1. CEP 是什么
CEP 是 Complex Event Processing 三个单词的缩写,表示复杂事件处理。
CEP 是 Flink 专门为我们提供的一个基于复杂事件监测处理的库。
CEP 通过一个或多个由简单事件构成的事件流通过一定的规则匹配,然后输出用户想得到的数据,满足规则的复杂事件。
CEP 复杂事件处理主要应用于防范网络欺诈、设备故障检测、风险规避和智能营销等领域。
Flink 基于 DataStrem API 提供了 FlinkCEP 组件栈,专门用于对复杂事件的处理,帮助用户从流式数据中发掘有价值的信息。
2. CEP 的特点
目标:从有序的简单事件流中发现一些高阶特征
输入:一个或多个简单事件构成的事件流
处理:识别简单事件之间的内在联系,多个符合一定规则的简单事件构成复杂事件
输出:满足规则的复杂事件
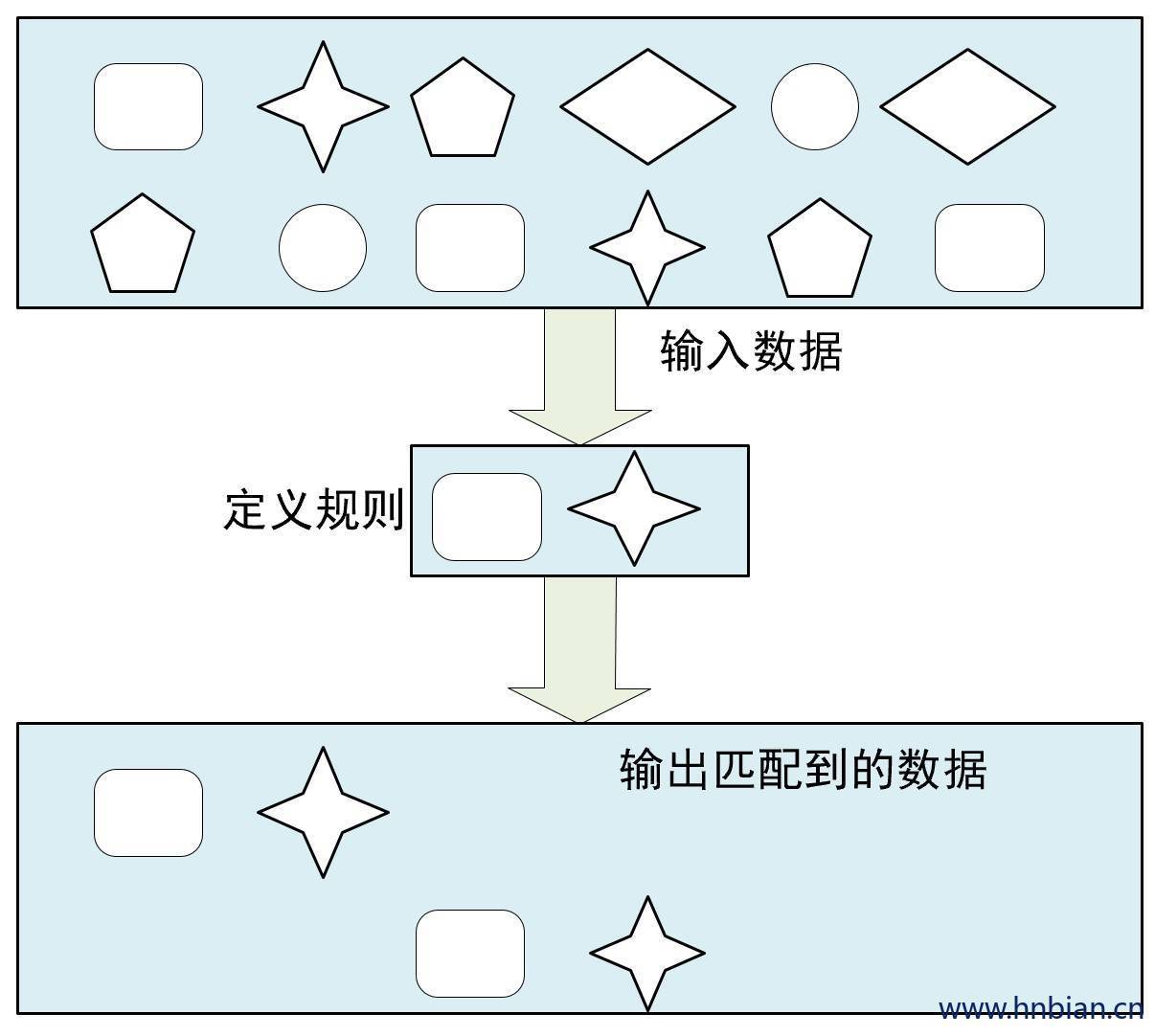
3. Pattern 介绍
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 import java.utilimport com.hnbian.flink.common.Record import org.apache.flink.cep.PatternSelectFunction import org.apache.flink.cep.scala.{CEP , PatternStream }import org.apache.flink.streaming.api.scala._import org.apache.flink.cep.scala.pattern.Pattern import org.apache.flink.streaming.api.windowing.time.Time object CEPTest extends App val env = StreamExecutionEnvironment .getExecutionEnvironment val stream1: DataStream [String ] = env.socketTextStream("localhost" ,9999 ) private val value: DataStream [Record ] = stream1 .map(data => { val arr = data.split("," ) Record (arr(0 ), arr(1 ), arr(2 ).toInt) }) private val pattern: Pattern [Record , Record ] = Pattern .begin[Record ]("start" ).where(_.age == 20 ) .next("next" ).where(_.age == 20 ) .within(Time .seconds(2 )) private val patternStream: PatternStream [Record ] = CEP .pattern[Record ](value, pattern) private val result: DataStream [String ] = patternStream.select(new PatternMacthData ) result.print("CEPTest" ) env.execute() } class PatternMacthData extends PatternSelectFunction [Record ,String ] override def select Map [String , util.List [Record ]]): String = { val start: Record = pattern.get("start" ).iterator().next() val next: Record = pattern.get("next" ).iterator().next() s"${start.name} 与 ${next.name} 都是 ${start.age} 岁" } }
4. Pattern 的定义与类型
定义 Pattern 可以是单次执行模式,也可以是循环执行模式。
单次执行模式一次只接受 一个事件
循环执行模式可以接收一个或者多个事件
可以通过指定循环次数将单次执行模式变为循环执行模式。
每种模式能够将多个条件组合应用到同一事件之上,条件组合可以通过 where 方法进行叠加。
每个 Pattern 都是通过 begin 方法为开始进行Pattern定义的,下一步通过 Pattern.where()方法在 Pattern 上指定匹配条件,只有当 匹配条件满足之后,当前的 Pattern 才会接受事件。
1 2 3 val pattern = Pattern .begin[Event ]("start" ) .where(_.id >= "100" )
4.1 定义 Pattern 的条件 每个模式都需要指定触发条件,作为事件进入到该模式是否接受的判断依据,当事件中的数值满足了条件时,便进行下一步操作。在 FlinkCFP 中通过 pattern.where()、 pattern.or() 及 pattern.until() 方法来为 Pattern 指定条件,且 Pattern 条件有 Simple Conditions 及Combining Conditions 等类型
使用 Pattern API 之前需要导入 CEP 依赖
1 2 3 4 5 <dependency > <groupId > org.apache.flink</groupId > <artifactId > flink-cep-scala_2.11</artifactId > <version > 1.10.0</version > </dependency >
4.1.1 简单条件
1 2 3 private val pattern: Pattern [Record , Record ] = Pattern .begin[Record ]("start" ).where(_.age == 20 )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 import java.utilimport com.hnbian.flink.common.Record import org.apache.flink.cep.PatternSelectFunction import org.apache.flink.cep.scala.{CEP , PatternStream }import org.apache.flink.cep.scala.pattern.Pattern import org.apache.flink.streaming.api.scala._object CepConditionSimpleTest extends App val env = StreamExecutionEnvironment .getExecutionEnvironment val socketStream: DataStream [String ] = env.socketTextStream("localhost" ,9999 ) private val recordStream: DataStream [Record ] = socketStream .map(data => { val arr = data.split("," ) Record (arr(0 ), arr(1 ), arr(2 ).toInt) }) private val pattern: Pattern [Record , Record ] = Pattern .begin[Record ]("start" ).where(_.age == 20 ) private val patternStream: PatternStream [Record ] = CEP .pattern[Record ](recordStream, pattern) private val result: DataStream [String ] = patternStream.select( new PatternSelectFunction [Record ,String ]{ override def select Map [String , util.List [Record ]]): String = { val start: Record = pattern.get("start" ).iterator().next() start.toString } } ) result.print("CepConditionSimpleTest" ) env.execute() }
4.1.2 组合条件
组合条件(Combining Conditions):是将简单条件进行合并
.where() 方法进行条件的组合,表示 AND
.or() 方法进行条件的组合,表示 OR
