1 Exactly-Once事务处理
1.1 什么是Exactly-Once事务?
数据仅处理一次并且仅输出一次,这样才是完整的事务处理。
以银行转帐为例,A用户转账给B用户,B用户可能收到多笔钱,保证事务的一致性,也就是说事务输出,能够输出且只会输出一次,即A只转一次,B只收一次。
1.2 从事务视角解密Spark Streaming架构
如下图,Spark Streaming应用程序启动,会分配资源,除非整个集群硬件资源崩溃,一般情况下都不会有问题。Spark Streaming程序分成两部分,一部分是Driver,另外一部分是Executor。Receiver接收到数据后不断发送元数据给Driver,Driver接收到元数据信息后进行CheckPoint处理。其中CheckPoint的元数据包括:Configuration(含有Spark Conf、Spark Streaming等配置信息)、Block MetaData、DStreamGraph、未处理完和等待中的Job。当然Receiver可以在多个Executor节点的上执行Job,Job的执行完全基于SparkCore的调度模式进行的。
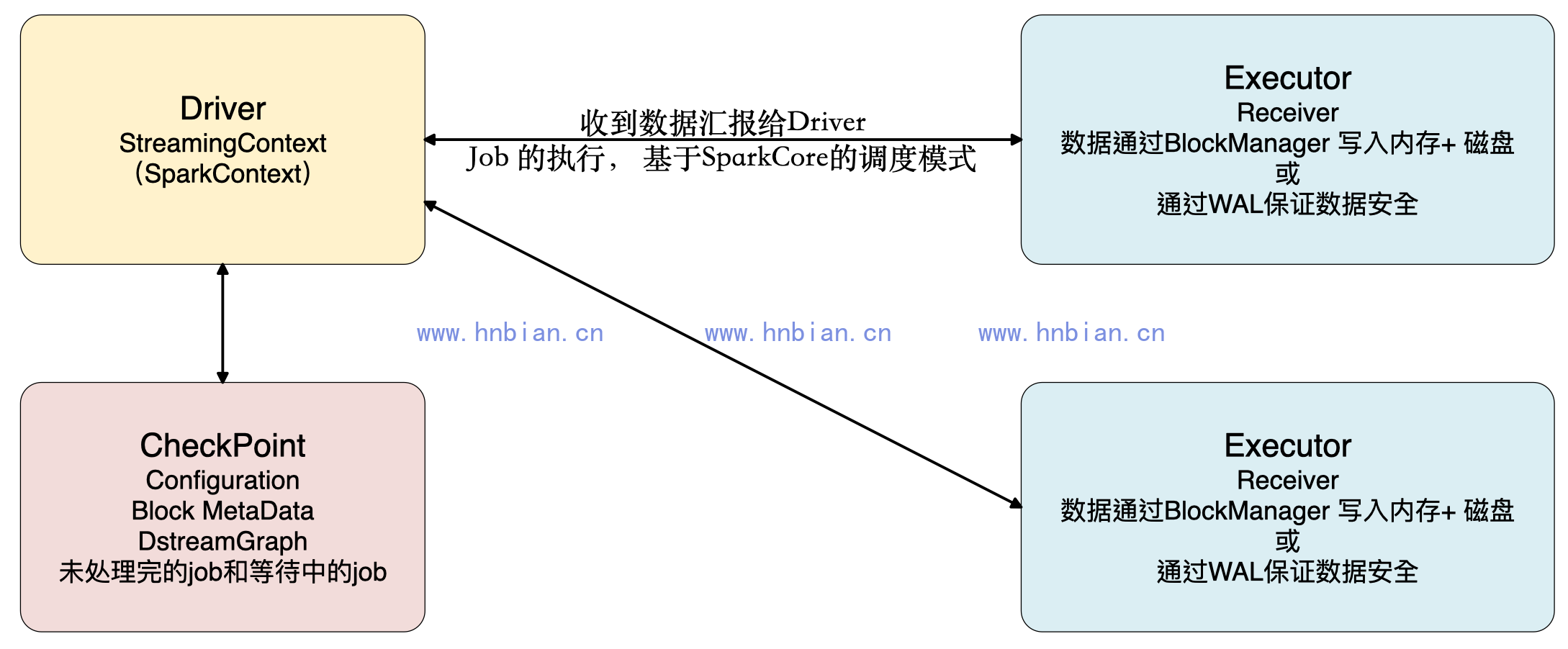
Executor只有函数处理逻辑和数据,外部InputStream流入到Receiver中通过BlockManager写入磁盘、内存、WAL进行容错。WAL先写入磁盘然后写入Executor中,失败可能性不大。如果1G数据要处理,Executor一条一条接收,Receiver接收数据是积累到一定记录后才会写入WAL,如果Receiver线程失败时,数据有可能会丢失。
