本文针对flink1.3做的记录。
1. Flink简介
Flink官网:https://flink.apache.org/
Flink中文文档地址(目前翻译了大部分):http://flink-cn.shinonomelab.com/
首先我们先了解两种数据集的大致类型
Flink是针对无界数据集的持续计算。数据源源不断的进入Flink程序,然后Flink程序根据预定义的代码逻辑实现相关功能。
2. Flink的两种运行模型
如果我们使用过SparkStreaming和Storm就会知道,SparkStreaming是属于微批次的方式进行数据的实时处理。Storm属于对数据的的实时处理。
而Flink同时满足了上面两种计算的方式:
流式计算:只要数据产生就一直处于计算状态。
批次处理:完成一个时间段的任务计算后,释放资源,等待下一个批次的计算。
3. Flink的特性
- 应用于流处理的开源框架。
- Flink支持流式计算以及灵活的基于时间的窗口化操作。
- 结果精准:即使是无序数据或延迟到达的数据也会保证精准。
- 有状态:保持每次计算的结果,实现累加。
- 容错:轻量级的,资源占用少,能够保证数据零丢失。出错以后能够恢复或重新计算,维护exactly once的应用状态(对数据算且只算一次)。
- 大规模:可以在几千台节点上运行,高吞吐量,低延迟。
- 检查点:Flink通过检查点机制实现exactly once,在出现故障时可以体现出来。版本化机制。
4. Flink流计算模型以及有界数据集
有界数据集是无界数据集的一种特例。
有界数据集在Flink内部是一种最终状态数据集进行处理的。
在Flink内部有界于无界数据集的差别很小,可能使用同一套计算执行引擎的API操作同时处理有界与无界数据集。
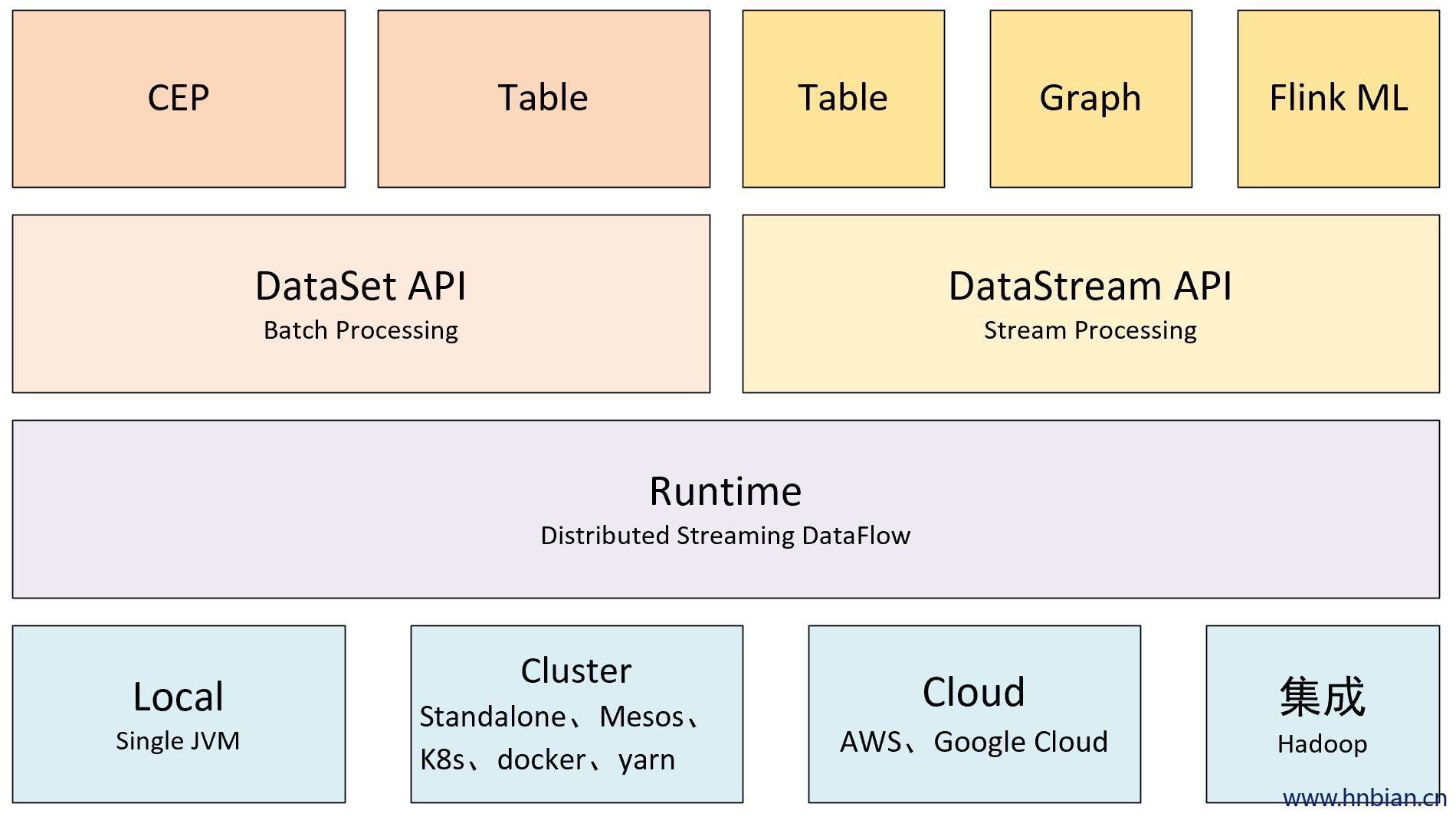
5.Flink 核心模块
6. 搭建单机版
下载地址: https://flink.apache.org/downloads.html
将flink 上传并解压即可
启动本地flink
./start-local.sh
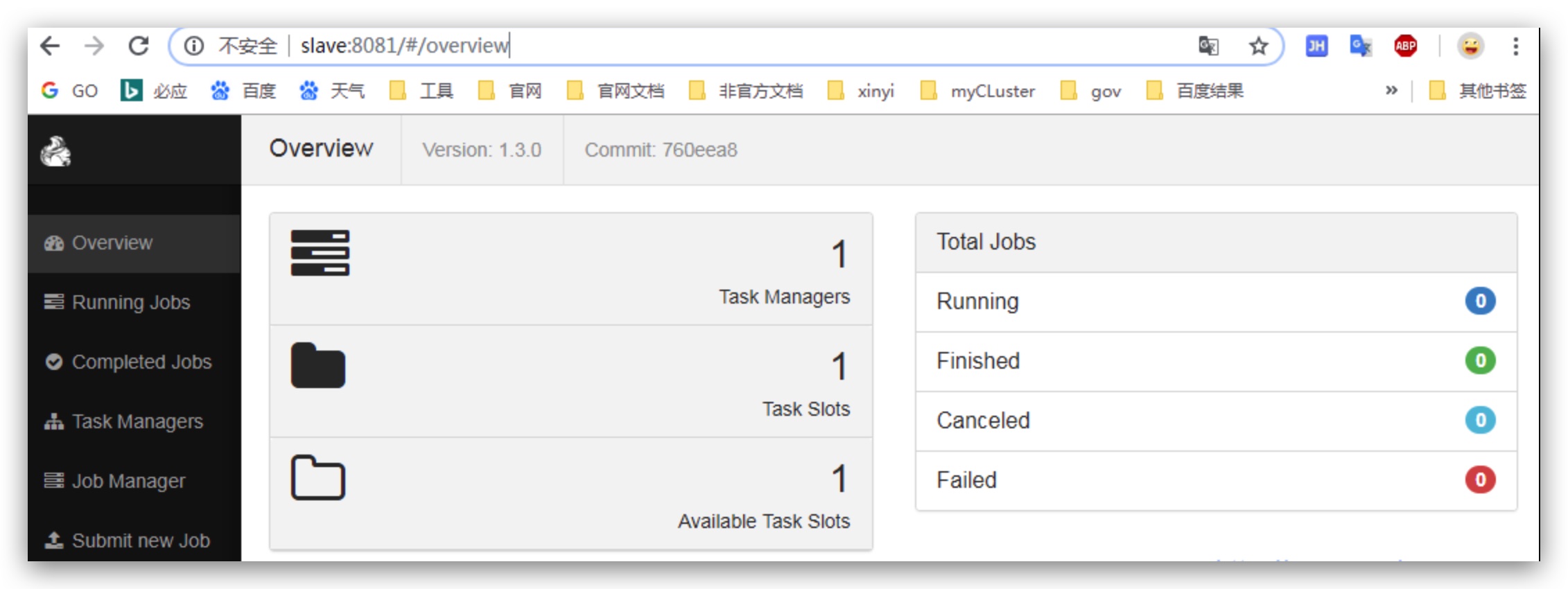
7. WebUI界面
http://slave:8081/#/overview
8. WordCount代码实例
引入依赖
1
2
3
4
5
6
|
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>1.3.0</version>
</dependency>
|
代码示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
| package com.hnbian;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
public class SocketWindowWordCountJava {
