1. storm是什么?
- Storm是Twitter开源的一个分布式的实时计算系统
- 使用场景:数据的实时分析,持续计算,分布式RPC等等
2.storm 有哪些优点
- 分布式
- 可扩展
- 高可靠性
- 编程模型简单
- 高效实时
3. storm 常用网址
- 官网地址:http://storm-project.net/
- 源码地址:https://github.com/nathanmarz/storm
- 技术论坛:https://groups.google.com/forum/#!forum/storm-user
4. storm 中常用的类
- BaseRichSpout(消息生产者)(从外部文件或者消息队列里面读取数据,用来产生数据)
- BaseBasicBolt(消息处理者)(用来处理数据)
- TopologyBuilder(拓扑的构建器)(通过拓扑构建器 将spout和bolt组合起来)
- Values(将数据存放到values,发送到下一个组件)(将bolt产生的数据放在values里面,可以看作一个集合)
- Tuple(发送的数据被封装到Tuple,可以通tuple接收上个组件发送的消息)(可以看作一个集合,封装上一个组件发送的消息)
- Config(配置)
- StoemSubmitter/LocalCluster(拓扑提交器)
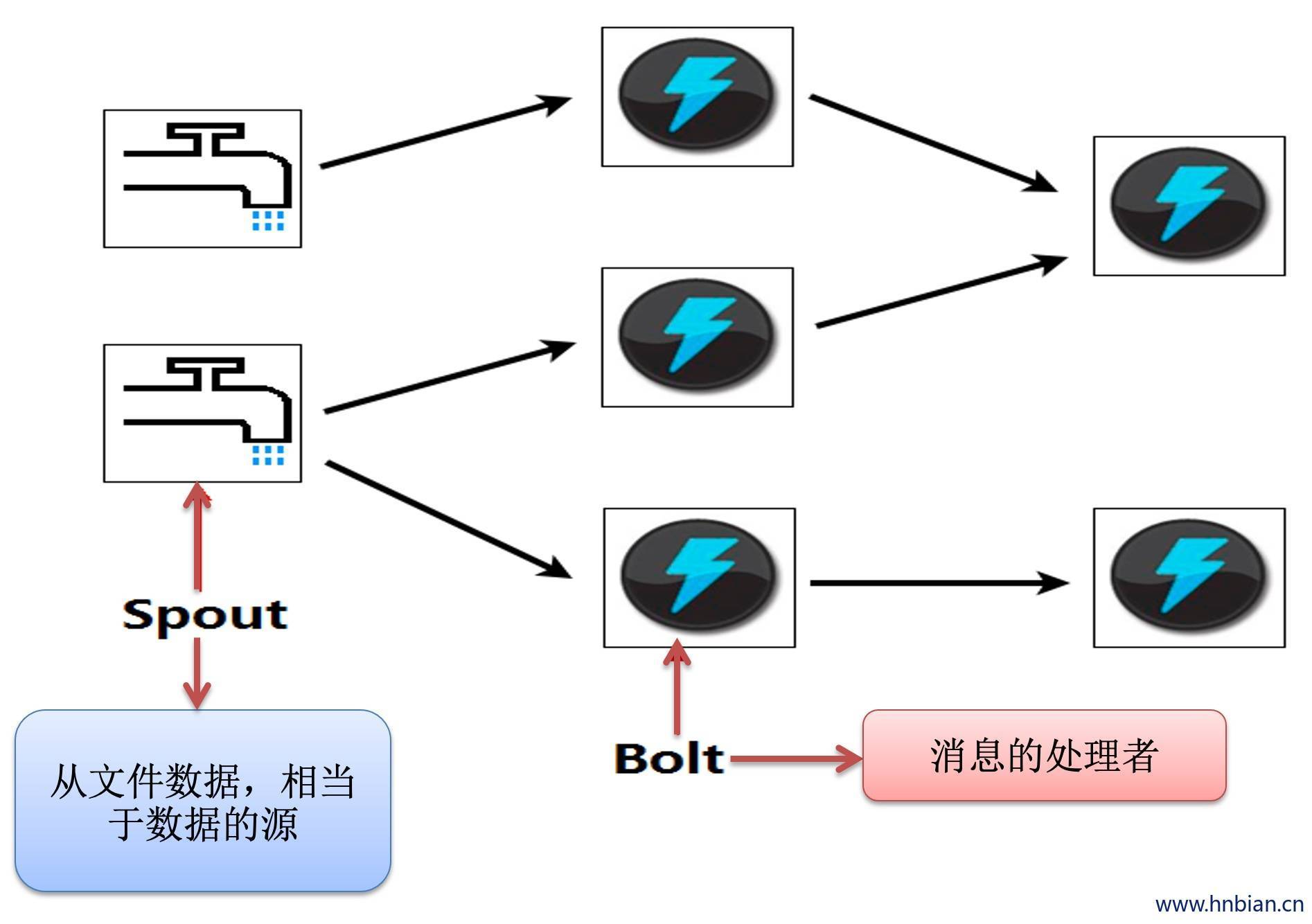
5.Storm 做wordcount计算
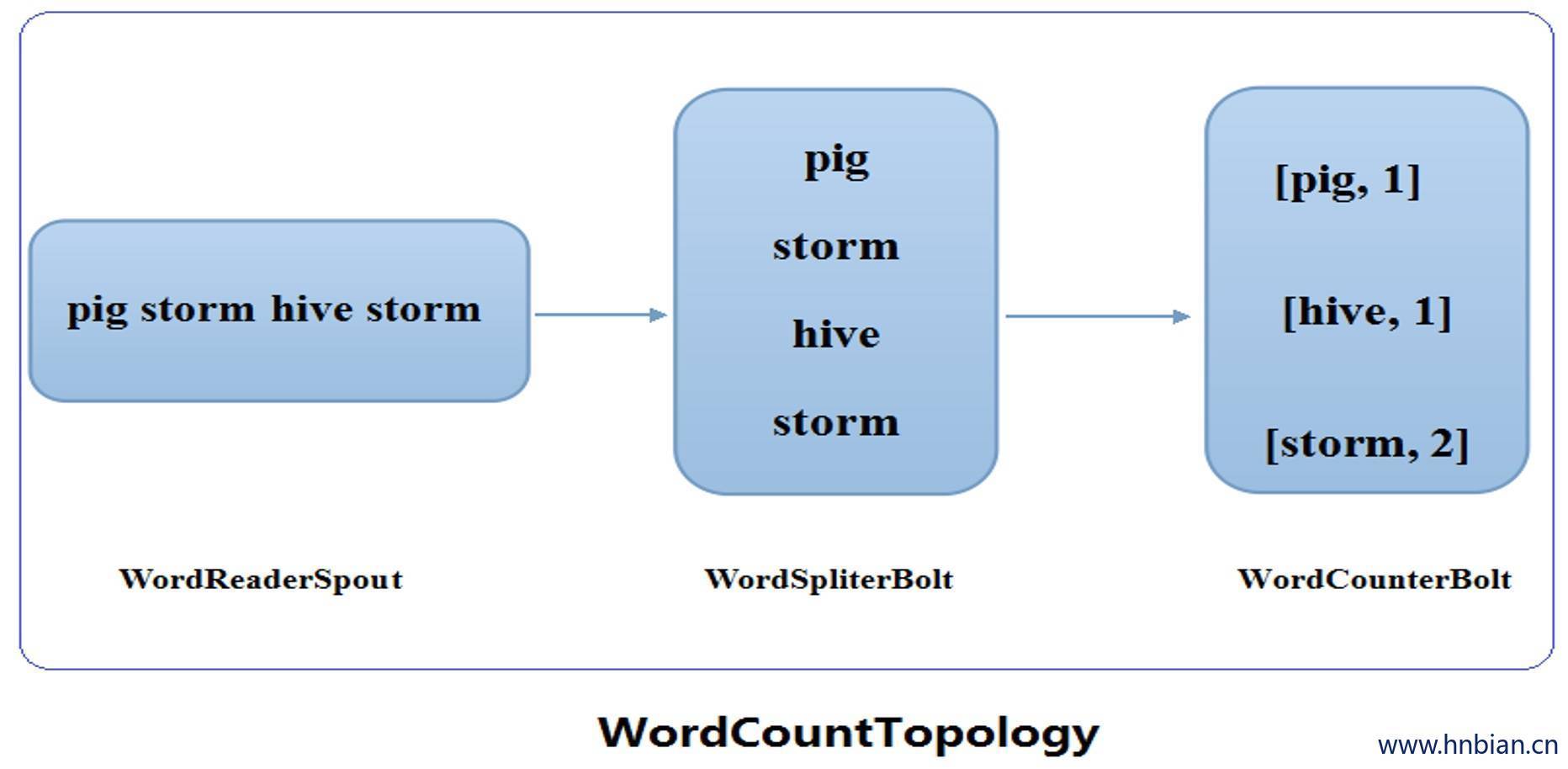
// TopologyBuilder
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.topology.BoltDeclarer;
import backtype.storm.topology.TopologyBuilder;
import cn.itcast.storm.bolt.WordCounter;
import cn.itcast.storm.bolt.WordSpliter;
import cn.itcast.storm.spout.WordReader;
import java.io.PrintStream;
public class WordCountTopo
{
public static void main(String[] args)
{
if (args.length != 2) {
System.err.println("Usage: inputPaht timeOffset");
System.err.println("such as : java -jar WordCount.jar D://input/ 2");
System.exit(2);
}
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("word-reader", new WordReader());
builder.setBolt("word-spilter", new WordSpliter()).shuffleGrouping("word-reader");
builder.setBolt("word-counter", new WordCounter()).shuffleGrouping("word-spilter");
String inputPaht = args[0];
String timeOffset = args[1];
Config conf = new Config();
conf.put("INPUT_PATH", inputPaht);
conf.put("TIME_OFFSET", timeOffset);
conf.setDebug(false);
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("WordCount", conf, builder.createTopology());
}
}
// spout
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichSpout;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import java.io.File;
import java.io.IOException;
import java.util.Collection;
import java.util.List;
import java.util.Map;
import org.apache.commons.io.FileUtils;
import org.apache.commons.io.filefilter.FileFilterUtils;
public class WordReader extends BaseRichSpout
{
private static final long serialVersionUID = 2197521792014017918L;
private String inputPath;
private SpoutOutputCollector collector;
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector)
{
this.collector = collector;
this.inputPath = ((String)conf.get("INPUT_PATH"));
}
public void nextTuple()