Driver处理元数据前会进行CheckPoint,Spark Streaming获取数据、产生作业,但没有解决执行的问题,执行一定要经过SparkContext。Driver级别的数据修复从Driver CheckPoint中需要把数据读入,在其内部会重新构建SparkContext、StreamingContext、SparkJob,再提交Spark集群运行。Receiver的重新恢复时会通过磁盘的WAL从磁盘恢复过来。
1.3 数据可能丢失的情况及通常的解决方式
在Receiver收到数据且通过Driver的调度Executor开始计算数据的时候,如果Driver突然奔溃,则此时Executor会被杀死,那么Executor中的数据就会丢失(如果没有进行WAL的操作)。
此时就必须通过例如WAL的方式,让所有的数据都通过例如HDFS的方式首先进行安全性容错处理。此时如果Executor中的数据丢失的话,就可以通过WAL恢复回来。
注意:这种方式的弊端是通过WAL的方式会极大额损伤SparkStreaming中Receivers接收数据的性能。
1.4 Exactly-Once事务处理如何解决数据零丢失?
解决数据零丢失,必须有可靠的数据来源和可靠的Receiver,且整个应用程序的metadata必须进行checkpoint,且通过WAL来保证数据安全。
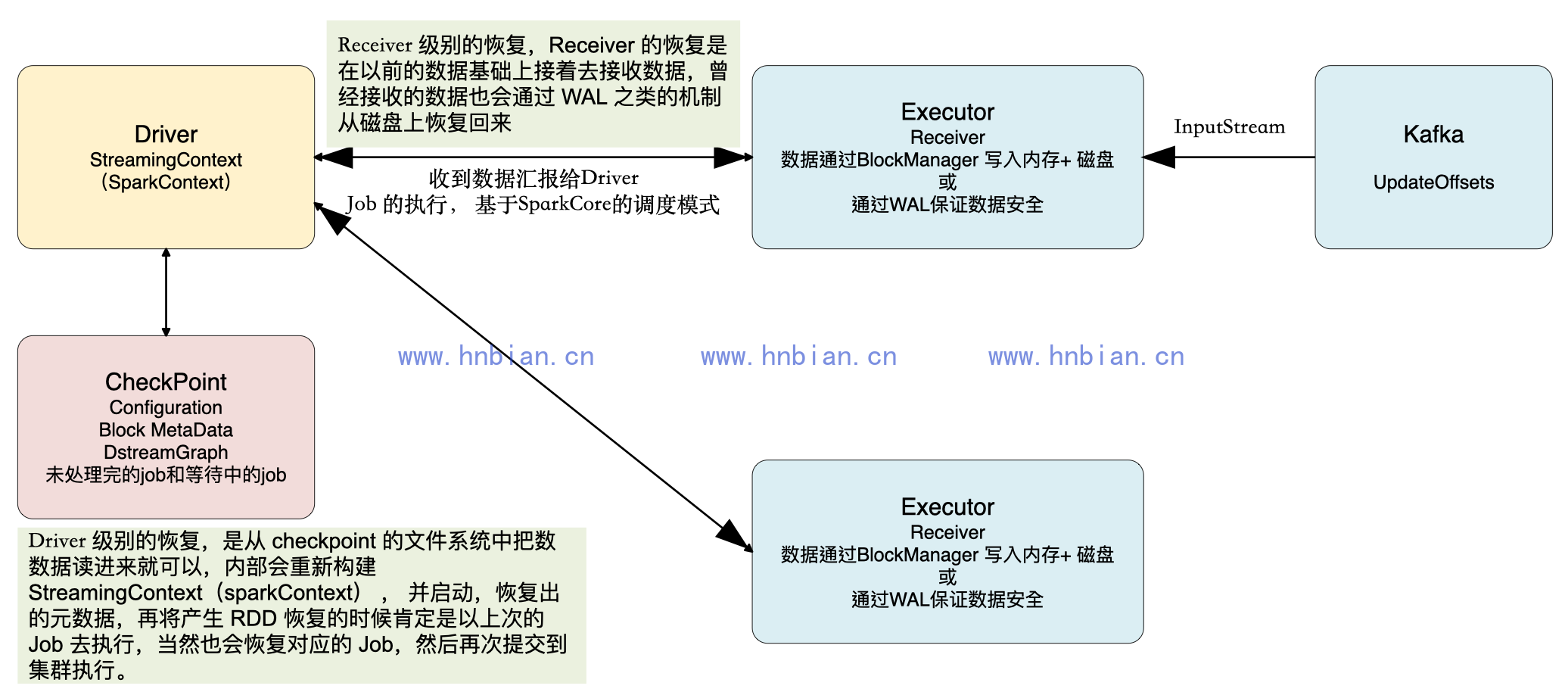
我们以数据来自Kafka为例,运行在Executor上的Receiver在接收到来自Kafka的数据时会向Kafka发送ACK确认收到信息并读取下一条信息,Kafka会通过updateOffset来记录Receiver接收到的偏移,这种方式保证了在Executor数据零丢失。在Driver端,定期进行checkpoint操作,出错时从Checkpoint的文件系统中把数据读取进来进行恢复,内部会重新构建StreamingContext(也就是构建SparkContext)并启动,恢复出元数据metedata,再次产生RDD,恢复的是上次的Job,然后再次提交到集群执行。
1.5 Exactly-Once事务处理如何解决数据重复读取?
