1. 介绍 除了 MergeTree 家族的表引擎之外,clickhouse 还支持外部存储、内存、日志等多个种类的表引擎,每个种类的表引擎下面都对应多种表引擎。
外部存储系列的表引擎:能够直接读取其他系统的数据,clickhouse 只需要管理元数据即可类似于外挂表的形式。
内存系列的表引擎:能够充当数据分发的临时存储载体或通道
日志文件系列的表引擎:拥有简单易用的特点,
接口系列的表引擎:能够串联已有的数据表,起到粘合剂的作用,
在后续会介绍上面各个系列的表引擎,接下来就介绍外部存储系列的表引擎。
2. 外部存储系列的表引擎 外部存储系列引擎直接从外部存储系统读取数据,例如读取 HDFS 或 MYSQL 中的数据,这些表只负责元数据的管理与数据的查询,通常表引擎不会负责数的插入工作,数据文件直接由外部系统提供。
3.HDFS HDFS 是一个开源的分布式存储系统, 在 Hadoop 生态中具有非常重要的作用,clickhouse 的 HDFS 表引擎可直接与 HDFS 进行对接。
在测试 HDFS表引擎之前需要确保 HDFS 环境已经安装好了,如果没有安装好,可以参考 之前的文章,安装 ambari 从而安装 HDFS 或者直接安装 Hadoop 环境
Ambari 介绍 一、环境安装 或 Hadoop 环境部署文档
3.1 语法 1 2 3 4 5 6 7 8 9 10 11 12 13 CREATE TABLE [IF NOT EXISTS ] [db_name.] table_name ( name1 [type] [DEFAULT | MATERIALIZED| ALIASexpr], name2[type][DEFAULT | MATERIALIZED| ALIASexpr], ... ) ENGINE = HDFS(hdfs_uri,format) / / hdfs_uri:hdfs 的文件存储路径 / / format:文件格式,常见格式有 CSV、TSV、JSON等
HDFS 表引擎通常有两种使用形式:
只能读取数据,数据写入工作由其他外部操作系统完成
即能读也可以写入数据
3.2 可以读写数据的表 1 2 3 4 5 6 # 在hdfs 创建 clickhouse 文件夹 hadoop fs -mkdir /clickhouse # 给 clickhouse 用户授权 hadoop fs -chown -R clickhouse:clickhouse /clickhouse
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 / / 定义数据表create table t_hdfs( id UInt32, code String, name String, )ENGINE= HDFS('hdfs://node3:8020/clickhouse/t_hdfs' ,'csv' ) / / 配置 hdfs:/ / node3:8020 / clickhouse/ t_hdfs 为存储数据的文件的绝对路径/ / 存储数据文件格式为 CSV/ / 写入数据insert into t_hdfs select number, concat('code' ,toString(number)), concat('n' ,toString(number)) from numbers(5 );/ / 查询数据select * from t_hdfs;/ / 查看 hdfs 上的文件有什么变化hadoop fs - cat / clickhouse/ t_hdfs / / 删除 表drop table t_hdfs/ / 查看 hdfs 中的数据文件hadoop fs - cat / clickhouse/ t_hdfs 文件依然存在
3.3 只能读数据的表 这种形式类似于 Hive 的外部表,由其他系统直接将数据文件写入 HDFS,通过 HDFS 表引擎的 hdfs_uri 和 format 参数分别与 HDFS 的文件路径,文件格式建立映射。其中 hdfs_uri 支持一下几种常见的配置方法:
配置方式
说明
绝对路径
会读取指定路径的单个文件,例如/clickhouse/t_hdfs
* 通配符
匹配所有字符,如 /clickhouse/t_hdfs/* 会匹配 /clickhouse/t_hdfs/* 路径下的所有文件
?通配符
匹配单个字符,如 /clickhouse/t_hdfs/emp_?.csv /clickhouse/t_hdfs/ 路径下的所有 名字为emp_?.csv 的文件,? 为任意的一个合法字符
{M..N} 数字区间
匹配指定数字的文件,如 /clickhouse/t_hdfs/emp_{1..3}.csv 则会匹配/clickhouse/t_hdfs/emp_1.csv /clickhouse/t_hdfs/emp_2.csv /clickhouse/t_hdfs/emp_3.csv