{
Collection files = FileUtils.listFiles(new File(this.inputPath), FileFilterUtils.notFileFilter(FileFilterUtils.suffixFileFilter(".bak")), null);
for (File f : files)
try {
List lines = FileUtils.readLines(f, "UTF-8");
for (String line : lines) {
this.collector.emit(new Values(new Object[] { line }));
}
FileUtils.moveFile(f, new File(f.getPath() + System.currentTimeMillis() + ".bak"));
} catch (IOException e) {
e.printStackTrace();
}
}
public void declareOutputFields(OutputFieldsDeclarer declarer)
{
declarer.declare(new Fields(new String[] { "line" }));
}
}
// bolt
import backtype.storm.topology.BasicOutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseBasicBolt;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values;
import org.apache.commons.lang.StringUtils;
public class WordSpliter extends BaseBasicBolt
{
private static final long serialVersionUID = -5653803832498574866L;
public void execute(Tuple input, BasicOutputCollector collector)
{
String line = input.getString(0);
String[] words = line.split(" ");
for (String word : words) {
word = word.trim();
if (StringUtils.isNotBlank(word)) {
word = word.toLowerCase();
collector.emit(new Values(new Object[] { word }));
}
}
}
public void declareOutputFields(OutputFieldsDeclarer declarer)
{
declarer.declare(new Fields(new String[] { "word" }));
}
}
// bolt
import backtype.storm.topology.BasicOutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseBasicBolt;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values;
import org.apache.commons.lang.StringUtils;
public class WordSpliter extends BaseBasicBolt{
private static final long serialVersionUID = -5653803832498574866L;
public void execute(Tuple input, BasicOutputCollector collector){
String line = input.getString(0);
String[] words = line.split(" ");
for (String word : words) {
word = word.trim();
if (StringUtils.isNotBlank(word)) {
word = word.toLowerCase();
collector.emit(new Values(new Object[] { word }));
}
}
}
public void declareOutputFields(OutputFieldsDeclarer declarer){
declarer.declare(new Fields(new String[] { "word" }));
}
}
6. Storm 集群结构
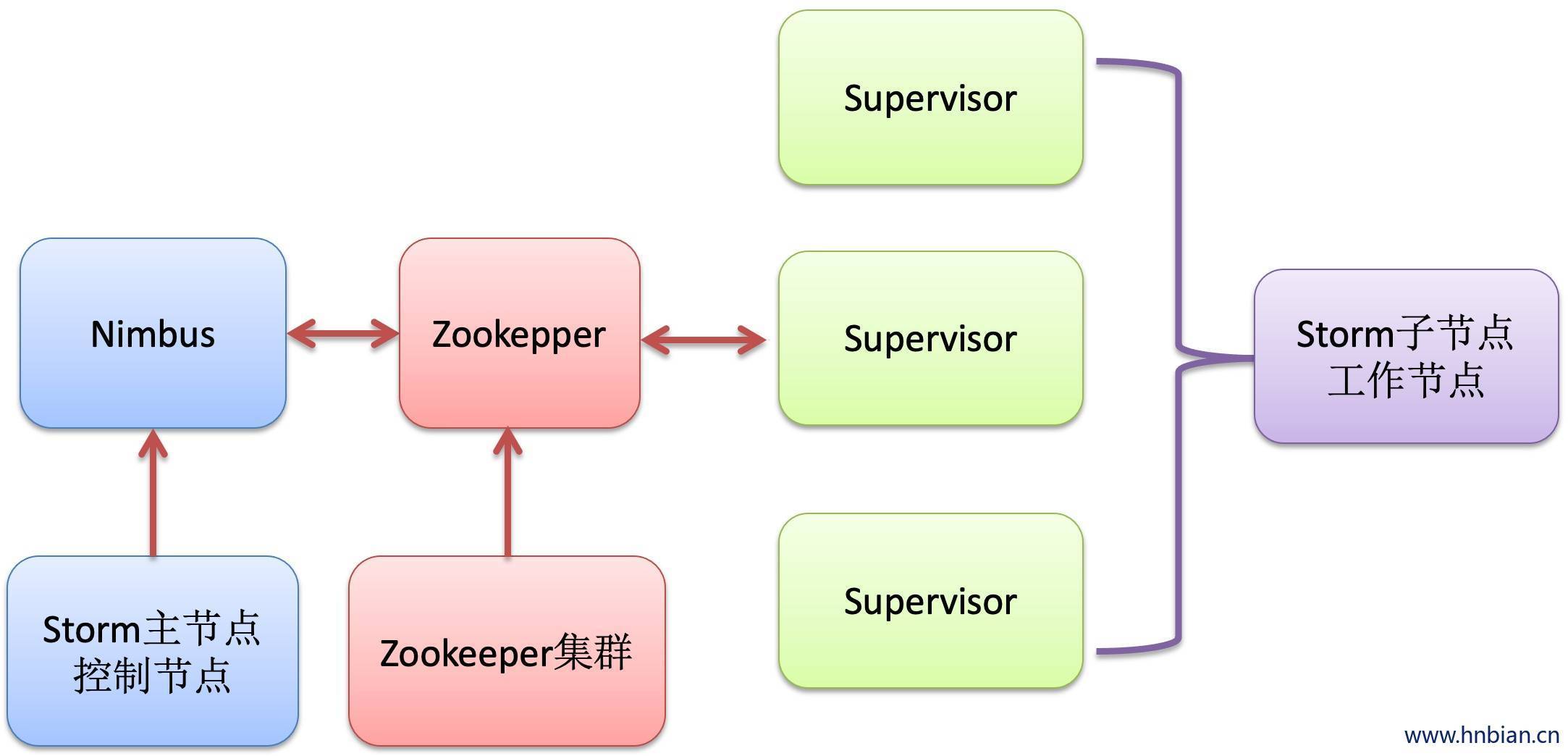
Nimbus 和 supervisor
- 在Storm 的集群里面有两种节点:控制节点和工作节点。
- 控制节点上面运行一个叫Nimbus进程,Nimbus负责在集群里面分发代码,分配计算任务,并且监控状态。
- 每一个工作节点上面运行 SuperVisor进程。每个Supervisor负责监听从Nimbus分配给它执行的任务,据此启动或者停止执行任务的工作进程
- Nimbus和SuperVisor之间的所有协调工作都是通过Zookepper集群完成的
7. Storm 集群搭建
7.1 集群规划
| 主机名 | Storm角色 | Zookeeper |
|---|---|---|