在Receiver收到数据保存到HDFS等持久化引擎但是没有来得及进行updateOffsets(以Kafka为例),此时Receiver崩溃后重新启动就会通过管理Kafka的Zookeeper中元数据再次重复读取数据,但是此时Spark Streaming认为是成功的,但是Kafka认为是失败的(因为没有更新offset到ZooKeeper中),此时就会导致数据重新消费的情况。
以Receiver基于ZooKeeper的方式,当读取数据时去访问Kafka的元数据信息,在处理代码中例如foreachRDD或transform时,将信息写入到内存数据库中(memorySet),在计算时读取内存数据库信息,判断是否已处理过,如果以处理过则跳过计算。这些元数据信息可以保存到内存数据结构或者memsql,sqllite中。
注意:如果通过Kafka作为数据来源的话,Kafka中有数据,然后Receiver接收的时候又会有数据副本,这个时候其实是存储资源的浪费。Spark在1.3的时候为了避免WAL的性能损失和实现Exactly Once而提供了Kafka Direct API,把Kafka作为文件存储系统。此时兼具有流的优势和文件系统的优势,至此Spark Streaming+Kafka就构建了完美的流处理世界(1,数据不需要拷贝副本;2,不需要WAL对性能的损耗;3,Kafka使用ZeroCopy比HDFS更高效)。所有的Executors通过Kafka API直接消息数据,直接管理Offset,所以也不会重复消费数据。
2 输出不重复的解决办法
2.1 为什么会有数据输出多次重写这个问题?
因为Spark Streaming在计算的时候基于Spark Core天生会做以下事情导致Spark Streaming的结果(部分)重复输出:
- Task重试
- 慢任务推测
- Stage重试
- Job重试
2.2 具体解决方案?