1 2 3 4 5 # 上传数据文件到 hdfs hadoop fs -put t_hdfs2_1.csv /clickhouse/t_hdfs2/ hadoop fs -put t_hdfs2_2.csv /clickhouse/t_hdfs2/ hadoop fs -put t_hdfs2_3.csv /clickhouse/t_hdfs2/
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 # 创建表 create table t_hdfs2( id UInt32, code String, name String, )ENGINE= HDFS('hdfs://node3:8020/clickhouse/t_hdfs2_?.csv' ,'csv' ) / / 或者ENGINE= HDFS('hdfs://node3:8020/clickhouse/*' ,'csv' ) / / 或者ENGINE= HDFS('hdfs://node3:8020/clickhouse/t_hdfs2_{1..3}.csv' ,'csv' ) # 查询数据 select * from t_hdfs2
4.MYSQL MySQL 表引擎可以与 MySQL 数据库中的表建立映射,并通过 SQL 向其发起远程查询,包括 select 和 insert 操作。
4.1 语法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 CREATE TABLE [IF NOT EXISTS ] [db_name.] table_name ( name1 [type] [DEFAULT | MATERIALIZED| ALIASexpr], name2[type][DEFAULT | MATERIALIZED| ALIASexpr], ... ) ENGINE = MySQL('host:port' ,'database' ,'table' ,'user' ,'password' ,[replace_query,'on_duplicate_clause' ]) / / host:port MySQL 地址和端口号 / / database 数据库名称 / / table 要映射的表 / / user 用户名 / / password 密码 / / replace_query 默认为 0 ,对应 MySQL 的 replace into 语法,如果设置为 1 ,则使用 replace into 代替 insert into / / on_duplicate_clause 默认为 0 ,对应 MySQL 的 on duplicate key 语法,如果需要使用该设置,则必须将 replace_query 设置为0
4.2 使用示例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 / / 先创建一张 MySQL 表CREATE TABLE `t_mysql` ( `id` varchar (20 ) DEFAULT NULL , `name` varchar (20 ) DEFAULT NULL ) INSERT INTO `test`.`t_mysql`(`id`, `name`) VALUES ('1' , 'xiaoming' );INSERT INTO `test`.`t_mysql`(`id`, `name`) VALUES ('2' , 'xiaohong' );/ / 在 clickhouse 中创建 MySQL 引擎表create table t_mysql( id String, name String )ENGINE= MySQL('192.168.98.99:3306' ,'test' ,'t_mysql' ,'root' ,'root' ) / / 查询数据 select * from t_mysql; ┌─id─┬─name─────┐ │ 1 │ xiaoming │ │ 2 │ xiaohong │ └────┴──────────┘ / / 写入数据insert into t_mysql values ('3' ,'xiaogang' );/ / 查询数据 select * from t_mysql; ┌─id─┬─name─────┐ │ 1 │ xiaoming │ │ 2 │ xiaohong │ │ 3 │ xiaogang │ └────┴──────────┘ / / 在 MySQL 中查询依然可以查询到刚刚写入的数据
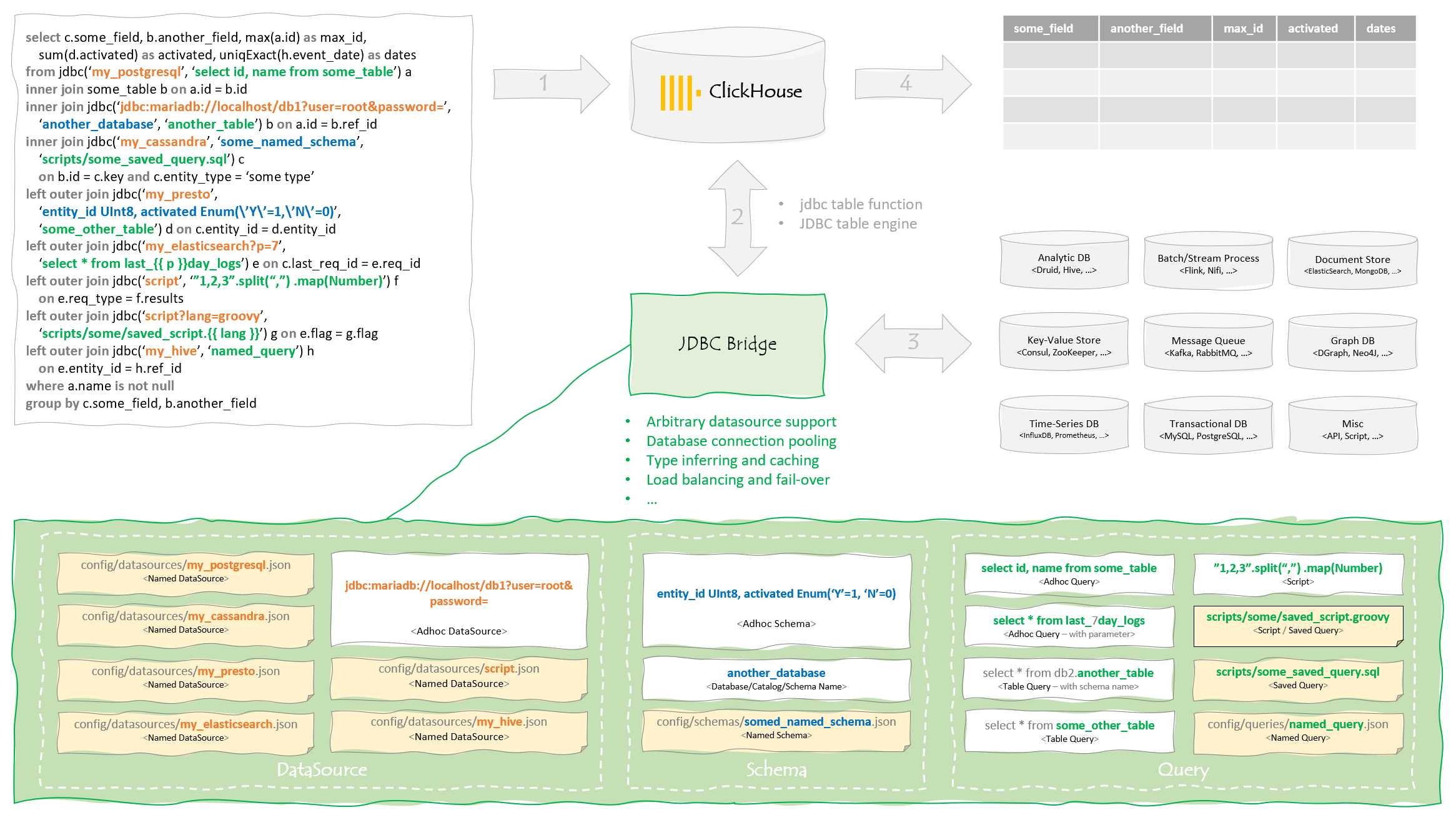
5.JDBC 相对于 MySQL 表引擎而言,JDBC 表引擎,不仅可以对接 MySQL 数据库,还能够与 PostgreSQL、SQLite 等数据库对接,但是 JDBC 表引擎还无法单独完成所有工作,它需要依赖名为 clickhouse-jdbc-bridge 的查询代理服务, clickhouse-jdbc-bridge可以为 clickhouse 代理访问其他的数据库,并自动转换数据类型,