| MASTER | Nimbus | 单节点Zookeeper |
| SLAVE-1 | Supervisor | |
| SLAVE-2 | Supervisor |
7.2 linux基本配置:
# 修改主机名
# 如果不生效更改/etc/sysconfig/network
vim /etc/sysconfig/network
# 添加如下
hostname=c1
# 修改IP
vim /etc/sysconfig/network-scripts/ifcfg-eth0
# 修改主机和IP的映射关系(把所有的节点都配置上)
vim /etc/hosts
192.168.10.198 c1
# 关闭防火墙
service iptables stop
# 关闭开机自启
chkconfig iptables off7.3 安装jdk
安装步骤:
# 1. 上传jdk安装包
# 2. 解压安装
tar -zxvf jdk-7u75-linux-i586.tar.gz
# 3. 配置环境变量
vim /etc/profile
# 将下面代码加都最后位置
export JAVA_HOME=/usr/java/jdk1.7.0_75
export PATH=$PATH:$JAVA_HOME/bin7.4 搭建Zookeeper集群
# 1.解压Zookeeper
tar -zxf Zookeeper.tar.gz
# 2. 进行配置
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg
# 修改:
dataDir=/opt/zookeeper-3.4.5/tmp
# 启动Zookeeper
bin/zkServer.sh start7.5 . 安装Storm依赖
7.5.1 安装 zeromq
# 1. 解压zeromq
tar -xzf zeromq-2.1.7.tar.gz
cd zeromq-2.1.7
# 2. 对编译环境进行检测
./configure
#编译可能会出错:configure: error: Unable to find a working C++ compiler
#安装一下依赖的rpm包:libstdc++-devel gcc-c++
# 可以上网的情况下:
yum install gcc-c++
#虚拟机不能上网情况:首先到http://mirrors.163.com/centos/6.4/os/x86_64/Packages/ 下载rpm
rpm -ivh libstdc++-devel-4.4.7-3.el6.x86_64.rpm
rpm -ivh gcc-c++-4.4.7-3.el6.x86_64.rpm
rpm -ivh libuuid-devel-2.17.2-12.9.el6.x86_64.rpm
# i:install
# v:显示详情
# h:进度条
#安装完成之后再进行检测
./configure
# 进行编译
make
# 进行安装
make install7.5.2 编译安装
# 1. 解压文件
unzip jqmq-master.zip
# 2. 跳转目录
cd jzmq
# 3. 运行脚本生成conf文件
./autogen.sh
#报错:autogen.sh: error: could not find libtool. libtool is required to run autogen.sh. 缺少libtool
yum install libtool
# 或者手动安装
rpm -ivh autoconf-2.63-5.1.el6.noarch.rpm
rpm -ivh automake-1.11.1-4.el6.noarch.rpm
rpm -ivh libtool-2.2.6-15.5.el6.x86_64.rpm
# 安装完成之后再生成conf
./autogen.sh
# 进行检测
./configure
# 进行编译
make
# 进行安装
make install7.5.3 安装python
# 1. 解压
tar –zxvf Python-2.6.6.tgz
# 2. 跳转目录
cd Python-2.6.6
# 3. 进行检测
./configure
# 4. 进行编译
make
# 5. 进行安装
make install7.6 下载并解压Storm发布版本
# 1. 下载Storm发行版本
wget https://dl.dropbox.com/u/133901206/storm-0.8.2.zip
# 2. 解压到安装目录下
unzip storm-0.8.1.zip
# 3. 修改storm.yaml配置文件
# 修改 conf/storm.yaml 配置文件
# conf/storm.yaml中的配置选项将覆盖defaults.yaml中的默认配置。
# 以下配置选项是必须在conf/storm.yaml中进行配置的:
# 1) storm.zookeeper.servers: Storm集群使用的Zookeeper集群地址,其格式如下:
storm.zookeeper.servers:
"192.168.10.98"
"192.168.10.99"
# 2) storm.local.dir: Nimbus和Supervisor进程用于存储少量状态,如jars、confs等的本地磁盘目录,需要提前创建该目录并给以足够的访问权限。然后在storm.yaml中配置该目录,如:
storm.local.dir: "/usr/storm/workdir"
# 3) java.library.path: Storm使用的本地库(ZMQ和JZMQ)加载路径,默认为"/usr/local/lib:/opt/local/lib:/usr/lib",
# 一般来说ZMQ和JZMQ默认安装在/usr/local/lib 下,因此不需要配置即可。
# 4) nimbus.host: Storm集群Nimbus机器地址,各个Supervisor工作节点需要知道哪个机器是Nimbus,以便下载Topologies的jars、confs等文件,如:
nimbus.host: "192.168.10.98"
# 5) supervisor.slots.ports: 对于每个Supervisor工作节点,需要配置该工作节点可以运行的worker数量。每个worker占用一个单独的端口用于接收消息,
# 该配置选项即用于定义哪些端口是可被worker使用的。默认情况下,每个节点上可运行4个workers,分别在6700、6701、6702和6703端口,如:
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 67037.7 . 启动Storm各个后台进程
最后一步,启动Storm的所有后台进程。和Zookeeper一样,Storm也是快速失败(fail-fast)的系统,这样Storm才能在任意时刻被停止,并且当进程重启后被正确地恢复执行。这也是为什么Storm不在进程内保存状态的原因,即使Nimbus或Supervisors被重启,运行中的Topologies不会受到影响。
以下是启动Storm各个后台进程的方式:
- Nimbus: 在Storm主控节点上运行
"bin/storm nimbus >/dev/stormlog 2>&1 &"启动Nimbus后台程序,并放到后台执行将错误信息与标准信息都打印到文件中; - Supervisor: 在Storm各个工作节点上运行
"bin/storm supervisor >/dev/null 2>&1 &"启动Supervisor后台程序,并放到后台执行将错误信息与标准信息都打印到文件中; - UI: 在Storm主控节点上运行
"bin/storm ui >/dev/null 2>&1 &"启动UI后台程序,并放到后台执行,启动后可以通过http://{nimbus host}:8080观察集群的worker资源使用情况、Topologies的运行状态等信息将错误信息与标准信息都打印到文件中。
注意事项:
Storm后台进程被启动后,将在Storm安装部署目录下的logs/子目录下生成各个进程的日志文件。
经测试,Storm UI必须和Storm Nimbus部署在同一台机器上,否则UI无法正常工作,因为UI进程会检查本机是否存在Nimbus链接。
为了方便使用,可以将bin/storm加入到系统环境变量中。
至此,Storm集群已经部署、配置完毕,可以向集群提交拓扑运行了。
7.8 向集群提交任务
- 启动Storm Topology:
storm jar allmycode.jar org.me.MyTopology arg1 arg2 arg3
其中,allmycode.jar是包含Topology实现代码的jar包,org.me.MyTopology的main方法是Topology的入口,arg1、arg2和arg3为org.me.MyTopology执行时需要传入的参数。
- 停止Storm Topology:
storm kill {toponame}
其中,{toponame}为Topology提交到Storm集群时指定的Topology任务名称。
浏览器访问http://192.168.10.98:8080
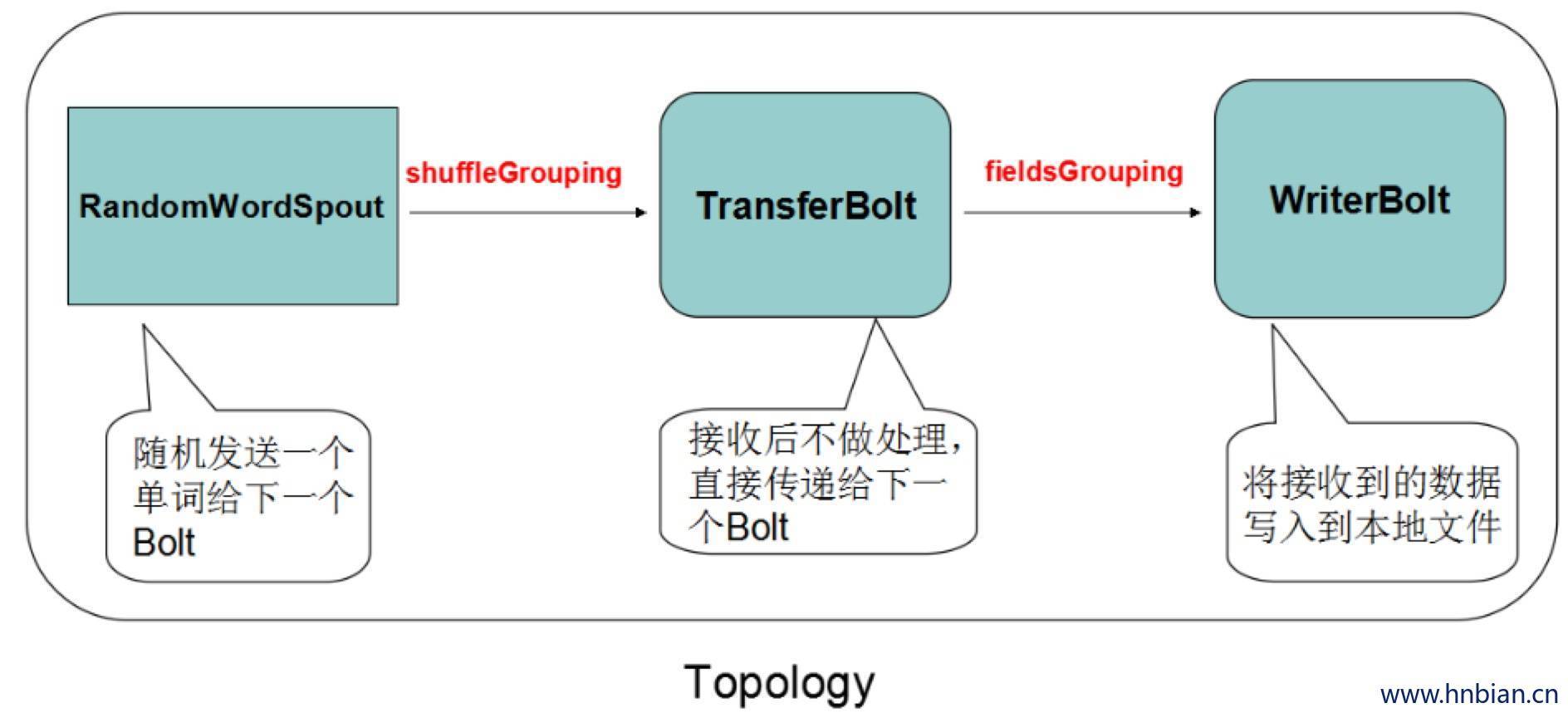
- 代码示例
// Topology
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import backtype.storm.Config;
import backtype.storm.StormSubmitter;
import backtype.storm.topology.TopologyBuilder;
import backtype.storm.tuple.Fields;
import cn.itcast.storm.bolt.TransferBolt;
import cn.itcast.storm.bolt.WriterBolt;
import cn.itcast.storm.spout.RandomWordSpout;
public class TopoMain {
private static final Log log = LogFactory.getLog(TopoMain.class);
/**
* @param args
*/
public static void main(String[] args) throws Exception {
TopologyBuilder builder = new TopologyBuilder();
//设置启动几个spout
实例化几个对象
builder.setSpout("random", new RandomWordSpout(), 2);
//设置并行度
builder.setBolt("transfer", new TransferBolt(), 4).shuffleGrouping("random");//.setNumTasks(8)
builder.setBolt("writer", new WriterBolt(), 4).fieldsGrouping("transfer", new Fields("word"));//.setNumTasks(8)
Config conf = new Config();
