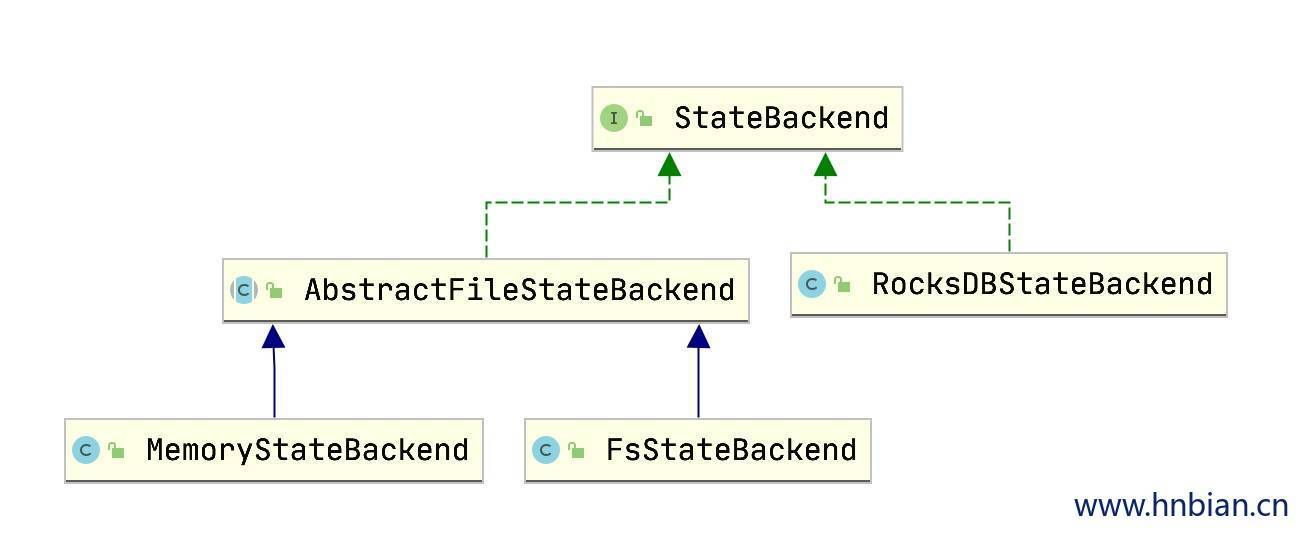
1. 状态后端介绍
Flink 实时计算数据场景下,有时需要启动 checkpoint 保存数据的状态,那么状态会随着 checkpoint 被持久化某个地方,以防止数据丢失,保证状态数据能够在需要恢复程序状态时保持数据的一致性。而进行 checkpoint 时保存状态数据的位置就是 **状态后端 **( State Backend) 。
状态后端中每传入一条数据,有状态的算子任务就会读取和更新状态。由于有效的状态访问对于处理数据的低延迟至关重要,因此每个并行任务都会在本地维护其状态,以确保能够快速的访问状态。
状态后端定义如何存储和检查点流式应用程序的状态。 不同的状态后端以不同的方式存储其状态,并使用不同的数据结构来保存正在运行的应用程序的状态。
状态后端实现必须是线程安全的。 多个线程可能正在同时创建流和键控/运算符状态后端
状态后端需要可serializable ,因为它们与流应用程序代码一起分布在并行进程中,StateBackend的实现提供访问持久存储并保持keyed-和操作状态数据结构的工厂。 这样,状态后端可以非常轻量级(仅包含配置),这使其更易于序列化。
状态后端主要负责两件事:
管理本地状态
将检查点状态写入远端存储
flink 中提供了三种状态后端:
MemoryStateBackend:将状态数据保存在内存中
FsStateBackend:将状态数据包括到文件系统中
RocksDBStateBackend:将状态数据保存在RocksDB中
2. StateBackend 接口
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 package org.apache.flink.runtime.state;import org.apache.flink.annotation.PublicEvolving ;import org.apache.flink.api.common.JobID ;import org.apache.flink.api.common.typeutils.TypeSerializer ;import org.apache.flink.core.fs.CloseableRegistry ;import org.apache.flink.metrics.MetricGroup ;import org.apache.flink.runtime.execution.Environment ;import org.apache.flink.runtime.query.TaskKvStateRegistry ;import org.apache.flink.runtime.state.ttl.TtlTimeProvider ;import javax.annotation.Nonnull ;import java.io.IOException ;import java.util.Collection ;@PublicEvolving public interface StateBackend extends java.io.Serializable { CompletedCheckpointStorageLocation resolveCheckpoint(String externalPointer) throws IOException ; CheckpointStorage createCheckpointStorage(JobID jobId) throws IOException ; <K > AbstractKeyedStateBackend <K > createKeyedStateBackend( Environment env, JobID jobID, String operatorIdentifier, TypeSerializer <K > keySerializer, int numberOfKeyGroups, KeyGroupRange keyGroupRange, TaskKvStateRegistry kvStateRegistry, TtlTimeProvider ttlTimeProvider, MetricGroup metricGroup, @Nonnull Collection <KeyedStateHandle > stateHandles, CloseableRegistry cancelStreamRegistry) throws Exception ; OperatorStateBackend createOperatorStateBackend( Environment env, String operatorIdentifier, @Nonnull Collection <OperatorStateHandle > stateHandles, CloseableRegistry cancelStreamRegistry) throws Exception ; }
3 MemoryStateBackend
memory state backend 是 flink 的默认状态后端方式,它将 工作状态 保存在 TaskManager的内存中 ,并将 检查点 存储在 JobManager的内存中 。
memory state backend 是轻量级的,没有其他依赖关系,访问速度快,但是容错率低,并且仅支持小状态。
在进行 CheckPoint 操作时,State Backend 对状态进行快照,并将快照信息作为 CheckPoint 应答消息的一部分发送给 JobManager(master),同时 JobManager 也将快照信息存储在堆内存中
StateBackend 创建用于原始字节存储以及键控状态和运算符状态的服务。
原始字节存储(通过CheckpointStreamFactory )是基本服务,它仅以容错方式存储字节。 JobManager使用此服务来存储检查点和恢复元数据,并且键控和操作员状态后端通常还使用该服务来存储检查点状态。