clickhouse-jdbc-bridge 是一款基于 Java 与语言编写的 SQL 代理服务,项目地址为 https://github.com/ClickHouse/clickhouse-jdbc-bridge
clickhouse 数据类型与 JDBC 标准数据类型对应关系
clickhouse 数据类型
JDBC 数据类型
Int8
TINYINT
Int16
SMALLINT
Int32
INTEGER
Int64
BIGINT
Float32
FLOAT
Float32
REAL
Float64
DOUBLE
DateTime
TIMESTAMP
DateTime
TIME
Date
DATE
UInt8
BIT
UInt8
BOOLEAN
String
CHAR
String
VARCHAR
String
LONGVARCHAR
clickhouse-jdbc-bridge 的构建方式是通过 maven 打包,clickhouse-jdbc-bridge-1.0.jar
5.1 配置 说明
在使用 clickhouse-jdbc-bridge 之前需要先启动 clickhouse-jdbc-bridge代理服务
1 2 3 4 java -jar clickhouse-jdbc-bridge-1.0.jar --driver-path /opt/clickhouse-jdbc-driver --listen-host node3:9019
配置代理服务
1 2 3 4 5 6 7 8 9 vim /etc/clickhouse-server/config.xml <jdbc_bridge> <host>node3</host> <port>9019</port> </jdbc_bridge>
5.2 语法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 CREATE TABLE [IF NOT EXISTS ] [db_name.] table_name ( name1 [type] [DEFAULT | MATERIALIZED| ALIASexpr], name2[type][DEFAULT | MATERIALIZED| ALIASexpr], ... ) ENGINE = MySQL('jdbc:url' ,'database' ,'table' ) / / jdbc:url 要对接的数据库地址 / / database 数据库名称 / / table 要映射的表
5.3 使用示例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 / / 在 clickhouse 中创建 MySQL 引擎表create table t_jdbc( id String, name String )ENGINE= JDBC('jdbc:mysql://192.168.71.100:3306/test?user=root&password=root' ,'test' ,'t_mysql' ) / / 查询数据select * from t_jdbc┌─id─┬─name─────┐ │ 1 │ xiaoming │ │ 2 │ xiaohong │ │ 3 │ xiaogang │ └────┴──────────┘ / / 观察 clickhouse 日志 < Debug> executeQuery: (from [::1 ]:50652 , using production parser) select * from t_jdbc; / / 可以看到每次select 请求之前会先向 clickhouse- jdbc- bridge 发送一次 ping 请求,看代理是否启动< Trace> ReadWriteBufferFromHTTP: Sending request to http:/ / node3:9019 / ping/ / 如果 ping 服务器访问不到或者返回值不是 “ok” 那么将会提示错误
除了 JDBC 表引擎之外,还可以使用 jdbc 函数 通过 clickhouse-jdbc-bridge 访问数据表,如
1 2 3 4 5 6 7 root select * from jdbc('jdbc:mysql://192.168.71.100:3306/test?user=root&password=root' ,'test' ,'t_mysql' ); ┌─id─┬─name─────┐ │ 1 │ xiaoming │ │ 2 │ xiaohong │ │ 3 │ xiaogang │ └────┴──────────┘
6.KAFKA
使用 kafka 表引擎前需要将 kafka 环境安装好
在消息系统的三层语义中,clickhouse 的 kafka 引擎只支持At least once 。
kafka 表引擎底层负责与 kafka 通信的部分是基于 librdkafka 实现的额,这是一个由 C++实现的 kafka 库,地址为 https://github.com/edenhill/librdkafka