conf.setNumWorkers(2);
conf.setDebug(true);
//默认有一个ackers 用于跟踪数据
//conf.setNumAckers(0);
log.warn("$$$$$$$$$$$ submitting topology...");
StormSubmitter.submitTopology("life-cycle", conf, builder.createTopology());
log.warn("$$$$$$$4$$$ topology submitted !");
}
}
// spout
import java.util.Map;
import java.util.Random;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichSpout;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.utils.Utils;
/**
* 随机从String数组当中读取一个单词发送给下一个bolt
* @author Administrator
*
*/
public class RandomWordSpout extends BaseRichSpout {
private static final long serialVersionUID = -4287209449750623371L;
private static final Log log = LogFactory.getLog(RandomWordSpout.class);
private SpoutOutputCollector collector;
//定义字符串数组
private String[] words = new String[]{"storm", "hadoop", "hive", "flume"};
private Random random = new Random();
public RandomWordSpout() {
log.warn("&&&&&&&&&&&&&&&&& RandomWordSpout constructor method invoked");
}
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
log.warn("################# RandomWordSpout open() method invoked");
this.collector = collector;
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
log.warn("################# RandomWordSpout declareOutputFields() method invoked");
declarer.declare(new Fields("str"));
}
//在这里发送数据
@Override
public void nextTuple() {
log.warn("################# RandomWordSpout nextTuple() method invoked");
Utils.sleep(500);
String str = words[random.nextInt(words.length)];
collector.emit(new Values(str));
}
@Override
public void activate() {
log.warn("################# RandomWordSpout activate() method invoked");
}
@Override
public void deactivate() {
log.warn("################# RandomWordSpout deactivate() method invoked");
}
}
// bolt
import java.util.Map;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.BasicOutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseBasicBolt;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values;
/**
* 将数据做简单的 传递的Bolt
* @author Administrator
*
*/
public class TransferBolt extends BaseBasicBolt {
private static final long serialVersionUID = 4223708336037089125L;
private static final Log log = LogFactory.getLog(TransferBolt.class);
public TransferBolt() {
log.warn("&&&&&&&&&&&&&&&&& TransferBolt constructor method invoked");
}
@Override
public void prepare(Map stormConf, TopologyContext context) {
log.warn("################# TransferBolt prepare() method invoked");
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
log.warn("################# TransferBolt declareOutputFields() method invoked");
declarer.declare(new Fields("word"));
}
//在这里处理数据
//通过Tuple 一个对象集合 得到上一个组件发送过来的数据
@Override
public void execute(Tuple input, BasicOutputCollector collector) {
log.warn("################# TransferBolt execute() method invoked");
String word = input.getStringByField("str");
collector.emit(new Values(word));
}
}
// bolt
import java.io.FileWriter;
import java.io.IOException;
import java.util.Map;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.BasicOutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseBasicBolt;
import backtype.storm.tuple.Tuple;
/**
* 将接收到的单词写入到一个文件当中
* @author Administrator
*
*/
public class WriterBolt extends BaseBasicBolt {
private static final long serialVersionUID = -6586283337287975719L;
private static final Log log = LogFactory.getLog(WriterBolt.class);
private FileWriter writer = null;
public WriterBolt() {
log.warn("&&&&&&&&&&&&&&&&& WriterBolt constructor method invoked");
}
//在execute 方法执行前执行一次
@Override
public void prepare(Map stormConf, TopologyContext context) {
log.warn("################# WriterBolt prepare() method invoked");
try {
writer = new FileWriter("/home/" + this);
} catch (IOException e) {
log.error(e);
throw new RuntimeException(e);
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
log.warn("################# WriterBolt declareOutputFields() method invoked");
}
//进行操作
@Override
public void execute(Tuple input, BasicOutputCollector collector) {
log.warn("################# WriterBolt execute() method invoked");
String s = input.getString(0);
try {
writer.write(s);
writer.write("\n");
writer.flush();
} catch (IOException e) {
log.error(e);
throw new RuntimeException(e);
}
}
}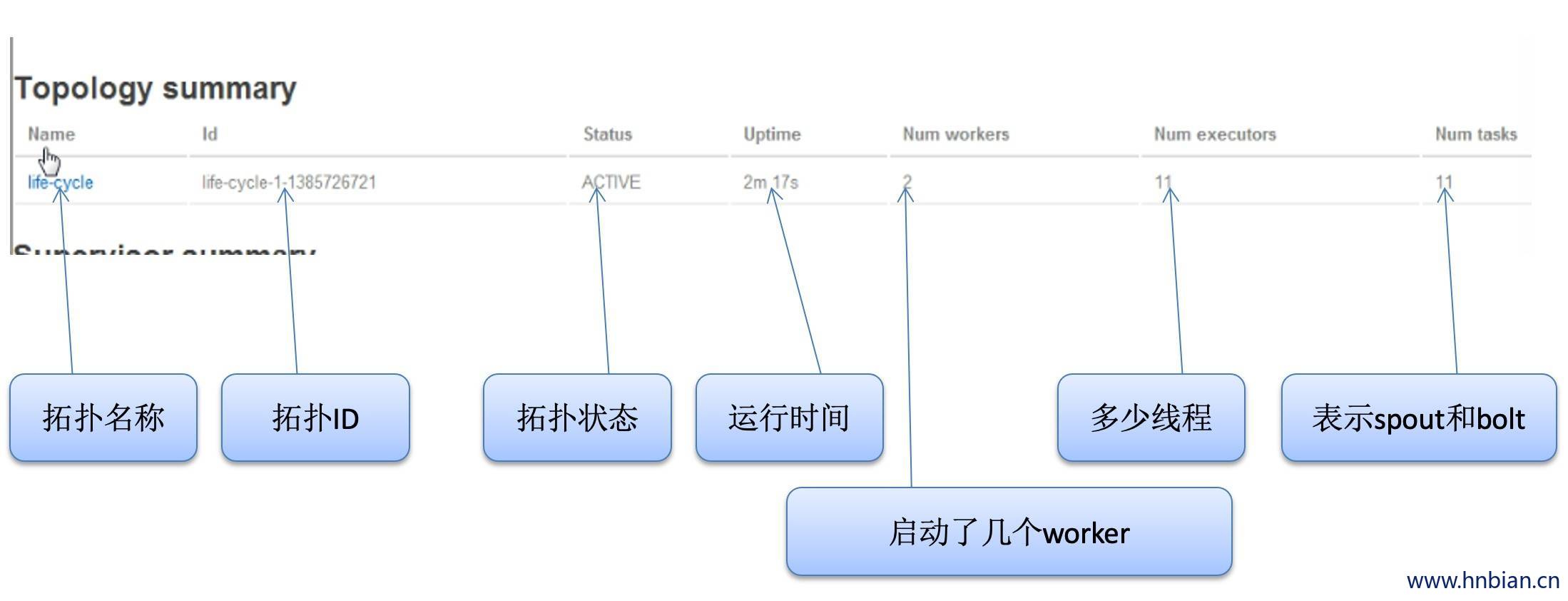
启动一定数量的worker
worker中有具体的某个对象 spout bolt实例化之后的对象,我门可以指定spout和bolt的数量
7.9 关闭任务
# 关掉任务
./storm kill 任务名称
# 启动任务
./storm jar 指定类8. Storm 内部运行关系
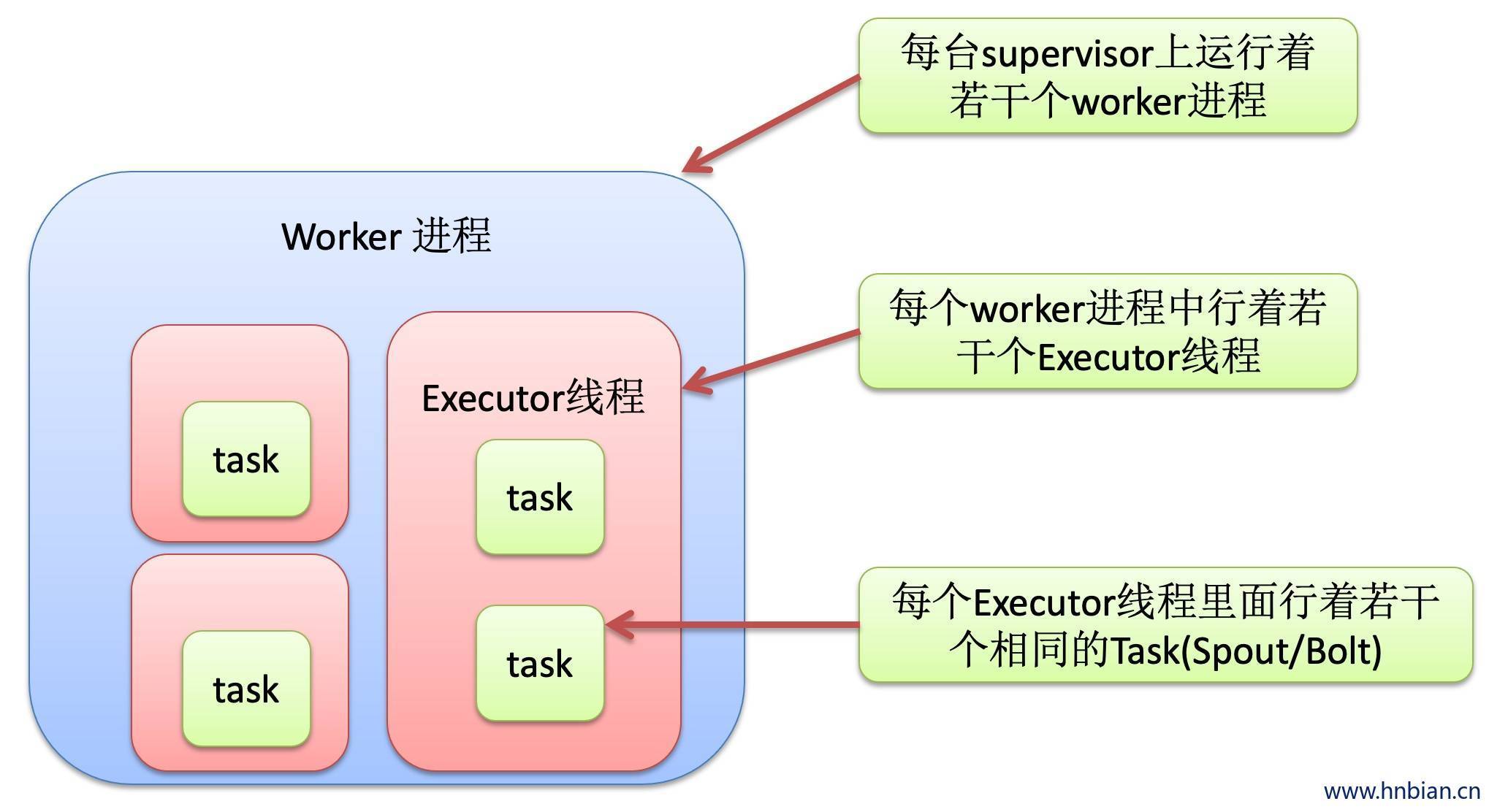
Nimbus 得到一个任务之后,首先将任务写到Zookeeper里面,supervisor 到Zookeeper里面领任务,SuperVisor领到任务(工作节点)之后会启动一定数量worker,worker 里面有task ++>spout/bolt的实例对象可以设置多个并行度,
9. 消息分发策略:Stream groupings
| 分发策略 | 说明 |
|---|---|
| Shuffer Grouping 随机分组 |
随机派发stream里面的tuple,保证每个bolt接收到的tuple数目相同 |
| Fields Grouping 按字段userid来分组 |
具有同样的userid的tuple会被分到相同的Bolts,而不同的userid则会分配到不同的Bolts. |
| All Grouping 广播发送 |
对于每一个tuple,所有的bolts都会收到。 |
| Global Grouping 全局分组 |
这个tuple被分配到storm中的一个bolt的其中的一个task。 再具体一点就是分配给id值最低的那个task. |