由此状态后端创建的AbstractKeyedStateBackend和OperatorStateBackend定义如何保持键和运算符的工作状态。 它们还定义了如何使用原始字节存储(通过CheckpointStreamFactory )来频繁地检查该状态。 但是,也可能的是,例如键控状态后端仅实现了到键/值存储的桥接,并且不需要在检查点上将任何内容存储在原始字节存储中。
3.1.1 异步快照 MemoryStateBackend 能配置异步快照。强烈建议使用异步快照来防止数据流阻塞,注意,异步快照默认是开启的。 用户可以在实例化 MemoryStateBackend 的时候,将相应布尔类型的构造参数设置为 false 来关闭异步快照(仅在 debug 的时候使用)。
1 2 new MemoryStateBackend (MAX_MEM_STATE_SIZE , false );
3.1.2 限制
默认情况下,每个独立的状态大小限制是 5 MB。在 MemoryStateBackend 的构造器中可以增加其大小。
无论配置的最大状态内存大小(MAX_MEM_STATE_SIZE)有多大,都不能大于 akka.framesize 大小(默认 1.25M)(详见配置参数 )
聚合后的状态必须能够放进 JobManager 的内存中
3.1.3 适用场景
本地开发和调试。
状态很小的 Job,例如:由每次只处理一条记录的函数(Map、FlatMap、Filter 等)构成的 Job。Kafka Consumer 仅仅需要非常小的状态。
3.1.4 构造器 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 public MemoryStateBackend () {...} public MemoryStateBackend (boolean asynchronousSnapshots) {...} public MemoryStateBackend (int maxStateSize) {...} public MemoryStateBackend (int maxStateSize, boolean asynchronousSnapshots) {...} public MemoryStateBackend (@Nullable String checkpointPath, @Nullable String savepointPath) {...} public MemoryStateBackend ( @Nullable String checkpointPath, @Nullable String savepointPath, int maxStateSize, TernaryBoolean asynchronousSnapshots) {...}
3.1.5 代码示例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 import com.hnbian.flink.common.Obj1 import com.hnbian.flink.state.keyed.TestValueState import org.apache.flink.api.common.state.{ValueState , ValueStateDescriptor }import org.apache.flink.api.scala.createTypeInformationimport org.apache.flink.api.scala.typeutils.Types import org.apache.flink.runtime.state.memory.MemoryStateBackend import org.apache.flink.streaming.api.functions.KeyedProcessFunction import org.apache.flink.streaming.api.scala.{DataStream , KeyedStream , StreamExecutionEnvironment }import org.apache.flink.util.Collector object TestMemoryStateBackend extends App val env = StreamExecutionEnvironment .getExecutionEnvironment env.setParallelism(1 ) import org.apache.flink.streaming.api.CheckpointingMode import org.apache.flink.streaming.api.environment.CheckpointConfig env.enableCheckpointing(5000 ) val stateBackend = new MemoryStateBackend (true ) env.setStateBackend(stateBackend) env.getCheckpointConfig.setCheckpointingMode(CheckpointingMode .EXACTLY_ONCE ) env.getCheckpointConfig.setMinPauseBetweenCheckpoints(500 ) env.getCheckpointConfig.setCheckpointTimeout(30 * 1000 ) env.getCheckpointConfig.setMaxConcurrentCheckpoints(1 ) env.getCheckpointConfig.enableExternalizedCheckpoints(CheckpointConfig .ExternalizedCheckpointCleanup .RETAIN_ON_CANCELLATION ) val stream1: DataStream [String ] = env.socketTextStream("localhost" ,9999 ) private val value: DataStream [Obj1 ] = stream1 .map(data => { val arr = data.split("," ) Obj1 (arr(0 ), arr(1 ), arr(2 ).toLong) }) private val value1: KeyedStream [Obj1 , String ] = value.keyBy(_.id) value1 .process(new TestMemoryStateBackend ) .print("TestMemoryStateBackend" ) env.execute() } class TestMemoryStateBackend extends KeyedProcessFunction [String , Obj1 , String ] val valueStateDescriptor = new ValueStateDescriptor [Obj1 ]("objs" , Types .of[Obj1 ]) lazy val valueState: ValueState [Obj1 ] = getRuntimeContext.getState(valueStateDescriptor) override def processElement Obj1 , ctx: KeyedProcessFunction [String , Obj1 , String ]#Context , out: Collector [String ]) = { val prev = valueState.value() if (null == prev){ valueState.update(value) }else { val obj1 = valueState.value() println(s"obj1.time=${obj1.time} ,value.time=${value.time} " ) if (obj1.time < value.time){ valueState.update(value) } } out.collect(value.name) } }
4. FsStateBackend 3.2.1 介绍
FsStateBackend 将正在运行中的状态数据保存在 TaskManager 的内存中。CheckPoint 时,将状态快照写入到配置的文件系统目录中,通常是复制的高可用性文件系统,例如 HDFS , Ceph , S3 , GCS 等。 少量的元数据信息存储到 JobManager 的内存中(高可用模式下,将其写入到 CheckPoint 的元数据文件中)。
file system state backend 有着内存级别的快速访问和文件系统存储的安全性,能够更好的容错
file system state backend 需要配置一个文件系统的 URL(类型、地址、路径),例如:”hdfs://namenode:40010/flink/checkpoints” 或 “file:///data/flink/checkpoints”。
FsStateBackend 默认使用异步快照来防止 CheckPoint 写状态时对数据处理造成阻塞。 用户可以在实例化 FsStateBackend 的时候,将相应布尔类型的构造参数设置为 false 来关闭异步快照,例如:
1 2 new FsStateBackend (path, false );
3.2.2 使用场景
状态比较大、窗口比较长、key/value 状态比较大的 Job。
所有高可用的场景。
3.2.3 构造器 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 public FsStateBackend (String checkpointDataUri) {...}public FsStateBackend (String checkpointDataUri, boolean asynchronousSnapshots) {...}public FsStateBackend (Path checkpointDataUri) {...}public FsStateBackend (Path checkpointDataUri, boolean asynchronousSnapshots) {...}public FsStateBackend (URI checkpointDataUri) {...}public FsStateBackend (URI checkpointDataUri, @Nullable URI defaultSavepointDirectory) {...}public FsStateBackend (URI checkpointDataUri, boolean asynchronousSnapshots) {...}public FsStateBackend (URI checkpointDataUri, int fileStateSizeThreshold) {...}public FsStateBackend (URI checkpointDataUri,int fileStateSizeThreshold,boolean asynchronousSnapshots) {...}public FsStateBackend (URI checkpointDirectory,@Nullable URI defaultSavepointDirectory, int fileStateSizeThreshold,int writeBufferSize,TernaryBoolean asynchronousSnapshots) {...}