- 设置spark.task.maxFailures次数为1,这样就不会有Task重试了。
- 设置spark.speculation为关闭状态,就不会有慢任务推测了,因为慢任务推测非常消耗性能,所以关闭后可以显著提高Spark Streaming处理性能。
- Spark Streaming On Kafka的话,Job失败后可以设置Kafka的参数auto.offset.reset为largest方式。
2.3 kafka auto.offset.reset 值含义解释
- 当各分区下有已提交的offset时(默认使用latest)
| 参数 |
说明 |
| earliest |
从提交的offset开始消费;无提交的offset时,从头开始消费 |
| latest |
从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据 |
| none |
从offset后开始消费;只要有一个分区不存在已提交的offset,则抛出异常 |
| 参数 |
结果 |
| none |
当该topic下所有分区中存在未提交的offset时,抛出异常。 |
| earliest |
当分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费。 |
| latest |
当分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据。 |
3. 使用示例
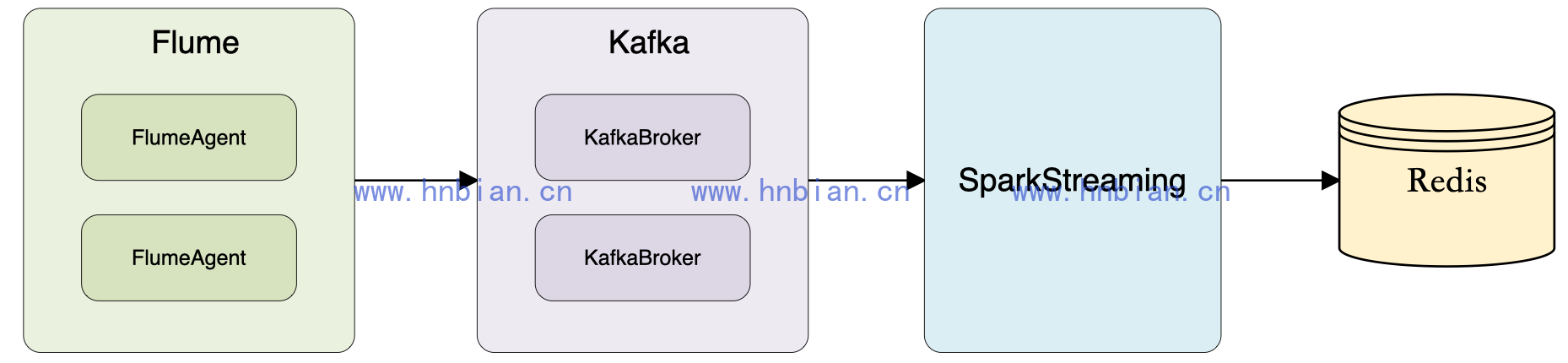
在实时流式计算中, 最重要的是在任何情况下, 消息不重复、比丢失, 即Exactly-once。 下面以 kafka -> Spark Streaming -> Redis 为例, 一方面说明一下如何做到 Exactly-once, 另一方面说明一下计算实时如何做去重指标
3.1 关于数据源
数据源是文本格式的日志, 由Nginx 产生, 存放在日志服务器上。 在日志服务器上部署flume Agent, 使用 TAILDIR Source 和kafka sink, 将日志采集到kafka进行临时存储, 日志格式如下:
1
2
3
4
5
6
7
8
9
10
| 2018-02-22T00:00:00+08:00|~|200|~|/test?pcid=DEIBAH&siteid=3
2018-02-22T00:00:00+08:00|~|200|~|/test?pcid=GLLIEG&siteid=3
2018-02-22T00:00:00+08:00|~|200|~|/test?pcid=HIJMEC&siteid=8
2018-02-22T00:00:00+08:00|~|200|~|/test?pcid=HMGBDE&siteid=3
2018-02-22T00:00:00+08:00|~|200|~|/test?pcid=HIJFLA&siteid=4
2018-02-22T00:00:01+08:00|~|200|~|/test?pcid=JCEBBC&siteid=9
2018-02-22T00:00:01+08:00|~|200|~|/test?pcid=KJLAKG&siteid=8
2018-02-22T00:00:01+08:00|~|200|~|/test?pcid=FHEIKI&siteid=3
2018-02-22T00:00:01+08:00|~|200|~|/test?pcid=IGIDLB&siteid=3
2018-02-22T00:00:01+08:00|~|200|~|/test?pcid=IIIJCD&siteid=5
|
日志是由测试程序模拟产生的,字段之间由|~|分隔。
3.2 实时计算需求
分天、分小时PV;
分天、分小时、分网站(siteid)PV;
分天 UV;
3.3 消费Kafka数据
http://spark.apache.org/docs/latest/streaming-kafka-0-10-integration.html
在Spark Streaming 中消费kafka数据, 保证Exactly-once 的核心有三点:
使用Direct 方式连接kafka
自己保存和维护Offset
更新Offset和计算在同一事务中完成
后面的Spark Streaming 程序, 主要有一下步骤:
启动后, 先从 Redis 中获取上次保存的 Offset, Redis 中的可以 为 topic_partition , 即每个分区维护一个Offset
使用获取到的 Offset, 创建 DirectStream
在处理每批次的消息时, 利用 Redis 的事物机制, 确保在 Redis 中指标的计算和 Offset 的更新维护在同一事物中完成。 只有这两者同步, 才能真正保证消息的 Exactly-once
1
2
3
4
5
6
7
8
9
10
11
| ./spark-submit \
--class com.hnbian.spark.TestSparkStreaming \
--master local[2] \
--conf spark.streaming.kafka.maxRatePerPartition=20000 \
--jars /opt/hnbian/realtime/commons-pool2-2.3.jar,\