1 2 3 val start = Pattern .begin[Event ]("start" ) .where(_.id >= "100" ).or(_.age >30 )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 import java.utilimport com.hnbian.flink.common.Record import org.apache.flink.cep.PatternSelectFunction import org.apache.flink.cep.scala.{CEP , PatternStream }import org.apache.flink.cep.scala.pattern.Pattern import org.apache.flink.streaming.api.scala._object CepConditionCombiningTest extends App val env = StreamExecutionEnvironment .getExecutionEnvironment val socketStream: DataStream [String ] = env.socketTextStream("localhost" ,9999 ) private val recordStream: DataStream [Record ] = socketStream .map(data => { val arr = data.split("," ) Record (arr(0 ), arr(1 ), arr(2 ).toInt) }) recordStream.print() private val pattern1: Pattern [Record , Record ] = Pattern .begin[Record ]("start" ) .where(_.age == 20 ) private val pattern2: Pattern [Record , Record ] = Pattern .begin[Record ]("start" ) .where(_.age == 20 ) .or( _.age==18 ) private val pattern3: Pattern [Record , Record ] = Pattern .begin[Record ]("start" ) .where(_.age == 20 ) .or( _.age==18 ) .where(_.classId=="1" ) private val pattern4: Pattern [Record , Record ] = Pattern .begin[Record ]("start" ) .where(_.age == 20 ) .or( _.age==18 ) .where(_.classId=="1" ) .or(_.name == "小明" ) private val patternStream: PatternStream [Record ] = CEP .pattern[Record ](recordStream, pattern4) private val result: DataStream [String ] = patternStream.select( new PatternSelectFunction [Record ,String ]{ override def select Map [String , util.List [Record ]]): String = { val start: Record = pattern.get("start" ).iterator().next() start.toString } } ) result.print("CepConditionSimpleTest" ) env.execute() }
4.1.3 迭代条件
1 2 3 4 def where IterativeCondition [F ]): Pattern [T , F ] = { jPattern.where(condition) this }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 import java.utilimport com.hnbian.flink.common.Record import org.apache.flink.cep.PatternSelectFunction import org.apache.flink.cep.pattern.conditions.IterativeCondition import org.apache.flink.cep.scala.{CEP , PatternStream }import org.apache.flink.cep.scala.pattern.Pattern import org.apache.flink.streaming.api.scala._object CepConditionIterativeTest extends App val env = StreamExecutionEnvironment .getExecutionEnvironment val socketStream: DataStream [String ] = env.socketTextStream("localhost" ,9999 ) private val recordStream: DataStream [Record ] = socketStream .map(data => { val arr = data.split("," ) Record (arr(0 ), arr(1 ), arr(2 ).toInt) }) recordStream.print() private val pattern: Pattern [Record , Record ] = Pattern .begin[Record ]("start" ) .where(_.age == 20 ) .or( _.age==18 ) .where(new MyIterativeCondition ()) class MyIterativeCondition extends IterativeCondition [Record ] override def filter Record , ctx: IterativeCondition .Context [Record ]): Boolean = { if (value.name=="小明" ){ false }else if (value.classId == "1" ){ true }else { false } } } private val patternStream: PatternStream [Record ] = CEP .pattern[Record ](recordStream, pattern) private val result: DataStream [String ] = patternStream.select( new PatternSelectFunction [Record ,String ]{ override def select Map [String , util.List [Record ]]): String = { val start: Record = pattern.get("start" ).iterator().next() start.toString } } ) result.print("CepConditionIterativeTest" ) env.execute() }
4.1.4 终止条件
终止条件( Stop condition):如果程序中使用了 oneOrMore 或者 oneOrMore().optional() 方法,还可以指定停止条件,否则模式中的规则会一直循环下去,如下终止条件通过 until()方法指定
终止条件测试代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 import java.utilimport com.hnbian.flink.common.Record import org.apache.flink.cep.PatternSelectFunction import org.apache.flink.cep.scala.{CEP , PatternStream }import org.apache.flink.cep.scala.pattern.Pattern import org.apache.flink.streaming.api.scala._object CepConditionStopTest extends App val env = StreamExecutionEnvironment .getExecutionEnvironment val socketStream: DataStream [String ] = env.socketTextStream("localhost" ,9999 ) private val recordStream: DataStream [Record ] = socketStream .map(data => { val arr = data.split("," ) Record (arr(0 ), arr(1 ), arr(2 ).toInt) }) private val pattern: Pattern [Record , Record ] = Pattern .begin[Record ]("start" ) .where(_.age == 20 ) .oneOrMore .until(_.classId=="2" ) private val patternStream: PatternStream [Record ] = CEP .pattern[Record ](recordStream, pattern) private val result: DataStream [String ] = patternStream.select( new PatternSelectFunction [Record ,String ]{ override def select Map [String , util.List [Record ]]): String = { val start: Record = pattern.get("start" ).iterator().next() start.toString } } ) result.print("CepConditionStopTest" ) env.execute() }