public static void main(String[] args) throws Exception {
final int port = 8965 ;
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<String> text = env.socketTextStream("slave", port, "\n");
DataStream<WordWithCount> windowCounts = text
.flatMap(new FlatMapFunction<String, WordWithCount>() {
public void flatMap(String value, Collector<WordWithCount> out) {
for (String word : value.split("\\s")) {
out.collect(new WordWithCount(word, 1L));
}
}
})
.keyBy("word")
.timeWindow(Time.seconds(5), Time.seconds(1))
.reduce(new ReduceFunction<WordWithCount>() {
public WordWithCount reduce(WordWithCount a, WordWithCount b) {
return new WordWithCount(a.word, a.count + b.count);
}
});
windowCounts.print().setParallelism(1);
env.execute("Socket Window WordCount");
}
public static class WordWithCount {
public String word;
public long count;
public WordWithCount() {
}
public WordWithCount(String word, long count) {
this.word = word;
this.count = count;
}
public String toString() {
return word + " : " + count;
}
}
}
|
安装netcat工具,并且启动nc服务
windows环境
启动nc命令:Cmd> nc -lL -p 9999
运行代码并查看结果。
Linux环境
启动nc命令:nc -lk -p 9999
将代码打包上传到Linux服务器,并且启动:Bin/flink run -c com.hnbian.className myflink.jar
代码启动之后可以通过nc服务发送数据看刚写的代码能否统计到数据。
我们可以在WebUI 中找标准作业管理器点击标准输出 即可看到输出日志。如下图: