1. spark的动态资源划分
动态资源划分,是指在spark当中用于对计算的时候资源,如果不够或者资源剩余的情况下进行动态的资源划分,以求资源的利用率达到最大
Spark中的资源单位一般指的是executors,和Yarn中的Containers一样
- 在Spark On Yarn模式下,通常使用 –num-executors 来指定 Application 使用的 executors 数量
- –executor-memory 和 –executor-cores分别用来指定每个executor所使用的内存和虚拟CPU核数
假设有这样的场景:
如果使用Hive,多个用户同时使用hive-cli做数据开发和分析,只有当用户提交执行了Hive SQL时候,才会向YARN申请资源,执行任务,如果不提交执行,无非就是停留在Hive-cli命令行,也就是个JVM而已,并不会浪费YARN的资源。
现在想用Spark-SQL代替Hive来做数据开发和分析,也是多用户同时使用,如果按照之前的方式,以yarn-client模式运行spark-sql命令行,在启动时候指定–num-executors 10,那么每个用户启动时候都使用了10个YARN的资源(Container),这10个资源就会一直被占用着,只有当用户退出spark-sql命令行时才会释放。
例如通过以下这种方式使用spark-sql
1 | 直接通过 -e 来执行任务,执行完成任务之后,回收资源 |
spark-sql On Yarn,能不能像Hive一样,执行SQL的时候才去申请资源,不执行的时候就释放掉资源呢,其实从Spark1.2之后,对于On Yarn模式,已经支持动态资源分配(Dynamic Resource Allocation),这样,就可以根据Application的负载(Task情况),动态的增加和减少executors,这种策略非常适合在YARN上使用spark-sql做数据开发和分析,以及将spark-sql作为长服务来使用的场景。
spark当中支持通过动态资源划分的方式来实现动态资源的配置,尽量减少内存的持久占用,但是动态资源划分又会产生进一步的问题例如:
1 | executor动态调整的范围?无限减少?无限制增加? |
通过spark-shell当中最简单的 wordcount 为例来查看spark当中的资源划分
1 | # 以yarn模式执行,并指定executor个数为1 |
上述的Spark应用中,以yarn模式启动spark-shell,并顺序执行两次wordcount,最后Ctrl+C退出spark-shell。此例中Executor的生命周期如下图:
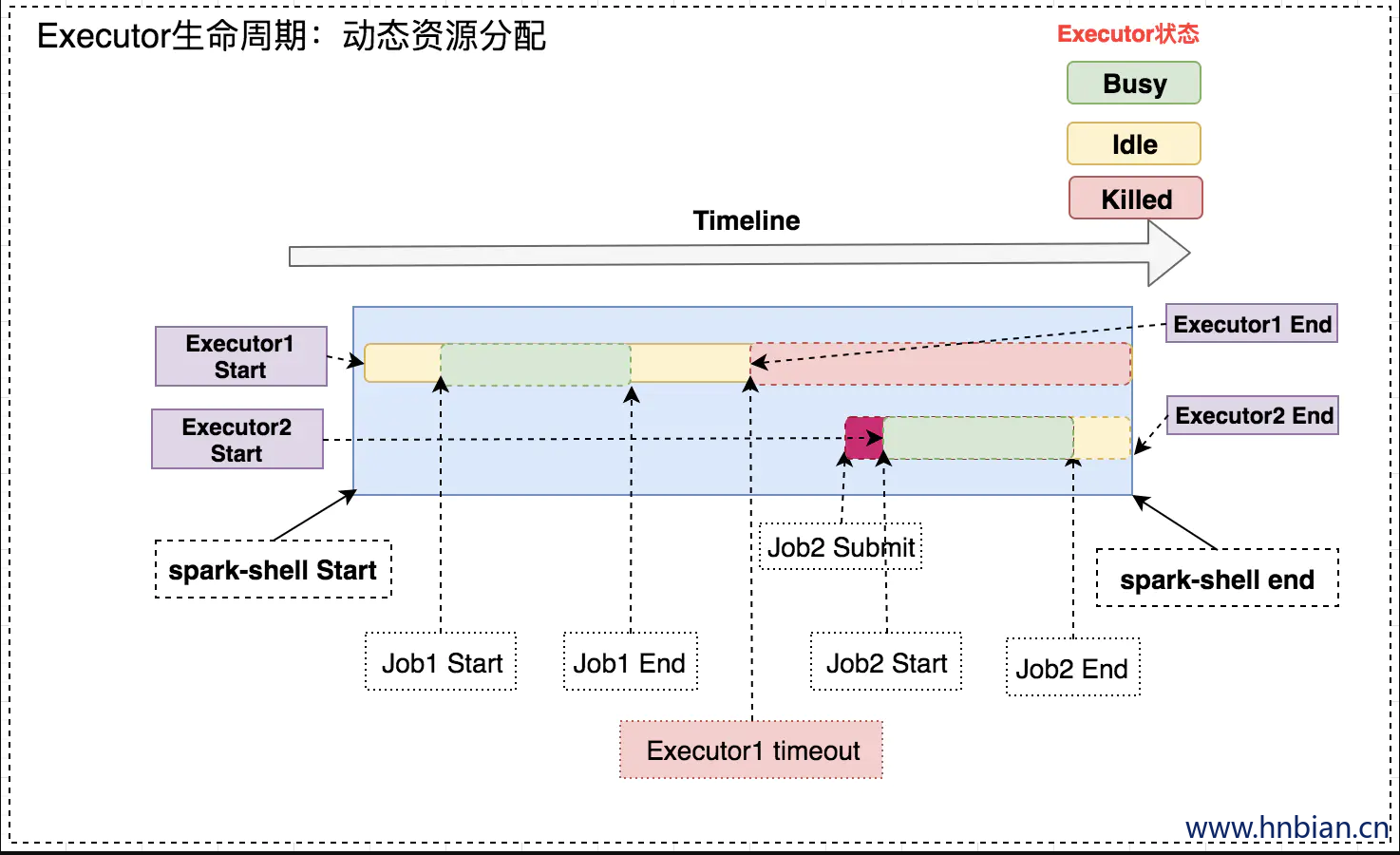
下面分析下上图中各个步骤:
- spark-shell Start:启动spark-shell应用,并通过–num-executor指定了1个执行器。
- Executor1 Start:启动执行器Executor1。注意:Executor启动前存在一个AM向ResourceManager申请资源的过程,所以启动时机略微滞后与Driver。
- Job1 Start:提交第一个wordcount作业,此时,Executor1处于Busy状态。
- Job1 End:作业1结束,Executor1又处于Idle状态。
- Executor1 timeout:Executor1空闲一段时间后,超时被Kill。
- Job2 Submit:提交第二个wordcount,此时,没有Active的Executor可用。Job2处于Pending状态。
- Executor2 Start:检测到有Pending的任务,此时Spark会启动Executor2。
- Job2 Start:此时,已经有Active的执行器,Job2会被分配到Executor2上执行。
- Job2 End:Job2结束。
- Executor2 End:Ctrl+C 杀死Driver,Executor2也会被RM杀死。
上述流程中需要重点关注的几个问题:
- Executor超时:当Executor不执行任何任务时,会被标记为Idle状态。空闲一段时间后即被认为超时,会被kill。该空闲时间由spark.dynamicAllocation.executorIdleTimeout决定,默认值60s。对应上图中:Job1 End到Executor1 timeout之间的时间。
- 资源不足时,何时新增Executor:当有Task处于pending状态,意味着资源不足,此时需要增加Executor。这段时间由spark.dynamicAllocation.schedulerBacklogTimeout控制,默认1s。对应上述step6和step7之间的时间。
- 该新增多少Executor:新增Executor的个数主要依据是当前负载情况,即running和pending任务数以及当前Executor个数决定。用maxNumExecutorsNeeded代表当前实际需要的最大Executor个数,maxNumExecutorsNeeded和当前Executor个数的差值即是潜在的新增Executor的个数。注意:之所以说潜在的个数,是因为最终新增的Executor个数还有别的因素需要考虑,后面会有分析。下面是maxNumExecutorsNeeded计算方法:
1 | private def maxNumExecutorsNeeded(): Int = { |
其中numRunningOrPendingTasks为当前running和pending任务数之和。
executorAllocationRatio:最理想的情况下,有多少待执行的任务,那么我们就新增多少个Executor,从而达到最大的任务并发度。但是这也有副作用,如果当前任务都是小任务,那么这一策略就会造成资源浪费。可能最后申请的Executor还没启动,这些小任务已经被执行完了。该值是一个系数值,范围[0~1]。默认1.
tasksPerExecutorForFullParallelism:每个Executor的最大并发数,简单理解为:cpu核心数(spark.executor.cores)/ 每个任务占用的核心数(spark.task.cpus)。
2. executor 动态调整的范围
要实现资源的动态调整,那么限定调整范围是最先考虑的事情,
Spark通过下面几个参数实现:
- spark.dynamicAllocation.minExecutors:Executor调整下限。(默认值:0)
- spark.dynamicAllocation.maxExecutors:Executor调整上限。(默认值:Integer.MAX_VALUE)
- spark.dynamicAllocation.initialExecutors:Executor初始数量(默认值:minExecutors)。
三者的关系必须满足:minExecutors <= initialExecutors <= maxExecutors
注意:如果显示指定了num-executors参数,那么initialExecutors就是num-executor指定的值。
- Executor既提供计算能力,也提供存储能力。这些因超时被杀死的Executor中持久化的数据如何处理?
如果Executor中缓存了数据,那么该Executor的Idle-timeout时间就不是由executorIdleTimeout决定,而是用 spark.dynamicAllocation.cachedExecutorIdleTimeout 控制,默认值:Integer.MAX_VALUE。
如果手动设置了该值,当这些缓存数据的Executor被kill后,我们可以通过NodeManannger的External Shuffle Server来访问这些数据。这就要求NodeManager中 spark.shuffle.service.enabled 必须开启。
3. 配置spark的动态资源划分
- 修改yarn-site.xml配置文件
1 | <property> |
- 配置spark的配置文件
修改spark-conf的配置选项,开启动态资源划分,或者直接修改spark-defaults.conf,增加以下参数:
1 | # 启用External shuffle Service服务 |
- 动态资源分配策略:
开启动态分配策略后,application会在task因没有足够资源被挂起的时候去动态申请资源,这种情况意味着该application现有的executor无法满足所有task并行运行。spark一轮一轮的申请资源,当有task挂起或等待spark.dynamicAllocation.schedulerBacklogTimeout(默认1s)时间的时候,会开始动态资源分配;之后会每隔spark.dynamicAllocation.sustainedSchedulerBacklogTimeout(默认1s)时间申请一次,直到申请到足够的资源。每次申请的资源量是指数增长的,即1,2,4,8等。
之所以采用指数增长,出于两方面考虑:其一,开始申请的少是考虑到可能application会马上得到满足;其次要成倍增加,是为了防止application需要很多资源,而该方式可以在很少次数的申请之后得到满足。
动态资源回收策略:
当application的executor空闲时间超过spark.dynamicAllocation.executorIdleTimeout(默认60s)后,就会被回收。
4. Spark 资源动态划分相关参数
| Property Name | Default | Meaning |
|---|---|---|
| spark.dynamicAllocation.enabled | false | Whether to use dynamic resource allocation, which scales the number of executors registered with this application up and down based on the workload. For more detail, see the description here. This requires spark.shuffle.service.enabled to be set. The following configurations are also relevant: spark.dynamicAllocation.minExecutors, spark.dynamicAllocation.maxExecutors, and spark.dynamicAllocation.initialExecutors |
| spark.dynamicAllocation.executorIdleTimeout | 60s | If dynamic allocation is enabled and an executor has been idle for more than this duration, the executor will be removed. For more detail, see this description. |
| spark.dynamicAllocation. cachedExecutorIdleTimeout |
infinity | If dynamic allocation is enabled and an executor which has cached data blocks has been idle for more than this duration, the executor will be removed. For more details, see this description. |
| spark.dynamicAllocation.maxExecutors | infinity | Upper bound for the number of executors if dynamic allocation is enabled. |
| spark.dynamicAllocation.minExecutors | 0 | Lower bound for the number of executors if dynamic allocation is enabled. |
| spark.dynamicAllocation. schedulerBacklogTimeout |
1s | If dynamic allocation is enabled and there have been pending tasks backlogged for more than this duration, new executors will be requested. For more detail, see this description. |
| Property Name | Default | Meaning |
|---|---|---|
| spark.dynamicAllocation. sustainedSchedulerBacklogTimeout |
schedulerBacklogTimeout | Same as spark.dynamicAllocation.schedulerBacklogTimeout, but used only for subsequent executor requests. For more detail, see this description. |
| spark.dynamicAllocation. initialExecutors |
spark. dynamicAllocation. minExecutors |
Initial number of executors to run if dynamic allocation is enabled. If --num-executors (or spark.executor.instances) is set and larger than this value, it will be used as the initial number of executors. |