/opt/hnbian/realtime/jedis-2.9.0.jar,\
/opt/hnbian/realtime/kafka-clients-0.11.0.1.jar,\
/opt/hnbian/realtime/spark-streaming-kafka-0-10_2.11-2.2.1.jar \
/opt/hnbian/realtime/testsparkstreaming.jar \
--executor-memory 4G \
--num-executors 1
|
在启动Spark Streaming 程序的时候, 有个参数最好指定:
spark.streaming.kafka.maxRatePerPartition=20000 ( 每秒钟从topic 的每个partition 最多消费的消息数)
如果程序第一次运行, 或者因为某种原因暂停了很久, 重新启动的时候, 会积累很多消息, 如果这些消息同事被消费, 很可能会因为内存不够而挂掉, 因为需要根据实际的数据量大小, 以及批次的间隔时间来说设置该参数, 以限定批次的消息量。
如果该参数设置20000, 而批次间隔时间为10s, 那么每个批次最多从kafka中消费20w消息
3.4 Redis中的数据模型
普通K-V结构,计算时候使用incr命令递增,
Key为 site_pv_网站ID_小时,
如:site_pv_9_2018-02-21-00、site_pv_10_2018-02-21-01
该数据模型用于计算分网站的按小时及按天PV。
普通K-V结构,计算时候使用incr命令递增,
Key为 pv_小时,如:pv_2018-02-21-14、pv_2018-02-22-03
该数据模型用于计算按小时及按天总PV。
Set结构,计算时候使用sadd命令添加,
Key为 uv_天,如:uv_2018-02-21、uv_2018-02-20
该数据模型用户计算按天UV(获取时候使用SCARD命令获取Set元素个数)
注:这些Key对应的时间,均由实际消息中的第一个字段(时间)而定。
3.5 故障恢复
如果 Spark Streaming 程序因为停电、网络等意外情况而终止需要恢复, 则直接重启即可;
如果因为其他原因需要重新计算某一时间段的消息, 可以先删除Redis中对应时间段内的key, 然后从原始日志中截取该段时间内的消息, 当做新的消息添加至kafka, 由Spark streaming 程序重新消费并进行计算;
3.6 附程序
依赖jar包:
1
2
3
4
| commons-pool2-2.3.jar
jedis-2.9.0.jar
kafka-clients-0.11.0.1.jar
spark-streaming-kafka-0-10_2.11-2.2.1.jar
|
3.7 代码示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
| import redis.clients.jedis.JedisPool
import org.apache.commons.pool2.impl.GenericObjectPoolConfig
object InternalRedisClient extends Serializable {
@transient private var pool: JedisPool = _
def makePool(host: String, port: Int, timeout: Int,
maxTotal: Int, maxIdle: Int, minIdle: Int): Unit = {
makePool(host, port, timeout, maxTotal, maxIdle, minIdle, testOnBorrow = true, testOnReturn = false, maxWaitMillis = 10000)
}
def makePool(host: String, port: Int, timeout: Int,
maxTotal: Int, maxIdle: Int, minIdle: Int, testOnBorrow: Boolean,
testOnReturn: Boolean, maxWaitMillis: Long): Unit = {
if (pool == null) {
val poolConfig = new GenericObjectPoolConfig()
poolConfig.setMaxTotal(maxTotal)
poolConfig.setMaxIdle(maxIdle)
poolConfig.setMinIdle(minIdle)
poolConfig.setTestOnBorrow(testOnBorrow)
poolConfig.setTestOnReturn(testOnReturn)
poolConfig.setMaxWaitMillis(maxWaitMillis)
pool = new JedisPool(poolConfig, host, port, timeout)
val hook = new Thread {
override def run(): Unit = pool.destroy()
}
sys.addShutdownHook(hook.run())
}
}
def getPool: JedisPool = {
assert(pool != null, "Redis连接池未被初始化!")