4.2 设置时间约束 可以为模式指定时间约束,用来要求在多长时间内匹配有效
1 2 3 4 5 private val pattern: Pattern [Record , Record ] = Pattern .begin[Record ]("start" ).where(_.age == 20 ) .next("next" ).where(_.age == 20 ) .within(Time .seconds(5 ))
4.3 设置循环 Pattern 对于已经创建好的 Pattern,可以在一个简单条件后追加量词,也就是指定循环次数,形成循环执行的 Pattern
4.3.1 times
可以通过 times 指定固定的循环执行次数
不会匹配出累积到触发次数最后一条数据,可以想象为数组下标最大值为 数组长度-1
1 2 3 4 5 start.times(3 ) start.times(2 , 4 )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 import java.utilimport com.hnbian.flink.common.Record import org.apache.flink.cep.PatternSelectFunction import org.apache.flink.cep.scala.{CEP , PatternStream }import org.apache.flink.cep.scala.pattern.Pattern import org.apache.flink.streaming.api.scala._object CepQuantifierTimesTest extends App val env = StreamExecutionEnvironment .getExecutionEnvironment val socketStream: DataStream [String ] = env.socketTextStream("localhost" , 9999 ) private val recordStream: DataStream [Record ] = socketStream .map(data => { val arr = data.split("," ) Record (arr(0 ), arr(1 ), arr(2 ).toInt) }) private val pattern: Pattern [Record , Record ] = Pattern .begin[Record ]("start" ) .where(_.age == 20 ).times(2 , 4 ) .next("next" ).where(_.classId == "2" ) private val patternStream: PatternStream [Record ] = CEP .pattern[Record ](recordStream, pattern) private val result: DataStream [String ] = patternStream.select( new PatternSelectFunction [Record , String ] { override def select Map [String , util.List [Record ]]): String = { val start: Record = pattern.get("start" ).iterator().next() val next: Record = pattern.get("next" ).iterator().next() s"${start.toString} ,${next.toString} " } } ) result.print("CepQuantifierTimesTest" ) env.execute() }
4.3.2 optional
可以通过 optional 关键字指定触发条件有两个
当到达触发条件时出现的次数为 0 会触发
当到达触发条件是出现次数达到指定次数触发
注意,当出现次数为 0 触发时,获取对应事件时可能为 null
1 2 3 4 5 6 start.times(4 ).optional start.times(2 , 4 ).optional
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 import java.utilimport com.hnbian.flink.common.Record import org.apache.flink.cep.PatternSelectFunction import org.apache.flink.cep.scala.{CEP , PatternStream }import org.apache.flink.cep.scala.pattern.Pattern import org.apache.flink.streaming.api.scala._object CepQuantifierOptionalTest extends App val env = StreamExecutionEnvironment .getExecutionEnvironment val socketStream: DataStream [String ] = env.socketTextStream("localhost" , 9999 ) private val recordStream: DataStream [Record ] = socketStream .map(data => { val arr = data.split("," ) Record (arr(0 ), arr(1 ), arr(2 ).toInt) }) private val pattern: Pattern [Record , Record ] = Pattern .begin[Record ]("start" ) .where(_.age == 20 ).times(2 ).optional .next("next" ).where(_.classId == "2" ) private val patternStream: PatternStream [Record ] = CEP .pattern[Record ](recordStream, pattern) private val result: DataStream [String ] = patternStream.select( new PatternSelectFunction [Record , String ] { override def select Map [String , util.List [Record ]]): String = { val result:StringBuffer = new StringBuffer () var start: Record = null if (null != pattern.get("start" )){ start = pattern.get("start" ).iterator().next() result .append("start:" ) .append(start.toString) .append("," ) } val next: Record = pattern.get("next" ).iterator().next() result.append("end:" ).append(next.toString) result.toString } } ) result.print("CepQuantifierOptionalTest" ) env.execute() }
4.3.3 greedy
可以通过 greedy 将 Pattern 标记为贪婪模式
在 Pattern 匹配成功的前提下,会尽可能多次触发
下一次触发可能会重复匹配前一次触发时匹配到的数据
1 2 3 4 5 start.times(2 , 4 ).greedy start.times(2 , 4 ).optional.greedy