| non Grouping 不分组 |
这个分组的意思就是说stream不关心到底谁会收到tuple。 目前这种分组和shuffle grouping 是一样的效果, 有一点不同的是storm会把这个bolt放到这个bole的订阅者同一个线程里面去执行。 |
| direct Grouping 直接分组 |
这是一种比较特别的分组方法,用这种分组意味着消息的发送者指定由消息接受者的 哪个task处理这个消息。 只有被生命为Direct Storm的消息流可以通过TopologyContext来获取处理它的消息的taskid(OutputCollector.emit方法也会返回taskid) |
| Local or shuffle Grouping | 如果目标bolt有一个或者多个task在同一工作进程中, tuple将会随机发送给这些tasks.否则,和普通的shuffle Grouping 行为一致。 |
10. Storm 中对象的生命周期
10.1 spout方法调用顺序
- declareOutputFields()(声明发送的字段。字段名称)
- Open()第一个执行
- Activate()将spout激活 如果没激活就不执行spout
- naxtTuple()(循环调用)
- Deactivate()当发送命令deactivate 时候执行
10.2 bolt方法调用顺序
- dectareOutputFields()(声明发送的字段。字段名称)
- Prepare()执行一次
- Execute()(循环执行)
11. 高可靠性
设置storm 支持的slots 数量
Vim conf
Supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
- 6704
- 6705
前面建议使用空格占位
重新平衡worker web界面 rebalance
在什么条件下,storm 才会认为一个从spout发送出来的消息被完全处理呢?
- Tuple tree不再生长
- 树中的任何消息被标识为“已处理”
使用strom提供的可靠处理特性:
- 无论何时在tuple tree中创建了一个新的节点,我们需要明确的通知storm
- 当处理完一个单独的消息时,我们需要告诉storm这颗tuple的变化状态
通过上面的两步,storm就可以检测到一个tuple tree何时被完全处理了,并且会调用相关的ack或fail方法、
锚定(anchoring) 把tuple传递进来 对tuple进行跟踪
怎么实现高可靠性
实现IRichSpout 接口
重写fail和ack方法
其他bolt对消息进行锚定
if (count == 5) {
collector.fail(input);
} else {
try {
writer.write(word);
writer.write("\r\n");
writer.flush();
} catch (IOException e) {
e.printStackTrace();
}
collector.emit(input, new Values(word));
collector.ack(input);
}// Topology
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.topology.TopologyBuilder;
import cn.itcast.storm.bolt.FileWriterBolt;
import cn.itcast.storm.bolt.SpliterBolt;
import cn.itcast.storm.spout.MessageSpout;
public class TopoMain {
public static void main(String[] args) {
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("spout", new MessageSpout());
builder.setBolt("bolt-1", new SpliterBolt()).shuffleGrouping("spout");
builder.setBolt("bolt-2", new FileWriterBolt()).shuffleGrouping("bolt-1");
Config conf = new Config();
conf.setDebug(false);
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("reliability", conf, builder.createTopology());
}
}
// spout
import java.util.Map;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichSpout;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
public class MessageSpout implements IRichSpout {
private static final long serialVersionUID = -4664068313075450186L;
private int index = 0;
private String[] lines;
private SpoutOutputCollector collector;
public MessageSpout(){