3.2.4 代码示例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 import com.hnbian.flink.common.Obj1 import com.hnbian.flink.state.keyed.TestValueState import org.apache.flink.api.common.state.{ValueState , ValueStateDescriptor }import org.apache.flink.api.scala.createTypeInformationimport org.apache.flink.api.scala.typeutils.Types import org.apache.flink.runtime.state.memory.MemoryStateBackend import org.apache.flink.streaming.api.functions.KeyedProcessFunction import org.apache.flink.streaming.api.scala.{DataStream , KeyedStream , StreamExecutionEnvironment }import org.apache.flink.util.Collector object TestFsStateBackend extends App val env = StreamExecutionEnvironment .getExecutionEnvironment env.setParallelism(1 ) import org.apache.flink.runtime.state.filesystem.FsStateBackend import org.apache.flink.streaming.api.CheckpointingMode import org.apache.flink.streaming.api.environment.CheckpointConfig env.enableCheckpointing(5000 ) val stateBackend = new FsStateBackend ("file:///opt/flink-1.10.2/checkpoint" ,true ) env.setStateBackend(stateBackend) env.getCheckpointConfig.setCheckpointingMode(CheckpointingMode .EXACTLY_ONCE ) env.getCheckpointConfig.setMinPauseBetweenCheckpoints(500 ) env.getCheckpointConfig.setCheckpointTimeout(30 * 1000 ) env.getCheckpointConfig.setMaxConcurrentCheckpoints(1 ) env.getCheckpointConfig.enableExternalizedCheckpoints(CheckpointConfig .ExternalizedCheckpointCleanup .RETAIN_ON_CANCELLATION ) val stream1: DataStream [String ] = env.socketTextStream("localhost" ,9999 ) private val value: DataStream [Obj1 ] = stream1 .map(data => { val arr = data.split("," ) Obj1 (arr(0 ), arr(1 ), arr(2 ).toLong) }) private val value1: KeyedStream [Obj1 , String ] = value.keyBy(_.id) value1 .process(new TestFsStateBackend ) .print("TestFsStateBackend" ) env.execute() } class TestFsStateBackend extends KeyedProcessFunction [String , Obj1 , String ] val valueStateDescriptor = new ValueStateDescriptor [Obj1 ]("objs" , Types .of[Obj1 ]) lazy val valueState: ValueState [Obj1 ] = getRuntimeContext.getState(valueStateDescriptor) override def processElement Obj1 , ctx: KeyedProcessFunction [String , Obj1 , String ]#Context , out: Collector [String ]) = { val prev = valueState.value() if (null == prev){ valueState.update(value) }else { val obj1 = valueState.value() println(s"obj1.time=${obj1.time} ,value.time=${value.time} " ) if (obj1.time < value.time){ valueState.update(value) } } out.collect(value.name) } }
5. RocksDBStateBackend 5.1 介绍
RocksDBStateBackend 将正在运行中的状态数据保存在 RocksDB 数据库中,RocksDB 数据库默认将数据存储在 TaskManager 的数据目录。
CheckPoint 时,整个 RocksDB 数据库被 checkpoint 到配置的文件系统目录中。 少量的元数据信息存储到 JobManager 的内存中(高可用模式下,将其存储到 CheckPoint 的元数据文件中)。
RocksDB 的支持并不直接包含在 flink 中,需要引入依赖
RocksDBStateBackend 只支持异步快照。
RocksDBStateBackend将工作状态存储在RocksDB中 ,并默认将状态检查点指向文件系统(类似于FsStateBackend )。所以 RocksDBStateBackend 需要配置一个文件系统的 URL (类型、地址、路径),例如:”hdfs://namenode:40010/flink/checkpoints” 或 “file:///data/flink/checkpoints”。
5.2 限制
由于 RocksDB 的 JNI API 构建在 byte[] 数据结构之上, 所以每个 key 和 value 最大支持 2^31 字节。 重要信息: RocksDB 合并操作的状态(例如:ListState)累积数据量大小可以超过 2^31 字节,但是会在下一次获取数据时失败。这是当前 RocksDB JNI 的限制。