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 import java.utilimport com.hnbian.flink.common.Record import org.apache.flink.cep.PatternSelectFunction import org.apache.flink.cep.scala.{CEP , PatternStream }import org.apache.flink.cep.scala.pattern.Pattern import org.apache.flink.streaming.api.scala._object CepQuantifierGreedyTest extends App val env = StreamExecutionEnvironment .getExecutionEnvironment val socketStream: DataStream [String ] = env.socketTextStream("localhost" , 9999 ) private val recordStream: DataStream [Record ] = socketStream .map(data => { val arr = data.split("," ) Record (arr(0 ), arr(1 ), arr(2 ).toInt) }) private val pattern: Pattern [Record , Record ] = Pattern .begin[Record ]("start" ) .where(_.age == 20 ).times(2 ,7 ).greedy .next("next" ).where(_.classId == "2" ) private val patternStream: PatternStream [Record ] = CEP .pattern[Record ](recordStream, pattern) private val result: DataStream [String ] = patternStream.select( new PatternSelectFunction [Record , String ] { override def select Map [String , util.List [Record ]]): String = { val result:StringBuffer = new StringBuffer () var start: Record = null if (null != pattern.get("start" )){ start = pattern.get("start" ).iterator().next() result .append("start:" ) .append(start.toString) .append("," ) } val next: Record = pattern.get("next" ).iterator().next() result.append("end:" ).append(next.toString) result.toString } } ) result.print("CepQuantifierGreedyTest" ) env.execute() }
4.3.4 oneOrMore
可以通过 oneOrMore 方法指定触发一次或多次
匹配触发条件前的一次到多次
已经前一次匹配的数据在后一次触发还会被匹配到
与 times 不同的是会匹配到触发事件及其之前的所有数据
1 2 3 4 5 6 7 8 9 10 11 start.oneOrMore() start.oneOrMore().greedy() start.oneOrMore().optional() start.oneOrMore().optional().greedy()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 import java.utilimport com.hnbian.flink.common.Record import org.apache.flink.cep.PatternSelectFunction import org.apache.flink.cep.scala.{CEP , PatternStream }import org.apache.flink.cep.scala.pattern.Pattern import org.apache.flink.streaming.api.scala._object CepQuantifierOneOrMoreTest extends App val env = StreamExecutionEnvironment .getExecutionEnvironment val socketStream: DataStream [String ] = env.socketTextStream("localhost" , 9999 ) private val recordStream: DataStream [Record ] = socketStream .map(data => { val arr = data.split("," ) Record (arr(0 ), arr(1 ), arr(2 ).toInt) }) private val pattern: Pattern [Record , Record ] = Pattern .begin[Record ]("start" ) .where(_.age == 20 ).oneOrMore .next("next" ).where(_.classId == "2" ) private val patternStream: PatternStream [Record ] = CEP .pattern[Record ](recordStream, pattern) private val result: DataStream [String ] = patternStream.select( new PatternSelectFunction [Record , String ] { override def select Map [String , util.List [Record ]]): String = { val start: Record = pattern.get("start" ).iterator().next() val next: Record = pattern.get("next" ).iterator().next() s"${start.toString} ,${next.toString} " } } ) result.print("CepQuantifierOneOrMoreTest" ) env.execute() }
4.3.5 timesOrMor 通过 timesOrMore 方法可以指定触发固定次数以上,例如执行两次以上
1 2 3 4 5 6 7 8 start.timesOrMore(2 ); start.timesOrMore(2 ).greedy() start.timesOrMore(2 ).optional().greedy()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 package com.hnbian.flink.cepimport java.utilimport com.hnbian.flink.common.Record import org.apache.flink.cep.PatternSelectFunction import org.apache.flink.cep.scala.{CEP , PatternStream }import org.apache.flink.cep.scala.pattern.Pattern import org.apache.flink.streaming.api.scala._object CepQuantifierTimesOrMorTest extends App val env = StreamExecutionEnvironment .getExecutionEnvironment val socketStream: DataStream [String ] = env.socketTextStream("localhost" , 9999 ) private val recordStream: DataStream [Record ] = socketStream .map(data => { val arr = data.split("," ) Record (arr(0 ), arr(1 ), arr(2 ).toInt) }) private val pattern: Pattern [Record , Record ] = Pattern .begin[Record ]("start" ) .where(_.age == 20 ).timesOrMore(2 ) .next("next" ).where(_.classId == "2" ) private val patternStream: PatternStream [Record ] = CEP .pattern[Record ](recordStream, pattern) private val result: DataStream [String ] = patternStream.select( new PatternSelectFunction [Record , String ] { override def select Map [String , util.List [Record ]]): String = { val start: Record = pattern.get("start" ).iterator().next() val next: Record = pattern.get("next" ).iterator().next() s"${start.toString} ,${next.toString} " } } ) result.print("CepQuantifierTimesOrMorTest" ) env.execute() }
4.3.6 设置条件注意项
模式序列不能以 .notFollowedBy() 结束
“ not ” 类型的模式不能被 optional 所修饰
4.4 组合模式
将相互独立的模式进行组合然后形成模式序列。
模式序列基本的编写方式和独立模式一 致,各个模式之间通过邻近条件进行连接即可,
其中有严格邻近、宽松邻近、非确定宽松邻近三种邻近连接条件。
模式序列必须是以一个“begin”开始:val start = Pattern.begin(“start”)
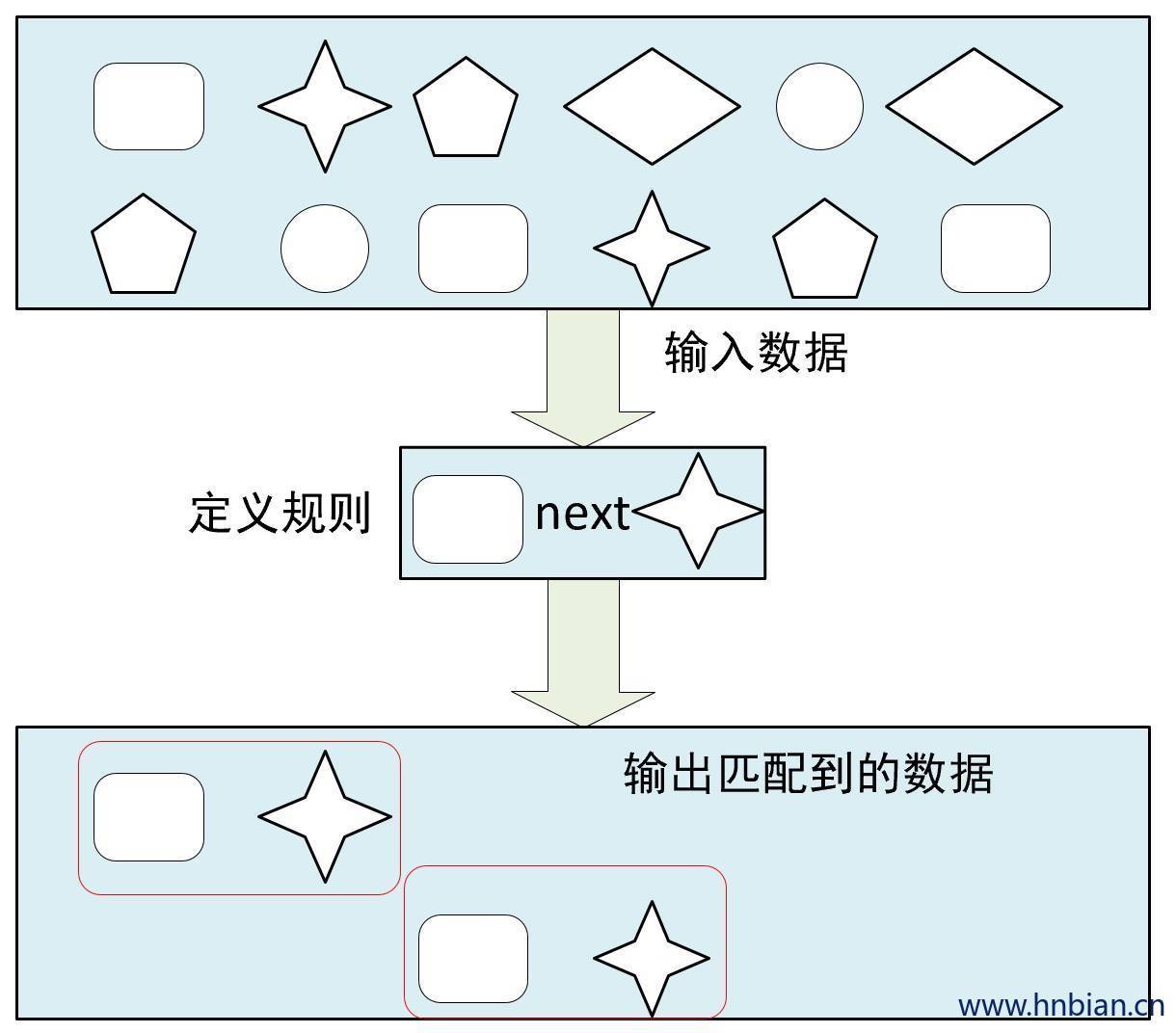
4.4.1 严格近邻
严格近邻:Strict Contiguity
所有事件按照严格的顺序出现,中间没有任何不匹配的事件,由.next()指定
例如对于模式 “a next b “ 事件序列 【a,c,b,d】则没有匹配
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 import java.utilimport com.hnbian.flink.common.Record import org.apache.flink.cep.PatternSelectFunction import org.apache.flink.cep.scala.{CEP , PatternStream }import org.apache.flink.cep.scala.pattern.Pattern import org.apache.flink.streaming.api.scala._object CepContiguityStrictTest extends App val env = StreamExecutionEnvironment .getExecutionEnvironment val socketStream: DataStream [String ] = env.socketTextStream("localhost" , 9999 ) private val recordStream: DataStream [Record ] = socketStream .map(data => { val arr = data.split("," ) Record (arr(0 ), arr(1 ), arr(2 ).toInt) }) private val pattern: Pattern [Record , Record ] = Pattern .begin[Record ]("start" ).where(_.age == 20 ) .next("next" ).where(_.classId == "2" ) private val patternStream: PatternStream [Record ] = CEP .pattern[Record ](recordStream, pattern) private val result: DataStream [String ] = patternStream.select( new PatternSelectFunction [Record , String ] { override def select Map [String , util.List [Record ]]): String = { val start: Record = pattern.get("start" ).iterator().next() val next: Record = pattern.get("next" ).iterator().next() s"${start.toString} ,${next.toString} " } } ) result.print("CepContiguityStrictTest" ) env.execute() }
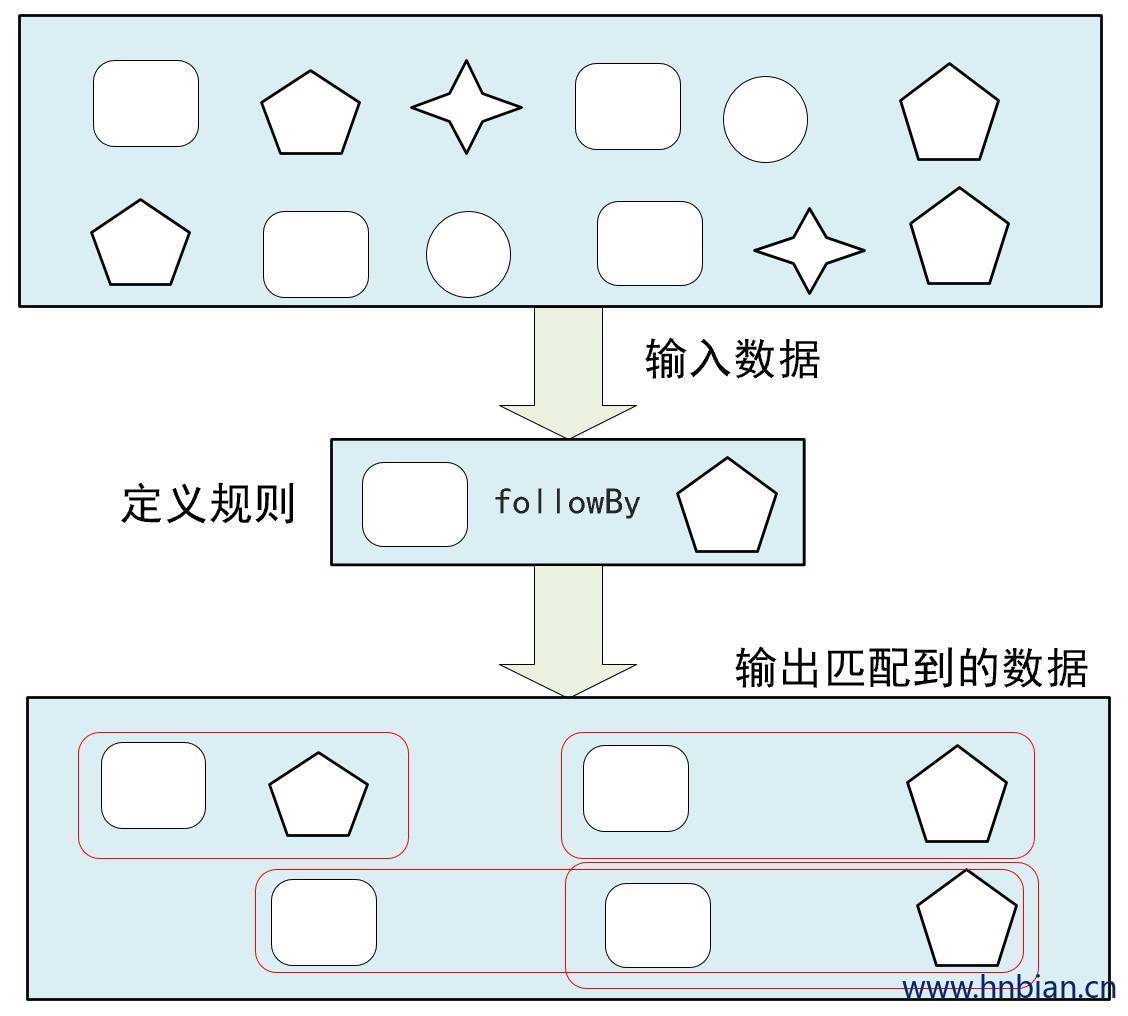
4.4.2 宽松近邻
宽松近邻(Relaxed Contiguity)
允许中间出现不匹配的时间,由.followBy()指定
例如对于模式 “a followedBy b “ 事件序列 【a,c,b,d】匹配为{a,b}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 import java.utilimport com.hnbian.flink.common.Record import org.apache.flink.cep.PatternSelectFunction import org.apache.flink.cep.scala.{CEP , PatternStream }import org.apache.flink.cep.scala.pattern.Pattern import org.apache.flink.streaming.api.scala._object CepContiguityRelaxedTest extends App val env = StreamExecutionEnvironment .getExecutionEnvironment val socketStream: DataStream [String ] = env.socketTextStream("localhost" , 9999 ) private val recordStream: DataStream [Record ] = socketStream .map(data => { val arr = data.split("," ) Record (arr(0 ), arr(1 ), arr(2 ).toInt) }) private val pattern: Pattern [Record , Record ] = Pattern .begin[Record ]("start" ).where(_.age == 20 ) .followedBy("followed" ).where(_.classId == "2" ) private val patternStream: PatternStream [Record ] = CEP .pattern[Record ](recordStream, pattern) private val result: DataStream [String ] = patternStream.select( new PatternSelectFunction [Record , String ] { override def select Map [String , util.List [Record ]]): String = { val result:StringBuffer = new StringBuffer () var start: Record = null var followed: Record = null if (null != pattern.get("start" )){ start = pattern.get("start" ).iterator().next() result .append("start:" ) .append(start.toString) .append("," ) } if (null != pattern.get("followed" )){ followed = pattern.get("followed" ).iterator().next() result .append("followed:" ) .append(followed.toString) .append("," ) } result.toString } } ) result.print("CepContiguityRelaxedTest" ) env.execute() }
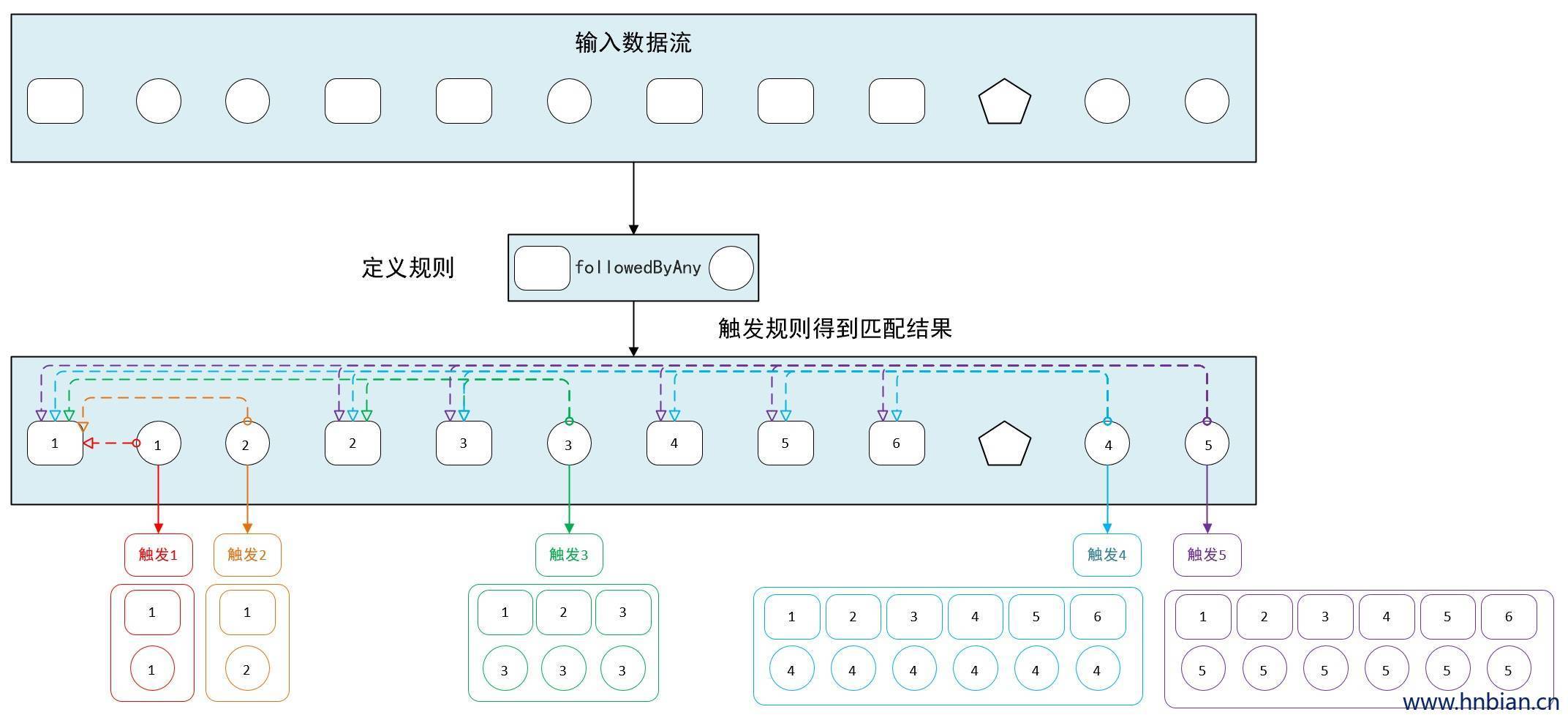
4.4.3 非确定性宽松近邻
非确定性宽松近邻:Non-Deterministic Relaxed Contiguity
进一步放宽条件,之前已经匹配过得事件也可以再次使用,由.followedByAny()指定