lines = new String[]{
"0,zero",
"1,one",
"2,two",
"3,three",
"4,four",
"5,five",
"6,six",
"7,seven",
"8,eight",
"9,nine"
};
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("line"));
}
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.collector = collector;
}
@Override
public void nextTuple() {
if(index < lines.length){
String l = lines[index];
collector.emit(new Values(l), index);
index++;
}
}
//标注消息处理成功
@Override
public void ack(Object msgId) {
System.out.println("message sends successfully (msgId = " + msgId +")");
}
//标注消息处理失败
@Override
public void fail(Object msgId) {
System.out.println("error : message sends unsuccessfully (msgId = " + msgId +")");
System.out.println("resending...");
collector.emit(new Values(lines[(Integer) msgId]), msgId);
System.out.println("resend successfully");
}
@Override
public void close() {
}
@Override
public void activate() {
}
@Override
public void deactivate() {
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}
// bolt
import java.util.Map;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values;
public class SpliterBolt implements IRichBolt {
private static final long serialVersionUID = 6266473268990329206L;
private OutputCollector collector;
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
@Override
public void execute(Tuple input) {
String line = input.getString(0);
String[] words = line.split(",");
for (String word : words) {
collector.emit(input, new Values(word));
}
collector.ack(input);
}
@Override
public void cleanup() {
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}
// bolt
import java.io.FileWriter;
import java.io.IOException;
import java.util.Map;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values;
public class FileWriterBolt implements IRichBolt {
private static final long serialVersionUID = -8619029556495402143L;
private FileWriter writer;
private OutputCollector collector;
private int count = 0;
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
try {
writer = new FileWriter("e://reliability.txt");
} catch (IOException e) {
}
}
@Override
public void execute(Tuple input) {
String word = input.getString(0);
if (count == 5) {
collector.fail(input);
} else {
try {
writer.write(word);
writer.write("\r\n");
writer.flush();
} catch (IOException e) {
e.printStackTrace();
}
collector.emit(input, new Values(word));
collector.ack(input);
}
count++;
}
@Override
public void cleanup() {
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}



