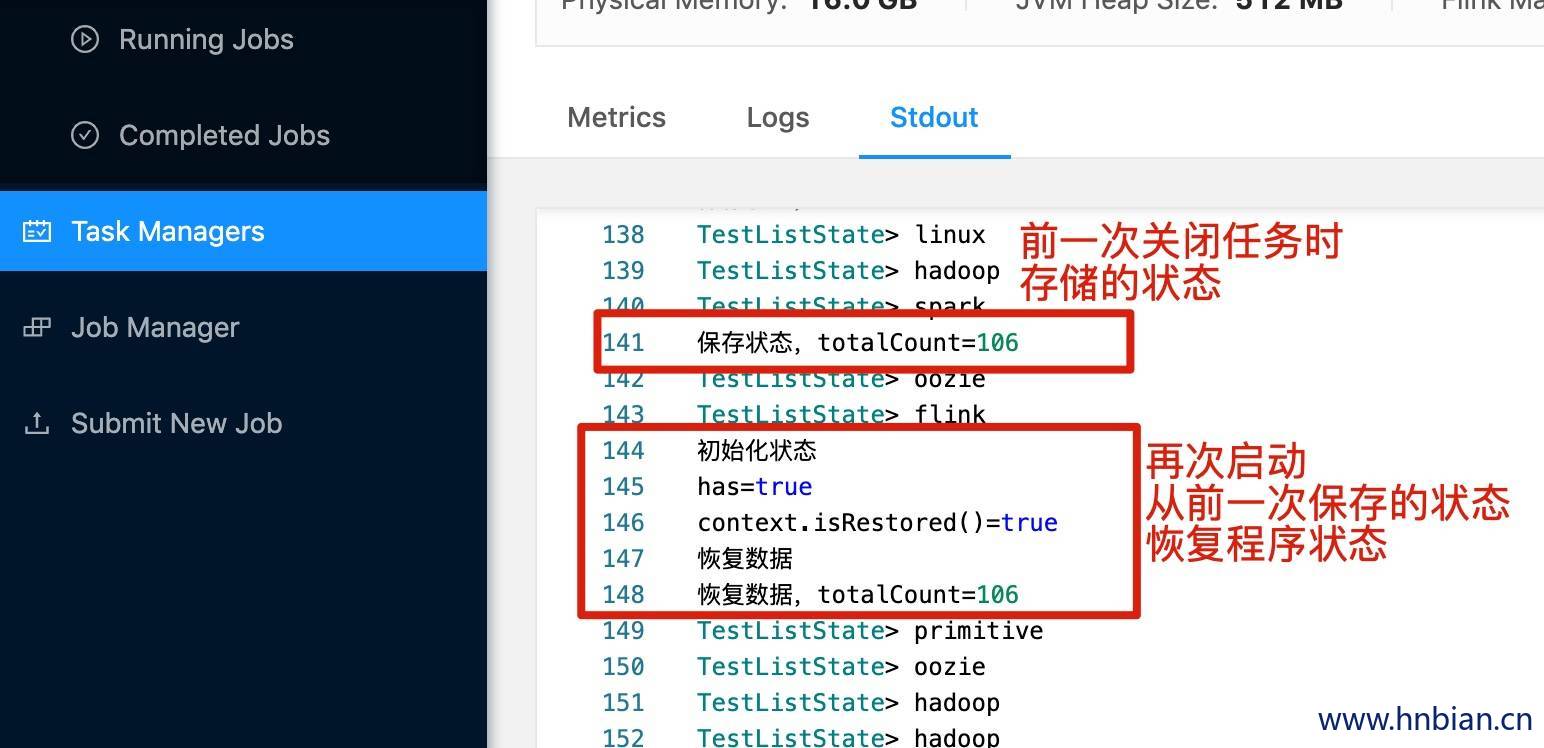
5.4 Broadcast state 使用示例
Broadcast State(广播状态),可以将一个流中的数据广播到下游算子的每个 task中,使得这些数据再所有的 task 中共享,比如用于配置的一些数据,通过Broadcast state,我们可以让下游的每一个task,配置保持一致,当配置有修改时也能够使用Broadcast State 对下游每个 task 中的相关配置进行变更。
Broadcast State比较适合这种场景,假设我们做一个规则匹配事件处理系统,规则是一个低吞吐的流、而事件是一个高吞吐的流。我们可以将规则以Broadcast State的方式发送到下游每一个任务中,然后当有事件需要处理时,可以从广播中读取之前的规则,进行处理。
Broadcast State是一个Map结构,它比较适合于一个broadcast stream、另外一个不是broadcast stream的两个流进行相关操作的场景。
- 测试代码
import com.hnbian.flink.common.{Class, Student}
import com.hnbian.flink.process. TestBroadcastProcessFunction
import org.apache.flink.api.common.state.{BroadcastState, MapStateDescriptor}
import org.apache.flink.api.common.typeinfo.BasicTypeInfo
import org.apache.flink.api.scala.createTypeInformation
import org.apache.flink.api.scala.typeutils.Types
import org.apache.flink.streaming.api.datastream.BroadcastStream
import org.apache.flink.streaming.api.functions.co.BroadcastProcessFunction
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
import org.apache.flink.util.Collector
object TestBroadcastState extends App {
// 创建执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream1: DataStream[String] = env.socketTextStream("localhost",9999)
val stream2: DataStream[String] = env.socketTextStream("localhost",8888)
private val StudentStream: DataStream[Student] = stream1
.map(data => {
val arr = data.split(",")
Student(arr(0), arr(1), arr(2))
})
val descriptor = new MapStateDescriptor[String, String]("classInfo", BasicTypeInfo.STRING_TYPE_INFO, BasicTypeInfo.STRING_TYPE_INFO)
val ClassStream: DataStream[Class] = stream2.map(data => {
val arr = data.split(",")
Class(arr(0), arr(1))
})
val ClassBradoStream: BroadcastStream[Class] = ClassStream.broadcast(descriptor)
StudentStream
.connect(ClassBradoStream)
.process(new CustomBroadcastState)
.print("CustomBroadcastState")
env.execute()
}
/**
* 参数
* 未广播数据类型
* 广播数据类型
* 输出数据类型
*/
class CustomBroadcastState extends BroadcastProcessFunction[Student,Class,String]{
private val mapStateDescriptor = new MapStateDescriptor[String,String]("maps", Types.of[String], Types.of[String])
override def processElement(value: Student, ctx: BroadcastProcessFunction[Student, Class, String]#ReadOnlyContext, out: Collector[String]): Unit = {
val classInfo = ctx.getBroadcastState(TestBroadcastProcessFunction.descriptor)
val className: String = classInfo.get(value.classId)
out.collect(s"stuId:${value.id} stuName:${value.name} stuClassName:${className}")
}
override def processBroadcastElement(value: Class, ctx: BroadcastProcessFunction[Student, Class, String]#Context, out: Collector[String]): Unit = {
val classInfo: BroadcastState[String, String] = ctx.getBroadcastState(mapStateDescriptor)
println("更新状态")
classInfo.put(value.id,value.name)
}
}