例如对于模式 “a followedByAny b “ 事件序列 【a,c,b1,b2】匹配为{a,b1},{a,b2}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 import java.utilimport com.hnbian.flink.common.Record import org.apache.flink.cep.PatternSelectFunction import org.apache.flink.cep.scala.{CEP , PatternStream }import org.apache.flink.cep.scala.pattern.Pattern import org.apache.flink.streaming.api.scala._object CepContiguityRelaxedNonDeterministicTest extends App val env = StreamExecutionEnvironment .getExecutionEnvironment val socketStream: DataStream [String ] = env.socketTextStream("localhost" , 9999 ) private val recordStream: DataStream [Record ] = socketStream .map(data => { val arr = data.split("," ) Record (arr(0 ), arr(1 ), arr(2 ).toInt) }) private val pattern: Pattern [Record , Record ] = Pattern .begin[Record ]("start" ) .where(_.age == 20 ) .followedByAny("followedByAny" ).where(_.classId == "2" ) private val patternStream: PatternStream [Record ] = CEP .pattern[Record ](recordStream, pattern) private val result: DataStream [String ] = patternStream.select( new PatternSelectFunction [Record , String ] { override def select Map [String , util.List [Record ]]): String = { val result:StringBuffer = new StringBuffer () var start: Record = null var followed: Record = null if (null != pattern.get("start" )){ start = pattern.get("start" ).iterator().next() result .append("start:" ) .append(start.toString) .append("," ) } if (null != pattern.get("followedByAny" )){ followed = pattern.get("followedByAny" ).iterator().next() result .append("followed:" ) .append(followed.toString) .append("," ) } result.toString } } ) result.print("CepContiguityRelaxedNonDeterministicTest" ) env.execute() }
4.4.4 严禁近邻
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 import java.utilimport com.hnbian.flink.common.Record import org.apache.flink.cep.PatternSelectFunction import org.apache.flink.cep.scala.{CEP , PatternStream }import org.apache.flink.cep.scala.pattern.Pattern import org.apache.flink.streaming.api.scala._object CepContiguityStrictNeverTest extends App val env = StreamExecutionEnvironment .getExecutionEnvironment val socketStream: DataStream [String ] = env.socketTextStream("localhost" , 9999 ) private val recordStream: DataStream [Record ] = socketStream .map(data => { val arr = data.split("," ) Record (arr(0 ), arr(1 ), arr(2 ).toInt) }) private val pattern: Pattern [Record , Record ] = Pattern .begin[Record ]("start" ).where(_.age == 20 ) .notNext("next" ).where(_.classId =="3" ) private val patternStream: PatternStream [Record ] = CEP .pattern[Record ](recordStream, pattern) private val result: DataStream [String ] = patternStream.select( new PatternSelectFunction [Record , String ] { override def select Map [String , util.List [Record ]]): String = { val result:StringBuffer = new StringBuffer () var start: Record = null var next: Record = null if (null != pattern.get("start" )){ start = pattern.get("start" ).iterator().next() result .append("start:" ) .append(start.toString) .append("," ) } println(pattern.get("next" )) if (null != pattern.get("next" )){ next = pattern.get("next" ).iterator().next() result .append("next:" ) .append(next.toString) .append("," ) } result.toString } } ) result.print("CepContiguityStrictNeverTest" ) env.execute() }
4.4.5 非中间时间 .notFollowedBy :不想让某个事件在两个事件之间发生
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 import java.utilimport com.hnbian.flink.common.Record import org.apache.flink.cep.PatternSelectFunction import org.apache.flink.cep.scala.{CEP , PatternStream }import org.apache.flink.cep.scala.pattern.Pattern import org.apache.flink.streaming.api.scala._object CepContiguityNotFollowedByTest extends App val env = StreamExecutionEnvironment .getExecutionEnvironment val socketStream: DataStream [String ] = env.socketTextStream("localhost" , 9999 ) private val recordStream: DataStream [Record ] = socketStream .map(data => { val arr = data.split("," ) Record (arr(0 ), arr(1 ), arr(2 ).toInt) }) private val pattern: Pattern [Record , Record ] = Pattern .begin[Record ]("start" ).where(_.age == 20 ) .notFollowedBy("notFollowedBy" ).where(_.classId == "3" ) .next("next" ).where(_.classId == "2" ) private val patternStream: PatternStream [Record ] = CEP .pattern[Record ](recordStream, pattern) private val result: DataStream [String ] = patternStream.select( new PatternSelectFunction [Record , String ] { override def select Map [String , util.List [Record ]]): String = { val result:StringBuffer = new StringBuffer () var start: Record = null