5.3 使用场景
状态非常大、窗口非常长、key/value 状态非常大的 Job。
所有高可用的场景。
注意,你可以保留的状态大小仅受磁盘空间的限制。与状态存储在内存中的 FsStateBackend 相比,RocksDBStateBackend 允许存储非常大的状态。 然而,这也意味着使用 RocksDBStateBackend 将会使应用程序的最大吞吐量降低。 所有的读写都必须序列化、反序列化操作,这个比基于堆内存的 state backend 的效率要低很多。
RocksDBStateBackend 是目前唯一支持增量 CheckPoint 的 State Backend (见 这里 )。
可以使用一些 RocksDB 的本地指标(metrics),但默认是关闭的。你能在 这里 找到关于 RocksDB 本地指标的文档。
5.4 增量快照
增量快照即 只包含自上一次快照完成之后被修改的记录,使用增量快照方式可以显著减少快照完成的耗时。
RocksDBStateBackend 支持 增量快照。不同于产生一个包含所有数据的全量备份
一个增量快照通常是基于多个前序快照构建的。由于 RocksDB 内部存在 compaction 机制对 sst 文件进行合并,Flink 的增量快照也会定期重新设立起点(rebase),因此增量链条不会一直增长,旧快照包含的文件也会逐渐过期并被自动清理。
增量快照 与全量快照的比较
增量快照
全量快照
网络带宽是瓶颈
消耗更多时间
消耗更少时间
CPU 或者 IO 是瓶颈
消耗更少时间
消耗更多时间
在状态数据量很大时我们可以使用增量快照,需要通过下述配置手动开启该功能(默认不开启):
在 flink-conf.yaml 中设置:state.backend.incremental: true 或者
在代码中按照右侧方式配置(来覆盖默认配置):RocksDBStateBackend backend = new RocksDBStateBackend(filebackend, true);
需要注意的是,一旦启用了增量快照,网页上展示的 Checkpointed Data Size 只代表增量上传的数据量,而不是一次快照的完整数据量。
5.5 构造器
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 public RocksDBStateBackend (String checkpointDataUri) throws IOException{...}public RocksDBStateBackend (String checkpointDataUri, boolean enableIncrementalCheckpointing) throws IOException {...}public RocksDBStateBackend (URI checkpointDataUri) throws IOException {...}public RocksDBStateBackend (URI checkpointDataUri, boolean enableIncrementalCheckpointing) throws IOException {...}public RocksDBStateBackend (StateBackend checkpointStreamBackend) {...}public RocksDBStateBackend (StateBackend checkpointStreamBackend, TernaryBoolean enableIncrementalCheckpointing) {...}
5.5 代码示例
引入依赖
1 2 3 4 5 <dependency > <groupId > org.apache.flink</groupId > <artifactId > flink-statebackend-rocksdb_2.11</artifactId > <version > ${flink.version}</version > </dependency >
设置状态后端
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 import com.hnbian.flink.common.Obj1 import org.apache.flink.streaming.api.scala.{DataStream , KeyedStream , StreamExecutionEnvironment }import org.apache.flink.api.common.restartstrategy.RestartStrategies import org.apache.flink.api.common.state.{ValueState , ValueStateDescriptor }import org.apache.flink.api.scala.createTypeInformationimport org.apache.flink.api.scala.typeutils.Types import org.apache.flink.contrib.streaming.state.RocksDBStateBackend import org.apache.flink.streaming.api.environment.CheckpointConfig import org.apache.flink.streaming.api.functions.KeyedProcessFunction import org.apache.flink.util.Collector object TestRocksDBStateBackend extends App System .setProperty("HADOOP_USER_NAME" , "root" ) System .setProperty("hadoop.home.dir" , "/usr/hdp/3.1.0.0-78/hadoop//bin/" ) private val environment: StreamExecutionEnvironment = StreamExecutionEnvironment .getExecutionEnvironment environment.enableCheckpointing(5000 ); environment.setRestartStrategy(RestartStrategies .fixedDelayRestart(3 , 1000 )) val stateBackend = new RocksDBStateBackend ("file:///opt/flink-1.10.2/checkpoint" ) environment.setStateBackend(stateBackend) environment.getCheckpointConfig.enableExternalizedCheckpoints(CheckpointConfig .ExternalizedCheckpointCleanup .RETAIN_ON_CANCELLATION ) val stream1: DataStream [String ] = environment.socketTextStream("localhost" ,9999 ) private val value: DataStream [Obj1 ] = stream1 .map(data => { val arr = data.split("," ) Obj1 (arr(0 ), arr(1 ), arr(2 ).toLong) }) private val value1: KeyedStream [Obj1 , String ] = value.keyBy(_.id) value1 .process(new TestRocksDBStateBackend ) .print("TestRocksDBStateBackend" ) environment.execute() } class TestRocksDBStateBackend extends KeyedProcessFunction [String , Obj1 , String ] val valueStateDescriptor = new ValueStateDescriptor [Obj1 ]("objs" , Types .of[Obj1 ]) lazy val valueState: ValueState [Obj1 ] = getRuntimeContext.getState(valueStateDescriptor) override def processElement Obj1 , ctx: KeyedProcessFunction [String , Obj1 , String ]#Context , out: Collector [String ]) = { val prev = valueState.value() if (null == prev){ valueState.update(value) }else { val obj1 = valueState.value() println(s"obj1.time=${obj1.time} ,value.time=${value.time} " ) if (obj1.time < value.time){ valueState.update(value) } } out.collect(value.name) } }
6. State Backend 其他配置 如果没有明确指定,将使用 jobmanager 做为默认的 state backend。你能在 flink-conf.yaml 中为所有 Job 设置其他默认的 State Backend。 每一个 Job 的 state backend 配置会覆盖默认的 state backend 配置,如下所示:
6.1 设置每个 Job 的 State Backend StreamExecutionEnvironment 可以对每个 Job 的 State Backend 进行设置,如下所示:
1 2 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setStateBackend(new FsStateBackend ("hdfs://namenode:40010/flink/checkpoints" ));
如果你想在 IDE 中使用 RocksDBStateBackend,或者需要在作业中通过编程方式动态配置 RocksDBStateBackend,必须添加以下依赖到 Flink 项目中。
1 2 3 4 5 <dependency > <groupId > org.apache.flink</groupId > <artifactId > flink-statebackend-rocksdb_2.11</artifactId > <version > ${flink.version}</version > </dependency >
6.2 设置默认的(全局的) State Backend 在 flink-conf.yaml 可以通过键 state.backend 设置默认的 State Backend。
可选值包括 jobmanager (MemoryStateBackend)、filesystem (FsStateBackend)、rocksdb*(RocksDBStateBackend), 或使用实现了 state backend 工厂 StateBackendFactory 的类的全限定类名, 例如: RocksDBStateBackend 对应为 org.apache.flink.contrib.streaming.state.RocksDBStateBackendFactory。
state.checkpoints.dir 选项指定了所有 State Backend 写 CheckPoint 数据和写元数据文件的目录。 你能在 这里 找到关于 CheckPoint 目录结构的详细信息。
配置文件的部分示例如下所示:
1 2 3 4 5 state.backend: filesystem state.checkpoints.dir: hdfs://namenode:40010/flink/checkpoints