pool
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
| import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.TopicPartition
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.streaming._
import redis.clients.jedis.Pipeline
object TestSparkStreaming {
def main(args: Array[String]): Unit = {
val brokers = "datadev1:9092"
val topic = "exactly-once"
val partition: Int = 0
val start_offset: Long = 0L
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> brokers,
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "exactly-once",
"enable.auto.commit" -> (false: java.lang.Boolean),
"auto.offset.reset" -> "none"
)
val maxTotal = 10
val maxIdle = 10
val minIdle = 1
val redisHost = "172.16.213.79"
val redisPort = 6379
val redisTimeout = 30000
val dbDefaultIndex = 8
InternalRedisClient.makePool(redisHost, redisPort, redisTimeout, maxTotal, maxIdle, minIdle)
val conf = new SparkConf().setAppName("TestSparkStreaming").setIfMissing("spark.master", "local[2]")
val ssc = new StreamingContext(conf, Seconds(10))
val jedis = InternalRedisClient.getPool.getResource
try {
jedis.select(dbDefaultIndex)
val topic_partition_key = topic + "_" + partition
var lastOffset: Long = 0L
val lastSavedOffset = jedis.get(topic_partition_key)
if (null != lastSavedOffset) {
try {
lastOffset = lastSavedOffset.toLong
} catch {
case ex: Exception =>
println(ex.getMessage)
println("get lastSavedOffset error, lastSavedOffset from redis [" + lastSavedOffset + "] ")
System.exit(1)
}
}
println("lastOffset from redis -> " + lastOffset)
} finally {
InternalRedisClient.getPool.returnResource(jedis)
}
val fromOffsets = Map(new TopicPartition(topic, partition) -> lastOffset)
val stream = KafkaUtils.createDirectStream[String, String](
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Assign[String, String](
fromOffsets.keys.toList,
kafkaParams,
fromOffsets
)
)
stream.foreachRDD { rdd =>
val offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
val result = processLogs(rdd)
println("=============== Total " + result.length + " events in this batch ..")
val jedis = InternalRedisClient.getPool.getResource
val p1: Pipeline = jedis.pipelined()
try {
p1.select(dbDefaultIndex)
p1.multi()
result.foreach { record =>
val pv_by_hour_key = "pv_" + record.hour
p1.incr(pv_by_hour_key)
val site_pv_by_hour_key = "site_pv_" + record.site_id + "_" + record.hour
p1.incr(site_pv_by_hour_key)
val uv_by_day_key = "uv_" + record.hour.substring(0, 10)
p1.sadd(uv_by_day_key, record.user_id)
}
offsetRanges.foreach { offsetRange =>
println("partition : " + offsetRange.partition +
" fromOffset: " + offsetRange.fromOffset +
" untilOffset: " + offsetRange.untilOffset)
val topic_partition_key = offsetRange.topic + "_" + offsetRange.partition
p1.set(topic_partition_key, offsetRange.untilOffset + "")
}
p1.exec()
} catch {
case ex:Exception =>println(ex.getMessage)
} finally {
p1.sync()
InternalRedisClient.getPool.returnResource(jedis)
}
}
case class MyRecord(hour: String, user_id: String, site_id: String)
def processLogs(messages: RDD[ConsumerRecord[String, String]]): Array[MyRecord] = {
messages.map(_.value()).flatMap(parseLog).collect()
}
def parseLog(line: String): Option[MyRecord] = {
val ary: Array[String] = line.split("\\|~\\|", -1)
try {
val hour = ary(0).substring(0, 13).replace("T", "-")
val uri = ary(2).split("[=|&]", -1)
val user_id = uri(1)
val site_id = uri(3)
return Some(MyRecord(hour, user_id, site_id))
} catch {
case ex: Exception =>
println(ex.getMessage)
}
return None
}
ssc.start()
ssc.awaitTermination()
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
| JedisPoolConfig config = new JedisPoolConfig();
config.setBlockWhenExhausted(true);
config.setEvictionPolicyClassName("org.apache.commons.pool2.impl.DefaultEvictionPolicy");
config.setJmxEnabled(true);
config.setJmxNamePrefix("pool");
config.setLifo(true);
config.setMaxIdle(8);
config.setMaxTotal(8);
config.setMaxWaitMillis(-1);
config.setMinEvictableIdleTimeMillis(1800000);
config.setMinIdle(0);
config.setNumTestsPerEvictionRun(3);
config.setSoftMinEvictableIdleTimeMillis(1800000);
config.setTestOnBorrow(false);
config.setTestWhileIdle(false);
config.setTimeBetweenEvictionRunsMillis(-1);
JedisPool pool = new JedisPool(config, "localhost",);
int timeout=3000;
new JedisSentinelPool(master, sentinels, poolConfig,timeout);
|