var notFollowedBy: Record = null var next: Record = null if (null != pattern.get("start" )){ start = pattern.get("start" ).iterator().next() result .append("start:" ) .append(start.toString) .append("," ) } println("notFollowedBy==" +pattern.get("notFollowedBy" )) if (null != pattern.get("notFollowedBy" )){ notFollowedBy = pattern.get("notFollowedBy" ).iterator().next() result .append("notFollowedBy:" ) .append(notFollowedBy.toString) .append("," ) } if (null != pattern.get("next" )){ next = pattern.get("next" ).iterator().next() result .append("next:" ) .append(next.toString) .append("," ) } result.toString } } ) result.print("CepContiguityNotFollowedByTest" ) env.execute() }
5. Pattern 在事件流上检测
指定要查找的模式序列后,就可以将其应用于输入流以检测潜在匹配
调用 CEP.pattern(),给定输入流和模式,就能得到一个 PatternStream
1 2 3 4 5 6 7 8 9 private val pattern: Pattern [Record , Record ] = Pattern .begin[Record ]("start" ).where(_.age == 20 ) .within(Time .seconds(2 )) import org.apache.flink.cep.scala.CEP private val patternStream: PatternStream [Record ] = CEP .pattern[Record ](value, pattern)
6. 选取结果
创建 PatternStream 之后,就可以应用 select 或者 flatselect方法,从检测到的事件序列中提取事件
select() 方法需要输入一个 select function 作为参数,每个成功匹配的事件序列都会调用它
select() 以一个 Map[String,Iterable[N]] 来接收匹配到的事件序列,其中 key 就是每个模式的名称,而 value 就是所接收到的事件的 Iterable 类型
6.1 Select Funciton
可以通过在 PatternStream 的 Select 方法中传入自定义 Select Funciton 完成对匹配 事件的转换与输出。
Select Funciton 的输入参数为 Map[String, Iterable[IN]],Map 中的 key 为模式序列中的 Pattern 名称,Value 为对应 Pattern 所接受的事件集合,格式为输入事件的数据类型。
6.1.1 Select Funciton抽取正常事件 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 import java.utilimport com.hnbian.flink.common.Record import org.apache.flink.cep.PatternSelectFunction import org.apache.flink.cep.scala.{CEP , PatternStream }import org.apache.flink.cep.scala.pattern.Pattern import org.apache.flink.streaming.api.scala._object CepSelectFuncitonTest extends App val env = StreamExecutionEnvironment .getExecutionEnvironment val socketStream: DataStream [String ] = env.socketTextStream("localhost" ,9999 ) private val recordStream: DataStream [Record ] = socketStream .map(data => { val arr = data.split("," ) Record (arr(0 ), arr(1 ), arr(2 ).toInt) }) private val pattern: Pattern [Record , Record ] = Pattern .begin[Record ]("start" ).where(_.age == 20 ) private val patternStream: PatternStream [Record ] = CEP .pattern[Record ](recordStream, pattern) private val result: DataStream [String ] = patternStream.select(new selectFunction) result.print("CepSelectFuncitonTest" ) env.execute() } class selectFunction extends PatternSelectFunction [Record ,String ] override def select Map [String , util.List [Record ]]): String = { val start: Record = pattern.get("start" ).iterator().next() start.toString } }
6.1.2 Select Funciton抽取超时事件 如果模式中有 within(time),那么就很有可能有超时的数据存在,通过 PatternStream,Select 方法分别获取超时事件和正常事件。首先需要创建 OutputTag 来标记超时事件,然后在 PatternStream.select 方法中使用 OutputTag,就可以将超时事件从 PatternStream中抽取出来。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 import java.utilimport com.hnbian.flink.common.Record import org.apache.flink.cep.{PatternSelectFunction , PatternTimeoutFunction }import org.apache.flink.cep.scala.{CEP , PatternStream }import org.apache.flink.cep.scala.pattern.Pattern import org.apache.flink.streaming.api.scala._import org.apache.flink.streaming.api.windowing.time.Time object CepSelectFunctionOutTimeTest extends App val env = StreamExecutionEnvironment .getExecutionEnvironment env.setParallelism(1 ) val socketStream: DataStream [String ] = env.socketTextStream("localhost" , 9999 ) private val recordStream: DataStream [Record ] = socketStream .map(data => { val arr = data.split("," ) Record (arr(0 ), arr(1 ), arr(2 ).toInt) }) private val pattern: Pattern [Record , Record ] = Pattern .begin[Record ]("start" ).where(_.age == 20 ) .next("next" ).where(_.classId == "2" ) .within(Time .seconds(2 )) private val patternStream: PatternStream [Record ] = CEP .pattern[Record ](recordStream, pattern) val timeoutTag = OutputTag [String ]("timeout-output" ) private val result: DataStream [String ] = patternStream.select(timeoutTag, new OutTimeSelectFunction2 , new SelectFunction2 ) result.print("CepSelectFunctionOutTimeTest" ) result.getSideOutput(timeoutTag).print("timeout-output" ) env.execute() } class SelectFunction2 (extends PatternSelectFunction [Record ,String ] override def select Map [String , util.List [Record ]]): String = { val start: Record = pattern.get("start" ).iterator().next() s"${start.toString} ,success" } } class OutTimeSelectFunction2 (extends PatternTimeoutFunction [Record ,String ] override def timeout Map [String , util.List [Record ]], timeoutTimestamp: Long ): String = { val start: Record = pattern.get("start" ).iterator().next() s"${start.toString} ,outTime" } }
6.2 Flat Select Funciton
6.2.1 Flat Select Funciton 抽取正常事件 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 import java.utilimport com.hnbian.flink.common.Record import org.apache.flink.cep.PatternFlatSelectFunction import org.apache.flink.cep.scala.{CEP , PatternStream }import org.apache.flink.cep.scala.pattern.Pattern import org.apache.flink.streaming.api.scala._import org.apache.flink.util.Collector object CepSelectFuncitonFlatTest extends App val env = StreamExecutionEnvironment .getExecutionEnvironment env.setParallelism(1 ) val socketStream: DataStream [String ] = env.socketTextStream("localhost" ,9999 ) private val recordStream: DataStream [Record ] = socketStream .map(data => { val arr = data.split("," ) Record (arr(0 ), arr(1 ), arr(2 ).toInt) }) private val pattern: Pattern [Record , Record ] = Pattern .begin[Record ]("start" ).where(_.age == 20 ) .next("next" ).where(_.classId == "2" ) private val patternStream: PatternStream [Record ] = CEP .pattern[Record ](recordStream, pattern) private val result: DataStream [String ] = patternStream.flatSelect(new flatSelectFunction) result.print("CepSelectFuncitonFlatTest" ) env.execute() } class flatSelectFunction extends PatternFlatSelectFunction [Record ,String ] override def flatSelect Map [String , util.List [Record ]], out: Collector [String ]): Unit = { out.collect( s"" " |flatSelectFunction: | ${pattern.get(" start").toString}, | ${pattern.get("next").toString} |" "" .stripMargin) } }
6.2.1 Flat Select Funciton 抽取超时事件 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 import java.utilimport com.hnbian.flink.common.Record import org.apache.flink.cep.{PatternFlatSelectFunction , PatternFlatTimeoutFunction }import org.apache.flink.cep.scala.{CEP , PatternStream }import org.apache.flink.cep.scala.pattern.Pattern import org.apache.flink.streaming.api.scala._import org.apache.flink.streaming.api.windowing.time.Time import org.apache.flink.util.Collector object CepSelectFunctionFlatOutTimeTest extends App val env = StreamExecutionEnvironment .getExecutionEnvironment env.setParallelism(1 ) val socketStream: DataStream [String ] = env.socketTextStream("localhost" ,9999 ) private val recordStream: DataStream [Record ] = socketStream .map(data => { val arr = data.split("," ) Record (arr(0 ), arr(1 ), arr(2 ).toInt) }) private val pattern: Pattern [Record , Record ] = Pattern .begin[Record ]("start" ).where(_.age == 20 ) .next("next" ).where(_.classId == "2" ) .within(Time .seconds(2 )) private val patternStream: PatternStream [Record ] = CEP .pattern[Record ](recordStream, pattern) val timeoutTag = OutputTag [String ]("timeout-output" ) private val result: DataStream [String ] = patternStream.flatSelect(timeoutTag,new FlatSelectTimeoutFunction ,new FlatSelectFunction ) result.print("CepSelectFunctionFlatOutTimeTest" ) result.getSideOutput(timeoutTag).print("time out" ) env.execute() } class FlatSelectFunction extends PatternFlatSelectFunction [Record ,String ] override def flatSelect Map [String , util.List [Record ]], out: Collector [String ]): Unit = { out.collect( s"" " |flatSelectFunction: | ${pattern.get(" start").toString}, | ${pattern.get("next").toString} |" "" .stripMargin) } } class FlatSelectTimeoutFunction extends PatternFlatTimeoutFunction [Record ,String ] override def timeout Map [String , util.List [Record ]], timeoutTimestamp: Long , out: Collector [String ]): Unit = { out.collect( s"" " |flatSelectFunction: | ${pattern.get(" start").toString} |" "" .stripMargin) } }