librdkafka 提供了许多自定义配置参数,如在默认情况下,他每次只会读取 kafka topic 中最新的数据 (auto.offset.reset=largest)如果将其改为 earlies 后,将会从头读取
clickhouse 对librdkafka的自定义参数提供了良好的扩展支持,clickhouse 的全局设置中,提供了一组 kafka 标签,专门用于定义 librdkafka 的自定义参数,不过librdkafka 的原生参数使用了 “.” 进行连接,在 clickhouse 中需要改为 “_” 如:
1 2 3 4 <kafka > <auto_offset_reset > smallest</auto_offset_reset > </kafka >
6.1 语法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 CREATE TABLE [IF NOT EXISTS ] [db_name.] table_name ( name1 [type] [DEFAULT | MATERIALIZED| ALIASexpr], name2[type][DEFAULT | MATERIALIZED| ALIASexpr], ... ) ENGINE = kafka() SETTING kafka_broker_list= 'host:port,...' , kafka_topic_list= 'topic1,...' , kfaka_group_name= 'group_name' , kafka_format= 'data_format' , [kafka_row_delimiter= 'delimiter_symbol' ] [kafka_schema= '' ] [kafka_num_consumers= n] [kafka_skip_broken_messages= n] [kafka_commit_every_batch= n]
配置
说明
kafka_broker_list
必填, broker 服务地址列表,多个 broker 之间用 “,” 分隔
kafka_topic_list
必填,订阅的topic 名称,多个 topic 使用”,”分隔,多个 topic 的数据均会被消费
kfaka_group_name
必填,消费组名称,
kafka_format
必填,解析 消费 kafka 中的数据格式,数据格式必须是 clickhouse 支持的数据格式,如 TSV、CSV、JSON 等
kafka_row_delimiter
选填,判断一行数据的结束符,默认 ‘\0’
kafka_schema
选填,对应 kafka 的 schema 参数
kafka_num_consumers
选填,消费者数量,默认值为 1,表引擎会依据此配置在消费组开启响应数量的消费者线程。
kafka_skip_broken_messages
选填,当 kafka 表引擎按照约定格式解析数据出现错误时,允许跳过失败的数据行数,
kafka_commit_every_batch
选填,执行 kafka commit 的频率,默认为 0,即当一个完整的 block 数据块完全写入后才执行一次 commit,如果设置为 1,则没写完一个 batch 批次,就会执行一次 kafka commit
stream_poll_timeout_ms
选填,kafka 表引擎拉取数据的时间间隔,默认 500 毫秒,数据会先被缓存,之后写入到表
stream_flush_interval_ms
选填,缓存刷新时间间隔,默认 7500 毫秒
6.3 使用示例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 [root@node3 kafka_2.11-2.2.2]# bin/kafka-topics.sh --zookeeper localhost:2181 --create --topic test1 --partitions 1 --replication-factor 1 Created topic test1. [root@node3 kafka_2.11-2.2.2]# [root@node3 kafka_2.11-2.2.2]# bin/kafka-topics.sh --zookeeper localhost:2181 --describe --topic test1 Topic:test1 PartitionCount:1 ReplicationFactor:1 Configs: Topic: test1 Partition: 0 Leader: 0 Replicas: 0 Isr: 0 bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test1 {"id" :1,"code" :"code1" ,"name" :"name1" } {"id" :2,"code" :"code2" ,"name" :"name2" } {"id" :3,"code" :"code3" ,"name" :"name3" } bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test1
上图中有四类角色
A 数据表 :充当数据管道,负责拉取 kafka topic 中的数据,
B 数据表:面向终端用户的查询数据的表,一般使用 MergeTree 系列的表引擎
C 物化视图:负责将 A 的数据同步到 B
D 客户端 :查询 B 数据表中的数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 / / 创建 kafka 数据通道,消费组为 clickhouse,数据格式为 JSONEachRowcreate table t_kafka( id UInt32, code String, name String ) ENGINE Kafka() SETTINGS kafka_broker_list= '192.168.71.100:6667' , kafka_topic_list= 'test1' , kafka_group_name= 'clickhouse' , kafka_format= 'JSONEachRow' ; / / 创建面向用户的数据表create table t_kafka_to_client( id UInt32, code String, name String ) ENGINE MergeTree() order by id;/ / 创建物化视图create MATERIALIZED VIEW db2.consumer TO t_kafka_to_client as select id,code,name from t_kafka;
向 kafka test1 topic 中发送数据测试
1 2 3 4 [root@node3 kafka_2.11-2.2.2]# bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test1 >{"id":1,"code":"code1","name":"name1"} >{"id":2,"code":"code2","name":"name2"} >{"id":3,"code":"code3","name":"name3"}
1 select * from t_kafka_to_client
1 2 3 4 5 6 7 8 9 10 11 12 13 / / 删除视图drop view consumer;/ / 卸载视图DETACH view consumer; 装载视图 ATTACH MATERIALIZED VIEW consumer TO t_kafka_to_client ( id UInt32, code String, name String ) select id,code,name from t_kafka;
7.FILE File 表引擎可以直接读取本地文件的数据,通常被作为一种扩充手段来使用,例如可以使用 file 引擎读取由其他系统生成的数据文件,如果外部系统直接修改了文件,则变向达到了更新数据的目的。它可以将 clickhouse 数据导出为本地文件,还可以用于数据格式转换等场景,file 表引擎还可以用于 clickhouse-local 工具。
7.1 语法 1 2 3 4 5 6 7 8 9 10 11 12 13 CREATE TABLE [IF NOT EXISTS ] [db_name.] table_name ( name1 [type] [DEFAULT | MATERIALIZED| ALIASexpr], name2[type][DEFAULT | MATERIALIZED| ALIASexpr], ... ) ENGINE = File(format) / / format 表示数据中的文件格式,其类型必须是 clickhouse 支持的格式,如 TSV、CSV、JSON 等。
7.1 使用示例 1 2 3 4 5 6 create table t_file( id String, name String )ENGINE= File(CSV); insert into t_file values ('1' ,'xiaoming' ),('2' ,'xiaohong' );
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 cd /var/lib/clickhouse/data/default/t_file[root@node3 t_file]# cat data.CSV "1" ,"xiaoming" "2" ,"xiaohong" "3" ,"xiaohua" select * from t_file; ┌─id ─┬─name─────┐ │ 1 │ xiaoming │ │ 2 │ xiaohong │ │ 3 │ xiaohua │ └────┴──────────┘